 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoison Ink: Robust and Invisible Backdoor Attack
Aug 14, 2021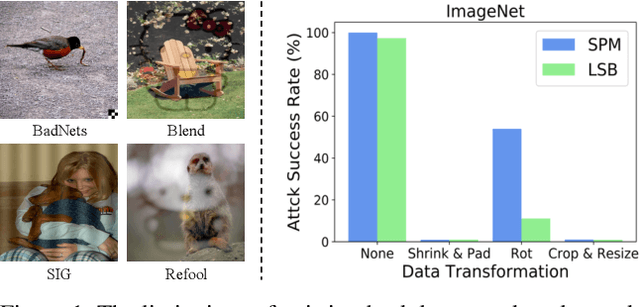
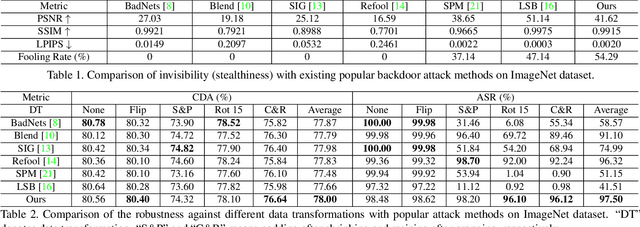
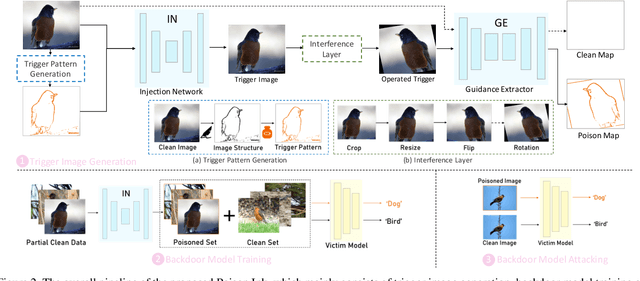

Recent research shows deep neural networks are vulnerable to different types of attacks, such as adversarial attack, data poisoning attack and backdoor attack. Among them, backdoor attack is the most cunning one and can occur in almost every stage of deep learning pipeline. Therefore, backdoor attack has attracted lots of interests from both academia and industry. However, most existing backdoor attack methods are either visible or fragile to some effortless pre-processing such as common data transformations. To address these limitations, we propose a robust and invisible backdoor attack called "Poison Ink". Concretely, we first leverage the image structures as target poisoning areas, and fill them with poison ink (information) to generate the trigger pattern. As the image structure can keep its semantic meaning during the data transformation, such trigger pattern is inherently robust to data transformations. Then we leverage a deep injection network to embed such trigger pattern into the cover image to achieve stealthiness. Compared to existing popular backdoor attack methods, Poison Ink outperforms both in stealthiness and robustness. Through extensive experiments, we demonstrate Poison Ink is not only general to different datasets and network architectures, but also flexible for different attack scenarios. Besides, it also has very strong resistance against many state-of-the-art defense techniques.
Mobile-Former: Bridging MobileNet and Transformer
Aug 12, 2021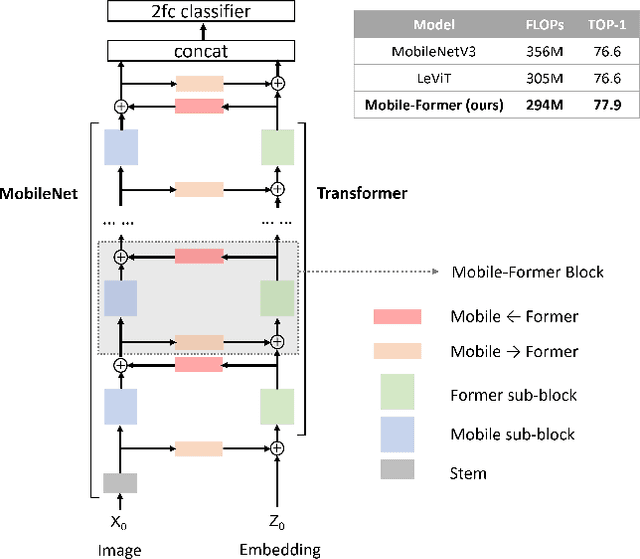
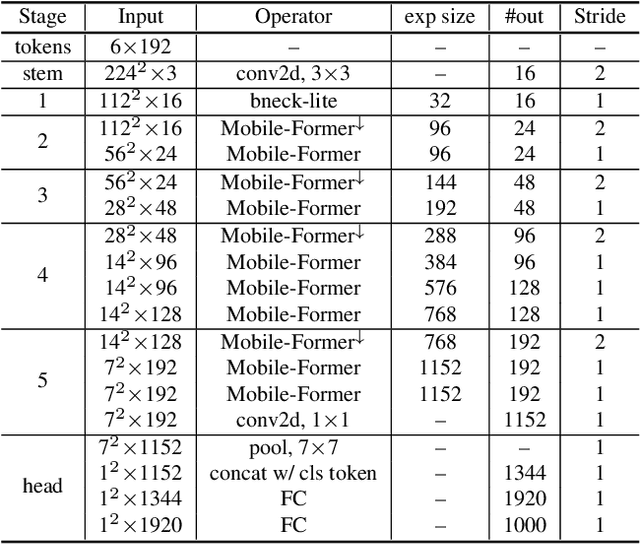
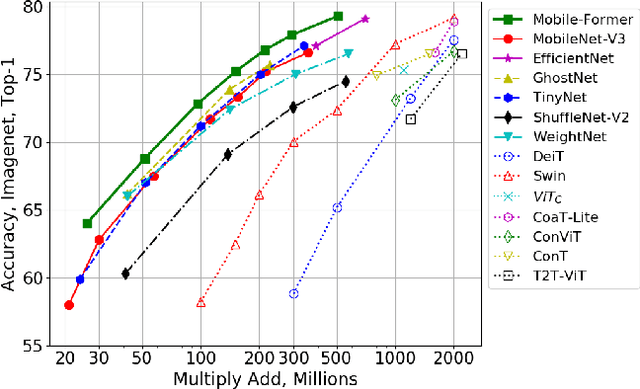
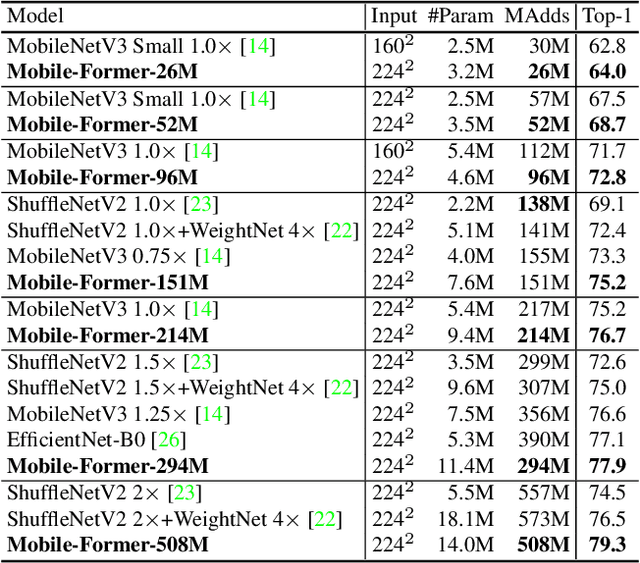
We present Mobile-Former, a parallel design of MobileNet and Transformer with a two-way bridge in between. This structure leverages the advantage of MobileNet at local processing and transformer at global interaction. And the bridge enables bidirectional fusion of local and global features. Different with recent works on vision transformer, the transformer in Mobile-Former contains very few tokens (e.g. less than 6 tokens) that are randomly initialized, resulting in low computational cost. Combining with the proposed light-weight cross attention to model the bridge, Mobile-Former is not only computationally efficient, but also has more representation power, outperforming MobileNetV3 at low FLOP regime from 25M to 500M FLOPs on ImageNet classification. For instance, it achieves 77.9\% top-1 accuracy at 294M FLOPs, gaining 1.3\% over MobileNetV3 but saving 17\% of computations. When transferring to object detection, Mobile-Former outperforms MobileNetV3 by 8.6 AP.
MicroNet: Improving Image Recognition with Extremely Low FLOPs
Aug 12, 2021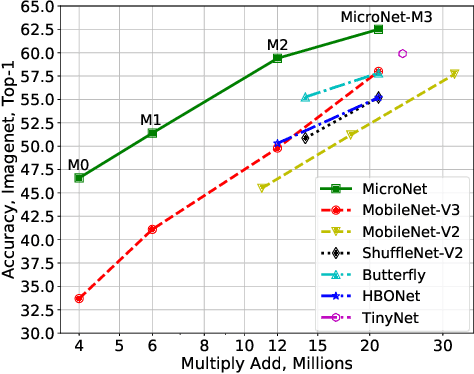
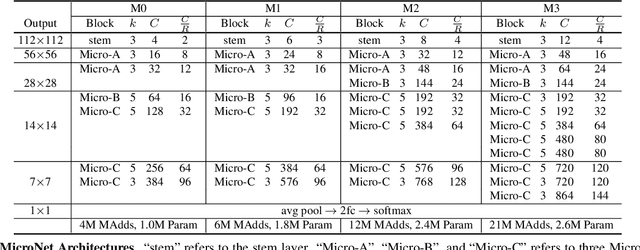
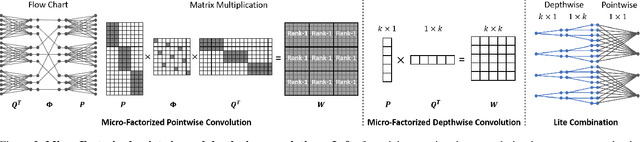
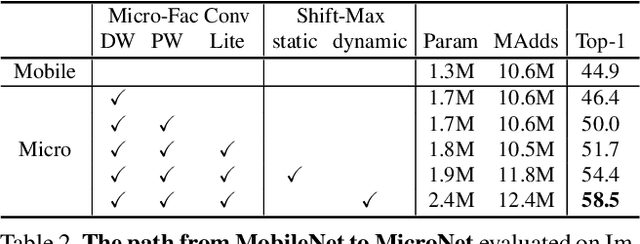
This paper aims at addressing the problem of substantial performance degradation at extremely low computational cost (e.g. 5M FLOPs on ImageNet classification). We found that two factors, sparse connectivity and dynamic activation function, are effective to improve the accuracy. The former avoids the significant reduction of network width, while the latter mitigates the detriment of reduction in network depth. Technically, we propose micro-factorized convolution, which factorizes a convolution matrix into low rank matrices, to integrate sparse connectivity into convolution. We also present a new dynamic activation function, named Dynamic Shift Max, to improve the non-linearity via maxing out multiple dynamic fusions between an input feature map and its circular channel shift. Building upon these two new operators, we arrive at a family of networks, named MicroNet, that achieves significant performance gains over the state of the art in the low FLOP regime. For instance, under the constraint of 12M FLOPs, MicroNet achieves 59.4\% top-1 accuracy on ImageNet classification, outperforming MobileNetV3 by 9.6\%. Source code is at \href{https://github.com/liyunsheng13/micronet}{https://github.com/liyunsheng13/micronet}.
Learning with Noisy Labels for Robust Point Cloud Segmentation
Aug 05, 2021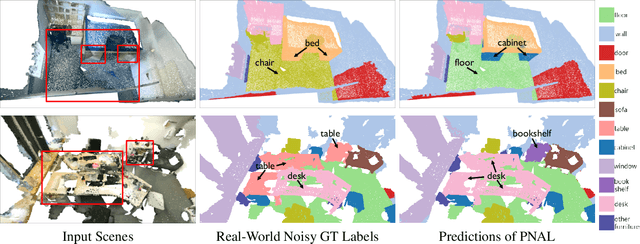
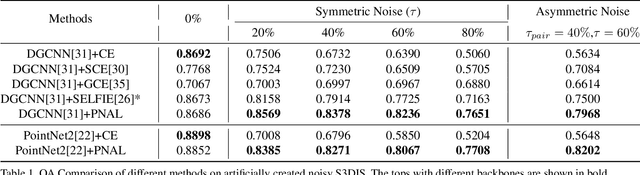
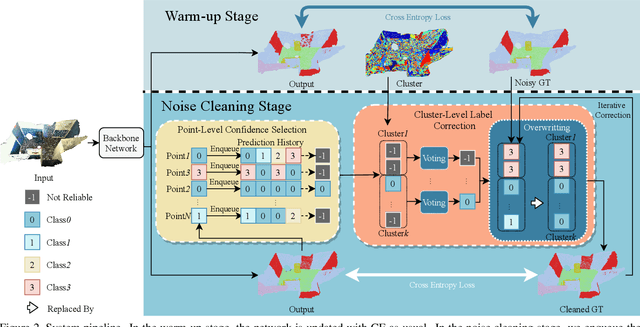
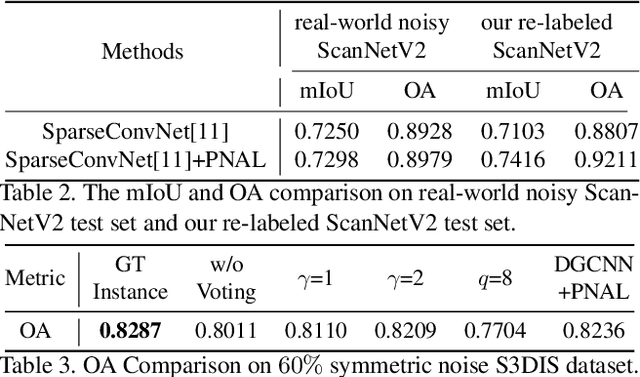
Point cloud segmentation is a fundamental task in 3D. Despite recent progress on point cloud segmentation with the power of deep networks, current deep learning methods based on the clean label assumptions may fail with noisy labels. Yet, object class labels are often mislabeled in real-world point cloud datasets. In this work, we take the lead in solving this issue by proposing a novel Point Noise-Adaptive Learning (PNAL) framework. Compared to existing noise-robust methods on image tasks, our PNAL is noise-rate blind, to cope with the spatially variant noise rate problem specific to point clouds. Specifically, we propose a novel point-wise confidence selection to obtain reliable labels based on the historical predictions of each point. A novel cluster-wise label correction is proposed with a voting strategy to generate the best possible label taking the neighbor point correlations into consideration. We conduct extensive experiments to demonstrate the effectiveness of PNAL on both synthetic and real-world noisy datasets. In particular, even with $60\%$ symmetric noisy labels, our proposed method produces much better results than its baseline counterpart without PNAL and is comparable to the ideal upper bound trained on a completely clean dataset. Moreover, we fully re-labeled the validation set of a popular but noisy real-world scene dataset ScanNetV2 to make it clean, for rigorous experiment and future research. Our code and data are available at \url{https://shuquanye.com/PNAL_website/}.
Exploring Structure Consistency for Deep Model Watermarking
Aug 05, 2021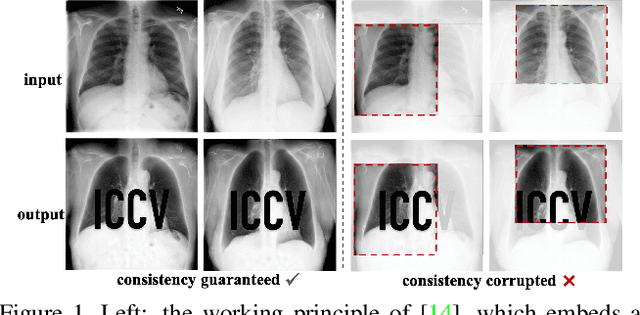
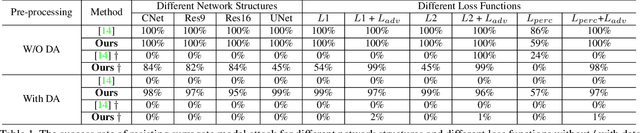

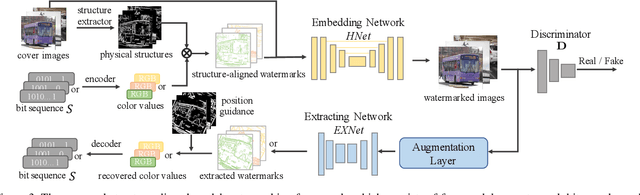
The intellectual property (IP) of Deep neural networks (DNNs) can be easily ``stolen'' by surrogate model attack. There has been significant progress in solutions to protect the IP of DNN models in classification tasks. However, little attention has been devoted to the protection of DNNs in image processing tasks. By utilizing consistent invisible spatial watermarks, one recent work first considered model watermarking for deep image processing networks and demonstrated its efficacy in many downstream tasks. Nevertheless, it highly depends on the hypothesis that the embedded watermarks in the network outputs are consistent. When the attacker uses some common data augmentation attacks (e.g., rotate, crop, and resize) during surrogate model training, it will totally fail because the underlying watermark consistency is destroyed. To mitigate this issue, we propose a new watermarking methodology, namely ``structure consistency'', based on which a new deep structure-aligned model watermarking algorithm is designed. Specifically, the embedded watermarks are designed to be aligned with physically consistent image structures, such as edges or semantic regions. Experiments demonstrate that our method is much more robust than the baseline method in resisting data augmentation attacks for model IP protection. Besides that, we further test the generalization ability and robustness of our method to a broader range of circumvention attacks.
Improve Unsupervised Pretraining for Few-label Transfer
Jul 26, 2021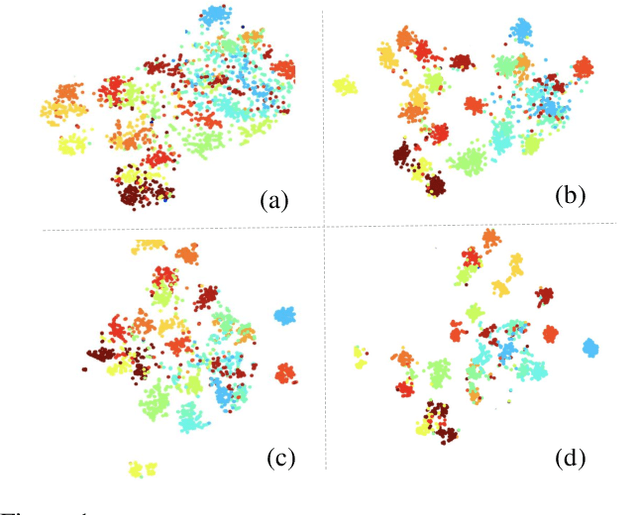
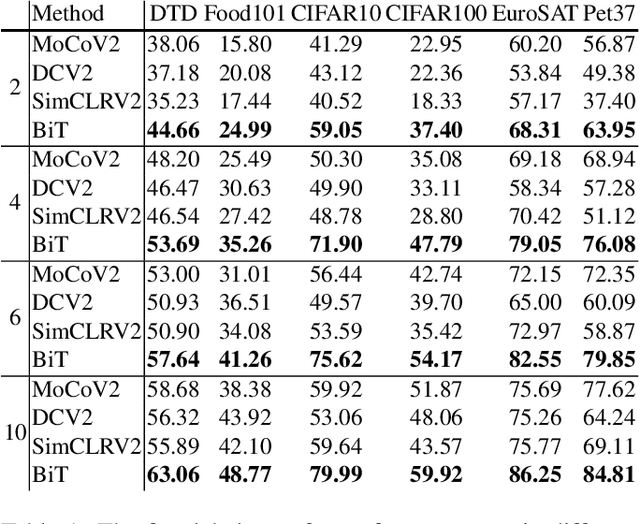
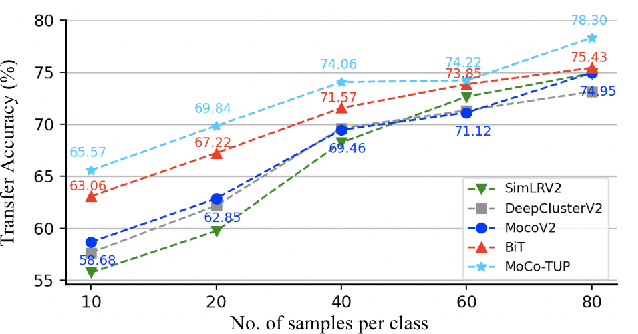
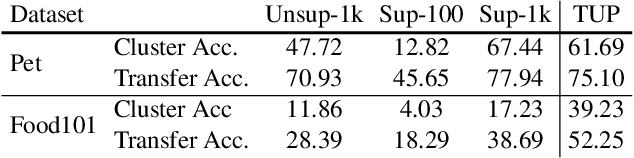
Unsupervised pretraining has achieved great success and many recent works have shown unsupervised pretraining can achieve comparable or even slightly better transfer performance than supervised pretraining on downstream target datasets. But in this paper, we find this conclusion may not hold when the target dataset has very few labeled samples for finetuning, \ie, few-label transfer. We analyze the possible reason from the clustering perspective: 1) The clustering quality of target samples is of great importance to few-label transfer; 2) Though contrastive learning is essential to learn how to cluster, its clustering quality is still inferior to supervised pretraining due to lack of label supervision. Based on the analysis, we interestingly discover that only involving some unlabeled target domain into the unsupervised pretraining can improve the clustering quality, subsequently reducing the transfer performance gap with supervised pretraining. This finding also motivates us to propose a new progressive few-label transfer algorithm for real applications, which aims to maximize the transfer performance under a limited annotation budget. To support our analysis and proposed method, we conduct extensive experiments on nine different target datasets. Experimental results show our proposed method can significantly boost the few-label transfer performance of unsupervised pretraining.
CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows
Jul 15, 2021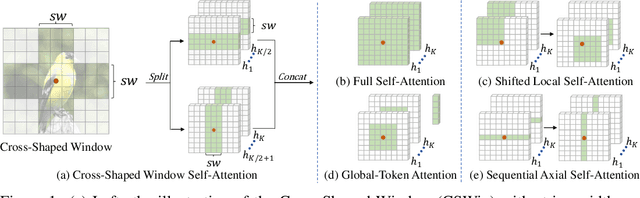

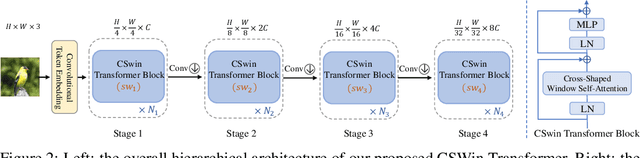
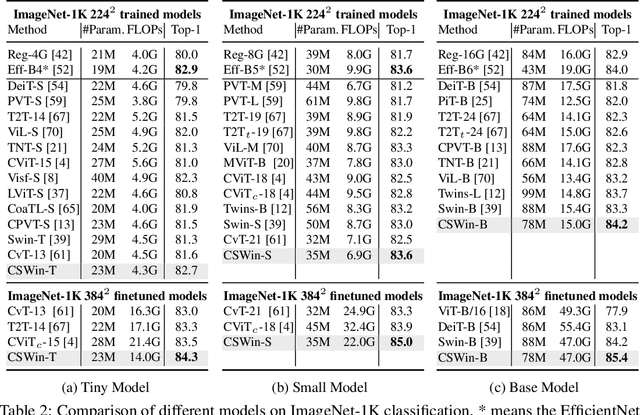
We present CSWin Transformer, an efficient and effective Transformer-based backbone for general-purpose vision tasks. A challenging issue in Transformer design is that global self-attention is very expensive to compute whereas local self-attention often limits the field of interactions of each token. To address this issue, we develop the Cross-Shaped Window self-attention mechanism for computing self-attention in the horizontal and vertical stripes in parallel that form a cross-shaped window, with each stripe obtained by splitting the input feature into stripes of equal width. We provide a detailed mathematical analysis of the effect of the stripe width and vary the stripe width for different layers of the Transformer network which achieves strong modeling capability while limiting the computation cost. We also introduce Locally-enhanced Positional Encoding (LePE), which handles the local positional information better than existing encoding schemes. LePE naturally supports arbitrary input resolutions, and is thus especially effective and friendly for downstream tasks. Incorporated with these designs and a hierarchical structure, CSWin Transformer demonstrates competitive performance on common vision tasks. Specifically, it achieves 85.4% Top-1 accuracy on ImageNet-1K without any extra training data or label, 53.9 box AP and 46.4 mask AP on the COCO detection task, and 51.7 mIOU on the ADE20K semantic segmentation task, surpassing previous state-of-the-art Swin Transformer backbone by +1.2, +2.0, +1.4, and +2.0 respectively under the similar FLOPs setting. By further pretraining on the larger dataset ImageNet-21K, we achieve 87.5% Top-1 accuracy on ImageNet-1K and state-of-the-art segmentation performance on ADE20K with 55.7 mIoU. The code and models will be available at https://github.com/microsoft/CSWin-Transformer.
Dynamic Head: Unifying Object Detection Heads with Attentions
Jun 15, 2021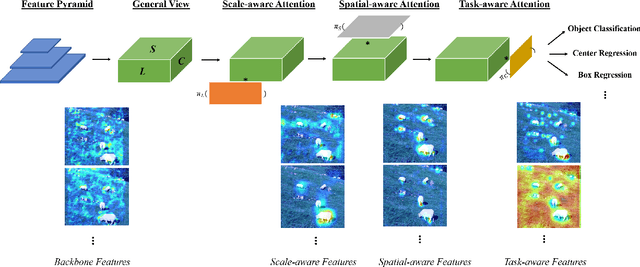
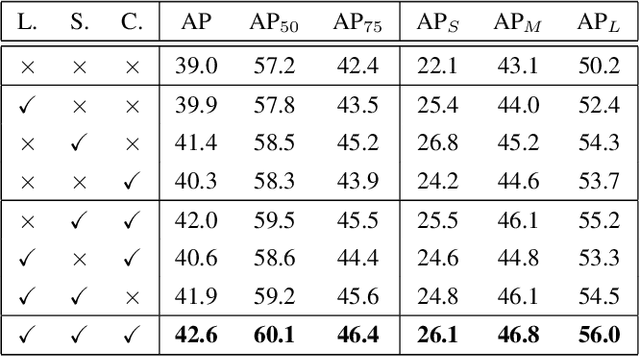
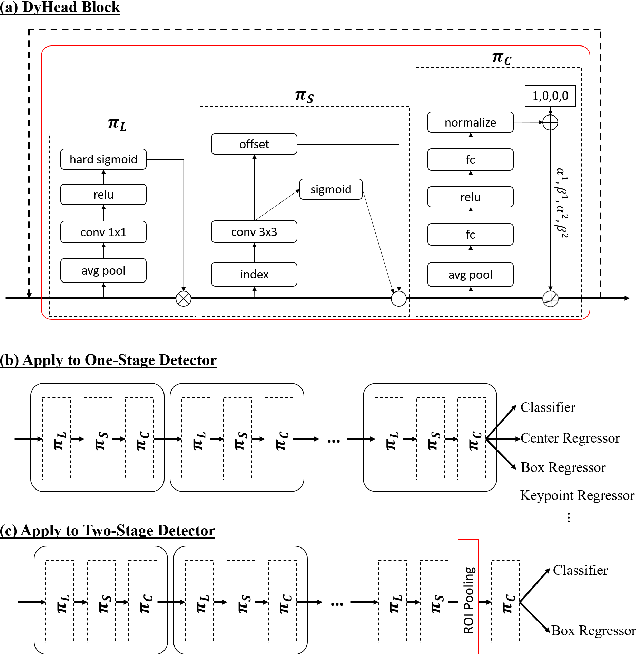
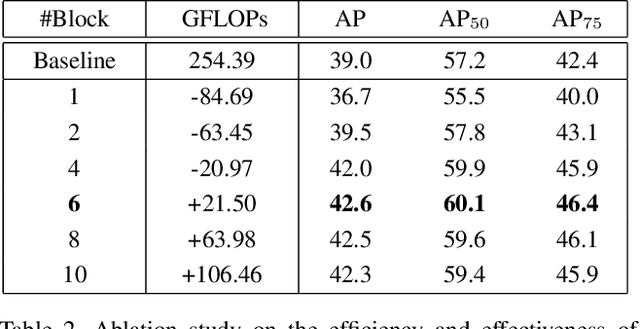
The complex nature of combining localization and classification in object detection has resulted in the flourished development of methods. Previous works tried to improve the performance in various object detection heads but failed to present a unified view. In this paper, we present a novel dynamic head framework to unify object detection heads with attentions. By coherently combining multiple self-attention mechanisms between feature levels for scale-awareness, among spatial locations for spatial-awareness, and within output channels for task-awareness, the proposed approach significantly improves the representation ability of object detection heads without any computational overhead. Further experiments demonstrate that the effectiveness and efficiency of the proposed dynamic head on the COCO benchmark. With a standard ResNeXt-101-DCN backbone, we largely improve the performance over popular object detectors and achieve a new state-of-the-art at 54.0 AP. Furthermore, with latest transformer backbone and extra data, we can push current best COCO result to a new record at 60.6 AP. The code will be released at https://github.com/microsoft/DynamicHead.
Cross-Domain and Disentangled Face Manipulation with 3D Guidance
Apr 22, 2021
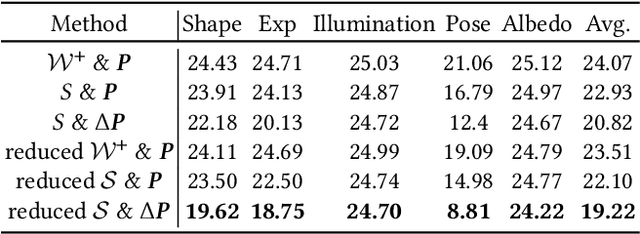
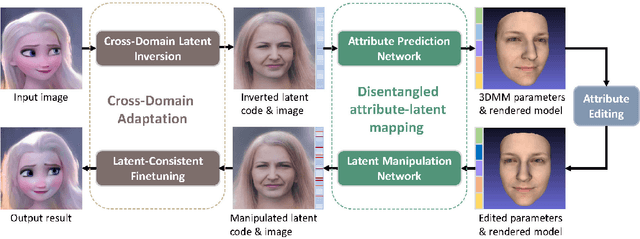
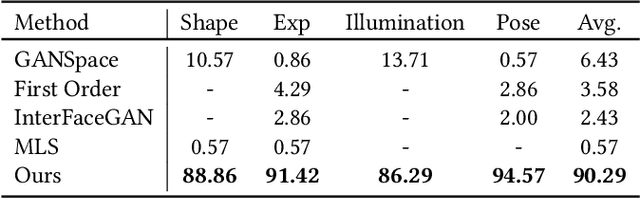
Face image manipulation via three-dimensional guidance has been widely applied in various interactive scenarios due to its semantically-meaningful understanding and user-friendly controllability. However, existing 3D-morphable-model-based manipulation methods are not directly applicable to out-of-domain faces, such as non-photorealistic paintings, cartoon portraits, or even animals, mainly due to the formidable difficulties in building the model for each specific face domain. To overcome this challenge, we propose, as far as we know, the first method to manipulate faces in arbitrary domains using human 3DMM. This is achieved through two major steps: 1) disentangled mapping from 3DMM parameters to the latent space embedding of a pre-trained StyleGAN2 that guarantees disentangled and precise controls for each semantic attribute; and 2) cross-domain adaptation that bridges domain discrepancies and makes human 3DMM applicable to out-of-domain faces by enforcing a consistent latent space embedding. Experiments and comparisons demonstrate the superiority of our high-quality semantic manipulation method on a variety of face domains with all major 3D facial attributes controllable: pose, expression, shape, albedo, and illumination. Moreover, we develop an intuitive editing interface to support user-friendly control and instant feedback. Our project page is https://cassiepython.github.io/sigasia/cddfm3d.html.
A Simple Baseline for StyleGAN Inversion
Apr 15, 2021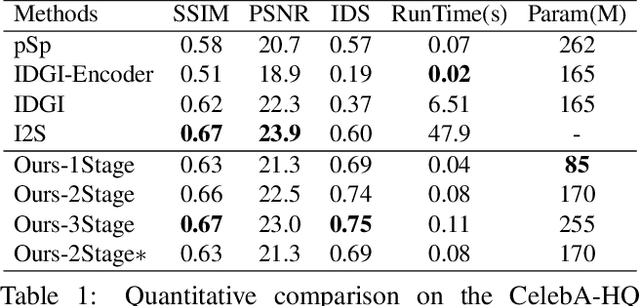
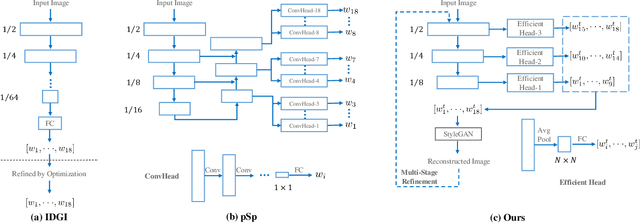
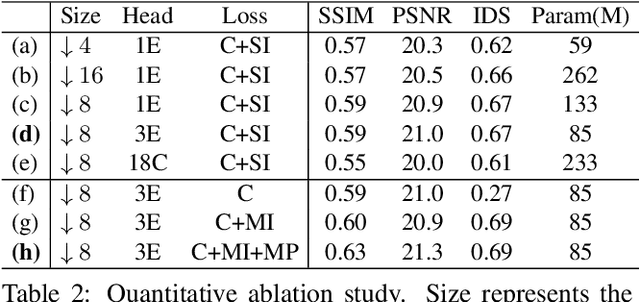

This paper studies the problem of StyleGAN inversion, which plays an essential role in enabling the pretrained StyleGAN to be used for real facial image editing tasks. This problem has the high demand for quality and efficiency. Existing optimization-based methods can produce high quality results, but the optimization often takes a long time. On the contrary, forward-based methods are usually faster but the quality of their results is inferior. In this paper, we present a new feed-forward network for StyleGAN inversion, with significant improvement in terms of efficiency and quality. In our inversion network, we introduce: 1) a shallower backbone with multiple efficient heads across scales; 2) multi-layer identity loss and multi-layer face parsing loss to the loss function; and 3) multi-stage refinement. Combining these designs together forms a simple and efficient baseline method which exploits all benefits of optimization-based and forward-based methods. Quantitative and qualitative results show that our method performs better than existing forward-based methods and comparably to state-of-the-art optimization-based methods, while maintaining the high efficiency as well as forward-based methods. Moreover, a number of real image editing applications demonstrate the efficacy of our method. Our project page is ~\url{https://wty-ustc.github.io/inversion}.