 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy-Preserving LLM Inference via Collaborative Obfuscation (Technical Report)
Mar 02, 2026The rapid development of large language models (LLMs) has driven the widespread adoption of cloud-based LLM inference services, while also bringing prominent privacy risks associated with the transmission and processing of private data in remote inference. For privacy-preserving LLM inference technologies to be practically applied in industrial scenarios, three core requirements must be satisfied simultaneously: (1) Accuracy and efficiency losses should be minimized to mitigate degradation in service experience. (2) The inference process can be run on large-scale clusters consist of heterogeneous legacy xPUs. (3) Compatibility with existing LLM infrastructures should be ensured to reuse their engineering optimizations. To the best of our knowledge, none of the existing privacy-preserving LLM inference methods satisfy all the above constraints while delivering meaningful privacy guarantees. In this paper, we propose AloePri, the first privacy-preserving LLM inference method for industrial applications. AloePri protects both the input and output data by covariant obfuscation, which jointly transforms data and model parameters to achieve better accuracy and privacy. We carefully design the transformation for each model component to ensure inference accuracy and data privacy while keeping full compatibility with existing infrastructures of Language Model as a Service. AloePri has been integrated into an industrial system for the evaluation of mainstream LLMs. The evaluation on Deepseek-V3.1-Terminus model (671B parameters) demonstrates that AloePri causes accuracy loss of 0.0%~3.5% and exhibits efficiency equivalent to that of plaintext inference. Meanwhile, AloePri successfully resists state-of-the-art attacks, with less than 5\% of tokens recovered. To the best of our knowledge, AloePri is the first method to exhibit practical applicability to large-scale models in real-world systems.
MORSE-STF: A Privacy Preserving Computation System
Sep 24, 2021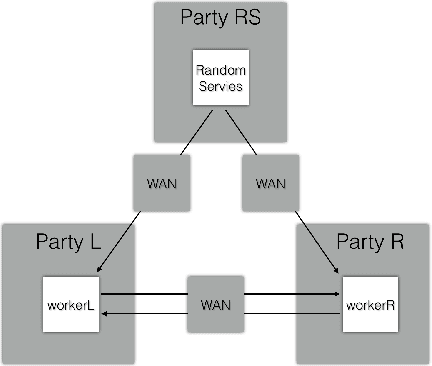
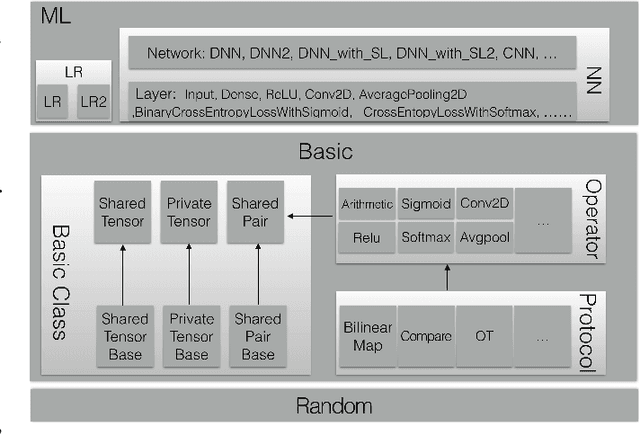

Privacy-preserving machine learning has become a popular area of research due to the increasing concern over data privacy. One way to achieve privacy-preserving machine learning is to use secure multi-party computation, where multiple distrusting parties can perform computations on data without revealing the data itself. We present Secure-TF, a privacy-preserving machine learning framework based on MPC. Our framework is able to support widely-used machine learning models such as logistic regression, fully-connected neural network, and convolutional neural network. We propose novel cryptographic protocols that has lower round complexity and less communication for computing sigmoid, ReLU, conv2D and there derivatives. All are central building blocks for modern machine learning models. With our more efficient protocols, our system is able to outperform previous state-of-the-art privacy-preserving machine learning framework in the WAN setting.
MPC Protocol for G-module and its Application in Secure Compare and ReLU
Jul 08, 2020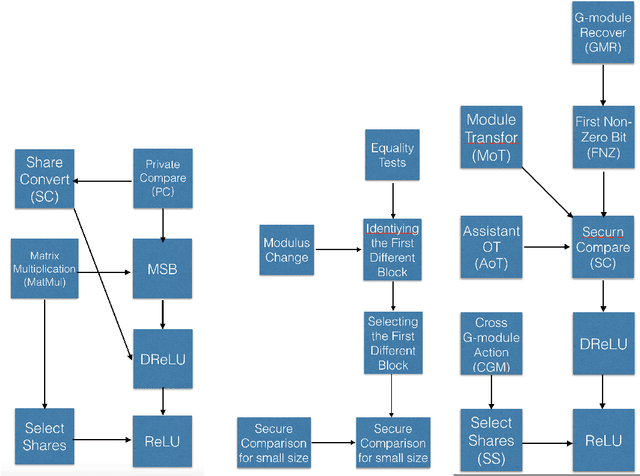



Secure multi-party computation (MPC) is a subfield of cryptography. Its aim is creating methods for multiple parties to jointly compute a function over their inputs meanwhile keeping their inputs privately. The Secure Compare problem, introduced by Yao under the name millionaire's problem, is an important problem in MPC. On the other hand, Privacy Preserving Machine Learning (PPML) is an intersectional field of cryptography and machine learning. It allows a group of independent data owners to collaboratively learn a model over their data sets without exposing their private data. MPC is a common cryptographic technique commonly used in PPML. In Deep learning, ReLU is an important layer. In order to train neural network to use MPC, we need an MPC protocol for ReLU and DReLU (the derivative of ReLU) in forward propagation and backward propagation of neural network respectively. In this paper, we give two new tools "G-module action" and "G-module recover" for MPC protocol, and use them to give the protocols for Secure Compare, DReLU and ReLU. The total communication in online and offline of our protocols is much less than the state of the art.
Matrix embedding method in match for session-based recommendation
Aug 27, 2019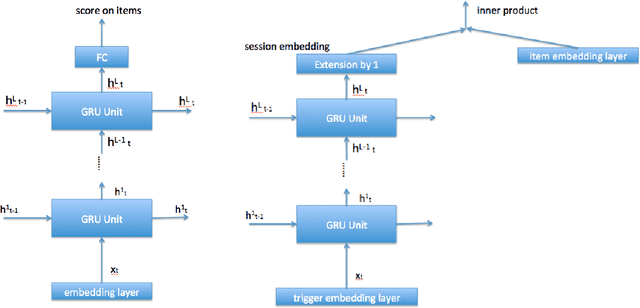

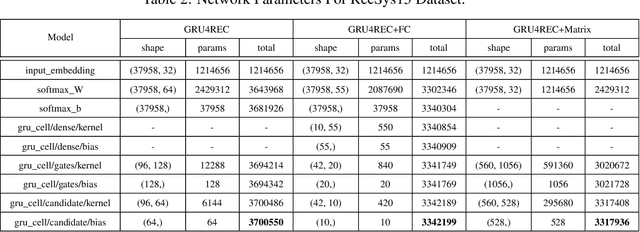
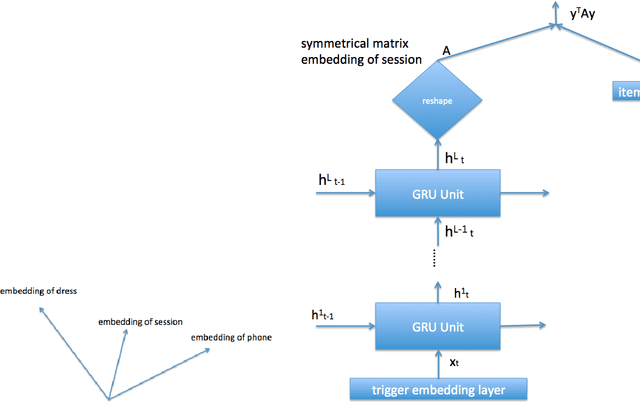
Session based model is widely used in recommend system. It use the user click sequence as input of a Recurrent Neural Network (RNN), and get the output of the RNN network as the vector embedding of the session, and use the inner product of the vector embedding of session and the vector embedding of the next item as the score that is the metric of the interest to the next item. This method can be used for the "match" stage for the recommendation system whose item number is very big by using some index method like KD-Tree or Ball-Tree and etc.. But this method repudiate the variousness of the interest of user in a session. We generated the model to modify the vector embedding of session to a symmetric matrix embedding, that is equivalent to a quadratic form on the vector space of items. The score is builded as the value of the vector embedding of next item under the quadratic form. The eigenvectors of the symmetric matrix embedding corresponding to the positive eigenvalues are conjectured to represent the interests of user in the session. This method can be used for the "match" stage also. The experiments show that this method is better than the method of vector embedding.
Large scale classification in deep neural network with Label Mapping
Jun 07, 2018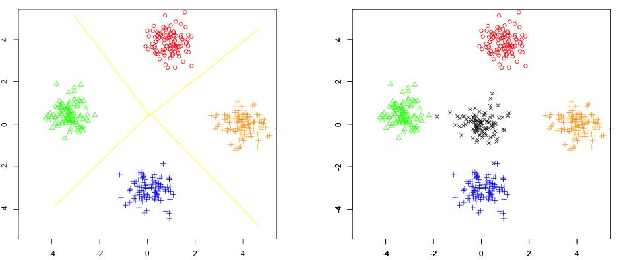
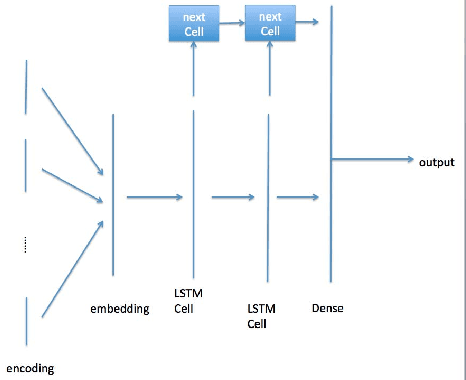
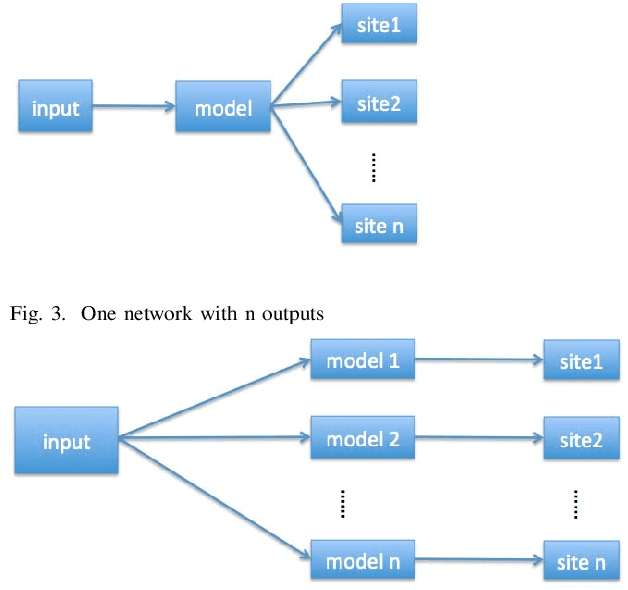
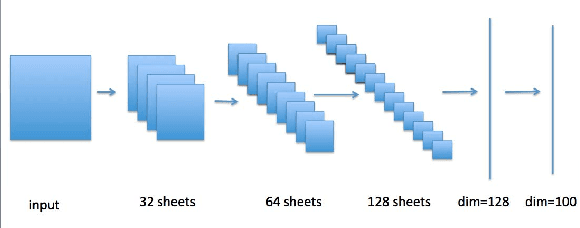
In recent years, deep neural network is widely used in machine learning. The multi-class classification problem is a class of important problem in machine learning. However, in order to solve those types of multi-class classification problems effectively, the required network size should have hyper-linear growth with respect to the number of classes. Therefore, it is infeasible to solve the multi-class classification problem using deep neural network when the number of classes are huge. This paper presents a method, so called Label Mapping (LM), to solve this problem by decomposing the original classification problem to several smaller sub-problems which are solvable theoretically. Our method is an ensemble method like error-correcting output codes (ECOC), but it allows base learners to be multi-class classifiers with different number of class labels. We propose two design principles for LM, one is to maximize the number of base classifier which can separate two different classes, and the other is to keep all base learners to be independent as possible in order to reduce the redundant information. Based on these principles, two different LM algorithms are derived using number theory and information theory. Since each base learner can be trained independently, it is easy to scale our method into a large scale training system. Experiments show that our proposed method outperforms the standard one-hot encoding and ECOC significantly in terms of accuracy and model complexity.