 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction Under Imperfect Compression: A Theory of Approximate MDL
Jun 03, 2026Minimum Description Length (MDL) formalizes the principle of Occam's razor by optimizing the total description length: $L(\mathrm{model})+L(\mathrm{data} \ | \ \mathrm{model})$. For sequential prediction, the MDL method repeatedly selects a model with a minimum objective score of the observed prefix for the next step prediction. Classical MDL prediction theory shows that exact optimization of the MDL objective indeed provides a strong compression guarantee that supports reliable prediction. However, practical machine learning usually can only find models by approximately optimizing the objective function. To bridge this gap, this paper addresses the following fundamental question: Under what forms of approximation and regularization does approximate MDL still guarantee reliable sequential prediction? This work offers a principled characterization. We prove that for any approximation with additive slack $C$ of the more general form of the balanced MDL objective: $λ\cdot L(\mathrm{model})+L(\mathrm{data} \ | \ \mathrm{model})$, the cumulative expected squared prediction error is finite for all $λ\ge1$. The case $λ>1$ is proved by an affinity-telescoping argument, while the boundary case $λ=1$ is proved by a likelihood-ratio stopping argument based on exact static MDL bounds. Our results establish that classical MDL regularization remains robust to any fixed additive optimization error. Furthermore, we establish that our characterization of the approximate MDL framework is sharp: When $0<λ<1$, overfits can happen to incur infinite cumulative expected error in the universal class of estimable measures, and hence a strong form of model-complexity regularization is necessary. In addition, model selection may fail in every regularized regime $λ>0$, under multiplicative approximation, and thus, additive approximation is both sufficient and essential.
PASTO: Strategic Parameter Optimization in Recommendation Systems -- Probabilistic is Better than Deterministic
Aug 20, 2021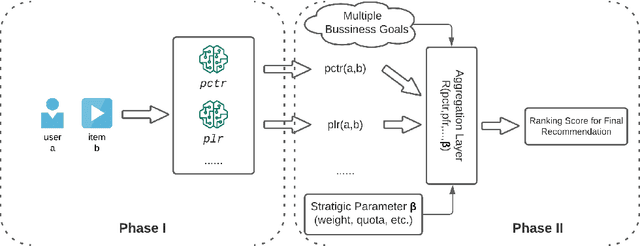
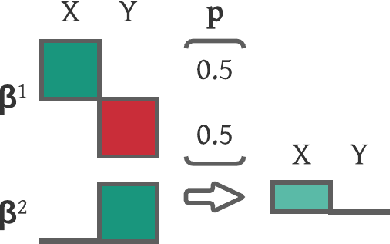

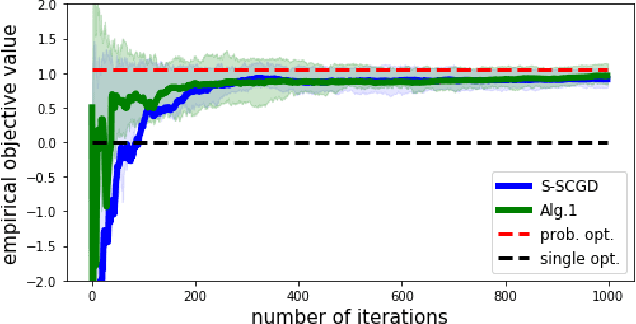
Real-world recommendation systems often consist of two phases. In the first phase, multiple predictive models produce the probability of different immediate user actions. In the second phase, these predictions are aggregated according to a set of 'strategic parameters' to meet a diverse set of business goals, such as longer user engagement, higher revenue potential, or more community/network interactions. In addition to building accurate predictive models, it is also crucial to optimize this set of 'strategic parameters' so that primary goals are optimized while secondary guardrails are not hurt. In this setting with multiple and constrained goals, this paper discovers that a probabilistic strategic parameter regime can achieve better value compared to the standard regime of finding a single deterministic parameter. The new probabilistic regime is to learn the best distribution over strategic parameter choices and sample one strategic parameter from the distribution when each user visits the platform. To pursue the optimal probabilistic solution, we formulate the problem into a stochastic compositional optimization problem, in which the unbiased stochastic gradient is unavailable. Our approach is applied in a popular social network platform with hundreds of millions of daily users and achieves +0.22% lift of user engagement in a recommendation task and +1.7% lift in revenue in an advertising optimization scenario comparing to using the best deterministic parameter strategy.