 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAST: Multiscale Audio Spectrogram Transformers
Nov 02, 2022We present Multiscale Audio Spectrogram Transformer (MAST) for audio classification, which brings the concept of multiscale feature hierarchies to the Audio Spectrogram Transformer (AST). Given an input audio spectrogram we first patchify and project it into an initial temporal resolution and embedding dimension, post which the multiple stages in MAST progressively expand the embedding dimension while reducing the temporal resolution of the input. We use a pyramid structure that allows early layers of MAST operating at a high temporal resolution but low embedding space to model simple low-level acoustic information and deeper temporally coarse layers to model high-level acoustic information with high-dimensional embeddings. We also extend our approach to present a new Self-Supervised Learning (SSL) method called SS-MAST, which calculates a symmetric contrastive loss between latent representations from a student and a teacher encoder. In practice, MAST significantly outperforms AST by an average accuracy of 3.4% across 8 speech and non-speech tasks from the LAPE Benchmark. Moreover, SS-MAST achieves an absolute average improvement of 2.6% over SSAST for both AST and MAST encoders. We make all our codes available on GitHub at the time of publication.
WGICP: Differentiable Weighted GICP-Based Lidar Odometry
Oct 03, 2022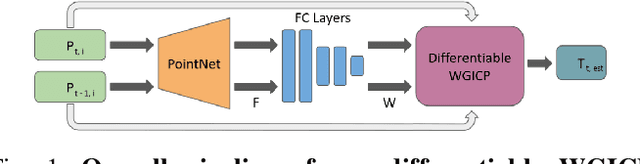
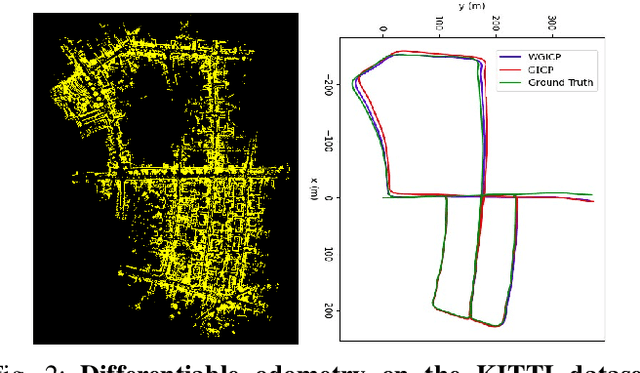
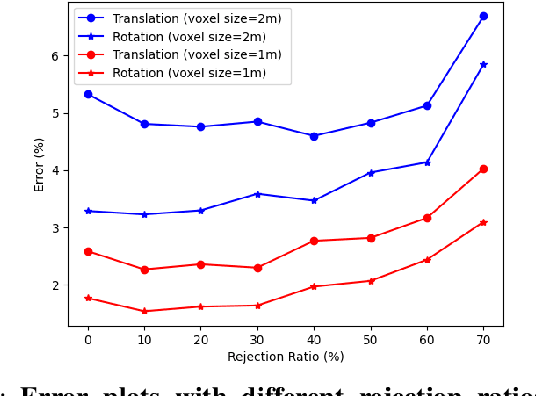
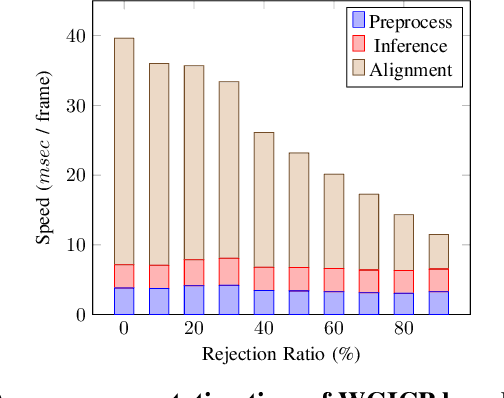
We present a novel differentiable weighted generalized iterative closest point (WGICP) method applicable to general 3D point cloud data, including that from Lidar. Our method builds on differentiable generalized ICP (GICP), and we propose using the differentiable K-Nearest Neighbor (KNN) algorithm to enhance differentiability. The differentiable GICP algorithm provides the gradient of output pose estimation with respect to each input point, which allows us to train a neural network to predict its importance, or weight, in estimating the correct pose. In contrast to the other ICP-based methods that use voxel-based downsampling or matching methods to reduce the computational cost, our method directly reduces the number of points used for GICP by only selecting those with the highest weights and ignoring redundant ones with lower weights. We show that our method improves both accuracy and speed of the GICP algorithm for the KITTI dataset and can be used to develop a more robust and efficient SLAM system.
DMCA: Dense Multi-agent Navigation using Attention and Communication
Sep 28, 2022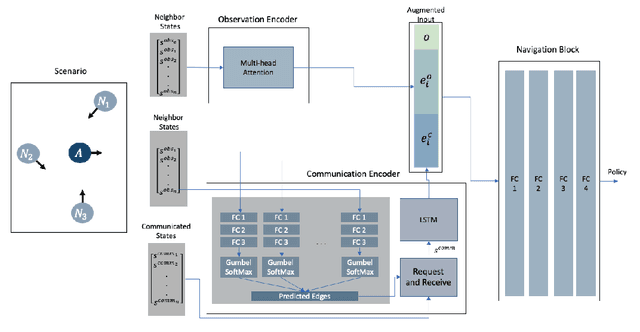
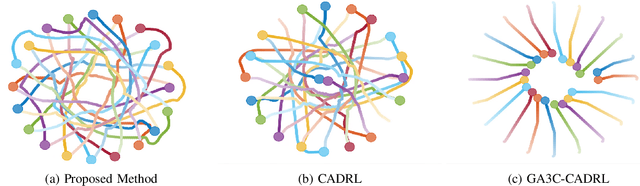


In decentralized multi-robot navigation, the agents lack the world knowledge to make safe and (near-)optimal plans reliably and make their decisions on their neighbors' observable states. We present a reinforcement learning based multi-agent navigation algorithm that performs inter-agent communications. In order to deal with the variable number of neighbors for each agent, we use a multi-head self-attention mechanism to encode neighbor information and create a fixed-length observation vector. We pose communication selection as a link prediction problem, where the network predicts whether communication is necessary given the observable information. The communicated information augments the observed neighbor information and is used to select a suitable navigation plan. We highlight the benefits of our approach by performing safe and efficient navigation among multiple robots in dense and challenging benchmarks. We also compare the performance with other learning-based methods and highlight improvements in terms of fewer collisions and time-to-goal in dense scenarios.
MSVIPER: Improved Policy Distillation for Reinforcement-Learning-Based Robot Navigation
Sep 19, 2022
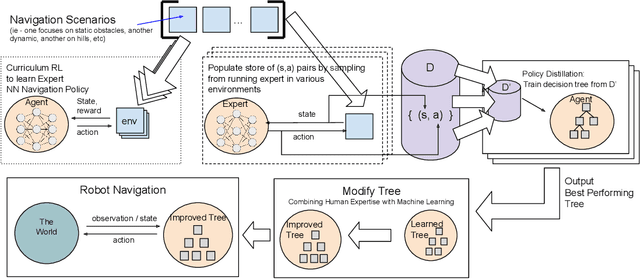
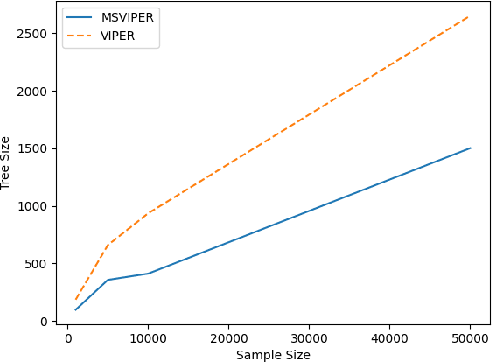

We present Multiple Scenario Verifiable Reinforcement Learning via Policy Extraction (MSVIPER), a new method for policy distillation to decision trees for improved robot navigation. MSVIPER learns an "expert" policy using any Reinforcement Learning (RL) technique involving learning a state-action mapping and then uses imitation learning to learn a decision-tree policy from it. We demonstrate that MSVIPER results in efficient decision trees and can accurately mimic the behavior of the expert policy. Moreover, we present efficient policy distillation and tree-modification techniques that take advantage of the decision tree structure to allow improvements to a policy without retraining. We use our approach to improve the performance of RL-based robot navigation algorithms for indoor and outdoor scenes. We demonstrate the benefits in terms of reduced freezing and oscillation behaviors (by up to 95\% reduction) for mobile robots navigating among dynamic obstacles and reduced vibrations and oscillation (by up to 17\%) for outdoor robot navigation on complex, uneven terrains.
Differentiable Frequency-based Disentanglement for Aerial Video Action Recognition
Sep 15, 2022
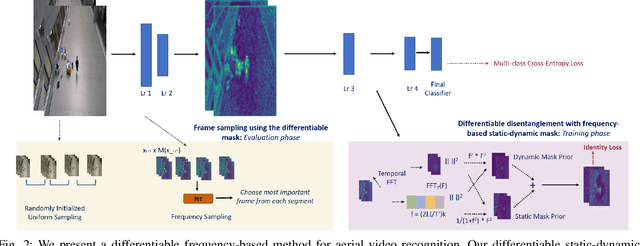

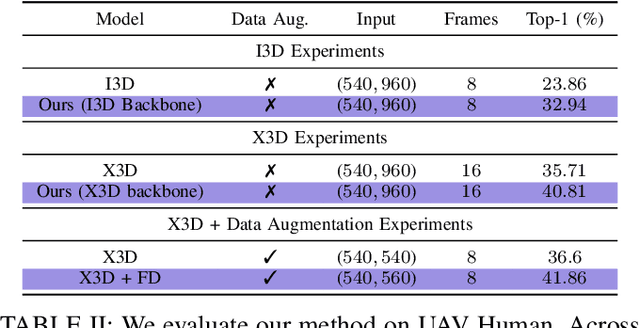
We present a learning algorithm for human activity recognition in videos. Our approach is designed for UAV videos, which are mainly acquired from obliquely placed dynamic cameras that contain a human actor along with background motion. Typically, the human actors occupy less than one-tenth of the spatial resolution. Our approach simultaneously harnesses the benefits of frequency domain representations, a classical analysis tool in signal processing, and data driven neural networks. We build a differentiable static-dynamic frequency mask prior to model the salient static and dynamic pixels in the video, crucial for the underlying task of action recognition. We use this differentiable mask prior to enable the neural network to intrinsically learn disentangled feature representations via an identity loss function. Our formulation empowers the network to inherently compute disentangled salient features within its layers. Further, we propose a cost-function encapsulating temporal relevance and spatial content to sample the most important frame within uniformly spaced video segments. We conduct extensive experiments on the UAV Human dataset and the NEC Drone dataset and demonstrate relative improvements of 5.72% - 13.00% over the state-of-the-art and 14.28% - 38.05% over the corresponding baseline model.
Placing Human Animations into 3D Scenes by Learning Interaction- and Geometry-Driven Keyframes
Sep 13, 2022
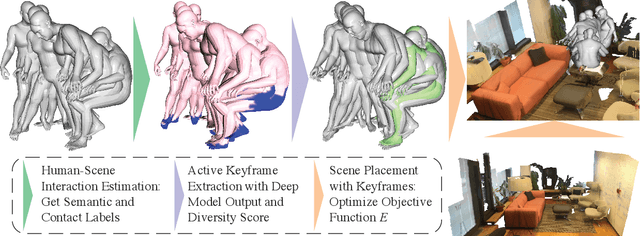
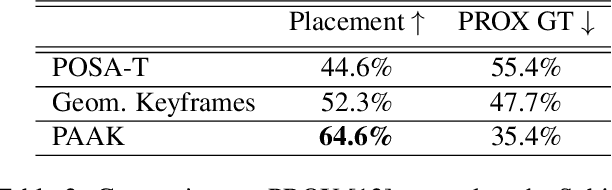
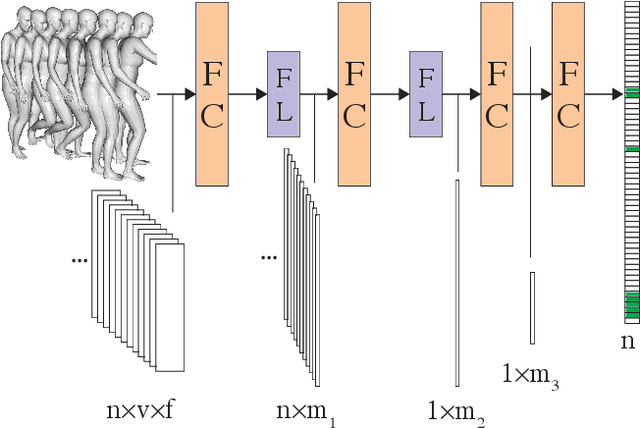
We present a novel method for placing a 3D human animation into a 3D scene while maintaining any human-scene interactions in the animation. We use the notion of computing the most important meshes in the animation for the interaction with the scene, which we call "keyframes." These keyframes allow us to better optimize the placement of the animation into the scene such that interactions in the animations (standing, laying, sitting, etc.) match the affordances of the scene (e.g., standing on the floor or laying in a bed). We compare our method, which we call PAAK, with prior approaches, including POSA, PROX ground truth, and a motion synthesis method, and highlight the benefits of our method with a perceptual study. Human raters preferred our PAAK method over the PROX ground truth data 64.6\% of the time. Additionally, in direct comparisons, the raters preferred PAAK over competing methods including 61.5\% compared to POSA.
RTAW: An Attention Inspired Reinforcement Learning Method for Multi-Robot Task Allocation in Warehouse Environments
Sep 13, 2022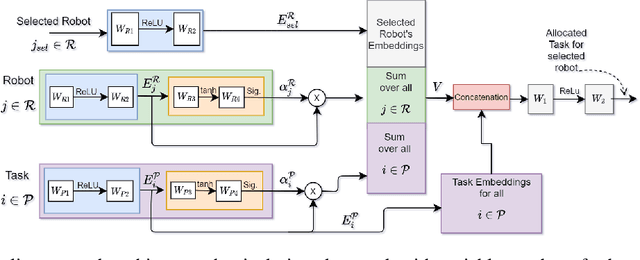
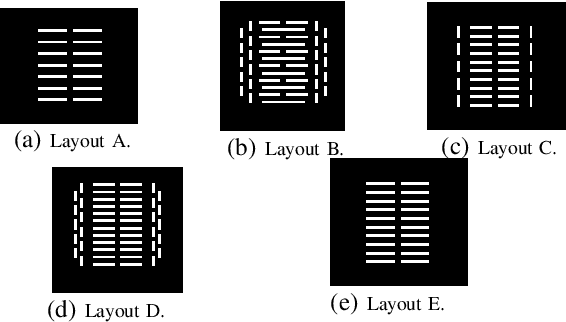
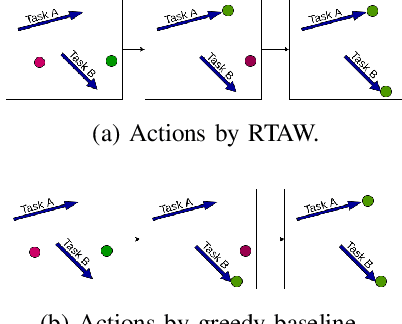
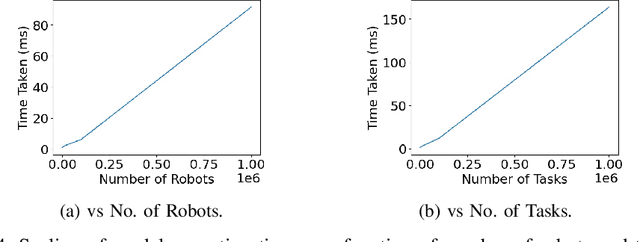
We present a novel reinforcement learning based algorithm for multi-robot task allocation problem in warehouse environments. We formulate it as a Markov Decision Process and solve via a novel deep multi-agent reinforcement learning method (called RTAW) with attention inspired policy architecture. Hence, our proposed policy network uses global embeddings that are independent of the number of robots/tasks. We utilize proximal policy optimization algorithm for training and use a carefully designed reward to obtain a converged policy. The converged policy ensures cooperation among different robots to minimize total travel delay (TTD) which ultimately improves the makespan for a sufficiently large task-list. In our extensive experiments, we compare the performance of our RTAW algorithm to state of the art methods such as myopic pickup distance minimization (greedy) and regret based baselines on different navigation schemes. We show an improvement of upto 14% (25-1000 seconds) in TTD on scenarios with hundreds or thousands of tasks for different challenging warehouse layouts and task generation schemes. We also demonstrate the scalability of our approach by showing performance with up to $1000$ robots in simulations.
GrASPE: Graph based Multimodal Fusion for Robot Navigation in Unstructured Outdoor Environments
Sep 13, 2022
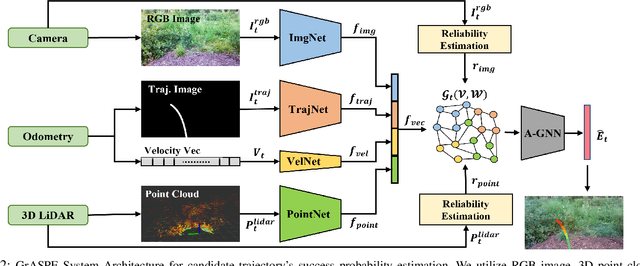

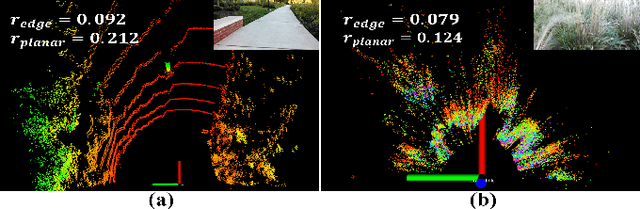
We present a novel trajectory traversability estimation and planning algorithm for robot navigation in complex outdoor environments. We incorporate multimodal sensory inputs from an RGB camera, 3D LiDAR, and robot's odometry sensor to train a prediction model to estimate candidate trajectories' success probabilities based on partially reliable multi-modal sensor observations. We encode high-dimensional multi-modal sensory inputs to low-dimensional feature vectors using encoder networks and represent them as a connected graph to train an attention-based Graph Neural Network (GNN) model to predict trajectory success probabilities. We further analyze the image and point cloud data separately to quantify sensor reliability to augment the weights of the feature graph representation used in our GNN. During runtime, our model utilizes multi-sensor inputs to predict the success probabilities of the trajectories generated by a local planner to avoid potential collisions and failures. Our algorithm demonstrates robust predictions when one or more sensor modalities are unreliable or unavailable in complex outdoor environments. We evaluate our algorithm's navigation performance using a Spot robot in real-world outdoor environments.
DC-MRTA: Decentralized Multi-Robot Task Allocation and Navigation in Complex Environments
Sep 07, 2022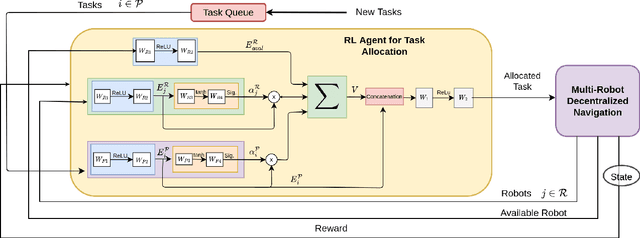
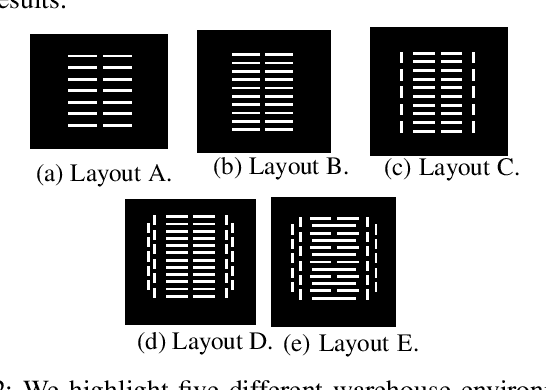
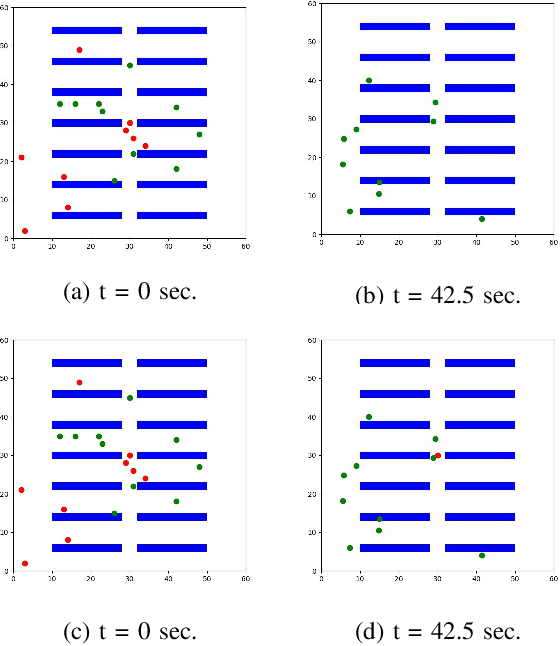
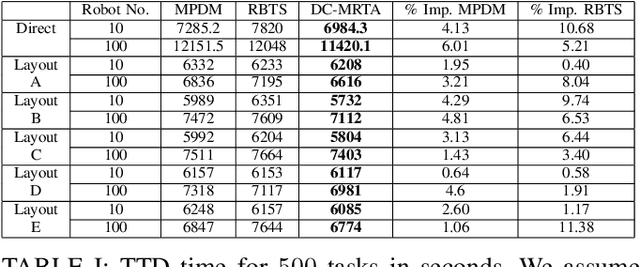
We present a novel reinforcement learning (RL) based task allocation and decentralized navigation algorithm for mobile robots in warehouse environments. Our approach is designed for scenarios in which multiple robots are used to perform various pick up and delivery tasks. We consider the problem of joint decentralized task allocation and navigation and present a two level approach to solve it. At the higher level, we solve the task allocation by formulating it in terms of Markov Decision Processes and choosing the appropriate rewards to minimize the Total Travel Delay (TTD). At the lower level, we use a decentralized navigation scheme based on ORCA that enables each robot to perform these tasks in an independent manner, and avoid collisions with other robots and dynamic obstacles. We combine these lower and upper levels by defining rewards for the higher level as the feedback from the lower level navigation algorithm. We perform extensive evaluation in complex warehouse layouts with large number of agents and highlight the benefits over state-of-the-art algorithms based on myopic pickup distance minimization and regret-based task selection. We observe improvement up to 14% in terms of task completion time and up-to 40% improvement in terms of computing collision-free trajectories for the robots.
Vision-Centric BEV Perception: A Survey
Aug 04, 2022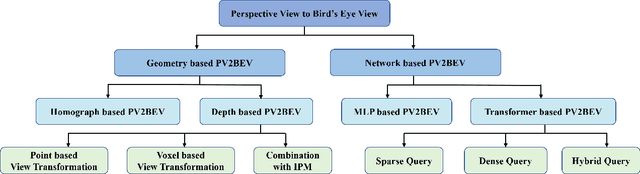

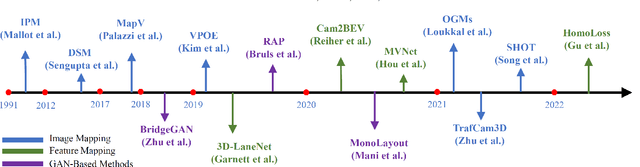
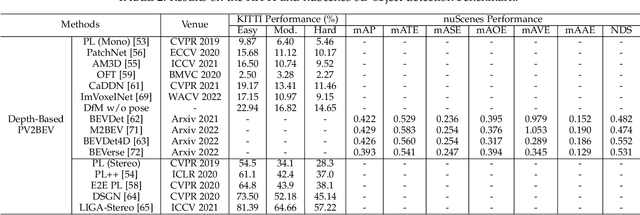
Vision-centric BEV perception has recently received increased attention from both industry and academia due to its inherent merits, including presenting a natural representation of the world and being fusion-friendly. With the rapid development of deep learning, numerous methods have been proposed to address the vision-centric BEV perception. However, there is no recent survey for this novel and growing research field. To stimulate its future research, this paper presents a comprehensive survey of recent progress of vision-centric BEV perception and its extensions. It collects and organizes the recent knowledge, and gives a systematic review and summary of commonly used algorithms. It also provides in-depth analyses and comparative results on several BEV perception tasks, facilitating the comparisons of future works and inspiring future research directions. Moreover, empirical implementation details are also discussed and shown to benefit the development of related algorithms.