 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalization Distillation for Object Detection
Apr 12, 2022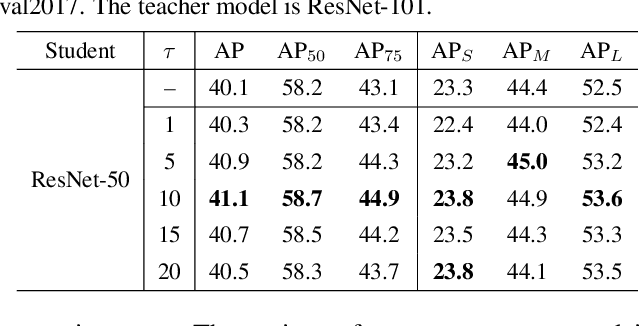

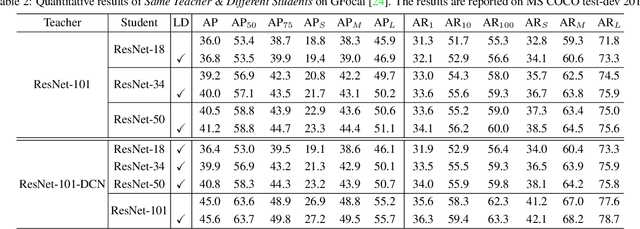
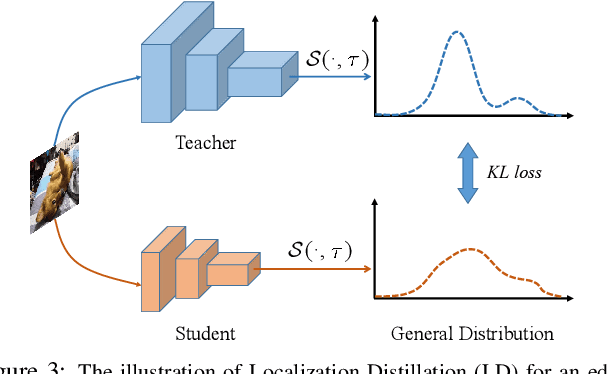
Previous knowledge distillation (KD) methods for object detection mostly focus on feature imitation instead of mimicking the classification logits due to its inefficiency in distilling the localization information. In this paper, we investigate whether logit mimicking always lags behind feature imitation. Towards this goal, we first present a novel localization distillation (LD) method which can efficiently transfer the localization knowledge from the teacher to the student. Second, we introduce the concept of valuable localization region that can aid to selectively distill the classification and localization knowledge for a certain region. Combining these two new components, for the first time, we show that logit mimicking can outperform feature imitation and the absence of localization distillation is a critical reason for why logit mimicking underperforms for years. The thorough studies exhibit the great potential of logit mimicking that can significantly alleviate the localization ambiguity, learn robust feature representation, and ease the training difficulty in the early stage. We also provide the theoretical connection between the proposed LD and the classification KD, that they share the equivalent optimization effect. Our distillation scheme is simple as well as effective and can be easily applied to both dense horizontal object detectors and rotated object detectors. Extensive experiments on the MS COCO, PASCAL VOC, and DOTA benchmarks demonstrate that our method can achieve considerable AP improvement without any sacrifice on the inference speed. Our source code and pretrained models are publicly available at https://github.com/HikariTJU/LD.
Learning Class-Agnostic Pseudo Mask Generation for Box-Supervised Semantic Segmentation
Mar 09, 2021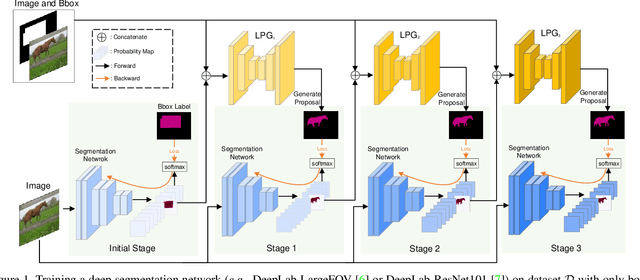

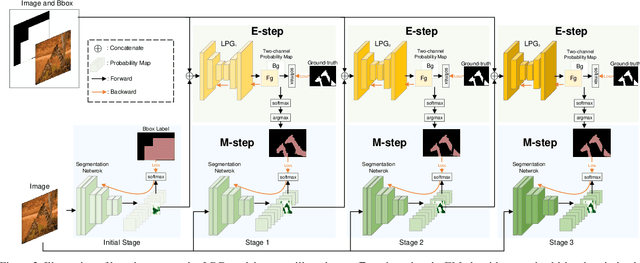
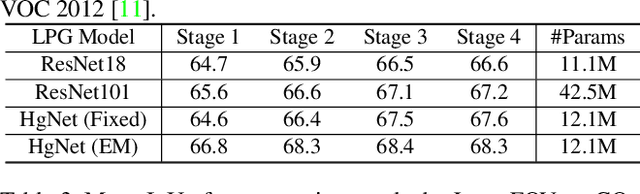
Recently, several weakly supervised learning methods have been devoted to utilize bounding box supervision for training deep semantic segmentation models. Most existing methods usually leverage the generic proposal generators (\eg, dense CRF and MCG) to produce enhanced segmentation masks for further training segmentation models. These proposal generators, however, are generic and not specifically designed for box-supervised semantic segmentation, thereby leaving some leeway for improving segmentation performance. In this paper, we aim at seeking for a more accurate learning-based class-agnostic pseudo mask generator tailored to box-supervised semantic segmentation. To this end, we resort to a pixel-level annotated auxiliary dataset where the class labels are non-overlapped with those of the box-annotated dataset. For learning pseudo mask generator from the auxiliary dataset, we present a bi-level optimization formulation. In particular, the lower subproblem is used to learn box-supervised semantic segmentation, while the upper subproblem is used to learn an optimal class-agnostic pseudo mask generator. The learned pseudo segmentation mask generator can then be deployed to the box-annotated dataset for improving weakly supervised semantic segmentation. Experiments on PASCAL VOC 2012 dataset show that the learned pseudo mask generator is effective in boosting segmentation performance, and our method can further close the performance gap between box-supervised and fully-supervised models. Our code will be made publicly available at https://github.com/Vious/LPG_BBox_Segmentation .
Two-Stage Single Image Reflection Removal with Reflection-Aware Guidance
Dec 02, 2020
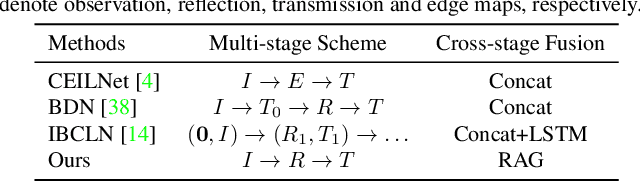
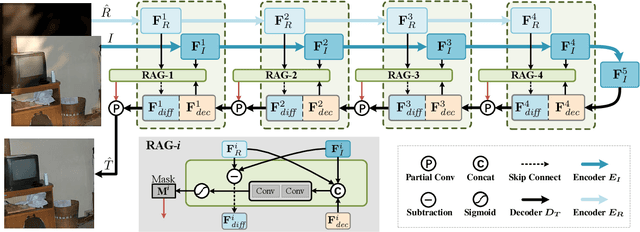
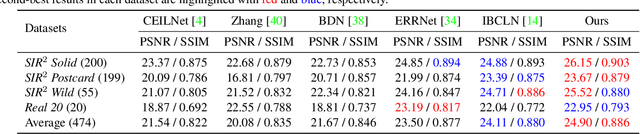
Removing undesired reflection from an image captured through a glass surface is a very challenging problem with many practical application scenarios. For improving reflection removal, cascaded deep models have been usually adopted to estimate the transmission in a progressive manner. However, most existing methods are still limited in exploiting the result in prior stage for guiding transmission estimation. In this paper, we present a novel two-stage network with reflection-aware guidance (RAGNet) for single image reflection removal (SIRR). To be specific, the reflection layer is firstly estimated due to that it generally is much simpler and is relatively easier to estimate. Reflectionaware guidance (RAG) module is then elaborated for better exploiting the estimated reflection in predicting transmission layer. By incorporating feature maps from the estimated reflection and observation, RAG can be used (i) to mitigate the effect of reflection from the observation, and (ii) to generate mask in partial convolution for mitigating the effect of deviating from linear combination hypothesis. A dedicated mask loss is further presented for reconciling the contributions of encoder and decoder features. Experiments on five commonly used datasets demonstrate the quantitative and qualitative superiority of our RAGNet in comparison to the state-of-the-art SIRR methods. The source code and pre-trained model are available at https://github.com/liyucs/RAGNet.
Unpaired Learning of Deep Image Denoising
Aug 31, 2020
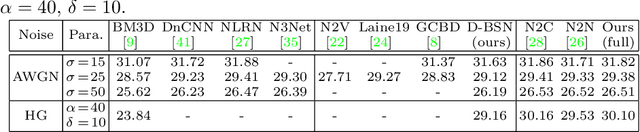
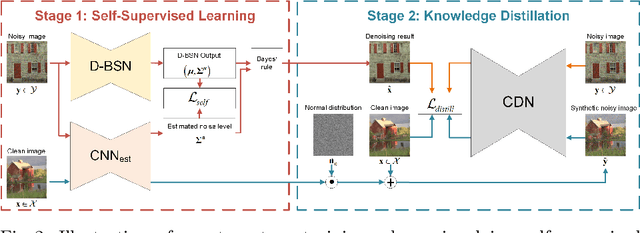
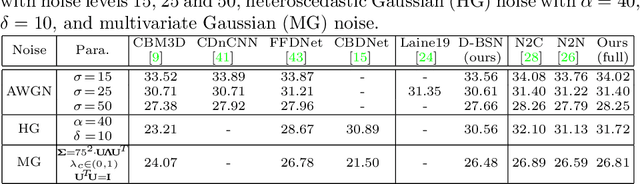
We investigate the task of learning blind image denoising networks from an unpaired set of clean and noisy images. Such problem setting generally is practical and valuable considering that it is feasible to collect unpaired noisy and clean images in most real-world applications. And we further assume that the noise can be signal dependent but is spatially uncorrelated. In order to facilitate unpaired learning of denoising network, this paper presents a two-stage scheme by incorporating self-supervised learning and knowledge distillation. For self-supervised learning, we suggest a dilated blind-spot network (D-BSN) to learn denoising solely from real noisy images. Due to the spatial independence of noise, we adopt a network by stacking 1x1 convolution layers to estimate the noise level map for each image. Both the D-BSN and image-specific noise model (CNN\_est) can be jointly trained via maximizing the constrained log-likelihood. Given the output of D-BSN and estimated noise level map, improved denoising performance can be further obtained based on the Bayes' rule. As for knowledge distillation, we first apply the learned noise models to clean images to synthesize a paired set of training images, and use the real noisy images and the corresponding denoising results in the first stage to form another paired set. Then, the ultimate denoising model can be distilled by training an existing denoising network using these two paired sets. Experiments show that our unpaired learning method performs favorably on both synthetic noisy images and real-world noisy photographs in terms of quantitative and qualitative evaluation.
Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation
May 08, 2020

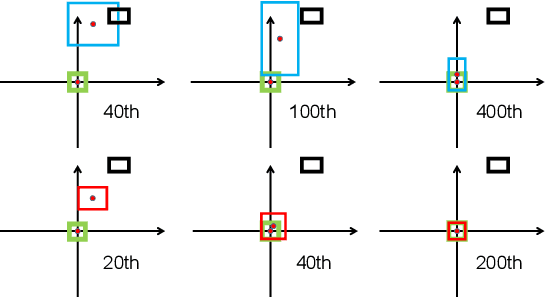
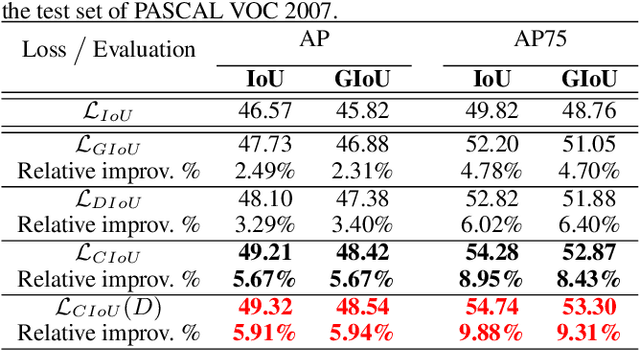
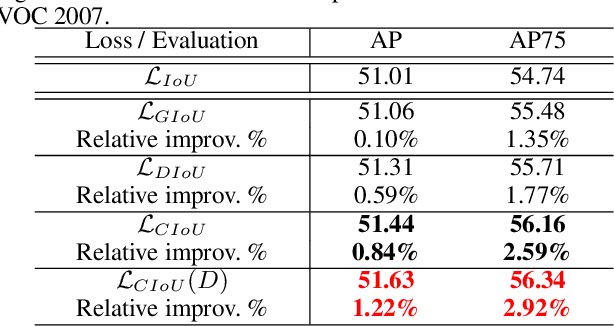
Deep learning-based object detection and instance segmentation have achieved unprecedented progress. In this paper, we propose Complete-IoU (CIoU) loss and Cluster-NMS for enhancing geometric factors in both bounding box regression and Non-Maximum Suppression (NMS), leading to notable gains of average precision (AP) and average recall (AR), without the sacrifice of inference efficiency. In particular, we consider three geometric factors, i.e., overlap area, normalized central point distance and aspect ratio, which are crucial for measuring bounding box regression in object detection and instance segmentation. The three geometric factors are then incorporated into CIoU loss for better distinguishing difficult regression cases. The training of deep models using CIoU loss results in consistent AP and AR improvements in comparison to widely adopted $\ell_n$-norm loss and IoU-based loss. Furthermore, we propose Cluster-NMS, where NMS during inference is done by implicitly clustering detected boxes and usually requires less iterations. Cluster-NMS is very efficient due to its pure GPU implementation, and geometric factors can be incorporated to improve both AP and AR. In the experiments, CIoU loss and Cluster-NMS have been applied to state-of-the-art instance segmentation (e.g., YOLACT), and object detection (e.g., YOLO v3, SSD and Faster R-CNN) models. Taking YOLACT on MS COCO as an example, our method achieves performance gains as +1.7 AP and +6.2 AR$_{100}$ for object detection, and +0.9 AP and +3.5 AR$_{100}$ for instance segmentation, with 27.1 FPS on one NVIDIA GTX 1080Ti GPU. All the source code and trained models are available at https://github.com/Zzh-tju/CIoU
What Deep CNNs Benefit from Global Covariance Pooling: An Optimization Perspective
Mar 25, 2020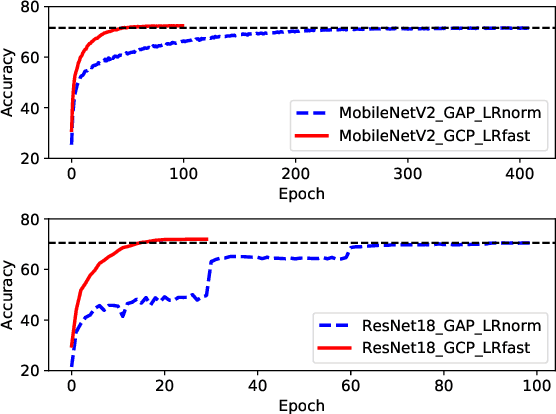
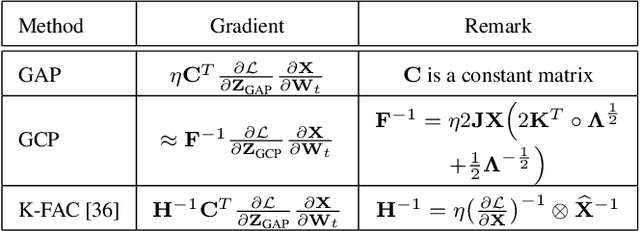
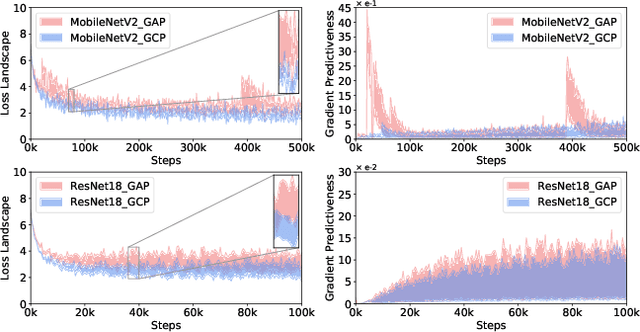
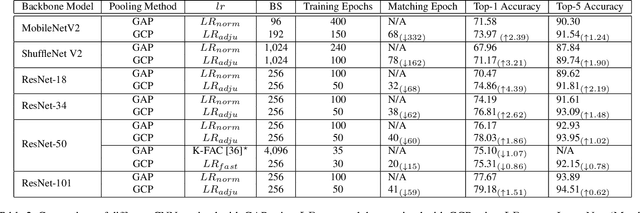
Recent works have demonstrated that global covariance pooling (GCP) has the ability to improve performance of deep convolutional neural networks (CNNs) on visual classification task. Despite considerable advance, the reasons on effectiveness of GCP on deep CNNs have not been well studied. In this paper, we make an attempt to understand what deep CNNs benefit from GCP in a viewpoint of optimization. Specifically, we explore the effect of GCP on deep CNNs in terms of the Lipschitzness of optimization loss and the predictiveness of gradients, and show that GCP can make the optimization landscape more smooth and the gradients more predictive. Furthermore, we discuss the connection between GCP and second-order optimization for deep CNNs. More importantly, above findings can account for several merits of covariance pooling for training deep CNNs that have not been recognized previously or fully explored, including significant acceleration of network convergence (i.e., the networks trained with GCP can support rapid decay of learning rates, achieving favorable performance while significantly reducing number of training epochs), stronger robustness to distorted examples generated by image corruptions and perturbations, and good generalization ability to different vision tasks, e.g., object detection and instance segmentation. We conduct extensive experiments using various deep CNN models on diversified tasks, and the results provide strong support to our findings.
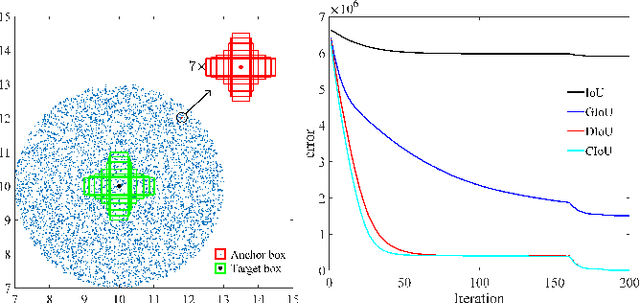
Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
Nov 19, 2019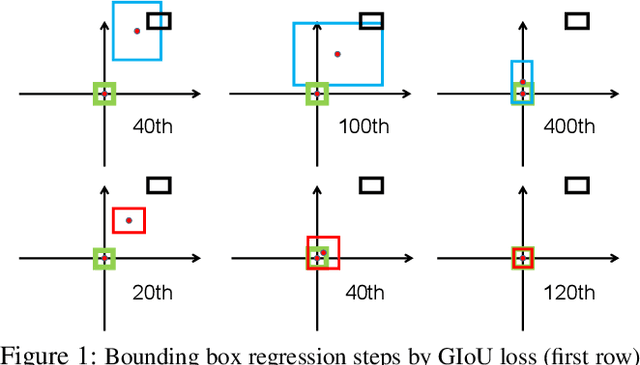
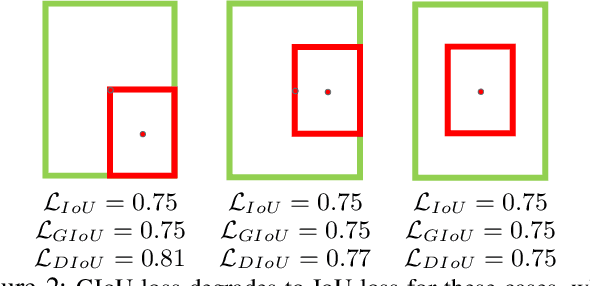
Bounding box regression is the crucial step in object detection. In existing methods, while $\ell_n$-norm loss is widely adopted for bounding box regression, it is not tailored to the evaluation metric, i.e., Intersection over Union (IoU). Recently, IoU loss and generalized IoU (GIoU) loss have been proposed to benefit the IoU metric, but still suffer from the problems of slow convergence and inaccurate regression. In this paper, we propose a Distance-IoU (DIoU) loss by incorporating the normalized distance between the predicted box and the target box, which converges much faster in training than IoU and GIoU losses. Furthermore, this paper summarizes three geometric factors in bounding box regression, \ie, overlap area, central point distance and aspect ratio, based on which a Complete IoU (CIoU) loss is proposed, thereby leading to faster convergence and better performance. By incorporating DIoU and CIoU losses into state-of-the-art object detection algorithms, e.g., YOLO v3, SSD and Faster RCNN, we achieve notable performance gains in terms of not only IoU metric but also GIoU metric. Moreover, DIoU can be easily adopted into non-maximum suppression (NMS) to act as the criterion, further boosting performance improvement. The source code and trained models are available at https://github.com/Zzh-tju/DIoU.
Neural Blind Deconvolution Using Deep Priors
Aug 06, 2019
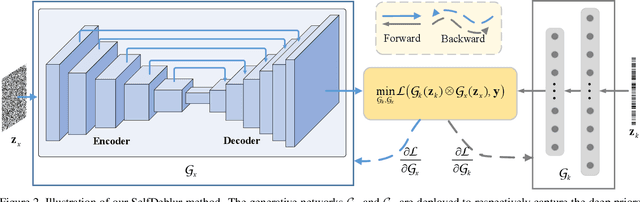


Blind deconvolution is a classical yet challenging low-level vision problem with many real-world applications. Traditional maximum a posterior (MAP) based methods rely heavily on fixed and handcrafted priors that certainly are insufficient in characterizing clean images and blur kernels, and usually adopt specially designed alternating minimization to avoid trivial solution. In contrast, existing deep motion deblurring networks learn from massive training images the mapping to clean image or blur kernel, but are limited in handling various complex and large size blur kernels. To connect MAP and deep models, we in this paper present two generative networks for respectively modeling the deep priors of clean image and blur kernel, and propose an unconstrained neural optimization solution to blind deconvolution. In particular, we adopt an asymmetric Autoencoder with skip connections for generating latent clean image, and a fully-connected network (FCN) for generating blur kernel. Moreover, the SoftMax nonlinearity is applied to the output layer of FCN to meet the non-negative and equality constraints. The process of neural optimization can be explained as a kind of "zero-shot" self-supervised learning of the generative networks, and thus our proposed method is dubbed SelfDeblur. Experimental results show that our SelfDeblur can achieve notable quantitative gains as well as more visually plausible deblurring results in comparison to state-of-the-art blind deconvolution methods on benchmark datasets and real-world blurry images. The source code is available at https://github.com/csdwren/SelfDeblur.
STAR: A Structure and Texture Aware Retinex Model
Jun 30, 2019



Retinex theory is developed mainly to decompose an image into the illumination and reflectance components by analyzing local image derivatives. In this theory, larger derivatives are attributed to the changes in piece-wise constant reflectance, while smaller derivatives are emerged in the smooth illumination. In this paper, we propose to utilize the exponentiated derivatives (with an exponent $\gamma$) of an observed image to generate a structure map when being amplified with $\gamma>1$ and a texture map when being shrank with $\gamma<1$. To this end, we design exponential filters for the local derivatives, and present their capability on extracting accurate structure and texture maps, influenced by the choices of exponents $\gamma$ on the local derivatives. The extracted structure and texture maps are employed to regularize the illumination and reflectance components in Retinex decomposition. A novel Structure and Texture Aware Retinex (STAR) model is further proposed for illumination and reflectance decomposition of a single image. We solve the STAR model in an alternating minimization manner. Each sub-problem is transformed into a vectorized least squares regression with closed-form solution. Comprehensive experiments demonstrate that, the proposed STAR model produce better quantitative and qualitative performance than previous competing methods, on illumination and reflectance estimation, low-light image enhancement, and color correction. The code will be publicly released.