 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Instance Perception as Object Discovery and Retrieval
Mar 12, 2023



All instance perception tasks aim at finding certain objects specified by some queries such as category names, language expressions, and target annotations, but this complete field has been split into multiple independent subtasks. In this work, we present a universal instance perception model of the next generation, termed UNINEXT. UNINEXT reformulates diverse instance perception tasks into a unified object discovery and retrieval paradigm and can flexibly perceive different types of objects by simply changing the input prompts. This unified formulation brings the following benefits: (1) enormous data from different tasks and label vocabularies can be exploited for jointly training general instance-level representations, which is especially beneficial for tasks lacking in training data. (2) the unified model is parameter-efficient and can save redundant computation when handling multiple tasks simultaneously. UNINEXT shows superior performance on 20 challenging benchmarks from 10 instance-level tasks including classical image-level tasks (object detection and instance segmentation), vision-and-language tasks (referring expression comprehension and segmentation), and six video-level object tracking tasks. Code is available at https://github.com/MasterBin-IIAU/UNINEXT.
PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce
Feb 06, 2023



Re-ranking draws increased attention on both academics and industries, which rearranges the ranking list by modeling the mutual influence among items to better meet users' demands. Many existing re-ranking methods directly take the initial ranking list as input, and generate the optimal permutation through a well-designed context-wise model, which brings the evaluation-before-reranking problem. Meanwhile, evaluating all candidate permutations brings unacceptable computational costs in practice. Thus, to better balance efficiency and effectiveness, online systems usually use a two-stage architecture which uses some heuristic methods such as beam-search to generate a suitable amount of candidate permutations firstly, which are then fed into the evaluation model to get the optimal permutation. However, existing methods in both stages can be improved through the following aspects. As for generation stage, heuristic methods only use point-wise prediction scores and lack an effective judgment. As for evaluation stage, most existing context-wise evaluation models only consider the item context and lack more fine-grained feature context modeling. This paper presents a novel end-to-end re-ranking framework named PIER to tackle the above challenges which still follows the two-stage architecture and contains two mainly modules named FPSM and OCPM. We apply SimHash in FPSM to select top-K candidates from the full permutation based on user's permutation-level interest in an efficient way. Then we design a novel omnidirectional attention mechanism in OCPM to capture the context information in the permutation. Finally, we jointly train these two modules end-to-end by introducing a comparative learning loss. Offline experiment results demonstrate that PIER outperforms baseline models on both public and industrial datasets, and we have successfully deployed PIER on Meituan food delivery platform.
A Deep Behavior Path Matching Network for Click-Through Rate Prediction
Feb 01, 2023



User behaviors on an e-commerce app not only contain different kinds of feedback on items but also sometimes imply the cognitive clue of the user's decision-making. For understanding the psychological procedure behind user decisions, we present the behavior path and propose to match the user's current behavior path with historical behavior paths to predict user behaviors on the app. Further, we design a deep neural network for behavior path matching and solve three difficulties in modeling behavior paths: sparsity, noise interference, and accurate matching of behavior paths. In particular, we leverage contrastive learning to augment user behavior paths, provide behavior path self-activation to alleviate the effect of noise, and adopt a two-level matching mechanism to identify the most appropriate candidate. Our model shows excellent performance on two real-world datasets, outperforming the state-of-the-art CTR model. Moreover, our model has been deployed on the Meituan food delivery platform and has accumulated 1.6% improvement in CTR and 1.8% improvement in advertising revenue.
Decision-Making Context Interaction Network for Click-Through Rate Prediction
Jan 29, 2023



Click-through rate (CTR) prediction is crucial in recommendation and online advertising systems. Existing methods usually model user behaviors, while ignoring the informative context which influences the user to make a click decision, e.g., click pages and pre-ranking candidates that inform inferences about user interests, leading to suboptimal performance. In this paper, we propose a Decision-Making Context Interaction Network (DCIN), which deploys a carefully designed Context Interaction Unit (CIU) to learn decision-making contexts and thus benefits CTR prediction. In addition, the relationship between different decision-making context sources is explored by the proposed Adaptive Interest Aggregation Unit (AIAU) to improve CTR prediction further. In the experiments on public and industrial datasets, DCIN significantly outperforms the state-of-the-art methods. Notably, the model has obtained the improvement of CTR+2.9%/CPM+2.1%/GMV+1.5% for online A/B testing and served the main traffic of Meituan Waimai advertising system.
Direct Heterogeneous Causal Learning for Resource Allocation Problems in Marketing
Nov 30, 2022Marketing is an important mechanism to increase user engagement and improve platform revenue, and heterogeneous causal learning can help develop more effective strategies. Most decision-making problems in marketing can be formulated as resource allocation problems and have been studied for decades. Existing works usually divide the solution procedure into two fully decoupled stages, i.e., machine learning (ML) and operation research (OR) -- the first stage predicts the model parameters and they are fed to the optimization in the second stage. However, the error of the predicted parameters in ML cannot be respected and a series of complex mathematical operations in OR lead to the increased accumulative errors. Essentially, the improved precision on the prediction parameters may not have a positive correlation on the final solution due to the side-effect from the decoupled design. In this paper, we propose a novel approach for solving resource allocation problems to mitigate the side-effects. Our key intuition is that we introduce the decision factor to establish a bridge between ML and OR such that the solution can be directly obtained in OR by only performing the sorting or comparison operations on the decision factor. Furthermore, we design a customized loss function that can conduct direct heterogeneous causal learning on the decision factor, an unbiased estimation of which can be guaranteed when the loss converges. As a case study, we apply our approach to two crucial problems in marketing: the binary treatment assignment problem and the budget allocation problem with multiple treatments. Both large-scale simulations and online A/B Tests demonstrate that our approach achieves significant improvement compared with state-of-the-art.
Wasserstein Archetypal Analysis
Oct 25, 2022Archetypal analysis is an unsupervised machine learning method that summarizes data using a convex polytope. In its original formulation, for fixed k, the method finds a convex polytope with k vertices, called archetype points, such that the polytope is contained in the convex hull of the data and the mean squared Euclidean distance between the data and the polytope is minimal. In the present work, we consider an alternative formulation of archetypal analysis based on the Wasserstein metric, which we call Wasserstein archetypal analysis (WAA). In one dimension, there exists a unique solution of WAA and, in two dimensions, we prove existence of a solution, as long as the data distribution is absolutely continuous with respect to Lebesgue measure. We discuss obstacles to extending our result to higher dimensions and general data distributions. We then introduce an appropriate regularization of the problem, via a Renyi entropy, which allows us to obtain existence of solutions of the regularized problem for general data distributions, in arbitrary dimensions. We prove a consistency result for the regularized problem, ensuring that if the data are iid samples from a probability measure, then as the number of samples is increased, a subsequence of the archetype points converges to the archetype points for the limiting data distribution, almost surely. Finally, we develop and implement a gradient-based computational approach for the two-dimensional problem, based on the semi-discrete formulation of the Wasserstein metric. Our analysis is supported by detailed computational experiments.
QA Domain Adaptation using Hidden Space Augmentation and Self-Supervised Contrastive Adaptation
Oct 19, 2022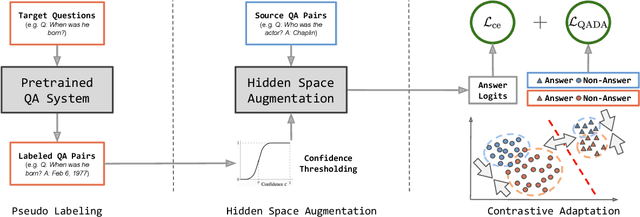
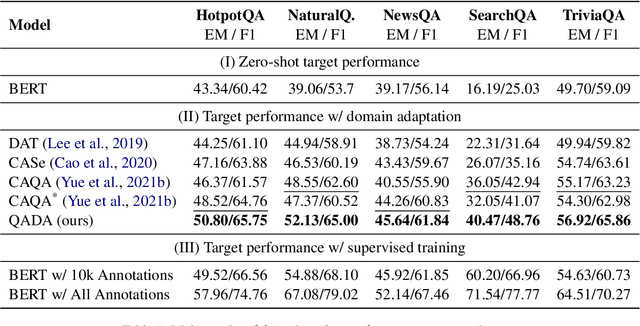
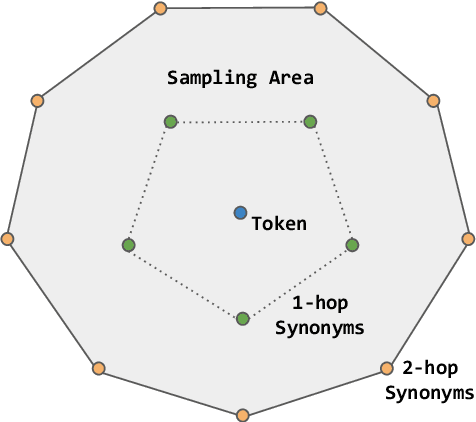
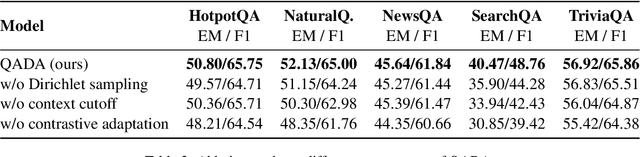
Question answering (QA) has recently shown impressive results for answering questions from customized domains. Yet, a common challenge is to adapt QA models to an unseen target domain. In this paper, we propose a novel self-supervised framework called QADA for QA domain adaptation. QADA introduces a novel data augmentation pipeline used to augment training QA samples. Different from existing methods, we enrich the samples via hidden space augmentation. For questions, we introduce multi-hop synonyms and sample augmented token embeddings with Dirichlet distributions. For contexts, we develop an augmentation method which learns to drop context spans via a custom attentive sampling strategy. Additionally, contrastive learning is integrated in the proposed self-supervised adaptation framework QADA. Unlike existing approaches, we generate pseudo labels and propose to train the model via a novel attention-based contrastive adaptation method. The attention weights are used to build informative features for discrepancy estimation that helps the QA model separate answers and generalize across source and target domains. To the best of our knowledge, our work is the first to leverage hidden space augmentation and attention-based contrastive adaptation for self-supervised domain adaptation in QA. Our evaluation shows that QADA achieves considerable improvements on multiple target datasets over state-of-the-art baselines in QA domain adaptation.
On Attacking Out-Domain Uncertainty Estimation in Deep Neural Networks
Oct 12, 2022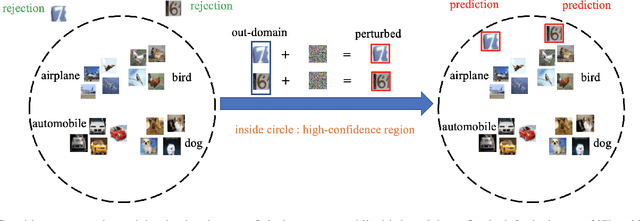
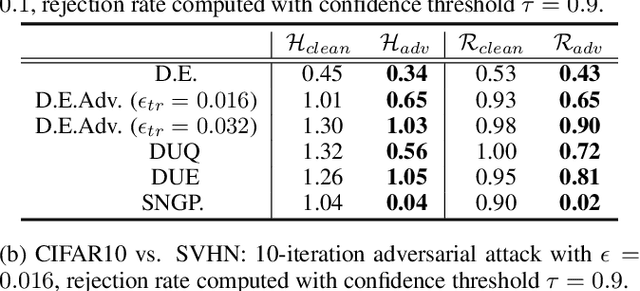
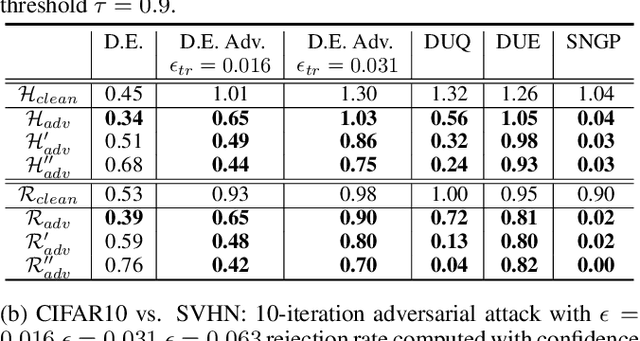
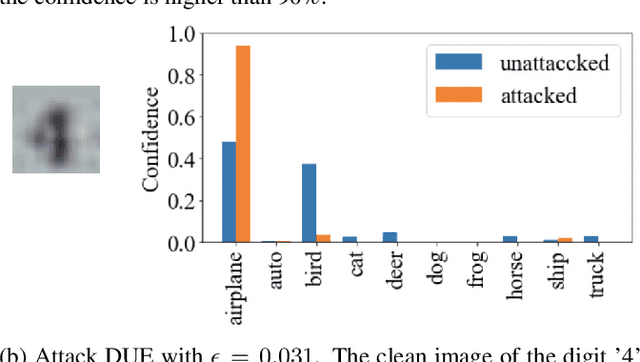
In many applications with real-world consequences, it is crucial to develop reliable uncertainty estimation for the predictions made by the AI decision systems. Targeting at the goal of estimating uncertainty, various deep neural network (DNN) based uncertainty estimation algorithms have been proposed. However, the robustness of the uncertainty returned by these algorithms has not been systematically explored. In this work, to raise the awareness of the research community on robust uncertainty estimation, we show that state-of-the-art uncertainty estimation algorithms could fail catastrophically under our proposed adversarial attack despite their impressive performance on uncertainty estimation. In particular, we aim at attacking the out-domain uncertainty estimation: under our attack, the uncertainty model would be fooled to make high-confident predictions for the out-domain data, which they originally would have rejected. Extensive experimental results on various benchmark image datasets show that the uncertainty estimated by state-of-the-art methods could be easily corrupted by our attack.
Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup
Oct 06, 2022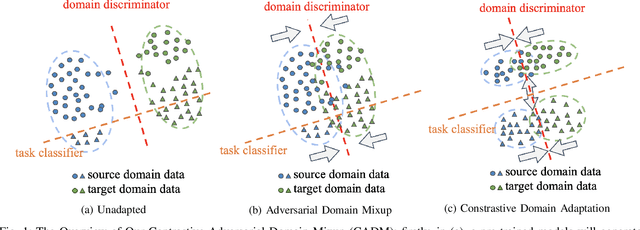
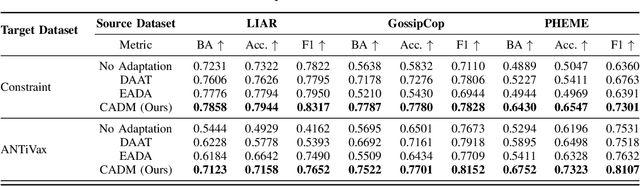
In the real-world application of COVID-19 misinformation detection, a fundamental challenge is the lack of the labeled COVID data to enable supervised end-to-end training of the models, especially at the early stage of the pandemic. To address this challenge, we propose an unsupervised domain adaptation framework using contrastive learning and adversarial domain mixup to transfer the knowledge from an existing source data domain to the target COVID-19 data domain. In particular, to bridge the gap between the source domain and the target domain, our method reduces a radial basis function (RBF) based discrepancy between these two domains. Moreover, we leverage the power of domain adversarial examples to establish an intermediate domain mixup, where the latent representations of the input text from both domains could be mixed during the training process. Extensive experiments on multiple real-world datasets suggest that our method can effectively adapt misinformation detection systems to the unseen COVID-19 target domain with significant improvements compared to the state-of-the-art baselines.
Multiscale Latent-Guided Entropy Model for LiDAR Point Cloud Compression
Sep 26, 2022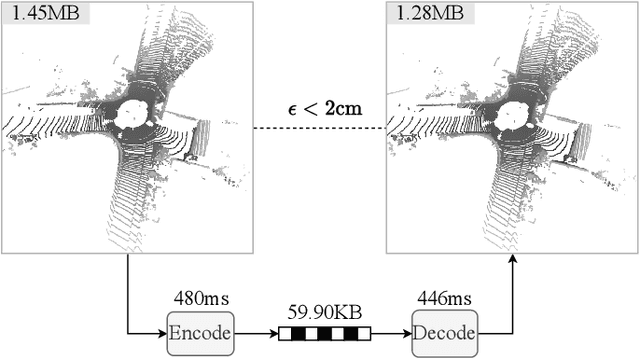
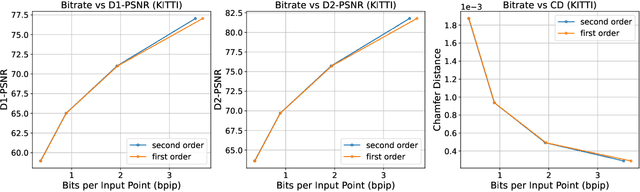
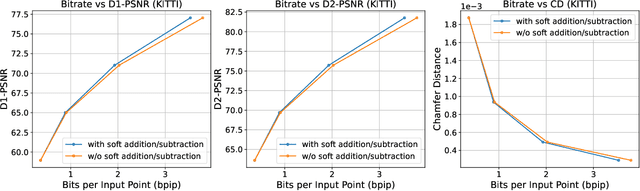

The non-uniform distribution and extremely sparse nature of the LiDAR point cloud (LPC) bring significant challenges to its high-efficient compression. This paper proposes a novel end-to-end, fully-factorized deep framework that encodes the original LPC into an octree structure and hierarchically decomposes the octree entropy model in layers. The proposed framework utilizes a hierarchical latent variable as side information to encapsulate the sibling and ancestor dependence, which provides sufficient context information for the modelling of point cloud distribution while enabling the parallel encoding and decoding of octree nodes in the same layer. Besides, we propose a residual coding framework for the compression of the latent variable, which explores the spatial correlation of each layer by progressive downsampling, and model the corresponding residual with a fully-factorized entropy model. Furthermore, we propose soft addition and subtraction for residual coding to improve network flexibility. The comprehensive experiment results on the LiDAR benchmark SemanticKITTI and MPEG-specified dataset Ford demonstrates that our proposed framework achieves state-of-the-art performance among all the previous LPC frameworks. Besides, our end-to-end, fully-factorized framework is proved by experiment to be high-parallelized and time-efficient and saves more than 99.8% of decoding time compared to previous state-of-the-art methods on LPC compression.