 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Variational Graph Autoencoders for Unsupervised Cross-domain Prerequisite Chains
Oct 06, 2021
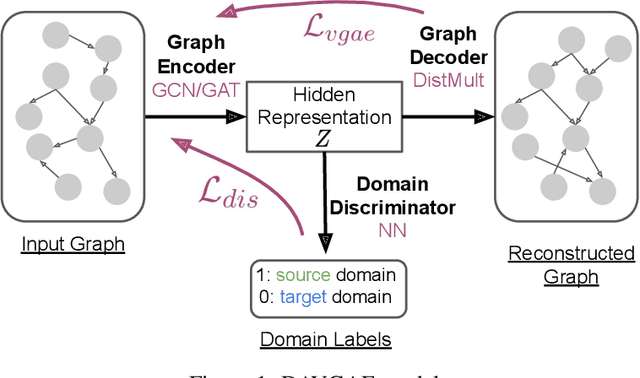
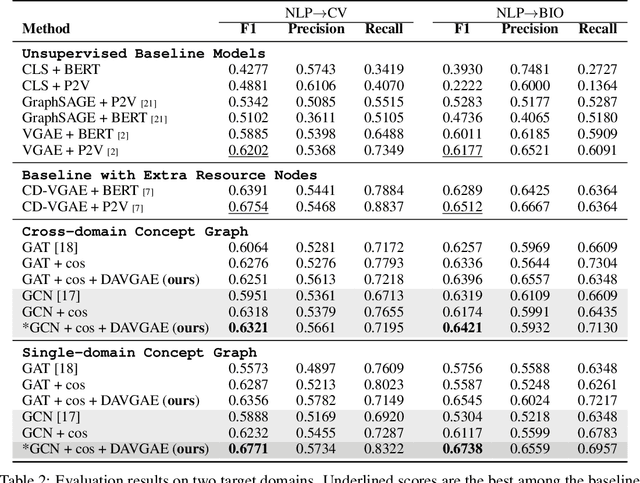
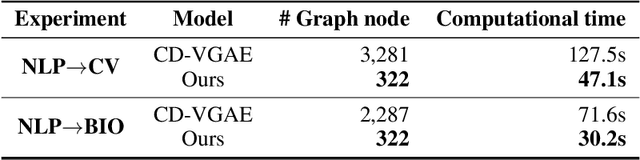
Prerequisite chain learning helps people acquire new knowledge efficiently. While people may quickly determine learning paths over concepts in a domain, finding such paths in other domains can be challenging. We introduce Domain-Adversarial Variational Graph Autoencoders (DAVGAE) to solve this cross-domain prerequisite chain learning task efficiently. Our novel model consists of a variational graph autoencoder (VGAE) and a domain discriminator. The VGAE is trained to predict concept relations through link prediction, while the domain discriminator takes both source and target domain data as input and is trained to predict domain labels. Most importantly, this method only needs simple homogeneous graphs as input, compared with the current state-of-the-art model. We evaluate our model on the LectureBankCD dataset, and results show that our model outperforms recent graph-based benchmarks while using only 1/10 of graph scale and 1/3 computation time.
Investigating Crowdsourcing Protocols for Evaluating the Factual Consistency of Summaries
Sep 21, 2021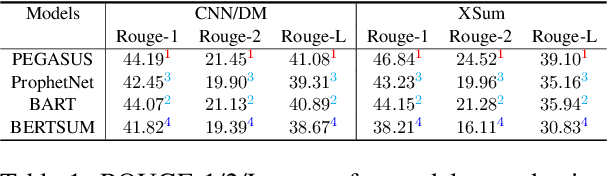
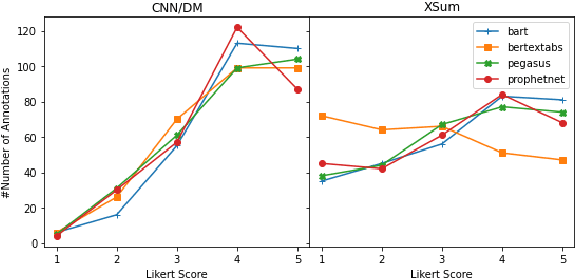
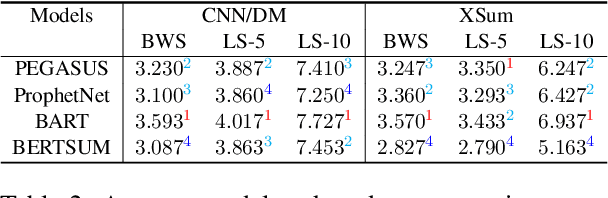
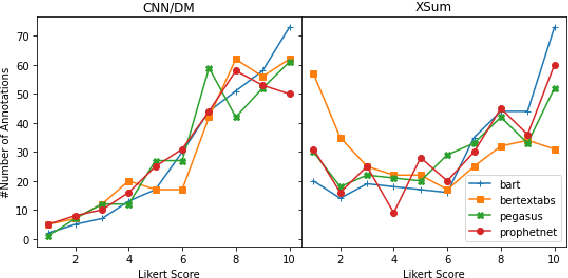
Current pre-trained models applied to summarization are prone to factual inconsistencies which either misrepresent the source text or introduce extraneous information. Thus, comparing the factual consistency of summaries is necessary as we develop improved models. However, the optimal human evaluation setup for factual consistency has not been standardized. To address this issue, we crowdsourced evaluations for factual consistency using the rating-based Likert scale and ranking-based Best-Worst Scaling protocols, on 100 articles from each of the CNN-Daily Mail and XSum datasets over four state-of-the-art models, to determine the most reliable evaluation framework. We find that ranking-based protocols offer a more reliable measure of summary quality across datasets, while the reliability of Likert ratings depends on the target dataset and the evaluation design. Our crowdsourcing templates and summary evaluations will be publicly available to facilitate future research on factual consistency in summarization.
SummerTime: Text Summarization Toolkit for Non-experts
Sep 10, 2021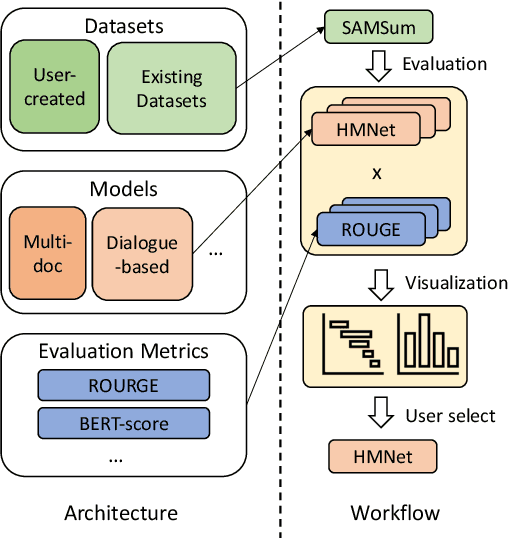
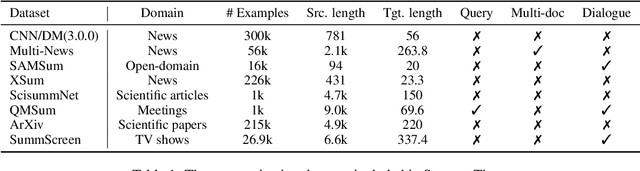

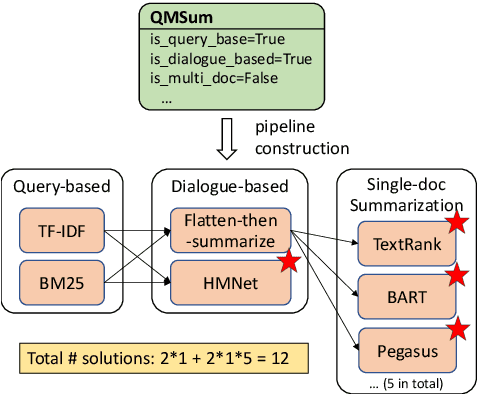
Recent advances in summarization provide models that can generate summaries of higher quality. Such models now exist for a number of summarization tasks, including query-based summarization, dialogue summarization, and multi-document summarization. While such models and tasks are rapidly growing in the research field, it has also become challenging for non-experts to keep track of them. To make summarization methods more accessible to a wider audience, we develop SummerTime by rethinking the summarization task from the perspective of an NLP non-expert. SummerTime is a complete toolkit for text summarization, including various models, datasets and evaluation metrics, for a full spectrum of summarization-related tasks. SummerTime integrates with libraries designed for NLP researchers, and enables users with easy-to-use APIs. With SummerTime, users can locate pipeline solutions and search for the best model with their own data, and visualize the differences, all with a few lines of code. We also provide explanations for models and evaluation metrics to help users understand the model behaviors and select models that best suit their needs. Our library, along with a notebook demo, is available at https://github.com/Yale-LILY/SummerTime.
An Exploratory Study on Long Dialogue Summarization: What Works and What's Next
Sep 10, 2021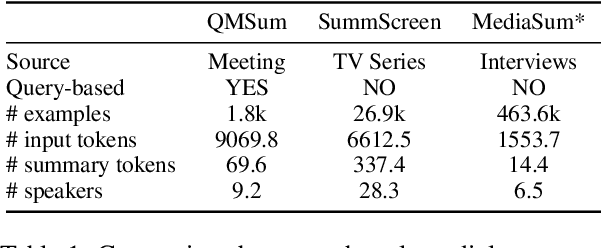
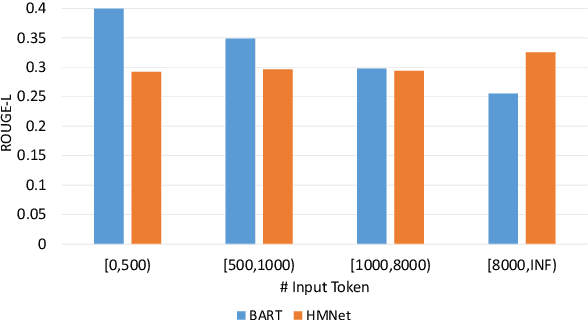
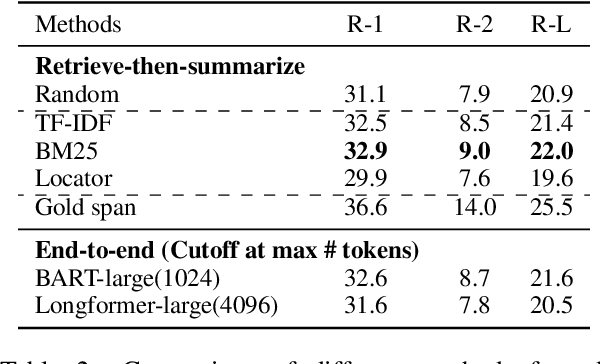
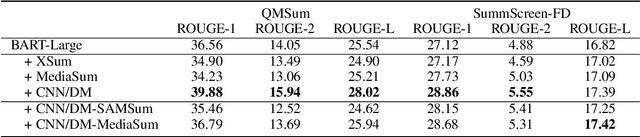
Dialogue summarization helps readers capture salient information from long conversations in meetings, interviews, and TV series. However, real-world dialogues pose a great challenge to current summarization models, as the dialogue length typically exceeds the input limits imposed by recent transformer-based pre-trained models, and the interactive nature of dialogues makes relevant information more context-dependent and sparsely distributed than news articles. In this work, we perform a comprehensive study on long dialogue summarization by investigating three strategies to deal with the lengthy input problem and locate relevant information: (1) extended transformer models such as Longformer, (2) retrieve-then-summarize pipeline models with several dialogue utterance retrieval methods, and (3) hierarchical dialogue encoding models such as HMNet. Our experimental results on three long dialogue datasets (QMSum, MediaSum, SummScreen) show that the retrieve-then-summarize pipeline models yield the best performance. We also demonstrate that the summary quality can be further improved with a stronger retrieval model and pretraining on proper external summarization datasets.
Neural Natural Language Processing for Unstructured Data in Electronic Health Records: a Review
Jul 07, 2021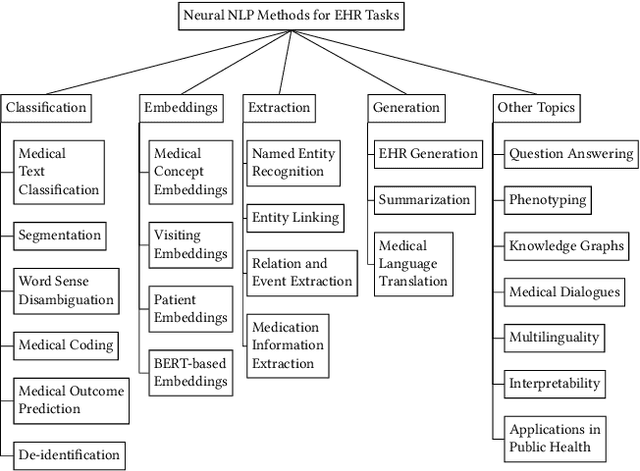
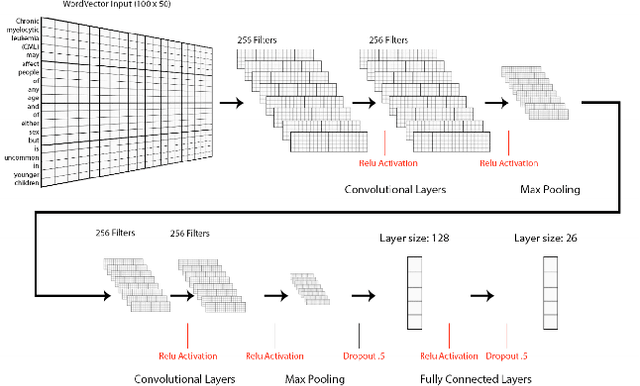
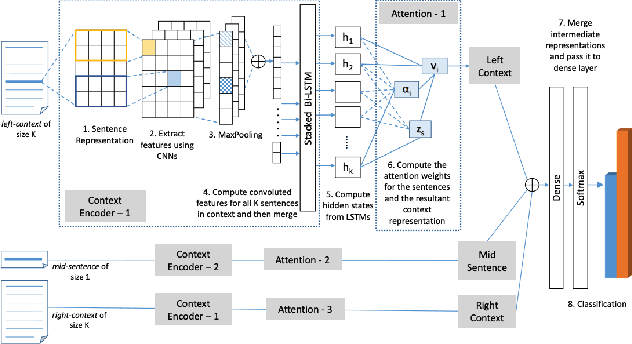

Electronic health records (EHRs), digital collections of patient healthcare events and observations, are ubiquitous in medicine and critical to healthcare delivery, operations, and research. Despite this central role, EHRs are notoriously difficult to process automatically. Well over half of the information stored within EHRs is in the form of unstructured text (e.g. provider notes, operation reports) and remains largely untapped for secondary use. Recently, however, newer neural network and deep learning approaches to Natural Language Processing (NLP) have made considerable advances, outperforming traditional statistical and rule-based systems on a variety of tasks. In this survey paper, we summarize current neural NLP methods for EHR applications. We focus on a broad scope of tasks, namely, classification and prediction, word embeddings, extraction, generation, and other topics such as question answering, phenotyping, knowledge graphs, medical dialogue, multilinguality, interpretability, etc.
DocNLI: A Large-scale Dataset for Document-level Natural Language Inference
Jun 17, 2021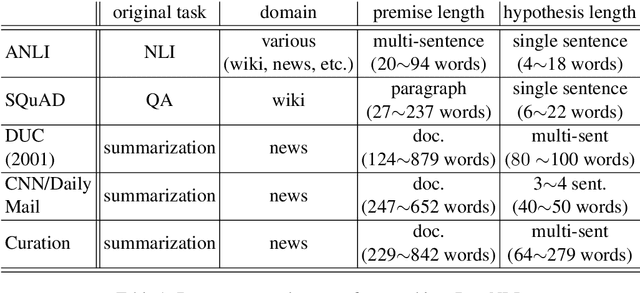

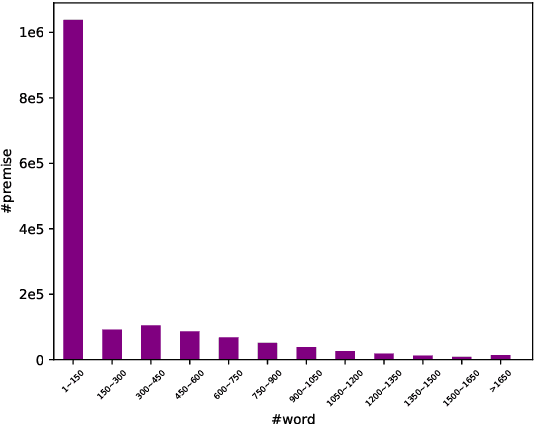

Natural language inference (NLI) is formulated as a unified framework for solving various NLP problems such as relation extraction, question answering, summarization, etc. It has been studied intensively in the past few years thanks to the availability of large-scale labeled datasets. However, most existing studies focus on merely sentence-level inference, which limits the scope of NLI's application in downstream NLP problems. This work presents DocNLI -- a newly-constructed large-scale dataset for document-level NLI. DocNLI is transformed from a broad range of NLP problems and covers multiple genres of text. The premises always stay in the document granularity, whereas the hypotheses vary in length from single sentences to passages with hundreds of words. Additionally, DocNLI has pretty limited artifacts which unfortunately widely exist in some popular sentence-level NLI datasets. Our experiments demonstrate that, even without fine-tuning, a model pretrained on DocNLI shows promising performance on popular sentence-level benchmarks, and generalizes well to out-of-domain NLP tasks that rely on inference at document granularity. Task-specific fine-tuning can bring further improvements. Data, code, and pretrained models can be found at https://github.com/salesforce/DocNLI.
ConvoSumm: Conversation Summarization Benchmark and Improved Abstractive Summarization with Argument Mining
Jun 01, 2021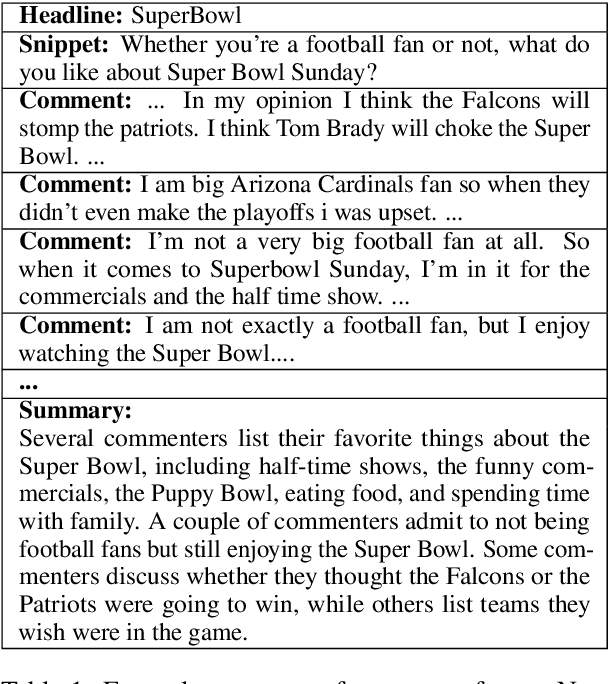
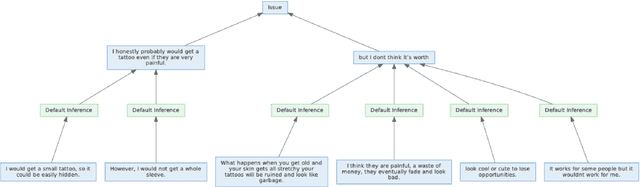


While online conversations can cover a vast amount of information in many different formats, abstractive text summarization has primarily focused on modeling solely news articles. This research gap is due, in part, to the lack of standardized datasets for summarizing online discussions. To address this gap, we design annotation protocols motivated by an issues--viewpoints--assertions framework to crowdsource four new datasets on diverse online conversation forms of news comments, discussion forums, community question answering forums, and email threads. We benchmark state-of-the-art models on our datasets and analyze characteristics associated with the data. To create a comprehensive benchmark, we also evaluate these models on widely-used conversation summarization datasets to establish strong baselines in this domain. Furthermore, we incorporate argument mining through graph construction to directly model the issues, viewpoints, and assertions present in a conversation and filter noisy input, showing comparable or improved results according to automatic and human evaluations.
Unsupervised Cross-Domain Prerequisite Chain Learning using Variational Graph Autoencoders
May 27, 2021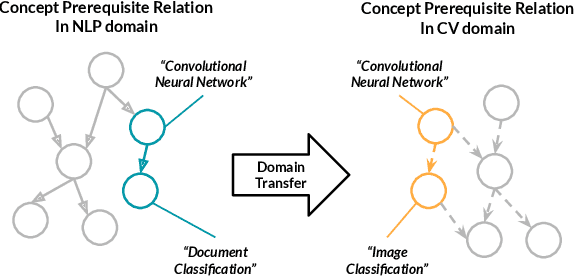
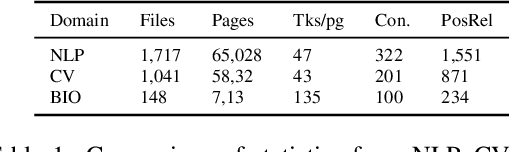
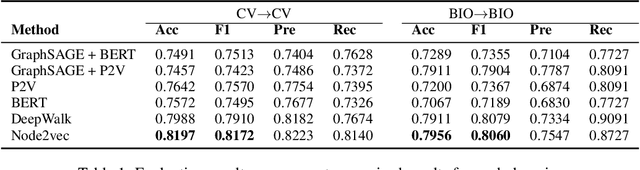
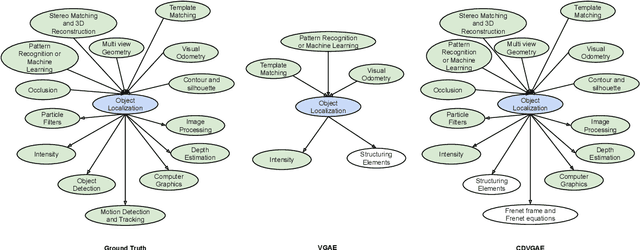
Learning prerequisite chains is an essential task for efficiently acquiring knowledge in both known and unknown domains. For example, one may be an expert in the natural language processing (NLP) domain but want to determine the best order to learn new concepts in an unfamiliar Computer Vision domain (CV). Both domains share some common concepts, such as machine learning basics and deep learning models. In this paper, we propose unsupervised cross-domain concept prerequisite chain learning using an optimized variational graph autoencoder. Our model learns to transfer concept prerequisite relations from an information-rich domain (source domain) to an information-poor domain (target domain), substantially surpassing other baseline models. Also, we expand an existing dataset by introducing two new domains: CV and Bioinformatics (BIO). The annotated data and resources, as well as the code, will be made publicly available.
BookSum: A Collection of Datasets for Long-form Narrative Summarization
May 18, 2021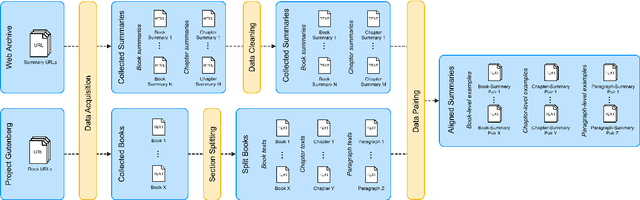
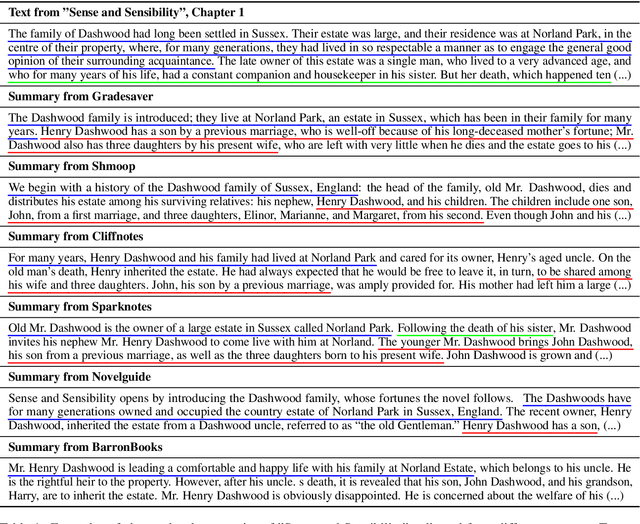
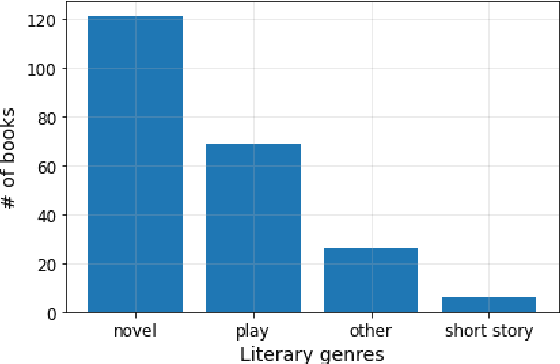
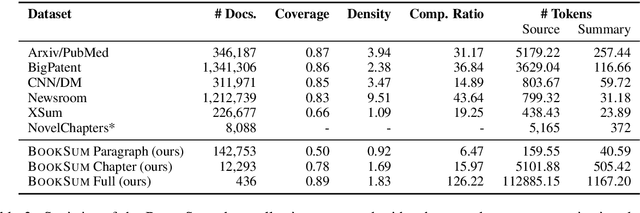
The majority of available text summarization datasets include short-form source documents that lack long-range causal and temporal dependencies, and often contain strong layout and stylistic biases. While relevant, such datasets will offer limited challenges for future generations of text summarization systems. We address these issues by introducing BookSum, a collection of datasets for long-form narrative summarization. Our dataset covers source documents from the literature domain, such as novels, plays and stories, and includes highly abstractive, human written summaries on three levels of granularity of increasing difficulty: paragraph-, chapter-, and book-level. The domain and structure of our dataset poses a unique set of challenges for summarization systems, which include: processing very long documents, non-trivial causal and temporal dependencies, and rich discourse structures. To facilitate future work, we trained and evaluated multiple extractive and abstractive summarization models as baselines for our dataset.
QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization
Apr 13, 2021
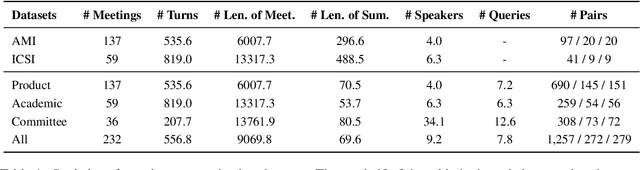
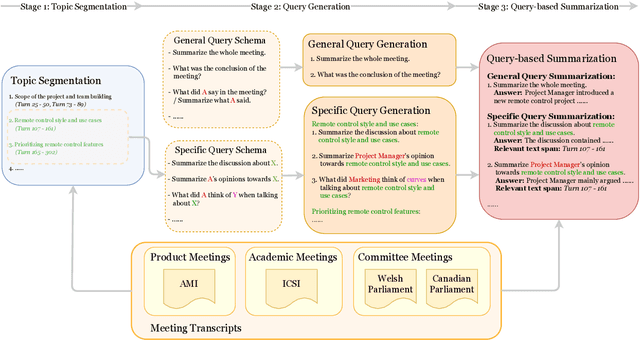
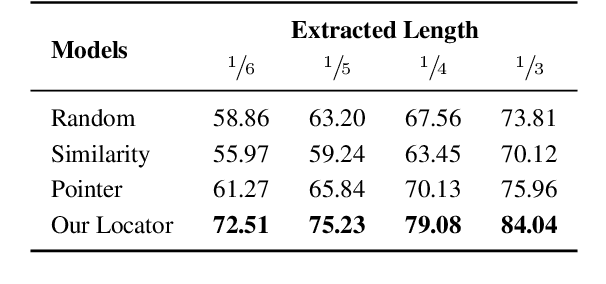
Meetings are a key component of human collaboration. As increasing numbers of meetings are recorded and transcribed, meeting summaries have become essential to remind those who may or may not have attended the meetings about the key decisions made and the tasks to be completed. However, it is hard to create a single short summary that covers all the content of a long meeting involving multiple people and topics. In order to satisfy the needs of different types of users, we define a new query-based multi-domain meeting summarization task, where models have to select and summarize relevant spans of meetings in response to a query, and we introduce QMSum, a new benchmark for this task. QMSum consists of 1,808 query-summary pairs over 232 meetings in multiple domains. Besides, we investigate a locate-then-summarize method and evaluate a set of strong summarization baselines on the task. Experimental results and manual analysis reveal that QMSum presents significant challenges in long meeting summarization for future research. Dataset is available at \url{https://github.com/Yale-LILY/QMSum}.