 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiLTra-Bench: The Swiss Legal Translation Benchmark
Mar 03, 2025In Switzerland legal translation is uniquely important due to the country's four official languages and requirements for multilingual legal documentation. However, this process traditionally relies on professionals who must be both legal experts and skilled translators -- creating bottlenecks and impacting effective access to justice. To address this challenge, we introduce SwiLTra-Bench, a comprehensive multilingual benchmark of over 180K aligned Swiss legal translation pairs comprising laws, headnotes, and press releases across all Swiss languages along with English, designed to evaluate LLM-based translation systems. Our systematic evaluation reveals that frontier models achieve superior translation performance across all document types, while specialized translation systems excel specifically in laws but under-perform in headnotes. Through rigorous testing and human expert validation, we demonstrate that while fine-tuning open SLMs significantly improves their translation quality, they still lag behind the best zero-shot prompted frontier models such as Claude-3.5-Sonnet. Additionally, we present SwiLTra-Judge, a specialized LLM evaluation system that aligns best with human expert assessments.
Can Large Language Models Infer Causation from Correlation?
Jun 09, 2023Causal inference is one of the hallmarks of human intelligence. While the field of CausalNLP has attracted much interest in the recent years, existing causal inference datasets in NLP primarily rely on discovering causality from empirical knowledge (e.g., commonsense knowledge). In this work, we propose the first benchmark dataset to test the pure causal inference skills of large language models (LLMs). Specifically, we formulate a novel task Corr2Cause, which takes a set of correlational statements and determines the causal relationship between the variables. We curate a large-scale dataset of more than 400K samples, on which we evaluate seventeen existing LLMs. Through our experiments, we identify a key shortcoming of LLMs in terms of their causal inference skills, and show that these models achieve almost close to random performance on the task. This shortcoming is somewhat mitigated when we try to re-purpose LLMs for this skill via finetuning, but we find that these models still fail to generalize -- they can only perform causal inference in in-distribution settings when variable names and textual expressions used in the queries are similar to those in the training set, but fail in out-of-distribution settings generated by perturbing these queries. Corr2Cause is a challenging task for LLMs, and would be helpful in guiding future research on improving LLMs' pure reasoning skills and generalizability. Our data is at https://huggingface.co/datasets/causalnlp/corr2cause. Our code is at https://github.com/causalNLP/corr2cause.
ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning
Dec 15, 2022



Large language models show improved downstream task performance when prompted to generate step-by-step reasoning to justify their final answers. These reasoning steps greatly improve model interpretability and verification, but objectively studying their correctness (independent of the final answer) is difficult without reliable methods for automatic evaluation. We simply do not know how often the stated reasoning steps actually support the final end task predictions. In this work, we present ROSCOE, a suite of interpretable, unsupervised automatic scores that improve and extend previous text generation evaluation metrics. To evaluate ROSCOE against baseline metrics, we design a typology of reasoning errors and collect synthetic and human evaluation scores on commonly used reasoning datasets. In contrast with existing metrics, ROSCOE can measure semantic consistency, logicality, informativeness, fluency, and factuality - among other traits - by leveraging properties of step-by-step rationales. We empirically verify the strength of our metrics on five human annotated and six programmatically perturbed diagnostics datasets - covering a diverse set of tasks that require reasoning skills and show that ROSCOE can consistently outperform baseline metrics.
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
Aug 10, 2022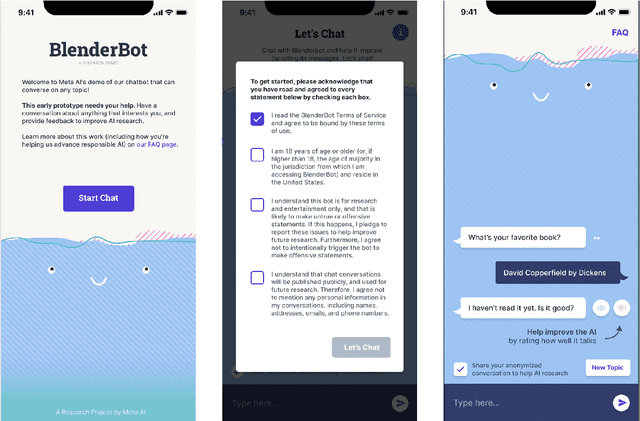
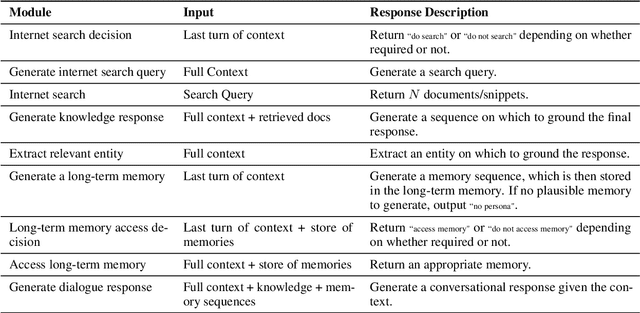
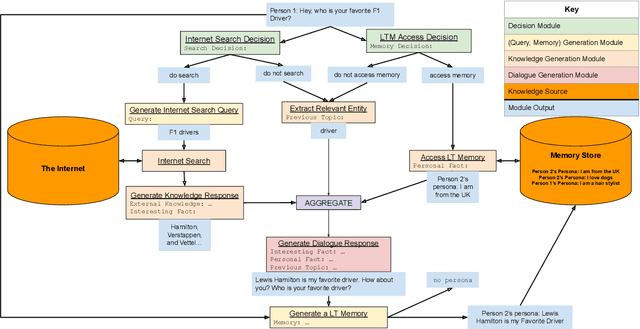
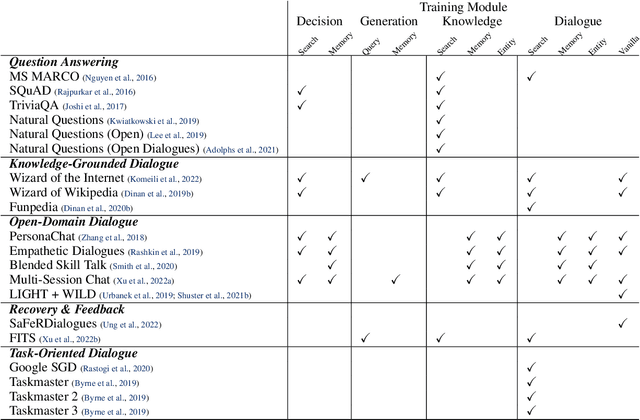
We present BlenderBot 3, a 175B parameter dialogue model capable of open-domain conversation with access to the internet and a long-term memory, and having been trained on a large number of user defined tasks. We release both the model weights and code, and have also deployed the model on a public web page to interact with organic users. This technical report describes how the model was built (architecture, model and training scheme), and details of its deployment, including safety mechanisms. Human evaluations show its superiority to existing open-domain dialogue agents, including its predecessors (Roller et al., 2021; Komeili et al., 2022). Finally, we detail our plan for continual learning using the data collected from deployment, which will also be publicly released. The goal of this research program is thus to enable the community to study ever-improving responsible agents that learn through interaction.
Not All Memories are Created Equal: Learning to Forget by Expiring
May 13, 2021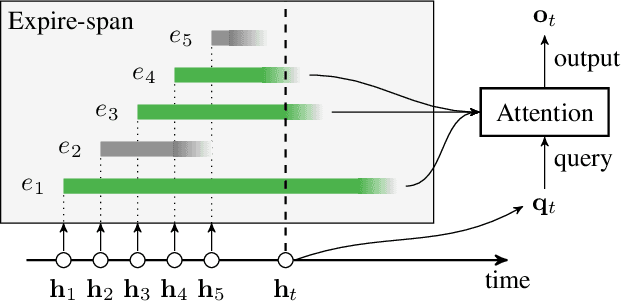
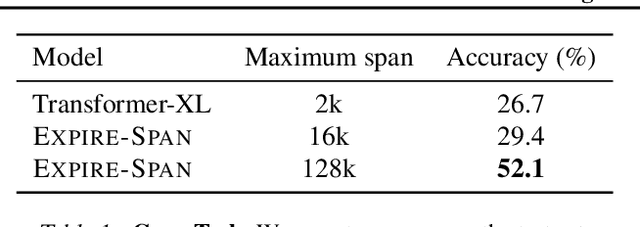
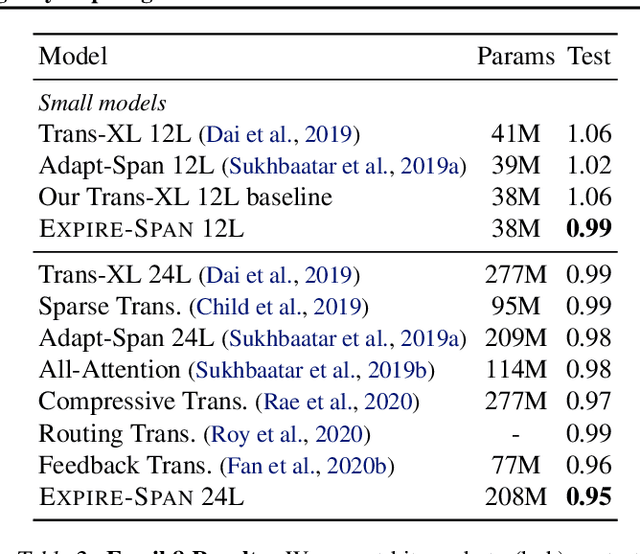

Attention mechanisms have shown promising results in sequence modeling tasks that require long-term memory. Recent work investigated mechanisms to reduce the computational cost of preserving and storing memories. However, not all content in the past is equally important to remember. We propose Expire-Span, a method that learns to retain the most important information and expire the irrelevant information. This forgetting of memories enables Transformers to scale to attend over tens of thousands of previous timesteps efficiently, as not all states from previous timesteps are preserved. We demonstrate that Expire-Span can help models identify and retain critical information and show it can achieve strong performance on reinforcement learning tasks specifically designed to challenge this functionality. Next, we show that Expire-Span can scale to memories that are tens of thousands in size, setting a new state of the art on incredibly long context tasks such as character-level language modeling and a frame-by-frame moving objects task. Finally, we analyze the efficiency of Expire-Span compared to existing approaches and demonstrate that it trains faster and uses less memory.
Retrieval Augmentation Reduces Hallucination in Conversation
Apr 15, 2021
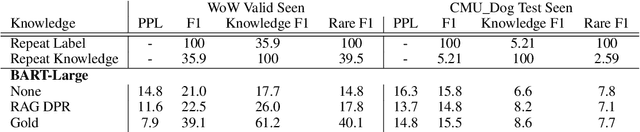
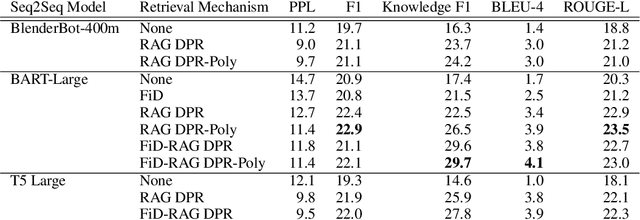
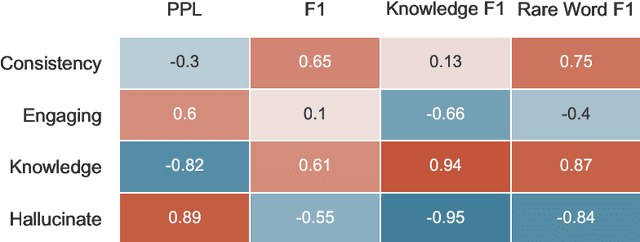
Despite showing increasingly human-like conversational abilities, state-of-the-art dialogue models often suffer from factual incorrectness and hallucination of knowledge (Roller et al., 2020). In this work we explore the use of neural-retrieval-in-the-loop architectures - recently shown to be effective in open-domain QA (Lewis et al., 2020b; Izacard and Grave, 2020) - for knowledge-grounded dialogue, a task that is arguably more challenging as it requires querying based on complex multi-turn dialogue context and generating conversationally coherent responses. We study various types of architectures with multiple components - retrievers, rankers, and encoder-decoders - with the goal of maximizing knowledgeability while retaining conversational ability. We demonstrate that our best models obtain state-of-the-art performance on two knowledge-grounded conversational tasks. The models exhibit open-domain conversational capabilities, generalize effectively to scenarios not within the training data, and, as verified by human evaluations, substantially reduce the well-known problem of knowledge hallucination in state-of-the-art chatbots.
Open-Domain Conversational Agents: Current Progress, Open Problems, and Future Directions
Jul 13, 2020We present our view of what is necessary to build an engaging open-domain conversational agent: covering the qualities of such an agent, the pieces of the puzzle that have been built so far, and the gaping holes we have not filled yet. We present a biased view, focusing on work done by our own group, while citing related work in each area. In particular, we discuss in detail the properties of continual learning, providing engaging content, and being well-behaved -- and how to measure success in providing them. We end with a discussion of our experience and learnings, and our recommendations to the community.