 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefRec: Preference-based Recommender Systems for Reinforcing Long-term User Engagement
Dec 06, 2022



Current advances in recommender systems have been remarkably successful in optimizing immediate engagement. However, long-term user engagement, a more desirable performance metric, remains difficult to improve. Meanwhile, recent reinforcement learning (RL) algorithms have shown their effectiveness in a variety of long-term goal optimization tasks. For this reason, RL is widely considered as a promising framework for optimizing long-term user engagement in recommendation. Despite being a promising approach, the application of RL heavily relies on well-designed rewards, but designing rewards related to long-term user engagement is quite difficult. To mitigate the problem, we propose a novel paradigm, Preference-based Recommender systems (PrefRec), which allows RL recommender systems to learn from preferences about users' historical behaviors rather than explicitly defined rewards. Such preferences are easily accessible through techniques such as crowdsourcing, as they do not require any expert knowledge. With PrefRec, we can fully exploit the advantages of RL in optimizing long-term goals, while avoiding complex reward engineering. PrefRec uses the preferences to automatically train a reward function in an end-to-end manner. The reward function is then used to generate learning signals to train the recommendation policy. Furthermore, we design an effective optimization method for PrefRec, which uses an additional value function, expectile regression and reward model pre-training to improve the performance. Extensive experiments are conducted on a variety of long-term user engagement optimization tasks. The results show that PrefRec significantly outperforms previous state-of-the-art methods in all the tasks.
Deconfounding Duration Bias in Watch-time Prediction for Video Recommendation
Jun 13, 2022

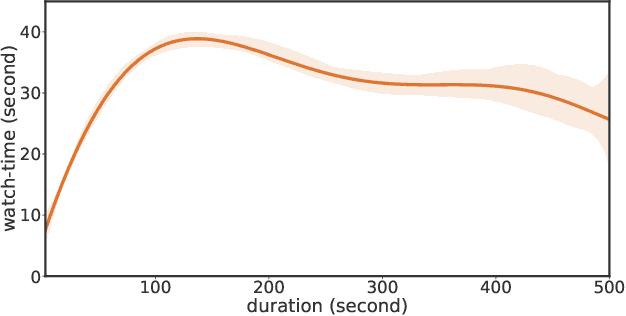
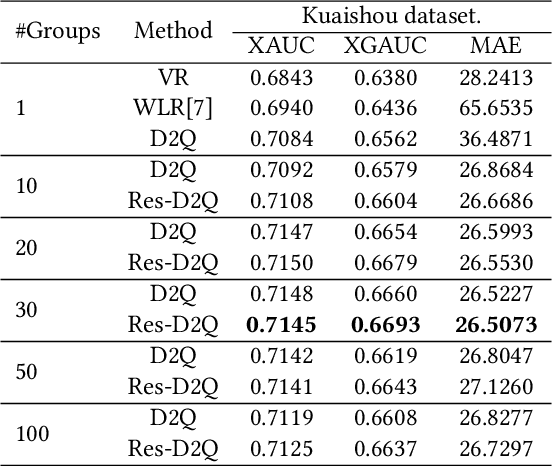
Watch-time prediction remains to be a key factor in reinforcing user engagement via video recommendations. It has become increasingly important given the ever-growing popularity of online videos. However, prediction of watch time not only depends on the match between the user and the video but is often mislead by the duration of the video itself. With the goal of improving watch time, recommendation is always biased towards videos with long duration. Models trained on this imbalanced data face the risk of bias amplification, which misguides platforms to over-recommend videos with long duration but overlook the underlying user interests. This paper presents the first work to study duration bias in watch-time prediction for video recommendation. We employ a causal graph illuminating that duration is a confounding factor that concurrently affects video exposure and watch-time prediction -- the first effect on video causes the bias issue and should be eliminated, while the second effect on watch time originates from video intrinsic characteristics and should be preserved. To remove the undesired bias but leverage the natural effect, we propose a Duration Deconfounded Quantile-based (D2Q) watch-time prediction framework, which allows for scalability to perform on industry production systems. Through extensive offline evaluation and live experiments, we showcase the effectiveness of this duration-deconfounding framework by significantly outperforming the state-of-the-art baselines. We have fully launched our approach on Kuaishou App, which has substantially improved real-time video consumption due to more accurate watch-time predictions.
ResAct: Reinforcing Long-term Engagement in Sequential Recommendation with Residual Actor
Jun 01, 2022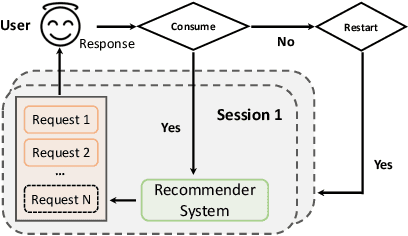
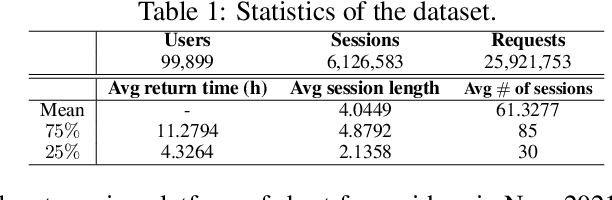
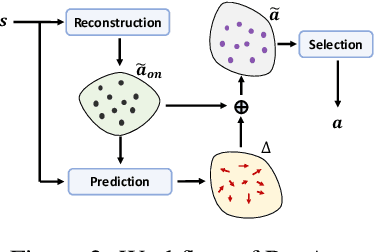
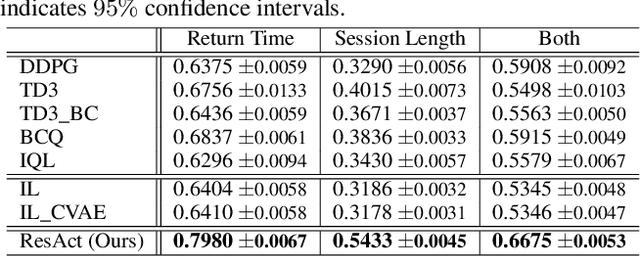
Long-term engagement is preferred over immediate engagement in sequential recommendation as it directly affects product operational metrics such as daily active users (DAUs) and dwell time. Meanwhile, reinforcement learning (RL) is widely regarded as a promising framework for optimizing long-term engagement in sequential recommendation. However, due to expensive online interactions, it is very difficult for RL algorithms to perform state-action value estimation, exploration and feature extraction when optimizing long-term engagement. In this paper, we propose ResAct which seeks a policy that is close to, but better than, the online-serving policy. In this way, we can collect sufficient data near the learned policy so that state-action values can be properly estimated, and there is no need to perform online exploration. Directly optimizing this policy is difficult due to the huge policy space. ResAct instead solves it by first reconstructing the online behaviors and then improving it. Our main contributions are fourfold. First, we design a generative model which reconstructs behaviors of the online-serving policy by sampling multiple action estimators. Second, we design an effective learning paradigm to train the residual actor which can output the residual for action improvement. Third, we facilitate the extraction of features with two information theoretical regularizers to confirm the expressiveness and conciseness of features. Fourth, we conduct extensive experiments on a real world dataset consisting of millions of sessions, and our method significantly outperforms the state-of-the-art baselines in various of long term engagement optimization tasks.
Constrained Reinforcement Learning for Short Video Recommendation
May 26, 2022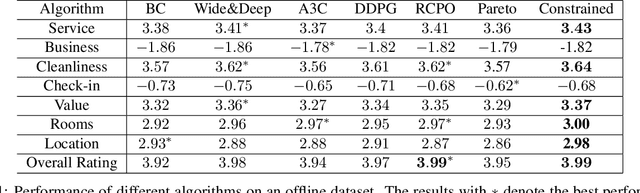
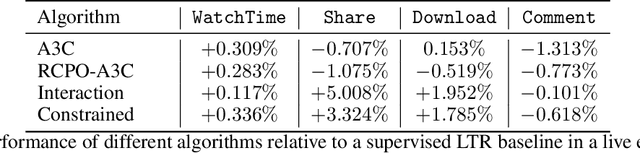
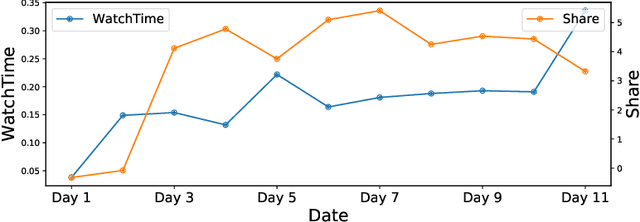
The wide popularity of short videos on social media poses new opportunities and challenges to optimize recommender systems on the video-sharing platforms. Users provide complex and multi-faceted responses towards recommendations, including watch time and various types of interactions with videos. As a result, established recommendation algorithms that concern a single objective are not adequate to meet this new demand of optimizing comprehensive user experiences. In this paper, we formulate the problem of short video recommendation as a constrained Markov Decision Process (MDP), where platforms want to optimize the main goal of user watch time in long term, with the constraint of accommodating the auxiliary responses of user interactions such as sharing/downloading videos. To solve the constrained MDP, we propose a two-stage reinforcement learning approach based on actor-critic framework. At stage one, we learn individual policies to optimize each auxiliary response. At stage two, we learn a policy to (i) optimize the main response and (ii) stay close to policies learned at the first stage, which effectively guarantees the performance of this main policy on the auxiliaries. Through extensive simulations, we demonstrate effectiveness of our approach over alternatives in both optimizing the main goal as well as balancing the others. We further show the advantage of our approach in live experiments of short video recommendations, where it significantly outperforms other baselines in terms of watch time and interactions from video views. Our approach has been fully launched in the production system to optimize user experiences on the platform.
PASTO: Strategic Parameter Optimization in Recommendation Systems -- Probabilistic is Better than Deterministic
Aug 20, 2021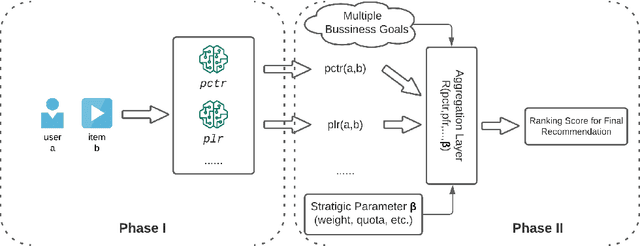
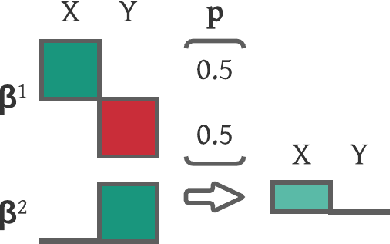

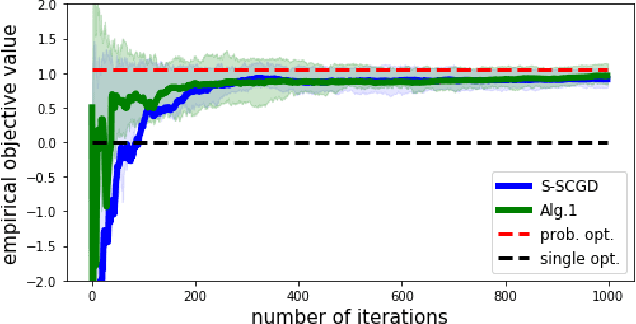
Real-world recommendation systems often consist of two phases. In the first phase, multiple predictive models produce the probability of different immediate user actions. In the second phase, these predictions are aggregated according to a set of 'strategic parameters' to meet a diverse set of business goals, such as longer user engagement, higher revenue potential, or more community/network interactions. In addition to building accurate predictive models, it is also crucial to optimize this set of 'strategic parameters' so that primary goals are optimized while secondary guardrails are not hurt. In this setting with multiple and constrained goals, this paper discovers that a probabilistic strategic parameter regime can achieve better value compared to the standard regime of finding a single deterministic parameter. The new probabilistic regime is to learn the best distribution over strategic parameter choices and sample one strategic parameter from the distribution when each user visits the platform. To pursue the optimal probabilistic solution, we formulate the problem into a stochastic compositional optimization problem, in which the unbiased stochastic gradient is unavailable. Our approach is applied in a popular social network platform with hundreds of millions of daily users and achieves +0.22% lift of user engagement in a recommendation task and +1.7% lift in revenue in an advertising optimization scenario comparing to using the best deterministic parameter strategy.