 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Mixture of Experts
Apr 20, 2022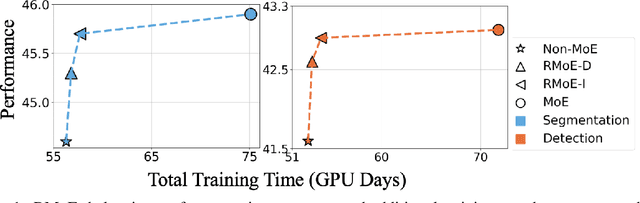
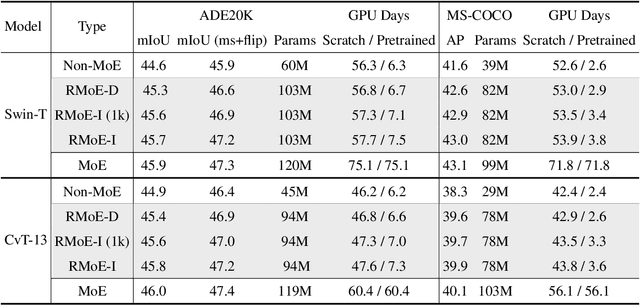
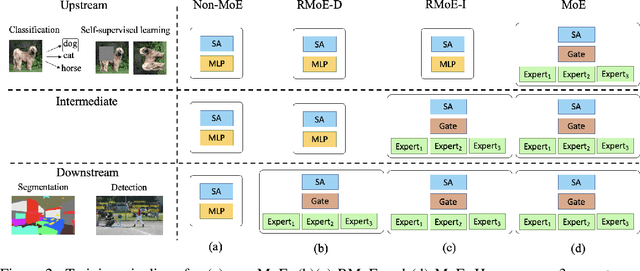
Mixture of Experts (MoE) is able to scale up vision transformers effectively. However, it requires prohibiting computation resources to train a large MoE transformer. In this paper, we propose Residual Mixture of Experts (RMoE), an efficient training pipeline for MoE vision transformers on downstream tasks, such as segmentation and detection. RMoE achieves comparable results with the upper-bound MoE training, while only introducing minor additional training cost than the lower-bound non-MoE training pipelines. The efficiency is supported by our key observation: the weights of an MoE transformer can be factored into an input-independent core and an input-dependent residual. Compared with the weight core, the weight residual can be efficiently trained with much less computation resource, e.g., finetuning on the downstream data. We show that, compared with the current MoE training pipeline, we get comparable results while saving over 30% training cost. When compared with state-of-the-art non- MoE transformers, such as Swin-T / CvT-13 / Swin-L, we get +1.1 / 0.9 / 1.0 mIoU gain on ADE20K segmentation and +1.4 / 1.6 / 0.6 AP gain on MS-COCO object detection task with less than 3% additional training cost.
Protecting Celebrities from DeepFake with Identity Consistency Transformer
Apr 05, 2022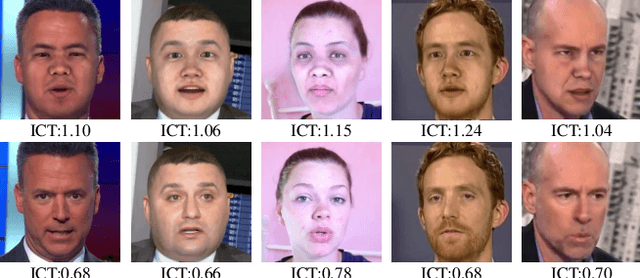
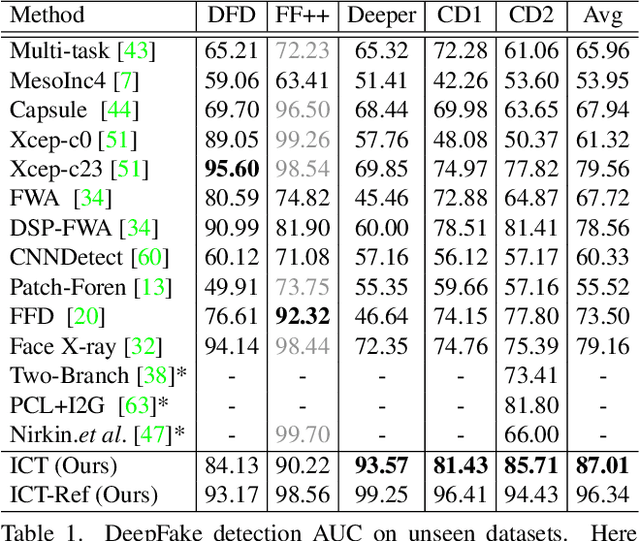

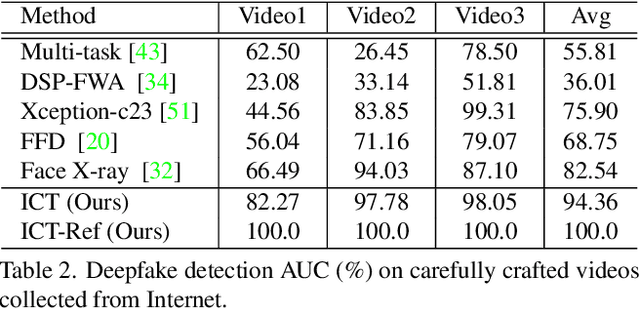
In this work we propose Identity Consistency Transformer, a novel face forgery detection method that focuses on high-level semantics, specifically identity information, and detecting a suspect face by finding identity inconsistency in inner and outer face regions. The Identity Consistency Transformer incorporates a consistency loss for identity consistency determination. We show that Identity Consistency Transformer exhibits superior generalization ability not only across different datasets but also across various types of image degradation forms found in real-world applications including deepfake videos. The Identity Consistency Transformer can be easily enhanced with additional identity information when such information is available, and for this reason it is especially well-suited for detecting face forgeries involving celebrities. Code will be released at \url{https://github.com/LightDXY/ICT_DeepFake}
Large-Scale Pre-training for Person Re-identification with Noisy Labels
Apr 04, 2022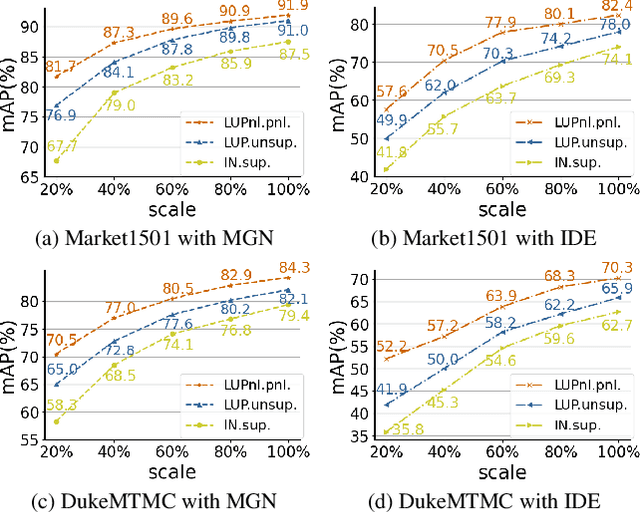
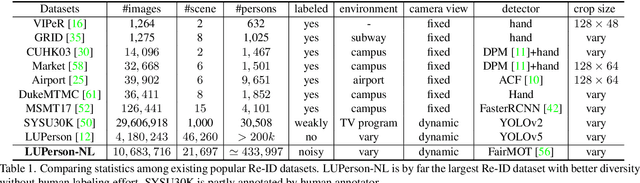
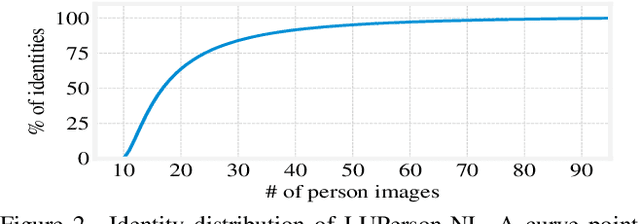
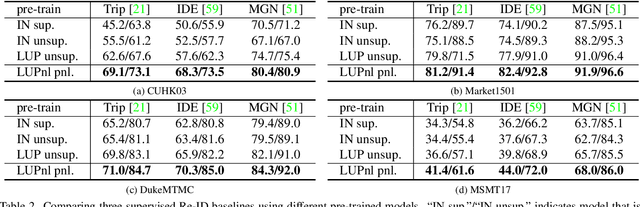
This paper aims to address the problem of pre-training for person re-identification (Re-ID) with noisy labels. To setup the pre-training task, we apply a simple online multi-object tracking system on raw videos of an existing unlabeled Re-ID dataset "LUPerson" nd build the Noisy Labeled variant called "LUPerson-NL". Since theses ID labels automatically derived from tracklets inevitably contain noises, we develop a large-scale Pre-training framework utilizing Noisy Labels (PNL), which consists of three learning modules: supervised Re-ID learning, prototype-based contrastive learning, and label-guided contrastive learning. In principle, joint learning of these three modules not only clusters similar examples to one prototype, but also rectifies noisy labels based on the prototype assignment. We demonstrate that learning directly from raw videos is a promising alternative for pre-training, which utilizes spatial and temporal correlations as weak supervision. This simple pre-training task provides a scalable way to learn SOTA Re-ID representations from scratch on "LUPerson-NL" without bells and whistles. For example, by applying on the same supervised Re-ID method MGN, our pre-trained model improves the mAP over the unsupervised pre-training counterpart by 5.7%, 2.2%, 2.3% on CUHK03, DukeMTMC, and MSMT17 respectively. Under the small-scale or few-shot setting, the performance gain is even more significant, suggesting a better transferability of the learned representation. Code is available at https://github.com/DengpanFu/LUPerson-NL
Bringing Old Films Back to Life
Mar 31, 2022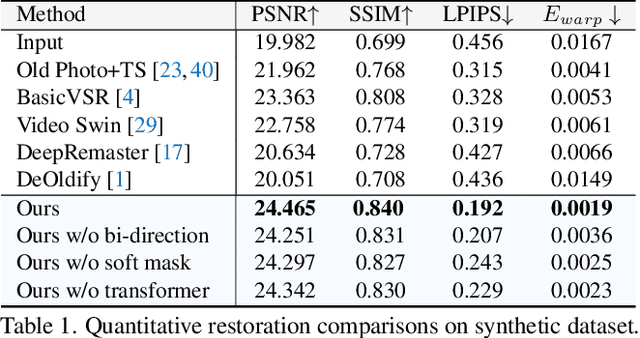
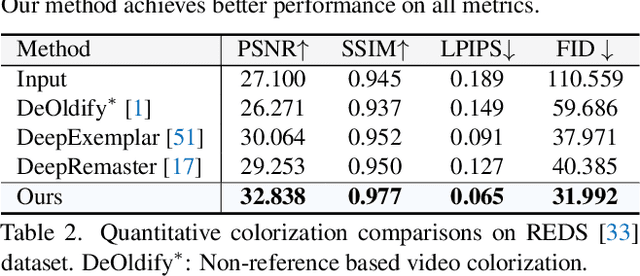
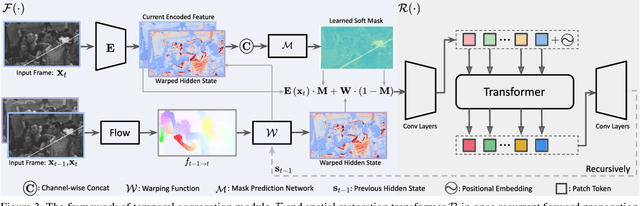
We present a learning-based framework, recurrent transformer network (RTN), to restore heavily degraded old films. Instead of performing frame-wise restoration, our method is based on the hidden knowledge learned from adjacent frames that contain abundant information about the occlusion, which is beneficial to restore challenging artifacts of each frame while ensuring temporal coherency. Moreover, contrasting the representation of the current frame and the hidden knowledge makes it possible to infer the scratch position in an unsupervised manner, and such defect localization generalizes well to real-world degradations. To better resolve mixed degradation and compensate for the flow estimation error during frame alignment, we propose to leverage more expressive transformer blocks for spatial restoration. Experiments on both synthetic dataset and real-world old films demonstrate the significant superiority of the proposed RTN over existing solutions. In addition, the same framework can effectively propagate the color from keyframes to the whole video, ultimately yielding compelling restored films. The implementation and model will be released at https://github.com/raywzy/Bringing-Old-Films-Back-to-Life.
Sampling Theorems for Unsupervised Learning in Linear Inverse Problems
Mar 23, 2022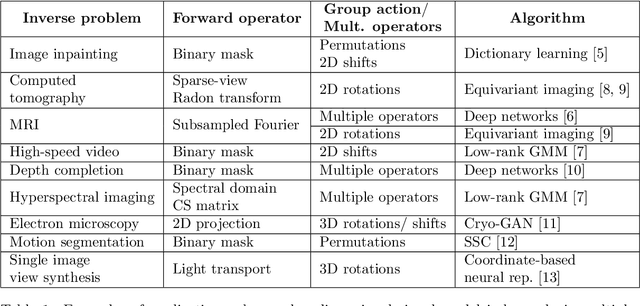
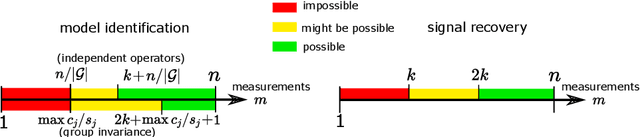
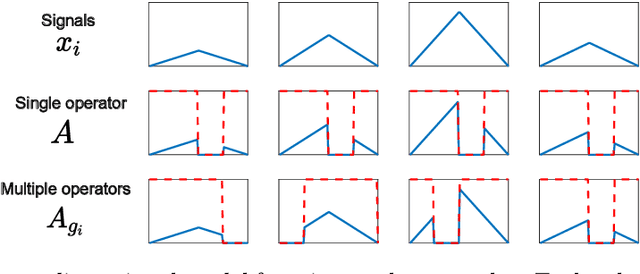

Solving a linear inverse problem requires knowledge about the underlying signal model. In many applications, this model is a priori unknown and has to be learned from data. However, it is impossible to learn the model using observations obtained via a single incomplete measurement operator, as there is no information outside the range of the inverse operator, resulting in a chicken-and-egg problem: to learn the model we need reconstructed signals, but to reconstruct the signals we need to know the model. Two ways to overcome this limitation are using multiple measurement operators or assuming that the signal model is invariant to a certain group action. In this paper, we present necessary and sufficient sampling conditions for learning the signal model from partial measurements which only depend on the dimension of the model, and the number of operators or properties of the group action that the model is invariant to. As our results are agnostic of the learning algorithm, they shed light into the fundamental limitations of learning from incomplete data and have implications in a wide range set of practical algorithms, such as dictionary learning, matrix completion and deep neural networks.
Shape-invariant 3D Adversarial Point Clouds
Mar 22, 2022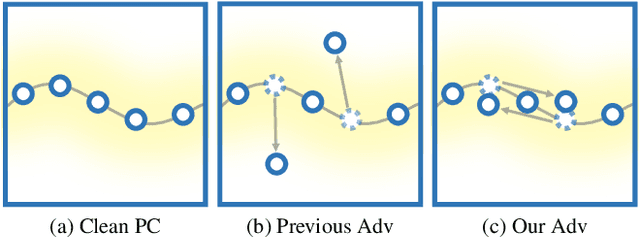
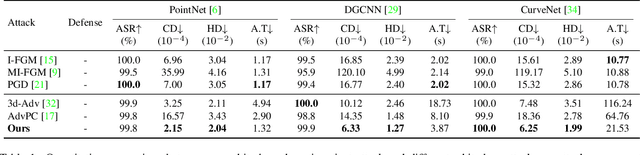
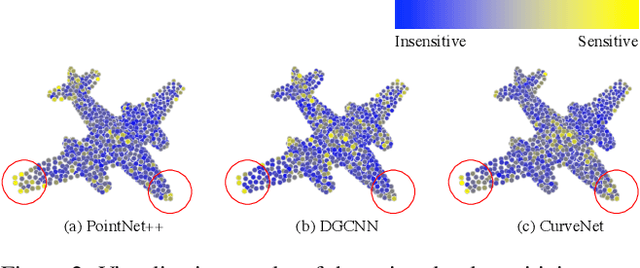
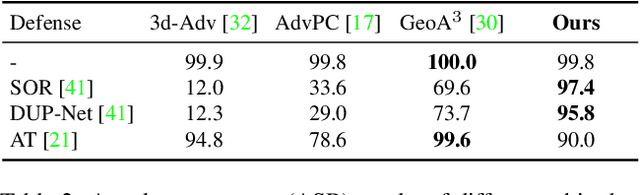
Adversary and invisibility are two fundamental but conflict characters of adversarial perturbations. Previous adversarial attacks on 3D point cloud recognition have often been criticized for their noticeable point outliers, since they just involve an "implicit constrain" like global distance loss in the time-consuming optimization to limit the generated noise. While point cloud is a highly structured data format, it is hard to constrain its perturbation with a simple loss or metric properly. In this paper, we propose a novel Point-Cloud Sensitivity Map to boost both the efficiency and imperceptibility of point perturbations. This map reveals the vulnerability of point cloud recognition models when encountering shape-invariant adversarial noises. These noises are designed along the shape surface with an "explicit constrain" instead of extra distance loss. Specifically, we first apply a reversible coordinate transformation on each point of the point cloud input, to reduce one degree of point freedom and limit its movement on the tangent plane. Then we calculate the best attacking direction with the gradients of the transformed point cloud obtained on the white-box model. Finally we assign each point with a non-negative score to construct the sensitivity map, which benefits both white-box adversarial invisibility and black-box query-efficiency extended in our work. Extensive evaluations prove that our method can achieve the superior performance on various point cloud recognition models, with its satisfying adversarial imperceptibility and strong resistance to different point cloud defense settings. Our code is available at: https://github.com/shikiw/SI-Adv.
Self-supervised Transformer for Deepfake Detection
Mar 02, 2022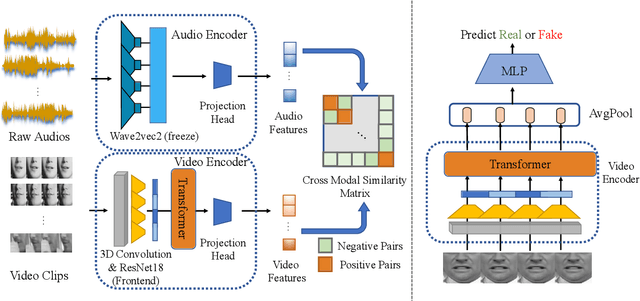
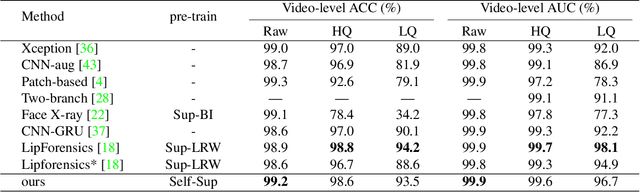
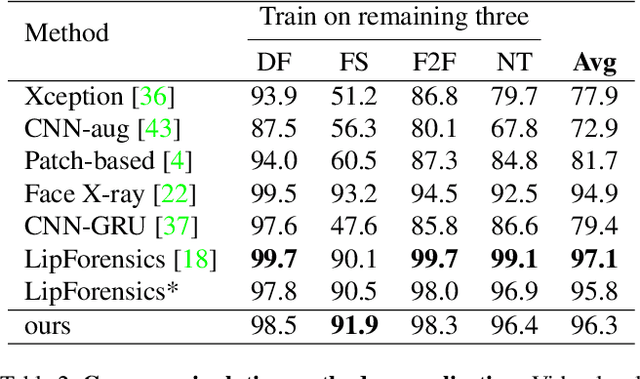
The fast evolution and widespread of deepfake techniques in real-world scenarios require stronger generalization abilities of face forgery detectors. Some works capture the features that are unrelated to method-specific artifacts, such as clues of blending boundary, accumulated up-sampling, to strengthen the generalization ability. However, the effectiveness of these methods can be easily corrupted by post-processing operations such as compression. Inspired by transfer learning, neural networks pre-trained on other large-scale face-related tasks may provide useful features for deepfake detection. For example, lip movement has been proved to be a kind of robust and good-transferring highlevel semantic feature, which can be learned from the lipreading task. However, the existing method pre-trains the lip feature extraction model in a supervised manner, which requires plenty of human resources in data annotation and increases the difficulty of obtaining training data. In this paper, we propose a self-supervised transformer based audio-visual contrastive learning method. The proposed method learns mouth motion representations by encouraging the paired video and audio representations to be close while unpaired ones to be diverse. After pre-training with our method, the model will then be partially fine-tuned for deepfake detection task. Extensive experiments show that our self-supervised method performs comparably or even better than the supervised pre-training counterpart.
Sampling Theorems for Learning from Incomplete Measurements
Jan 31, 2022

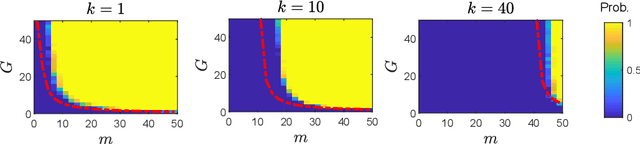
In many real-world settings, only incomplete measurement data are available which can pose a problem for learning. Unsupervised learning of the signal model using a fixed incomplete measurement process is impossible in general, as there is no information in the nullspace of the measurement operator. This limitation can be overcome by using measurements from multiple operators. While this idea has been successfully applied in various applications, a precise characterization of the conditions for learning is still lacking. In this paper, we fill this gap by presenting necessary and sufficient conditions for learning the signal model which indicate the interplay between the number of distinct measurement operators $G$, the number of measurements per operator $m$, the dimension of the model $k$ and the dimension of the signals $n$. In particular, we show that generically unsupervised learning is possible if each operator obtains at least $m>k+n/G$ measurements. Our results are agnostic of the learning algorithm and have implications in a wide range of practical algorithms, from low-rank matrix recovery to deep neural networks.
Deep Unrolling for Magnetic Resonance Fingerprinting
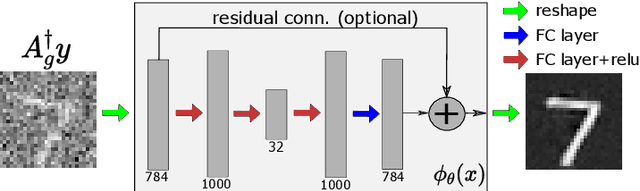
Jan 25, 2022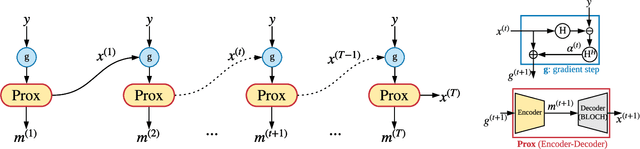
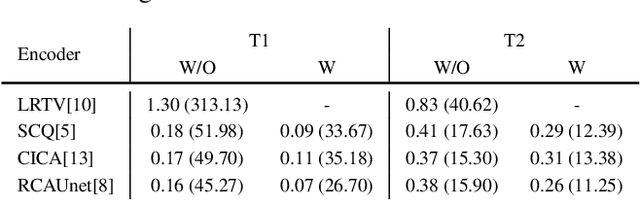
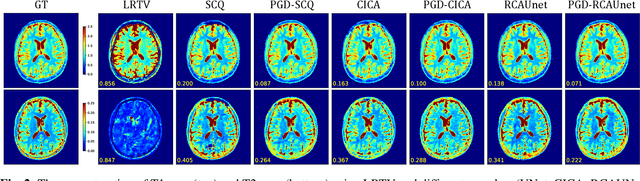
Magnetic Resonance Fingerprinting (MRF) has emerged as a promising quantitative MR imaging approach. Deep learning methods have been proposed for MRF and demonstrated improved performance over classical compressed sensing algorithms. However many of these end-to-end models are physics-free, while consistency of the predictions with respect to the physical forward model is crucial for reliably solving inverse problems. To address this, recently [1] proposed a proximal gradient descent framework that directly incorporates the forward acquisition and Bloch dynamic models within an unrolled learning mechanism. However, [1] only evaluated the unrolled model on synthetic data using Cartesian sampling trajectories. In this paper, as a complementary to [1], we investigate other choices of encoders to build the proximal neural network, and evaluate the deep unrolling algorithm on real accelerated MRF scans with non-Cartesian k-space sampling trajectories.
Online Multi-Object Tracking with Unsupervised Re-Identification Learning and Occlusion Estimation
Jan 04, 2022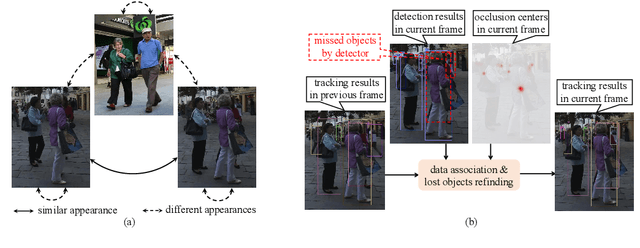

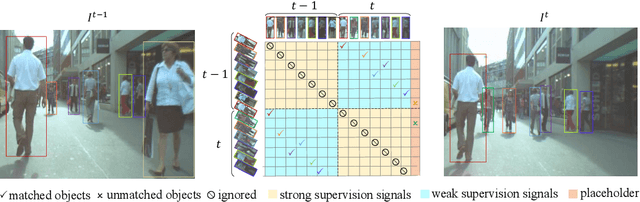

Occlusion between different objects is a typical challenge in Multi-Object Tracking (MOT), which often leads to inferior tracking results due to the missing detected objects. The common practice in multi-object tracking is re-identifying the missed objects after their reappearance. Though tracking performance can be boosted by the re-identification, the annotation of identity is required to train the model. In addition, such practice of re-identification still can not track those highly occluded objects when they are missed by the detector. In this paper, we focus on online multi-object tracking and design two novel modules, the unsupervised re-identification learning module and the occlusion estimation module, to handle these problems. Specifically, the proposed unsupervised re-identification learning module does not require any (pseudo) identity information nor suffer from the scalability issue. The proposed occlusion estimation module tries to predict the locations where occlusions happen, which are used to estimate the positions of missed objects by the detector. Our study shows that, when applied to state-of-the-art MOT methods, the proposed unsupervised re-identification learning is comparable to supervised re-identification learning, and the tracking performance is further improved by the proposed occlusion estimation module.