 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMephisto: A Framework for Portable, Reproducible, and Iterative Crowdsourcing
Jan 12, 2023
We introduce Mephisto, a framework to make crowdsourcing for research more reproducible, transparent, and collaborative. Mephisto provides abstractions that cover a broad set of task designs and data collection workflows, and provides a simple user experience to make best-practices easy defaults. In this whitepaper we discuss the current state of data collection and annotation in ML research, establish the motivation for building a shared framework to enable researchers to create and open-source data collection and annotation tools as part of their publication, and outline a set of suggested requirements for a system to facilitate these goals. We then step through our resolution in Mephisto, explaining the abstractions we use, our design decisions around the user experience, and share implementation details and where they align with the original motivations. We also discuss current limitations, as well as future work towards continuing to deliver on the framework's initial goals. Mephisto is available as an open source project, and its documentation can be found at www.mephisto.ai.
Dynabench: Rethinking Benchmarking in NLP
Apr 07, 2021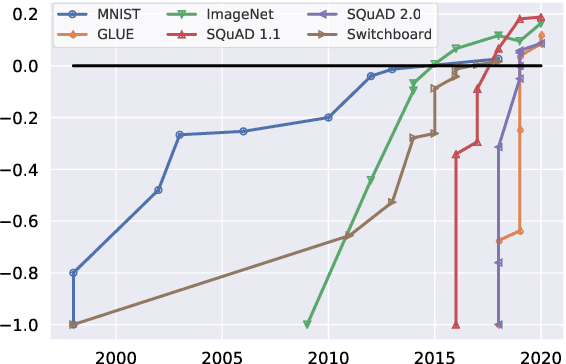
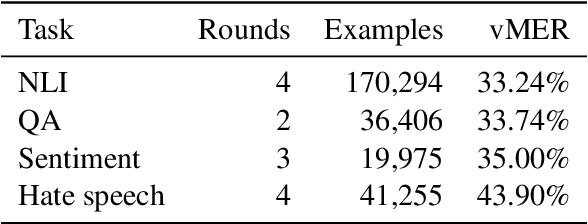
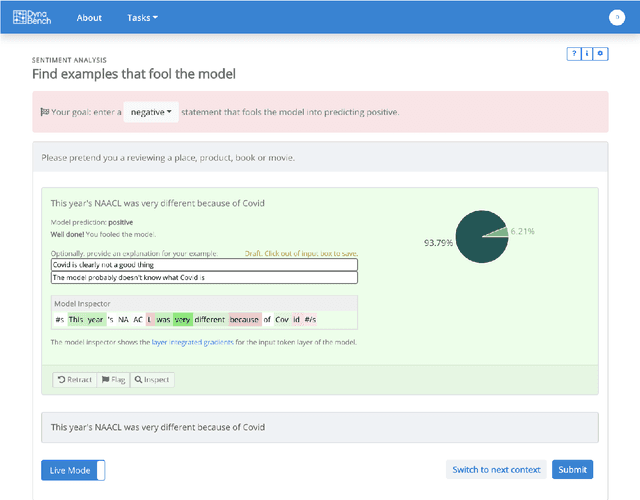
We introduce Dynabench, an open-source platform for dynamic dataset creation and model benchmarking. Dynabench runs in a web browser and supports human-and-model-in-the-loop dataset creation: annotators seek to create examples that a target model will misclassify, but that another person will not. In this paper, we argue that Dynabench addresses a critical need in our community: contemporary models quickly achieve outstanding performance on benchmark tasks but nonetheless fail on simple challenge examples and falter in real-world scenarios. With Dynabench, dataset creation, model development, and model assessment can directly inform each other, leading to more robust and informative benchmarks. We report on four initial NLP tasks, illustrating these concepts and highlighting the promise of the platform, and address potential objections to dynamic benchmarking as a new standard for the field.
Open-Domain Conversational Agents: Current Progress, Open Problems, and Future Directions
Jul 13, 2020We present our view of what is necessary to build an engaging open-domain conversational agent: covering the qualities of such an agent, the pieces of the puzzle that have been built so far, and the gaping holes we have not filled yet. We present a biased view, focusing on work done by our own group, while citing related work in each area. In particular, we discuss in detail the properties of continual learning, providing engaging content, and being well-behaved -- and how to measure success in providing them. We end with a discussion of our experience and learnings, and our recommendations to the community.
The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes
Jun 08, 2020
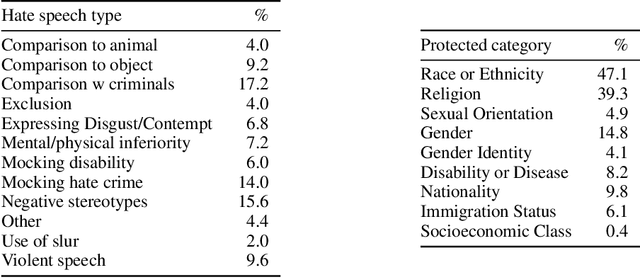
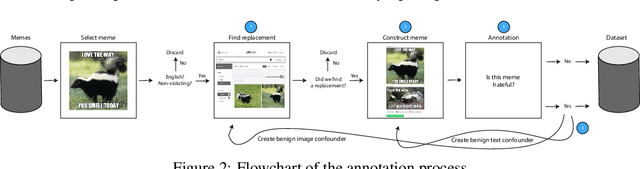

This work proposes a new challenge set for multimodal classification, focusing on detecting hate speech in multimodal memes. It is constructed such that unimodal models struggle and only multimodal models can succeed: difficult examples ("benign confounders") are added to the dataset to make it hard to rely on unimodal signals. The task requires subtle reasoning, yet is straightforward to evaluate as a binary classification problem. We provide baseline performance numbers for unimodal models, as well as for multimodal models with various degrees of sophistication. We find that state-of-the-art methods perform poorly compared to humans (64.73% vs. 84.7% accuracy), illustrating the difficulty of the task and highlighting the challenge that this important problem poses to the community.
Generating Interactive Worlds with Text
Dec 04, 2019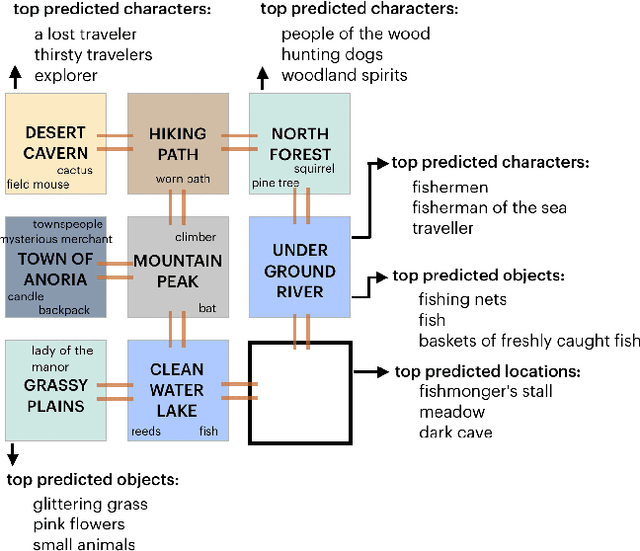
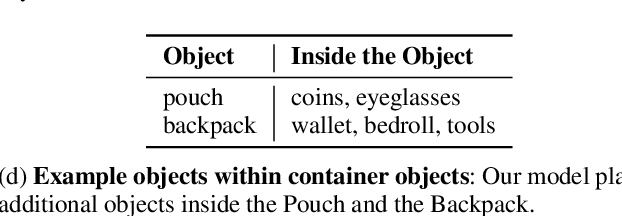
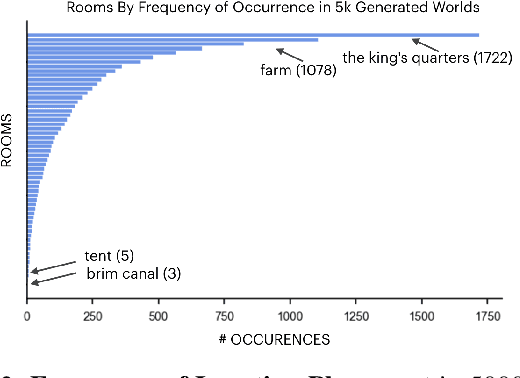
Procedurally generating cohesive and interesting game environments is challenging and time-consuming. In order for the relationships between the game elements to be natural, common-sense has to be encoded into arrangement of the elements. In this work, we investigate a machine learning approach for world creation using content from the multi-player text adventure game environment LIGHT. We introduce neural network based models to compositionally arrange locations, characters, and objects into a coherent whole. In addition to creating worlds based on existing elements, our models can generate new game content. Humans can also leverage our models to interactively aid in worldbuilding. We show that the game environments created with our approach are cohesive, diverse, and preferred by human evaluators compared to other machine learning based world construction algorithms.