 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving the Human Subjects Status of Machine Learning's Crowdworkers
Jun 08, 2022
In recent years, machine learning (ML) has come to rely more heavily on crowdworkers, both for building bigger datasets and for addressing research questions requiring human interaction or judgment. Owing to the diverse tasks performed by crowdworkers, and the myriad ways the resulting datasets are used, it can be difficult to determine when these individuals are best thought of as workers, versus as human subjects. These difficulties are compounded by conflicting policies, with some institutions and researchers treating all ML crowdwork as human subjects research, and other institutions holding that ML crowdworkers rarely constitute human subjects. Additionally, few ML papers involving crowdwork mention IRB oversight, raising the prospect that many might not be in compliance with ethical and regulatory requirements. In this paper, we focus on research in natural language processing to investigate the appropriate designation of crowdsourcing studies and the unique challenges that ML research poses for research oversight. Crucially, under the U.S. Common Rule, these judgments hinge on determinations of "aboutness", both whom (or what) the collected data is about and whom (or what) the analysis is about. We highlight two challenges posed by ML: (1) the same set of workers can serve multiple roles and provide many sorts of information; and (2) compared to the life sciences and social sciences, ML research tends to embrace a dynamic workflow, where research questions are seldom stated ex ante and data sharing opens the door for future studies to ask questions about different targets from the original study. In particular, our analysis exposes a potential loophole in the Common Rule, where researchers can elude research ethics oversight by splitting data collection and analysis into distinct studies. We offer several policy recommendations to address these concerns.
Practical Benefits of Feature Feedback Under Distribution Shift
Oct 14, 2021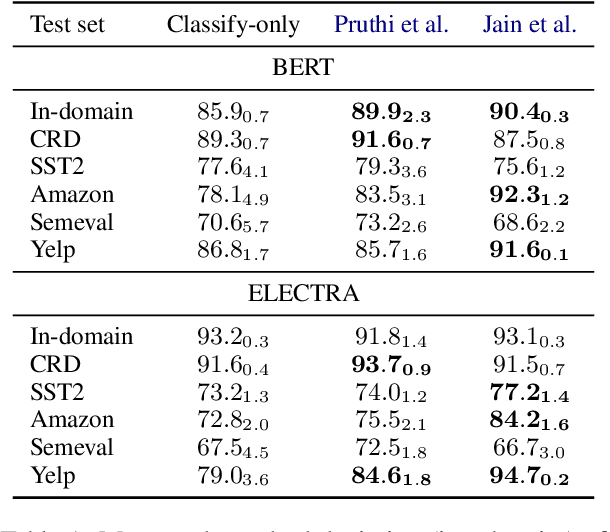
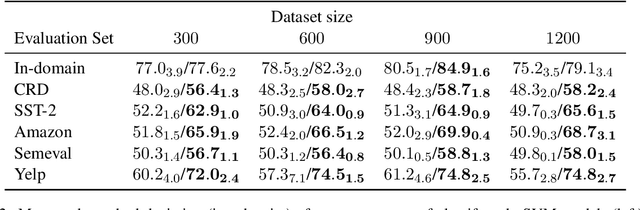
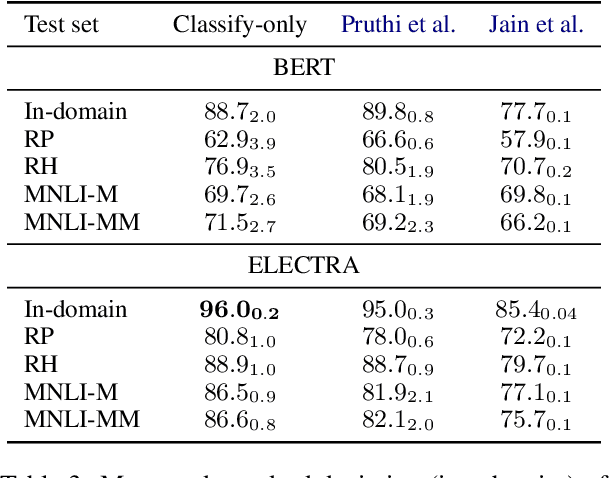
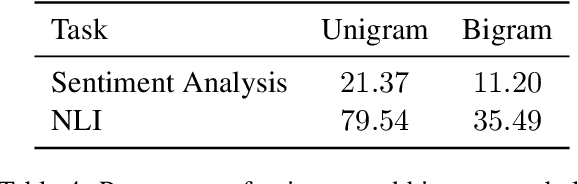
In attempts to develop sample-efficient algorithms, researcher have explored myriad mechanisms for collecting and exploiting feature feedback, auxiliary annotations provided for training (but not test) instances that highlight salient evidence. Examples include bounding boxes around objects and salient spans in text. Despite its intuitive appeal, feature feedback has not delivered significant gains in practical problems as assessed on iid holdout sets. However, recent works on counterfactually augmented data suggest an alternative benefit of supplemental annotations: lessening sensitivity to spurious patterns and consequently delivering gains in out-of-domain evaluations. Inspired by these findings, we hypothesize that while the numerous existing methods for incorporating feature feedback have delivered negligible in-sample gains, they may nevertheless generalize better out-of-domain. In experiments addressing sentiment analysis, we show that feature feedback methods perform significantly better on various natural out-of-domain datasets even absent differences on in-domain evaluation. By contrast, on natural language inference tasks, performance remains comparable. Finally, we compare those tasks where feature feedback does (and does not) help.
On the Efficacy of Adversarial Data Collection for Question Answering: Results from a Large-Scale Randomized Study
Jun 02, 2021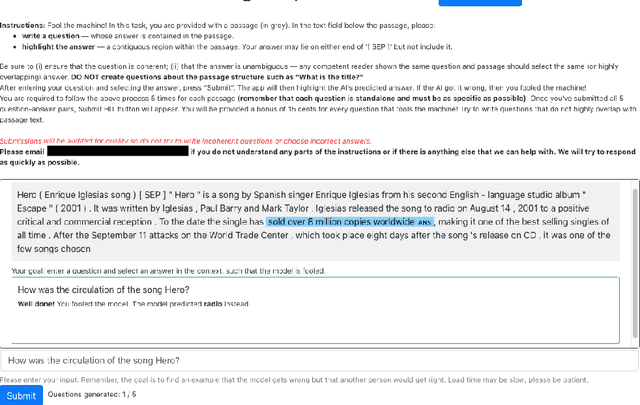

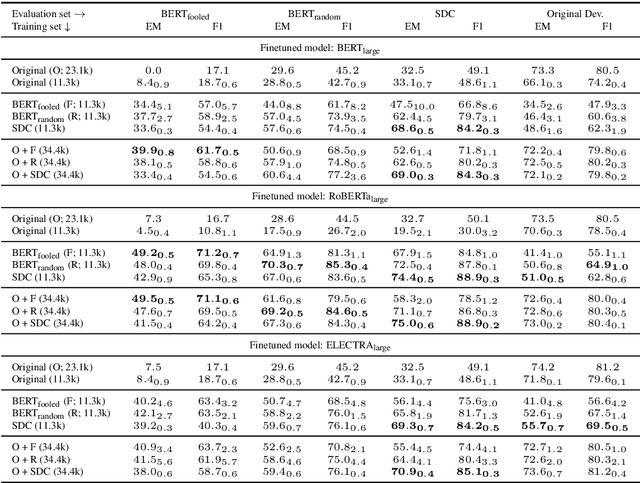

In adversarial data collection (ADC), a human workforce interacts with a model in real time, attempting to produce examples that elicit incorrect predictions. Researchers hope that models trained on these more challenging datasets will rely less on superficial patterns, and thus be less brittle. However, despite ADC's intuitive appeal, it remains unclear when training on adversarial datasets produces more robust models. In this paper, we conduct a large-scale controlled study focused on question answering, assigning workers at random to compose questions either (i) adversarially (with a model in the loop); or (ii) in the standard fashion (without a model). Across a variety of models and datasets, we find that models trained on adversarial data usually perform better on other adversarial datasets but worse on a diverse collection of out-of-domain evaluation sets. Finally, we provide a qualitative analysis of adversarial (vs standard) data, identifying key differences and offering guidance for future research.
Dynabench: Rethinking Benchmarking in NLP
Apr 07, 2021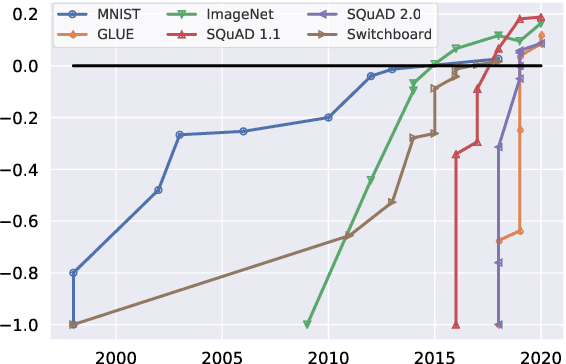
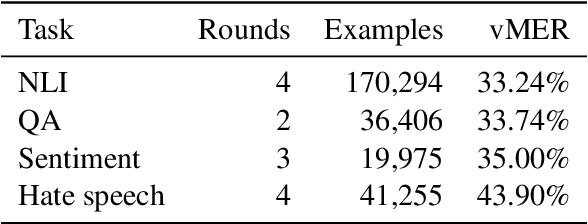
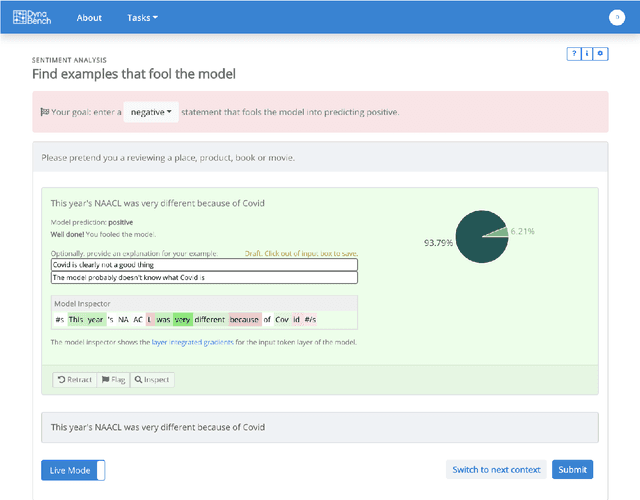
We introduce Dynabench, an open-source platform for dynamic dataset creation and model benchmarking. Dynabench runs in a web browser and supports human-and-model-in-the-loop dataset creation: annotators seek to create examples that a target model will misclassify, but that another person will not. In this paper, we argue that Dynabench addresses a critical need in our community: contemporary models quickly achieve outstanding performance on benchmark tasks but nonetheless fail on simple challenge examples and falter in real-world scenarios. With Dynabench, dataset creation, model development, and model assessment can directly inform each other, leading to more robust and informative benchmarks. We report on four initial NLP tasks, illustrating these concepts and highlighting the promise of the platform, and address potential objections to dynamic benchmarking as a new standard for the field.
Explaining The Efficacy of Counterfactually-Augmented Data
Oct 06, 2020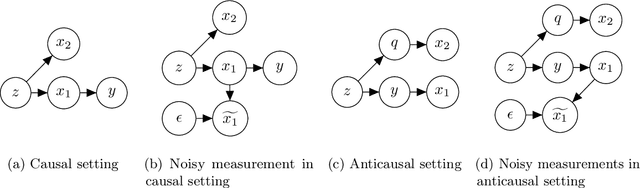
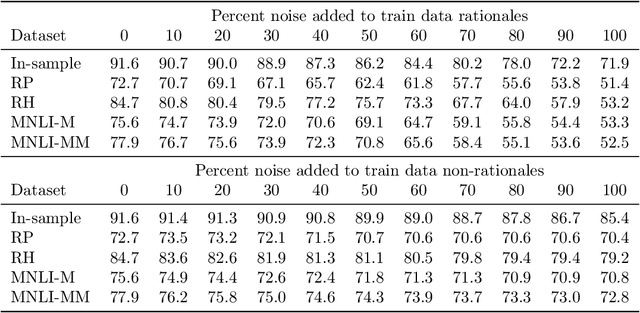
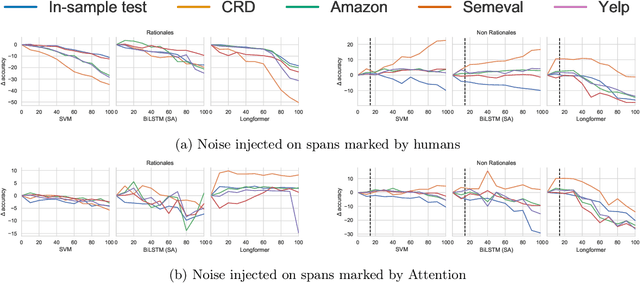
In attempts to produce machine learning models less reliant on spurious patterns in training data, researchers have recently proposed a human-in-the-loop process for generating counterfactually augmented datasets. As applied in NLP, given some documents and their (initial) labels, humans are tasked with revising the text to make a (given) counterfactual label applicable. Importantly, the instructions prohibit edits that are not necessary to flip the applicable label. Models trained on the augmented (original and revised) data have been shown to rely less on semantically irrelevant words and to generalize better out-of-domain. While this work draws on causal thinking, casting edits as interventions and relying on human understanding to assess outcomes, the underlying causal model is not clear nor are the principles underlying the observed improvements in out-of-domain evaluation. In this paper, we explore a toy analog, using linear Gaussian models. Our analysis reveals interesting relationships between causal models, measurement noise, out-of-domain generalization, and reliance on spurious signals. Interestingly our analysis suggests that data corrupted by adding noise to causal features will degrade out-of-domain performance, while noise added to non-causal features may make models more robust out-of-domain. This analysis yields interesting insights that help to explain the efficacy of counterfactually augmented data. Finally, we present a large-scale empirical study that supports this hypothesis.
Learning the Difference that Makes a Difference with Counterfactually-Augmented Data
Sep 26, 2019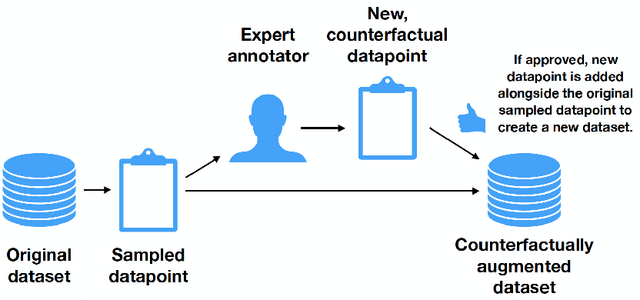
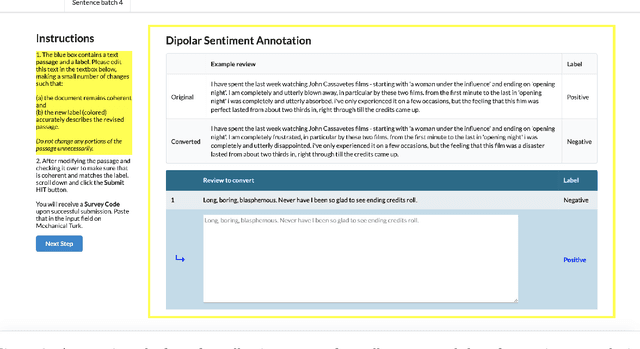

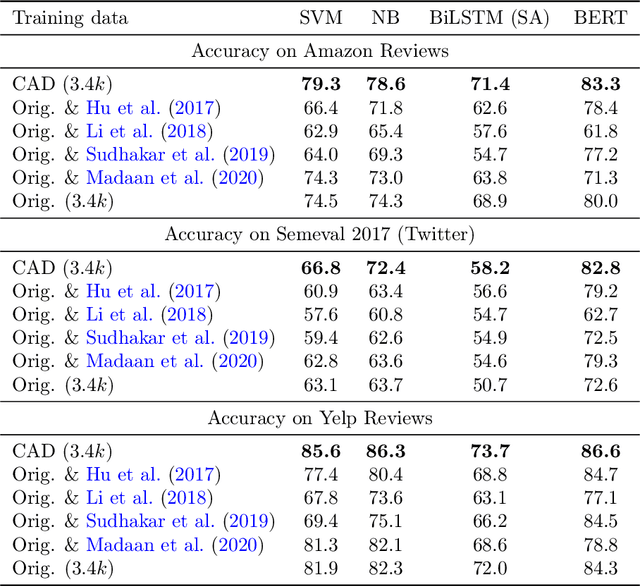
Despite alarm over the reliance of machine learning systems on so-called spurious patterns in training data, the term lacks coherent meaning in standard statistical frameworks. However, the language of causality offers clarity: spurious associations are those due to a common cause (confounding) vs direct or indirect effects. In this paper, we focus on NLP, introducing methods and resources for training models insensitive to spurious patterns. Given documents and their initial labels, we task humans with revise each document to accord with a counterfactual target label, asking that the revised documents be internally coherent while avoiding any gratuitous changes. Interestingly, on sentiment analysis and natural language inference tasks, classifiers trained on original data fail on their counterfactually-revised counterparts and vice versa. Classifiers trained on combined datasets perform remarkably well, just shy of those specialized to either domain. While classifiers trained on either original or manipulated data alone are sensitive to spurious features (e.g., mentions of genre), models trained on the combined data are insensitive to this signal. We will publicly release both datasets.
Domain Adaptation with Asymmetrically-Relaxed Distribution Alignment
Mar 11, 2019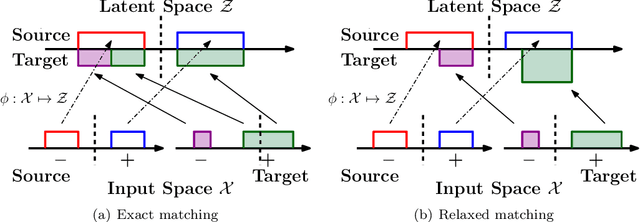
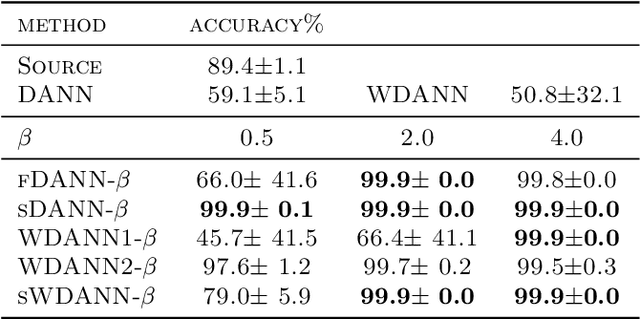
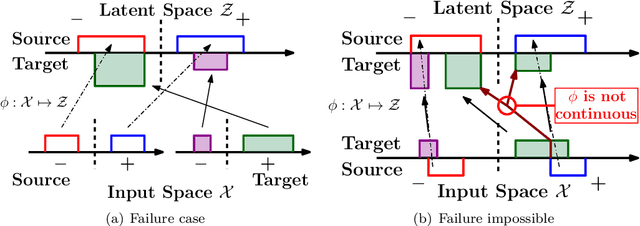
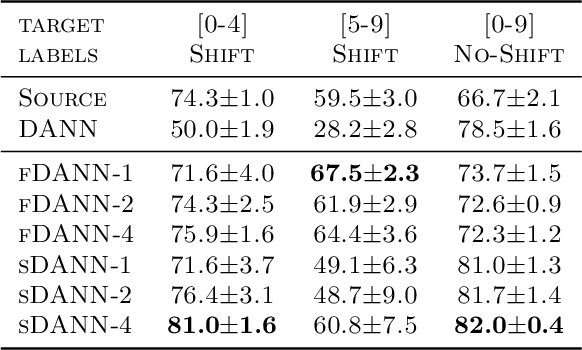
Domain adaptation addresses the common problem when the target distribution generating our test data drifts from the source (training) distribution. While absent assumptions, domain adaptation is impossible, strict conditions, e.g. covariate or label shift, enable principled algorithms. Recently-proposed domain-adversarial approaches consist of aligning source and target encodings, often motivating this approach as minimizing two (of three) terms in a theoretical bound on target error. Unfortunately, this minimization can cause arbitrary increases in the third term, e.g. they can break down under shifting label distributions. We propose asymmetrically-relaxed distribution alignment, a new approach that overcomes some limitations of standard domain-adversarial algorithms. Moreover, we characterize precise assumptions under which our algorithm is theoretically principled and demonstrate empirical benefits on both synthetic and real datasets.
How Much Reading Does Reading Comprehension Require? A Critical Investigation of Popular Benchmarks
Aug 21, 2018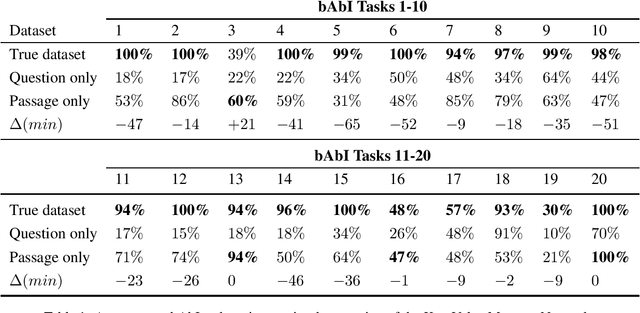
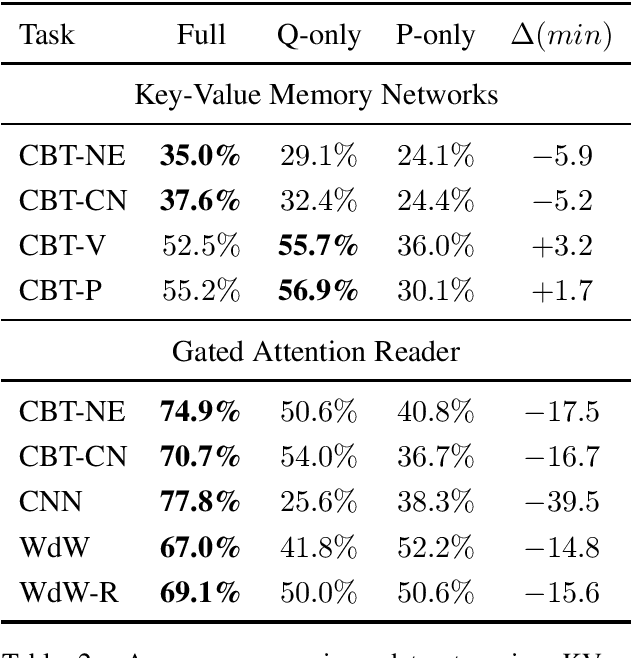


Many recent papers address reading comprehension, where examples consist of (question, passage, answer) tuples. Presumably, a model must combine information from both questions and passages to predict corresponding answers. However, despite intense interest in the topic, with hundreds of published papers vying for leaderboard dominance, basic questions about the difficulty of many popular benchmarks remain unanswered. In this paper, we establish sensible baselines for the bAbI, SQuAD, CBT, CNN, and Who-did-What datasets, finding that question- and passage-only models often perform surprisingly well. On $14$ out of $20$ bAbI tasks, passage-only models achieve greater than $50\%$ accuracy, sometimes matching the full model. Interestingly, while CBT provides $20$-sentence stories only the last is needed for comparably accurate prediction. By comparison, SQuAD and CNN appear better-constructed.