 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDumitru Erhan
Hierarchical Long-term Video Prediction without Supervision
Jun 12, 2018
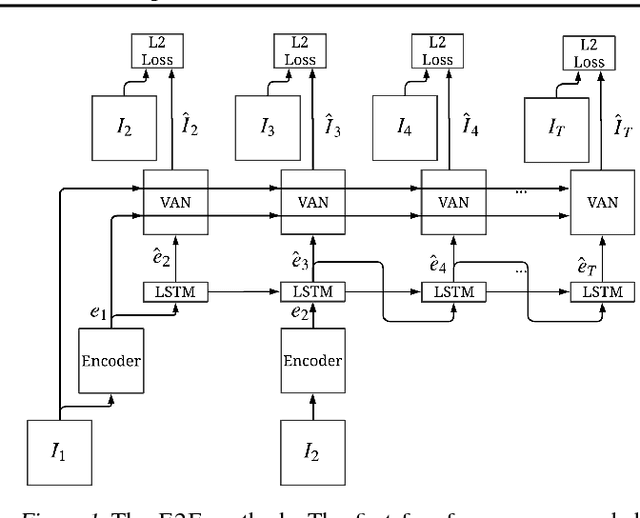
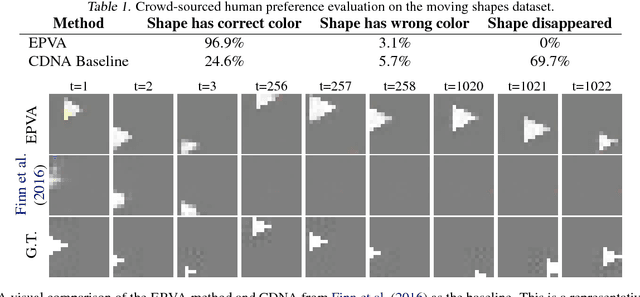
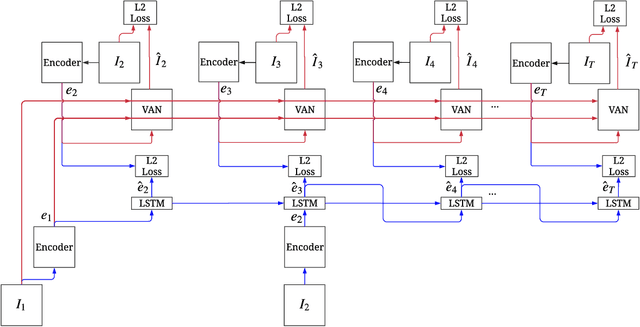
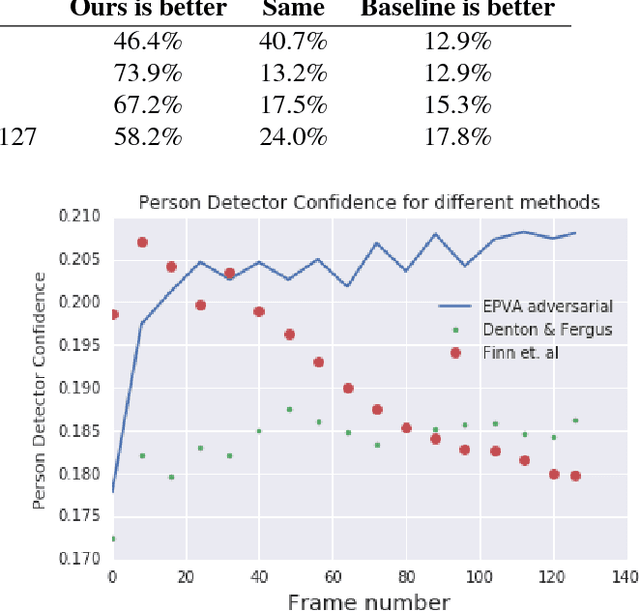
Much of recent research has been devoted to video prediction and generation, yet most of the previous works have demonstrated only limited success in generating videos on short-term horizons. The hierarchical video prediction method by Villegas et al. (2017) is an example of a state-of-the-art method for long-term video prediction, but their method is limited because it requires ground truth annotation of high-level structures (e.g., human joint landmarks) at training time. Our network encodes the input frame, predicts a high-level encoding into the future, and then a decoder with access to the first frame produces the predicted image from the predicted encoding. The decoder also produces a mask that outlines the predicted foreground object (e.g., person) as a by-product. Unlike Villegas et al. (2017), we develop a novel training method that jointly trains the encoder, the predictor, and the decoder together without highlevel supervision; we further improve upon this by using an adversarial loss in the feature space to train the predictor. Our method can predict about 20 seconds into the future and provides better results compared to Denton and Fergus (2018) and Finn et al. (2016) on the Human 3.6M dataset.
Stochastic Variational Video Prediction
Mar 06, 2018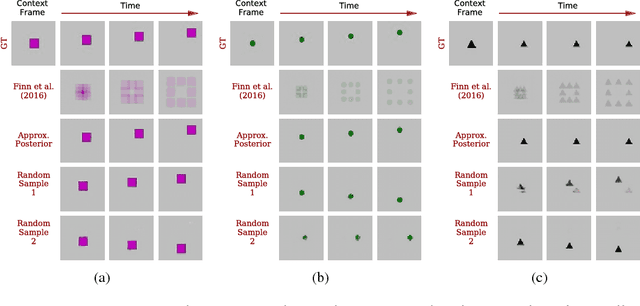
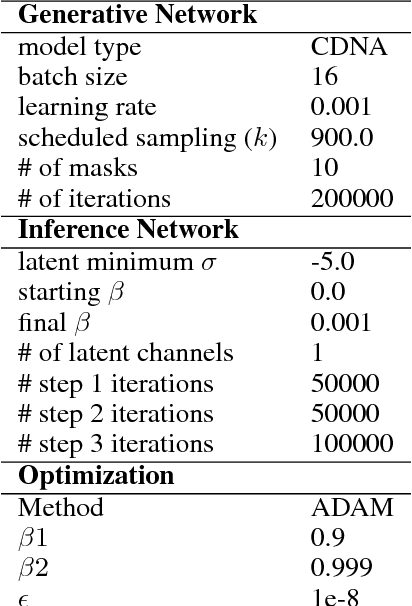
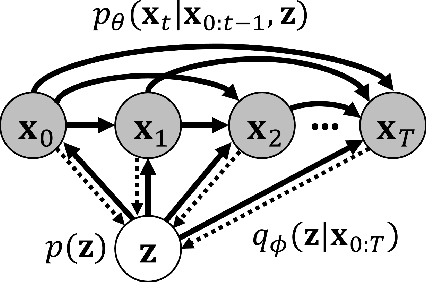
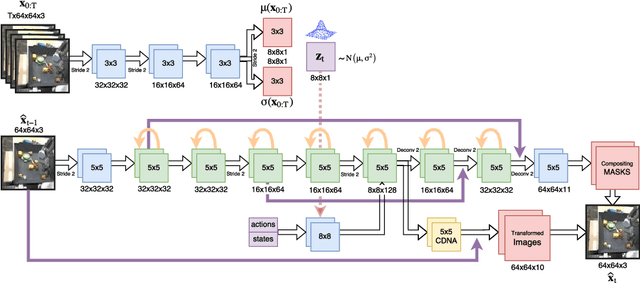
Predicting the future in real-world settings, particularly from raw sensory observations such as images, is exceptionally challenging. Real-world events can be stochastic and unpredictable, and the high dimensionality and complexity of natural images requires the predictive model to build an intricate understanding of the natural world. Many existing methods tackle this problem by making simplifying assumptions about the environment. One common assumption is that the outcome is deterministic and there is only one plausible future. This can lead to low-quality predictions in real-world settings with stochastic dynamics. In this paper, we develop a stochastic variational video prediction (SV2P) method that predicts a different possible future for each sample of its latent variables. To the best of our knowledge, our model is the first to provide effective stochastic multi-frame prediction for real-world video. We demonstrate the capability of the proposed method in predicting detailed future frames of videos on multiple real-world datasets, both action-free and action-conditioned. We find that our proposed method produces substantially improved video predictions when compared to the same model without stochasticity, and to other stochastic video prediction methods. Our SV2P implementation will be open sourced upon publication.
The (Un)reliability of saliency methods
Nov 02, 2017
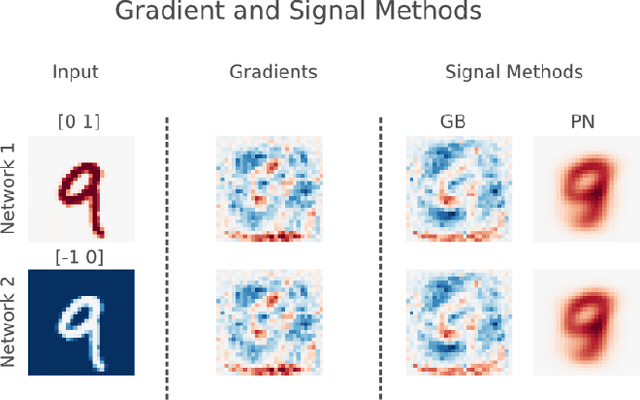
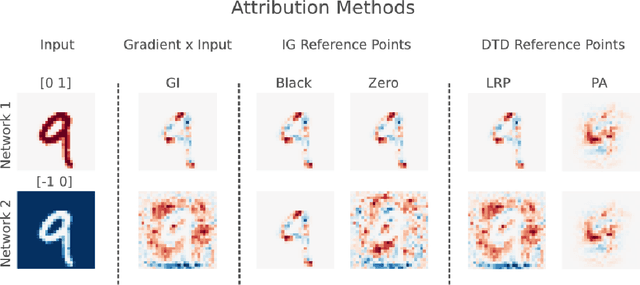
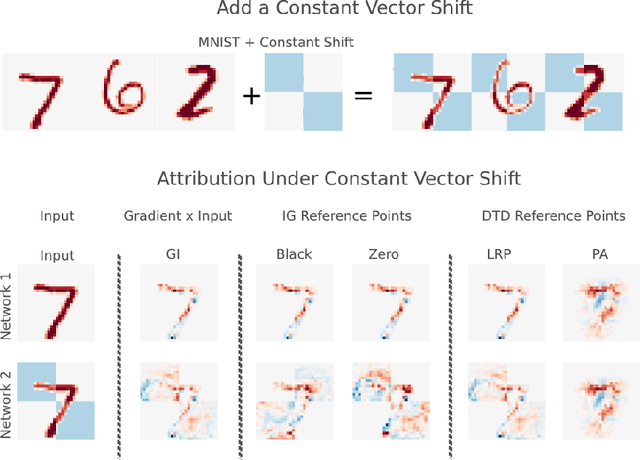
Saliency methods aim to explain the predictions of deep neural networks. These methods lack reliability when the explanation is sensitive to factors that do not contribute to the model prediction. We use a simple and common pre-processing step ---adding a constant shift to the input data--- to show that a transformation with no effect on the model can cause numerous methods to incorrectly attribute. In order to guarantee reliability, we posit that methods should fulfill input invariance, the requirement that a saliency method mirror the sensitivity of the model with respect to transformations of the input. We show, through several examples, that saliency methods that do not satisfy input invariance result in misleading attribution.
Learning how to explain neural networks: PatternNet and PatternAttribution
Oct 24, 2017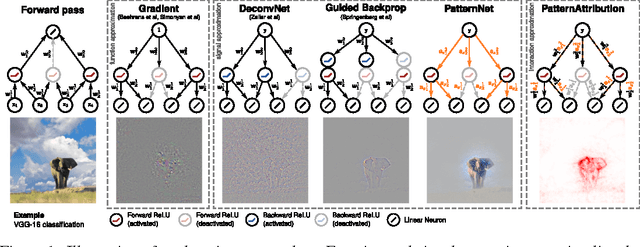
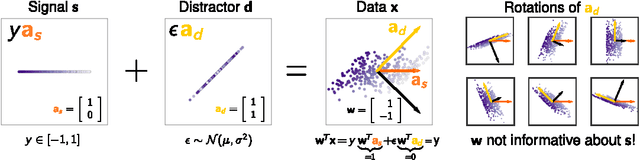
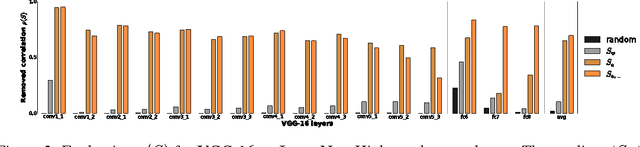

DeConvNet, Guided BackProp, LRP, were invented to better understand deep neural networks. We show that these methods do not produce the theoretically correct explanation for a linear model. Yet they are used on multi-layer networks with millions of parameters. This is a cause for concern since linear models are simple neural networks. We argue that explanation methods for neural nets should work reliably in the limit of simplicity, the linear models. Based on our analysis of linear models we propose a generalization that yields two explanation techniques (PatternNet and PatternAttribution) that are theoretically sound for linear models and produce improved explanations for deep networks.
Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks
Aug 23, 2017
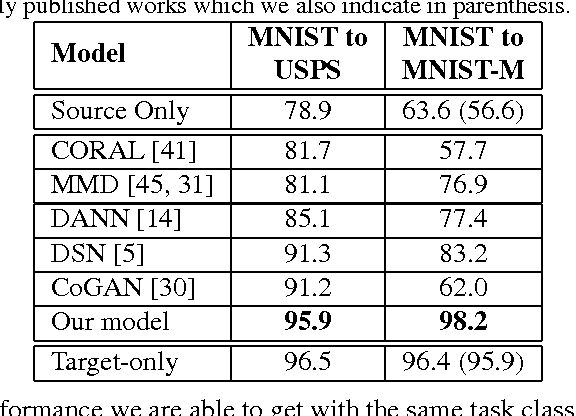
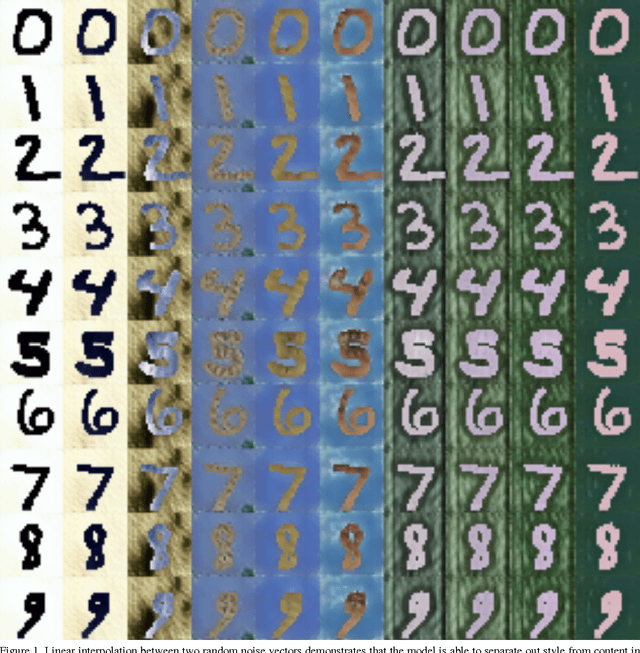
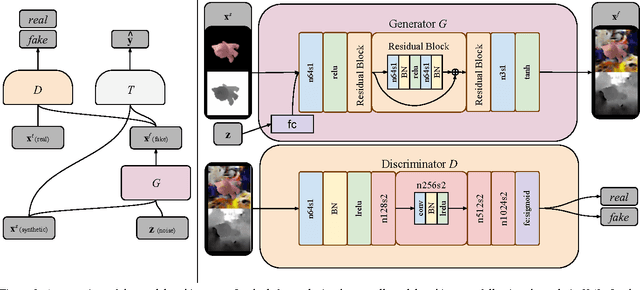
Collecting well-annotated image datasets to train modern machine learning algorithms is prohibitively expensive for many tasks. One appealing alternative is rendering synthetic data where ground-truth annotations are generated automatically. Unfortunately, models trained purely on rendered images often fail to generalize to real images. To address this shortcoming, prior work introduced unsupervised domain adaptation algorithms that attempt to map representations between the two domains or learn to extract features that are domain-invariant. In this work, we present a new approach that learns, in an unsupervised manner, a transformation in the pixel space from one domain to the other. Our generative adversarial network (GAN)-based method adapts source-domain images to appear as if drawn from the target domain. Our approach not only produces plausible samples, but also outperforms the state-of-the-art on a number of unsupervised domain adaptation scenarios by large margins. Finally, we demonstrate that the adaptation process generalizes to object classes unseen during training.
SSD: Single Shot MultiBox Detector
Dec 29, 2016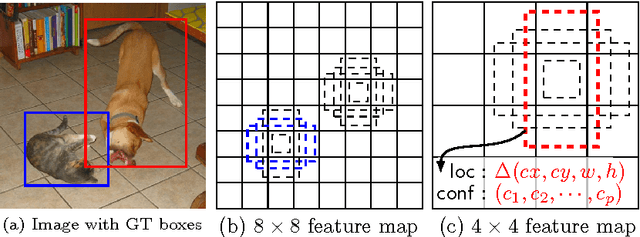
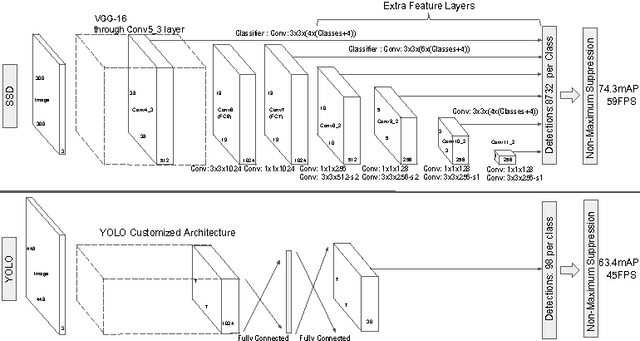

We present a method for detecting objects in images using a single deep neural network. Our approach, named SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location. At prediction time, the network generates scores for the presence of each object category in each default box and produces adjustments to the box to better match the object shape. Additionally, the network combines predictions from multiple feature maps with different resolutions to naturally handle objects of various sizes. Our SSD model is simple relative to methods that require object proposals because it completely eliminates proposal generation and subsequent pixel or feature resampling stage and encapsulates all computation in a single network. This makes SSD easy to train and straightforward to integrate into systems that require a detection component. Experimental results on the PASCAL VOC, MS COCO, and ILSVRC datasets confirm that SSD has comparable accuracy to methods that utilize an additional object proposal step and is much faster, while providing a unified framework for both training and inference. Compared to other single stage methods, SSD has much better accuracy, even with a smaller input image size. For $300\times 300$ input, SSD achieves 72.1% mAP on VOC2007 test at 58 FPS on a Nvidia Titan X and for $500\times 500$ input, SSD achieves 75.1% mAP, outperforming a comparable state of the art Faster R-CNN model. Code is available at https://github.com/weiliu89/caffe/tree/ssd .
Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge
Sep 21, 2016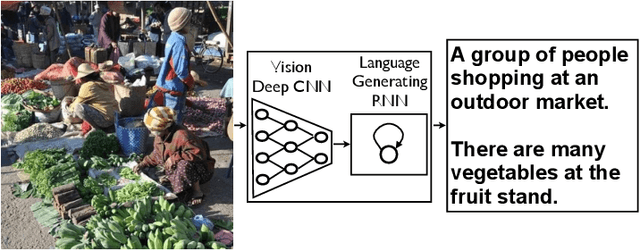
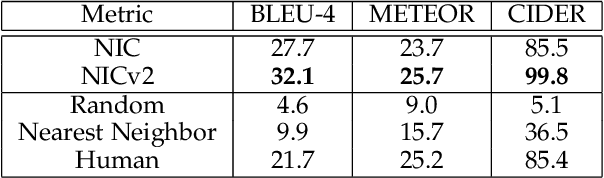
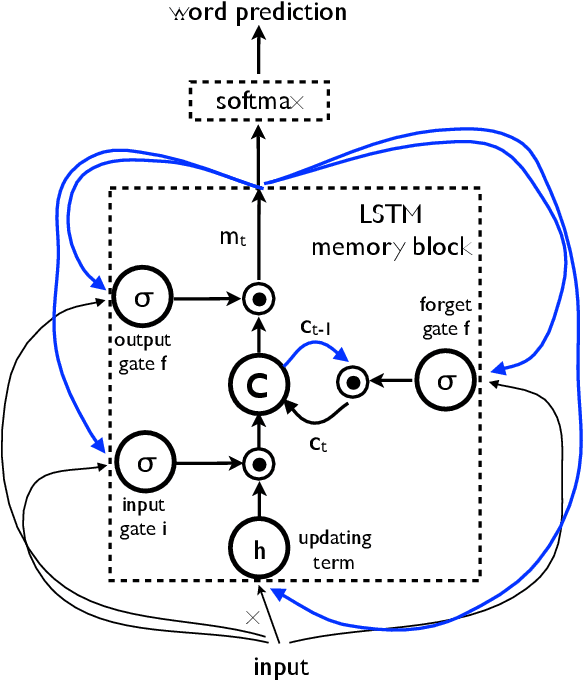
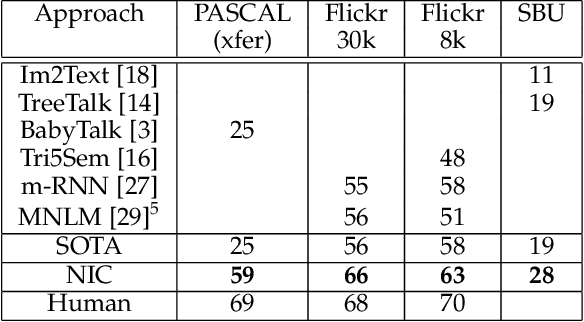
Automatically describing the content of an image is a fundamental problem in artificial intelligence that connects computer vision and natural language processing. In this paper, we present a generative model based on a deep recurrent architecture that combines recent advances in computer vision and machine translation and that can be used to generate natural sentences describing an image. The model is trained to maximize the likelihood of the target description sentence given the training image. Experiments on several datasets show the accuracy of the model and the fluency of the language it learns solely from image descriptions. Our model is often quite accurate, which we verify both qualitatively and quantitatively. Finally, given the recent surge of interest in this task, a competition was organized in 2015 using the newly released COCO dataset. We describe and analyze the various improvements we applied to our own baseline and show the resulting performance in the competition, which we won ex-aequo with a team from Microsoft Research, and provide an open source implementation in TensorFlow.
* arXiv admin note: substantial text overlap with arXiv:1411.4555
Domain Separation Networks
Aug 22, 2016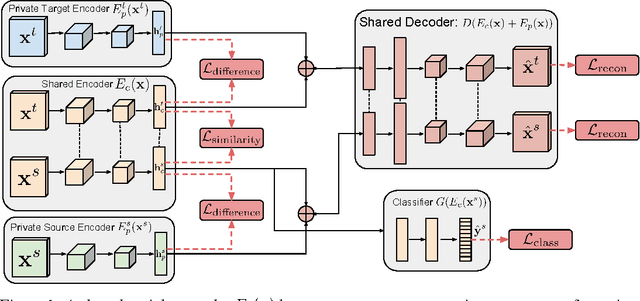
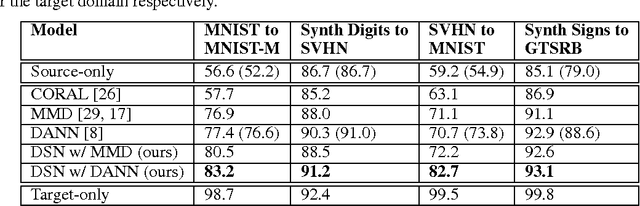
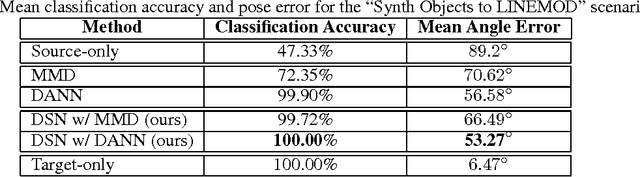

The cost of large scale data collection and annotation often makes the application of machine learning algorithms to new tasks or datasets prohibitively expensive. One approach circumventing this cost is training models on synthetic data where annotations are provided automatically. Despite their appeal, such models often fail to generalize from synthetic to real images, necessitating domain adaptation algorithms to manipulate these models before they can be successfully applied. Existing approaches focus either on mapping representations from one domain to the other, or on learning to extract features that are invariant to the domain from which they were extracted. However, by focusing only on creating a mapping or shared representation between the two domains, they ignore the individual characteristics of each domain. We suggest that explicitly modeling what is unique to each domain can improve a model's ability to extract domain-invariant features. Inspired by work on private-shared component analysis, we explicitly learn to extract image representations that are partitioned into two subspaces: one component which is private to each domain and one which is shared across domains. Our model is trained not only to perform the task we care about in the source domain, but also to use the partitioned representation to reconstruct the images from both domains. Our novel architecture results in a model that outperforms the state-of-the-art on a range of unsupervised domain adaptation scenarios and additionally produces visualizations of the private and shared representations enabling interpretation of the domain adaptation process.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Scalable, High-Quality Object Detection
Dec 09, 2015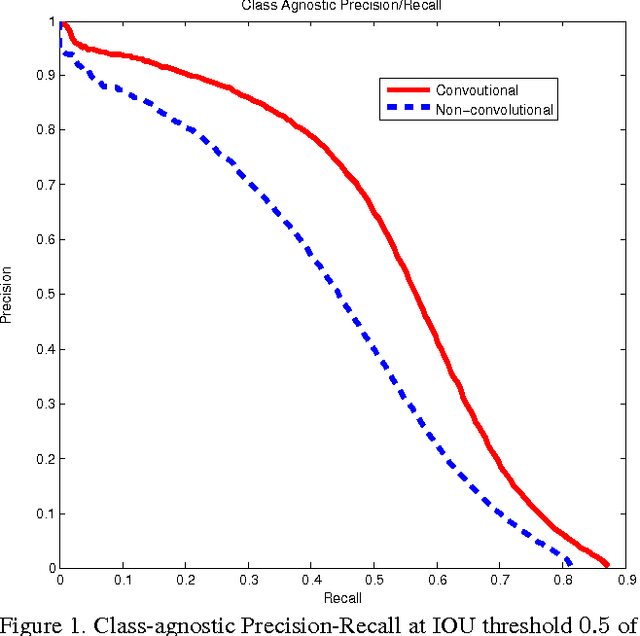
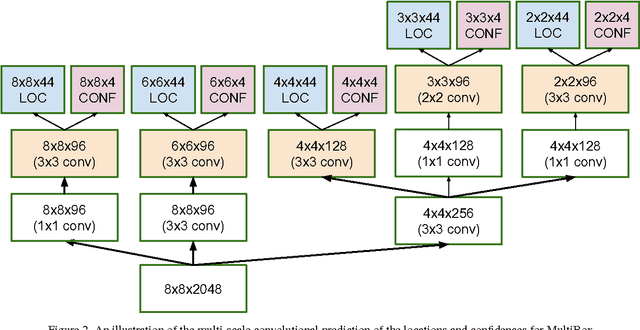
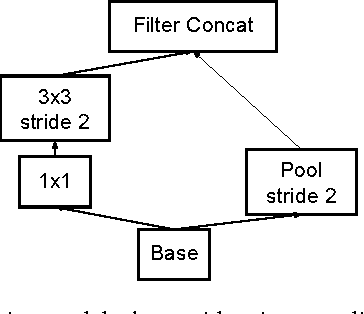

Current high-quality object detection approaches use the scheme of salience-based object proposal methods followed by post-classification using deep convolutional features. This spurred recent research in improving object proposal methods. However, domain agnostic proposal generation has the principal drawback that the proposals come unranked or with very weak ranking, making it hard to trade-off quality for running time. This raises the more fundamental question of whether high-quality proposal generation requires careful engineering or can be derived just from data alone. We demonstrate that learning-based proposal methods can effectively match the performance of hand-engineered methods while allowing for very efficient runtime-quality trade-offs. Using the multi-scale convolutional MultiBox (MSC-MultiBox) approach, we substantially advance the state-of-the-art on the ILSVRC 2014 detection challenge data set, with $0.5$ mAP for a single model and $0.52$ mAP for an ensemble of two models. MSC-Multibox significantly improves the proposal quality over its predecessor MultiBox~method: AP increases from $0.42$ to $0.53$ for the ILSVRC detection challenge. Finally, we demonstrate improved bounding-box recall compared to Multiscale Combinatorial Grouping with less proposals on the Microsoft-COCO data set.