 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Efficacy of Adversarial Data Collection for Question Answering: Results from a Large-Scale Randomized Study
Jun 02, 2021

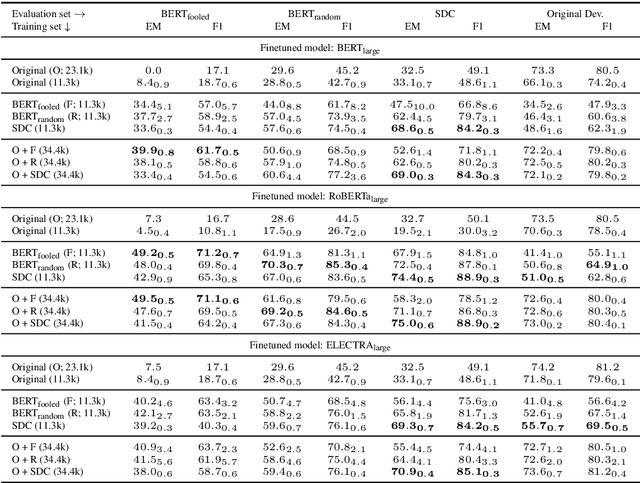

In adversarial data collection (ADC), a human workforce interacts with a model in real time, attempting to produce examples that elicit incorrect predictions. Researchers hope that models trained on these more challenging datasets will rely less on superficial patterns, and thus be less brittle. However, despite ADC's intuitive appeal, it remains unclear when training on adversarial datasets produces more robust models. In this paper, we conduct a large-scale controlled study focused on question answering, assigning workers at random to compose questions either (i) adversarially (with a model in the loop); or (ii) in the standard fashion (without a model). Across a variety of models and datasets, we find that models trained on adversarial data usually perform better on other adversarial datasets but worse on a diverse collection of out-of-domain evaluation sets. Finally, we provide a qualitative analysis of adversarial (vs standard) data, identifying key differences and offering guidance for future research.
True Few-Shot Learning with Language Models
May 24, 2021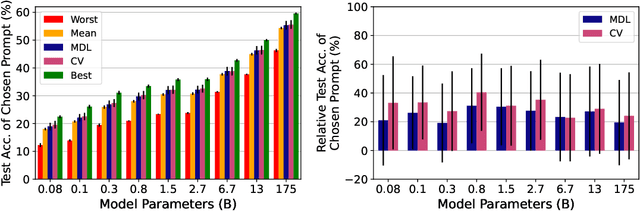
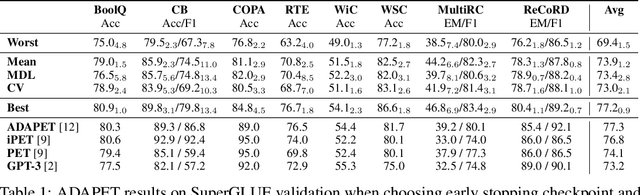
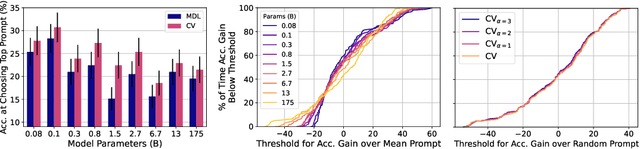

Pretrained language models (LMs) perform well on many tasks even when learning from a few examples, but prior work uses many held-out examples to tune various aspects of learning, such as hyperparameters, training objectives, and natural language templates ("prompts"). Here, we evaluate the few-shot ability of LMs when such held-out examples are unavailable, a setting we call true few-shot learning. We test two model selection criteria, cross-validation and minimum description length, for choosing LM prompts and hyperparameters in the true few-shot setting. On average, both marginally outperform random selection and greatly underperform selection based on held-out examples. Moreover, selection criteria often prefer models that perform significantly worse than randomly-selected ones. We find similar results even when taking into account our uncertainty in a model's true performance during selection, as well as when varying the amount of computation and number of examples used for selection. Overall, our findings suggest that prior work significantly overestimated the true few-shot ability of LMs given the difficulty of few-shot model selection.
Dynaboard: An Evaluation-As-A-Service Platform for Holistic Next-Generation Benchmarking
May 21, 2021
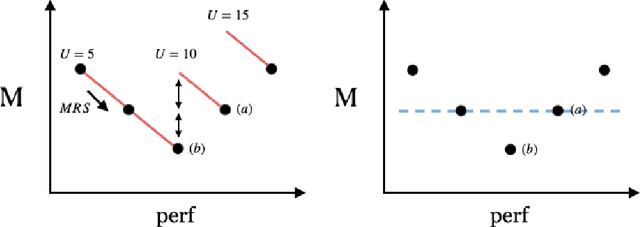
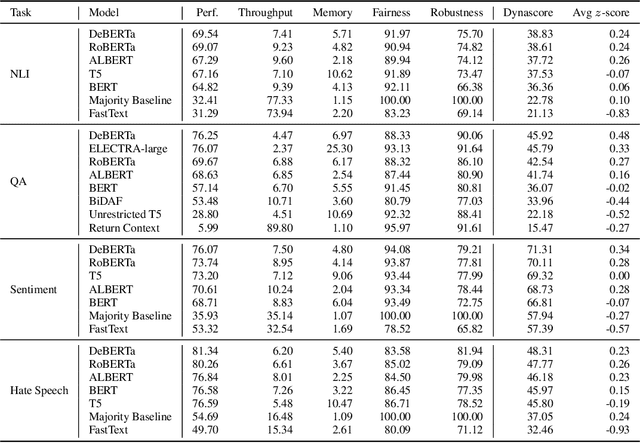
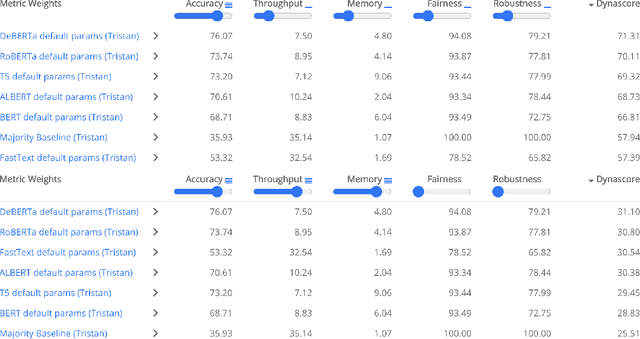
We introduce Dynaboard, an evaluation-as-a-service framework for hosting benchmarks and conducting holistic model comparison, integrated with the Dynabench platform. Our platform evaluates NLP models directly instead of relying on self-reported metrics or predictions on a single dataset. Under this paradigm, models are submitted to be evaluated in the cloud, circumventing the issues of reproducibility, accessibility, and backwards compatibility that often hinder benchmarking in NLP. This allows users to interact with uploaded models in real time to assess their quality, and permits the collection of additional metrics such as memory use, throughput, and robustness, which -- despite their importance to practitioners -- have traditionally been absent from leaderboards. On each task, models are ranked according to the Dynascore, a novel utility-based aggregation of these statistics, which users can customize to better reflect their preferences, placing more/less weight on a particular axis of evaluation or dataset. As state-of-the-art NLP models push the limits of traditional benchmarks, Dynaboard offers a standardized solution for a more diverse and comprehensive evaluation of model quality.
Improving Question Answering Model Robustness with Synthetic Adversarial Data Generation
Apr 18, 2021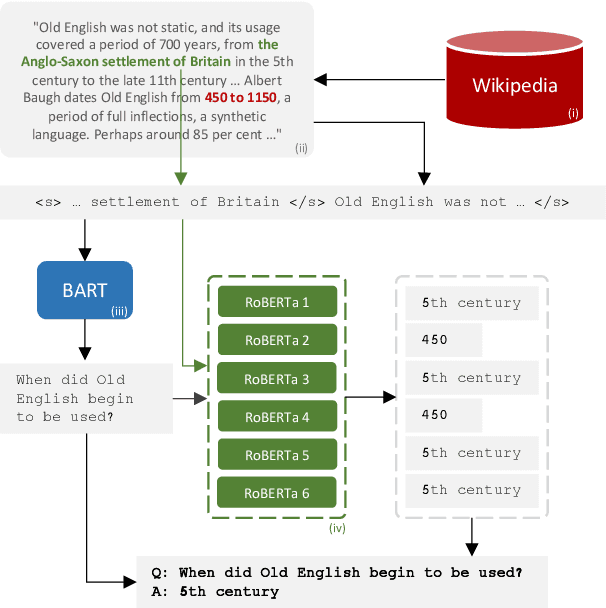
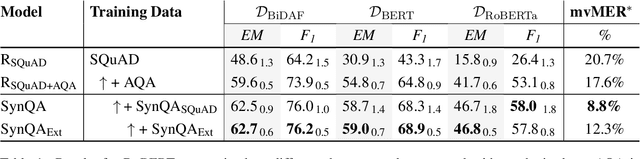
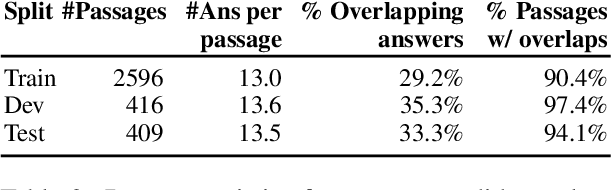
Despite the availability of very large datasets and pretrained models, state-of-the-art question answering models remain susceptible to a variety of adversarial attacks and are still far from obtaining human-level language understanding. One proposed way forward is dynamic adversarial data collection, in which a human annotator attempts to create examples for which a model-in-the-loop fails. However, this approach comes at a higher cost per sample and slower pace of annotation, as model-adversarial data requires more annotator effort to generate. In this work, we investigate several answer selection, question generation, and filtering methods that form a synthetic adversarial data generation pipeline that takes human-generated adversarial samples and unannotated text to create synthetic question-answer pairs. Models trained on both synthetic and human-generated data outperform models not trained on synthetic adversarial data, and obtain state-of-the-art results on the AdversarialQA dataset with overall performance gains of 3.7F1. Furthermore, we find that training on the synthetic adversarial data improves model generalisation across domains for non-adversarial data, demonstrating gains on 9 of the 12 datasets for MRQA. Lastly, we find that our models become considerably more difficult to beat by human adversaries, with a drop in macro-averaged validated model error rate from 17.6% to 8.8% when compared to non-augmented models.
Cross-Modal Retrieval Augmentation for Multi-Modal Classification
Apr 16, 2021
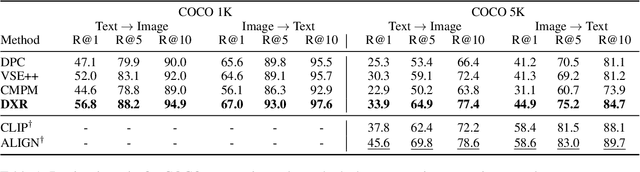
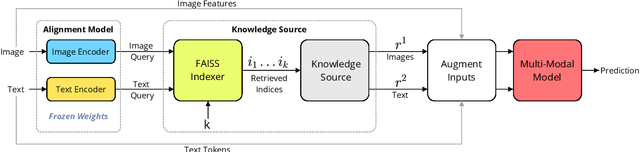
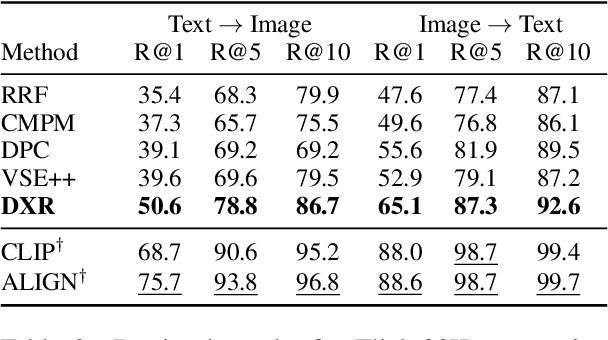
Recent advances in using retrieval components over external knowledge sources have shown impressive results for a variety of downstream tasks in natural language processing. Here, we explore the use of unstructured external knowledge sources of images and their corresponding captions for improving visual question answering (VQA). First, we train a novel alignment model for embedding images and captions in the same space, which achieves substantial improvement in performance on image-caption retrieval w.r.t. similar methods. Second, we show that retrieval-augmented multi-modal transformers using the trained alignment model improve results on VQA over strong baselines. We further conduct extensive experiments to establish the promise of this approach, and examine novel applications for inference time such as hot-swapping indices.
Gradient-based Adversarial Attacks against Text Transformers
Apr 15, 2021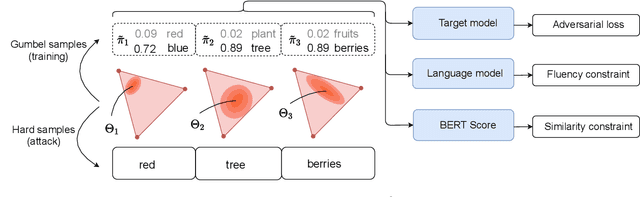
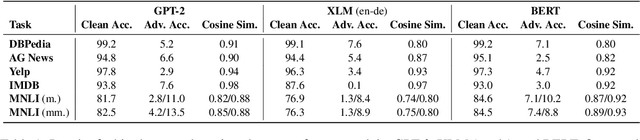

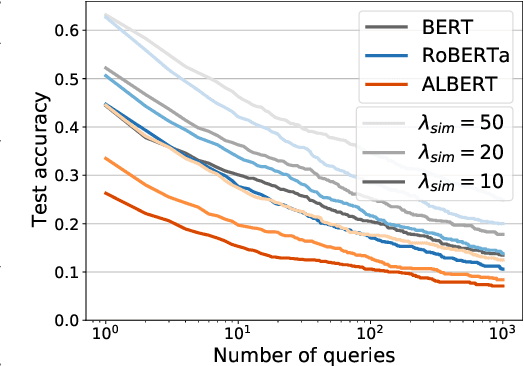
We propose the first general-purpose gradient-based attack against transformer models. Instead of searching for a single adversarial example, we search for a distribution of adversarial examples parameterized by a continuous-valued matrix, hence enabling gradient-based optimization. We empirically demonstrate that our white-box attack attains state-of-the-art attack performance on a variety of natural language tasks. Furthermore, we show that a powerful black-box transfer attack, enabled by sampling from the adversarial distribution, matches or exceeds existing methods, while only requiring hard-label outputs.
Retrieval Augmentation Reduces Hallucination in Conversation
Apr 15, 2021
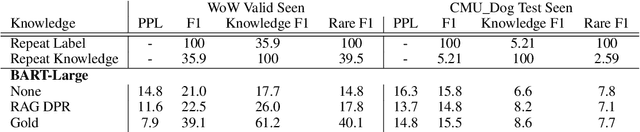
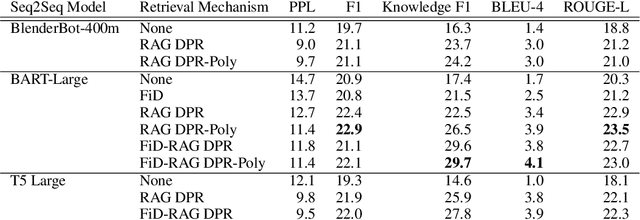
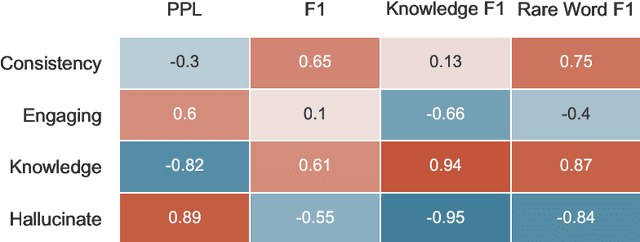
Despite showing increasingly human-like conversational abilities, state-of-the-art dialogue models often suffer from factual incorrectness and hallucination of knowledge (Roller et al., 2020). In this work we explore the use of neural-retrieval-in-the-loop architectures - recently shown to be effective in open-domain QA (Lewis et al., 2020b; Izacard and Grave, 2020) - for knowledge-grounded dialogue, a task that is arguably more challenging as it requires querying based on complex multi-turn dialogue context and generating conversationally coherent responses. We study various types of architectures with multiple components - retrievers, rankers, and encoder-decoders - with the goal of maximizing knowledgeability while retaining conversational ability. We demonstrate that our best models obtain state-of-the-art performance on two knowledge-grounded conversational tasks. The models exhibit open-domain conversational capabilities, generalize effectively to scenarios not within the training data, and, as verified by human evaluations, substantially reduce the well-known problem of knowledge hallucination in state-of-the-art chatbots.
Masked Language Modeling and the Distributional Hypothesis: Order Word Matters Pre-training for Little
Apr 14, 2021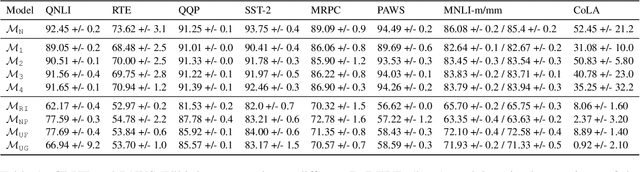
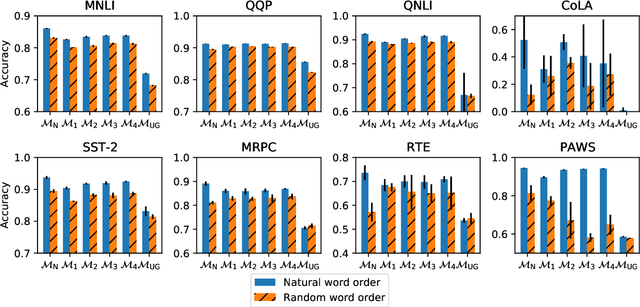
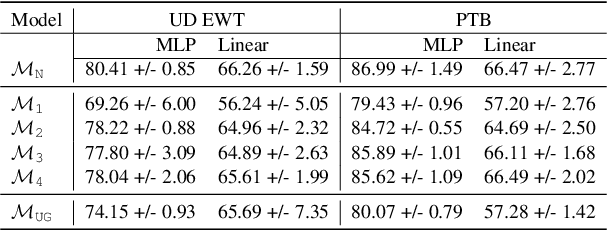
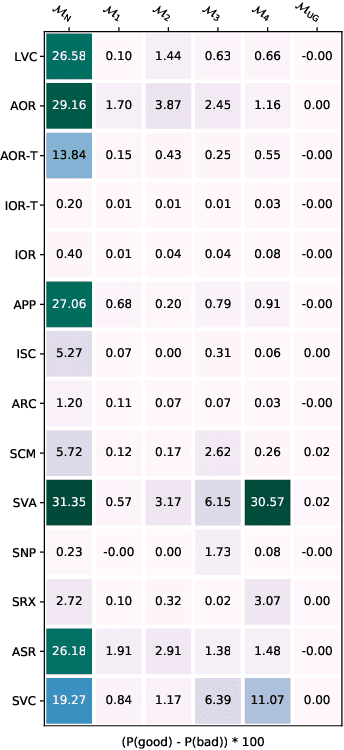
A possible explanation for the impressive performance of masked language model (MLM) pre-training is that such models have learned to represent the syntactic structures prevalent in classical NLP pipelines. In this paper, we propose a different explanation: MLMs succeed on downstream tasks almost entirely due to their ability to model higher-order word co-occurrence statistics. To demonstrate this, we pre-train MLMs on sentences with randomly shuffled word order, and show that these models still achieve high accuracy after fine-tuning on many downstream tasks -- including on tasks specifically designed to be challenging for models that ignore word order. Our models perform surprisingly well according to some parametric syntactic probes, indicating possible deficiencies in how we test representations for syntactic information. Overall, our results show that purely distributional information largely explains the success of pre-training, and underscore the importance of curating challenging evaluation datasets that require deeper linguistic knowledge.
Dynabench: Rethinking Benchmarking in NLP
Apr 07, 2021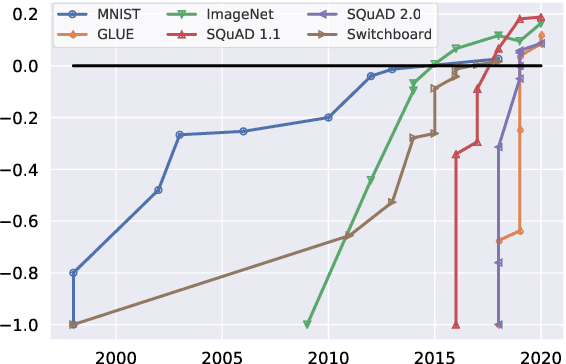
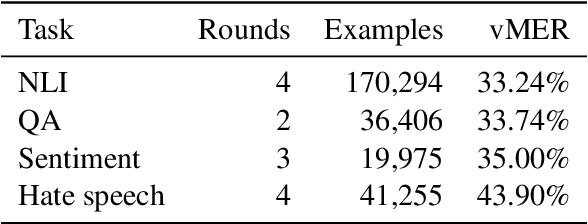
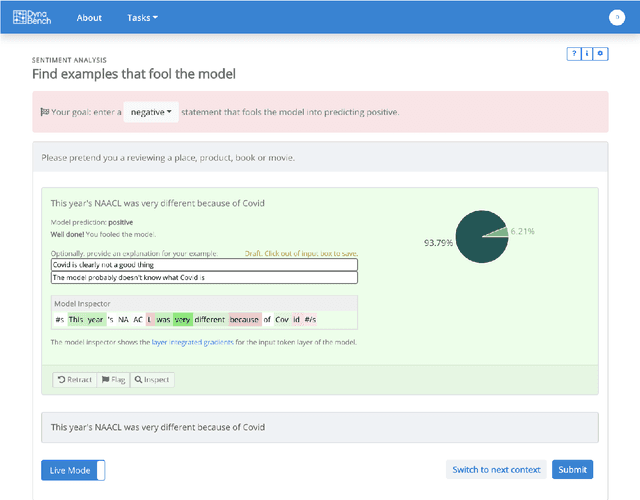
We introduce Dynabench, an open-source platform for dynamic dataset creation and model benchmarking. Dynabench runs in a web browser and supports human-and-model-in-the-loop dataset creation: annotators seek to create examples that a target model will misclassify, but that another person will not. In this paper, we argue that Dynabench addresses a critical need in our community: contemporary models quickly achieve outstanding performance on benchmark tasks but nonetheless fail on simple challenge examples and falter in real-world scenarios. With Dynabench, dataset creation, model development, and model assessment can directly inform each other, leading to more robust and informative benchmarks. We report on four initial NLP tasks, illustrating these concepts and highlighting the promise of the platform, and address potential objections to dynamic benchmarking as a new standard for the field.
Quasi-Equivalence Discovery for Zero-Shot Emergent Communication
Mar 14, 2021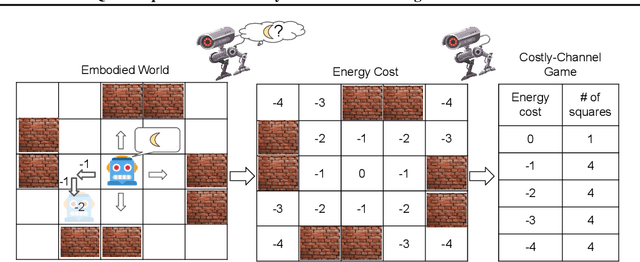
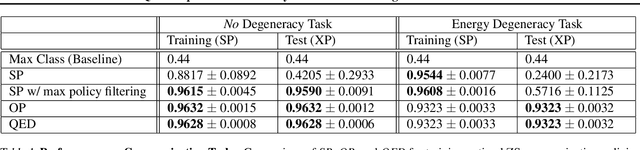

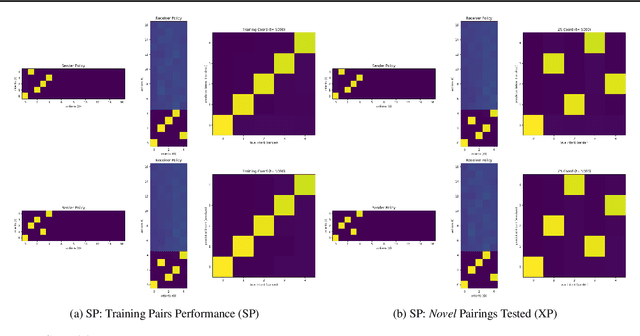
Effective communication is an important skill for enabling information exchange in multi-agent settings and emergent communication is now a vibrant field of research, with common settings involving discrete cheap-talk channels. Since, by definition, these settings involve arbitrary encoding of information, typically they do not allow for the learned protocols to generalize beyond training partners. In contrast, in this work, we present a novel problem setting and the Quasi-Equivalence Discovery (QED) algorithm that allows for zero-shot coordination (ZSC), i.e., discovering protocols that can generalize to independently trained agents. Real world problem settings often contain costly communication channels, e.g., robots have to physically move their limbs, and a non-uniform distribution over intents. We show that these two factors lead to unique optimal ZSC policies in referential games, where agents use the energy cost of the messages to communicate intent. Other-Play was recently introduced for learning optimal ZSC policies, but requires prior access to the symmetries of the problem. Instead, QED can iteratively discovers the symmetries in this setting and converges to the optimal ZSC policy.