 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamics Model in Reinforcement Learning by Incorporating the Long Term Future
Mar 16, 2019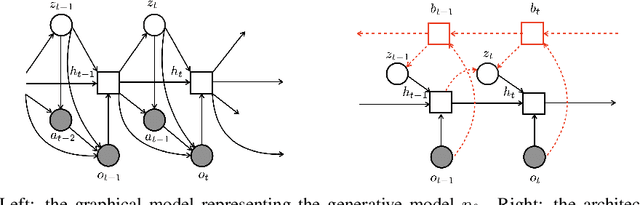
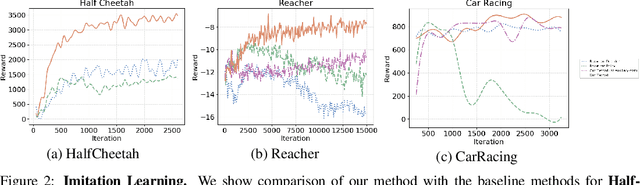
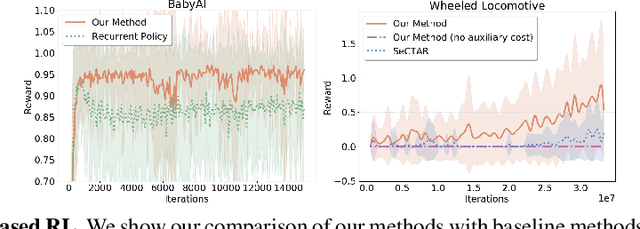
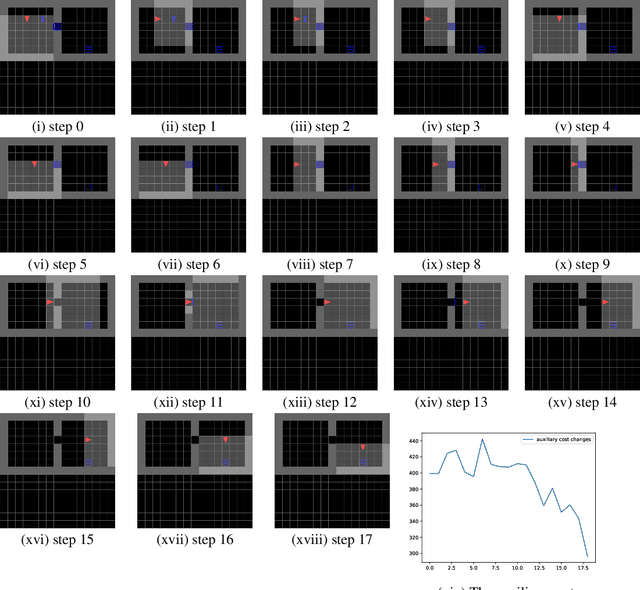
In model-based reinforcement learning, the agent interleaves between model learning and planning. These two components are inextricably intertwined. If the model is not able to provide sensible long-term prediction, the executed planner would exploit model flaws, which can yield catastrophic failures. This paper focuses on building a model that reasons about the long-term future and demonstrates how to use this for efficient planning and exploration. To this end, we build a latent-variable autoregressive model by leveraging recent ideas in variational inference. We argue that forcing latent variables to carry future information through an auxiliary task substantially improves long-term predictions. Moreover, by planning in the latent space, the planner's solution is ensured to be within regions where the model is valid. An exploration strategy can be devised by searching for unlikely trajectories under the model. Our method achieves higher reward faster compared to baselines on a variety of tasks and environments in both the imitation learning and model-based reinforcement learning settings.
CLEVR-Dialog: A Diagnostic Dataset for Multi-Round Reasoning in Visual Dialog
Mar 07, 2019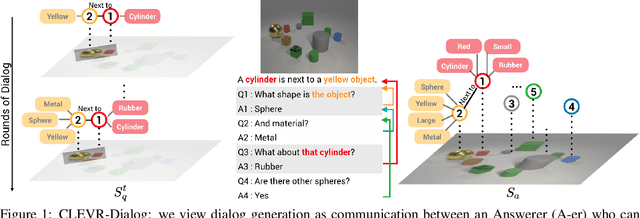
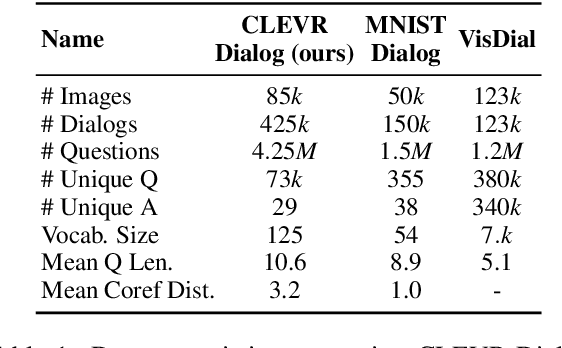
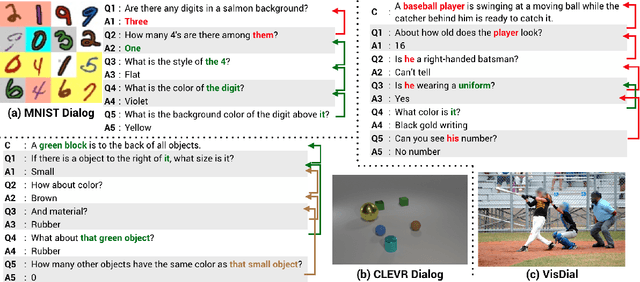
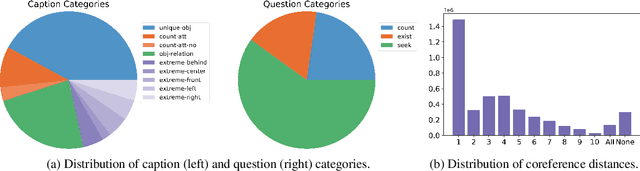
Visual Dialog is a multimodal task of answering a sequence of questions grounded in an image, using the conversation history as context. It entails challenges in vision, language, reasoning, and grounding. However, studying these subtasks in isolation on large, real datasets is infeasible as it requires prohibitively-expensive complete annotation of the 'state' of all images and dialogs. We develop CLEVR-Dialog, a large diagnostic dataset for studying multi-round reasoning in visual dialog. Specifically, we construct a dialog grammar that is grounded in the scene graphs of the images from the CLEVR dataset. This combination results in a dataset where all aspects of the visual dialog are fully annotated. In total, CLEVR-Dialog contains 5 instances of 10-round dialogs for about 85k CLEVR images, totaling to 4.25M question-answer pairs. We use CLEVR-Dialog to benchmark performance of standard visual dialog models; in particular, on visual coreference resolution (as a function of the coreference distance). This is the first analysis of its kind for visual dialog models that was not possible without this dataset. We hope the findings from CLEVR-Dialog will help inform the development of future models for visual dialog. Our dataset and code will be made public.
Probabilistic Neural-symbolic Models for Interpretable Visual Question Answering
Feb 21, 2019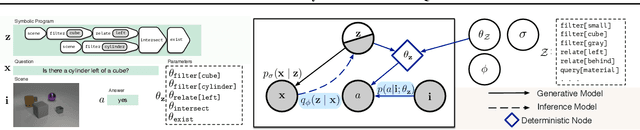
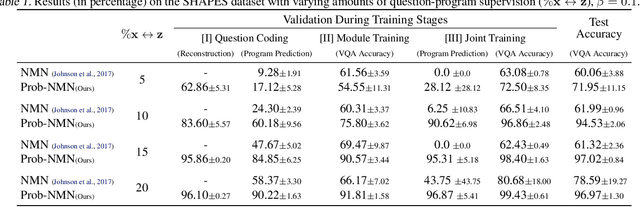
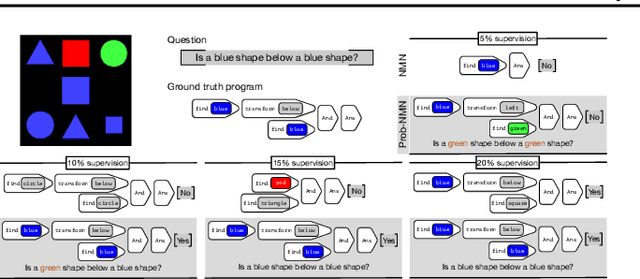

We propose a new class of probabilistic neural-symbolic models, that have symbolic functional programs as a latent, stochastic variable. Instantiated in the context of visual question answering, our probabilistic formulation offers two key conceptual advantages over prior neural-symbolic models for VQA. Firstly, the programs generated by our model are more understandable while requiring lesser number of teaching examples. Secondly, we show that one can pose counterfactual scenarios to the model, to probe its beliefs on the programs that could lead to a specified answer given an image. Our results on the CLEVR and SHAPES datasets verify our hypotheses, showing that the model gets better program (and answer) prediction accuracy even in the low data regime, and allows one to probe the coherence and consistency of reasoning performed.
Taking a HINT: Leveraging Explanations to Make Vision and Language Models More Grounded
Feb 11, 2019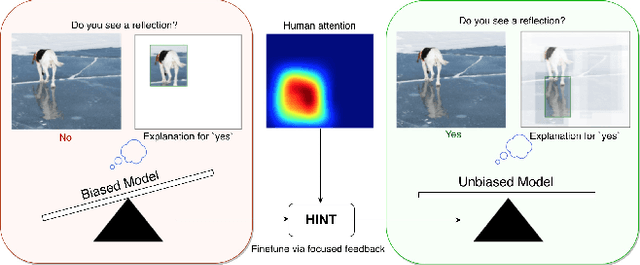
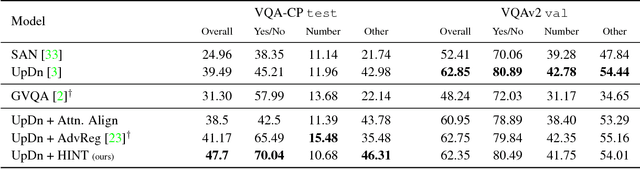
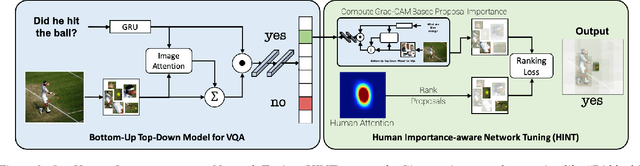

Many vision and language models suffer from poor visual grounding - often falling back on easy-to-learn language priors rather than associating language with visual concepts. In this work, we propose a generic framework which we call Human Importance-aware Network Tuning (HINT) that effectively leverages human supervision to improve visual grounding. HINT constrains deep networks to be sensitive to the same input regions as humans. Crucially, our approach optimizes the alignment between human attention maps and gradient-based network importances - ensuring that models learn not just to look at but rather rely on visual concepts that humans found relevant for a task when making predictions. We demonstrate our approach on Visual Question Answering and Image Captioning tasks, achieving state of-the-art for the VQA-CP dataset which penalizes over-reliance on language priors.
EvalAI: Towards Better Evaluation Systems for AI Agents
Feb 10, 2019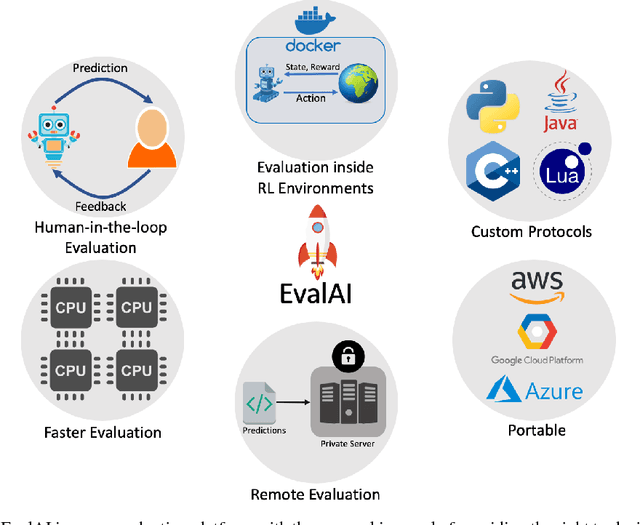

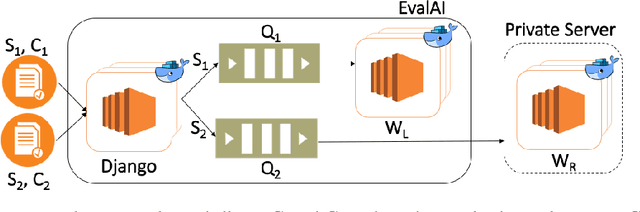
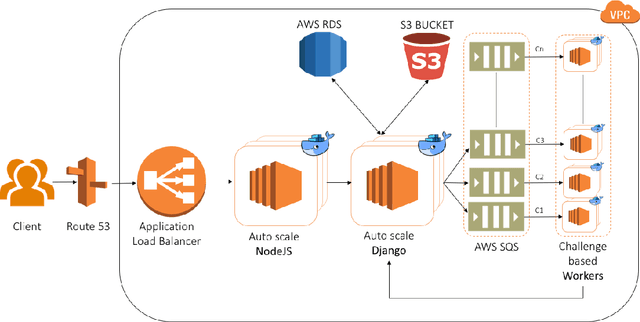
We introduce EvalAI, an open source platform for evaluating and comparing machine learning (ML) and artificial intelligence algorithms (AI) at scale. EvalAI is built to provide a scalable solution to the research community to fulfill the critical need of evaluating machine learning models and agents acting in an environment against annotations or with a human-in-the-loop. This will help researchers, students, and data scientists to create, collaborate, and participate in AI challenges organized around the globe. By simplifying and standardizing the process of benchmarking these models, EvalAI seeks to lower the barrier to entry for participating in the global scientific effort to push the frontiers of machine learning and artificial intelligence, thereby increasing the rate of measurable progress in this domain.
Embodied Multimodal Multitask Learning
Feb 04, 2019

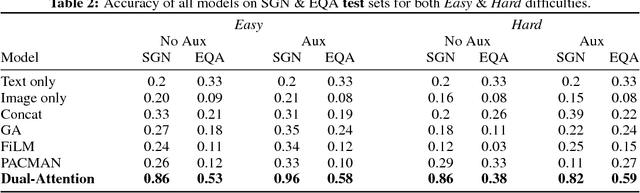
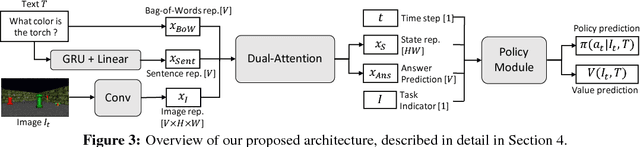
Recent efforts on training visual navigation agents conditioned on language using deep reinforcement learning have been successful in learning policies for different multimodal tasks, such as semantic goal navigation and embodied question answering. In this paper, we propose a multitask model capable of jointly learning these multimodal tasks, and transferring knowledge of words and their grounding in visual objects across the tasks. The proposed model uses a novel Dual-Attention unit to disentangle the knowledge of words in the textual representations and visual concepts in the visual representations, and align them with each other. This disentangled task-invariant alignment of representations facilitates grounding and knowledge transfer across both tasks. We show that the proposed model outperforms a range of baselines on both tasks in simulated 3D environments. We also show that this disentanglement of representations makes our model modular, interpretable, and allows for transfer to instructions containing new words by leveraging object detectors.
Audio-Visual Scene-Aware Dialog
Jan 25, 2019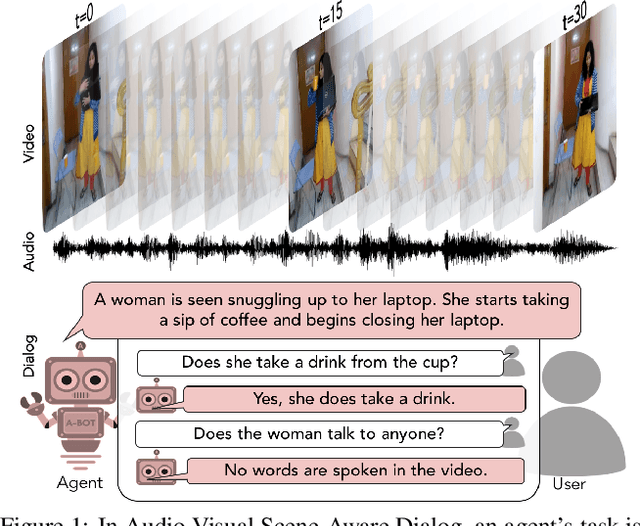
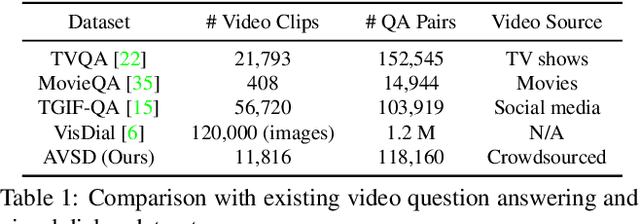


We introduce the task of scene-aware dialog. Given a follow-up question in an ongoing dialog about a video, our goal is to generate a complete and natural response to a question given (a) an input video, and (b) the history of previous turns in the dialog. To succeed, agents must ground the semantics in the video and leverage contextual cues from the history of the dialog to answer the question. To benchmark this task, we introduce the Audio Visual Scene-Aware Dialog (AVSD) dataset. For each of more than 11,000 videos of human actions for the Charades dataset. Our dataset contains a dialog about the video, plus a final summary of the video by one of the dialog participants. We train several baseline systems for this task and evaluate the performance of the trained models using several qualitative and quantitative metrics. Our results indicate that the models must comprehend all the available inputs (video, audio, question and dialog history) to perform well on this dataset.
Response to "Visual Dialogue without Vision or Dialogue"
Jan 16, 2019
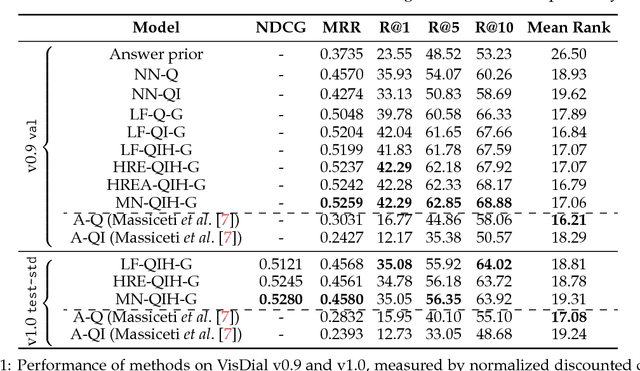
In a recent workshop paper, Massiceti et al. presented a baseline model and subsequent critique of Visual Dialog (Das et al., CVPR 2017) that raises what we believe to be unfounded concerns about the dataset and evaluation. This article intends to rebut the critique and clarify potential confusions for practitioners and future participants in the Visual Dialog challenge.
Dialog System Technology Challenge 7
Jan 11, 2019

This paper introduces the Seventh Dialog System Technology Challenges (DSTC), which use shared datasets to explore the problem of building dialog systems. Recently, end-to-end dialog modeling approaches have been applied to various dialog tasks. The seventh DSTC (DSTC7) focuses on developing technologies related to end-to-end dialog systems for (1) sentence selection, (2) sentence generation and (3) audio visual scene aware dialog. This paper summarizes the overall setup and results of DSTC7, including detailed descriptions of the different tracks and provided datasets. We also describe overall trends in the submitted systems and the key results. Each track introduced new datasets and participants achieved impressive results using state-of-the-art end-to-end technologies.
nocaps: novel object captioning at scale
Dec 20, 2018
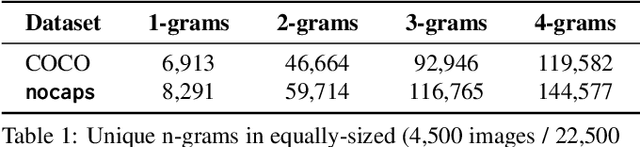
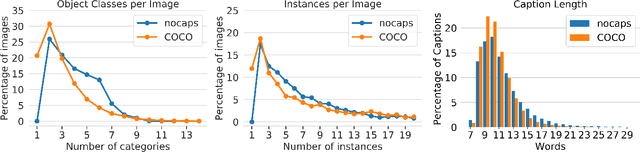
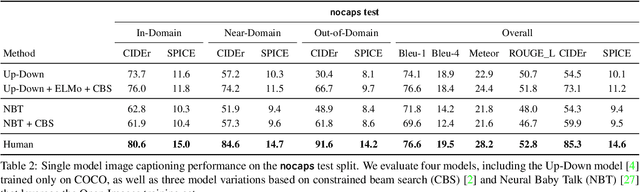
Image captioning models have achieved impressive results on datasets containing limited visual concepts and large amounts of paired image-caption training data. However, if these models are to ever function in the wild, a much larger variety of visual concepts must be learned, ideally from less supervision. To encourage the development of image captioning models that can learn visual concepts from alternative data sources, such as object detection datasets, we present the first large-scale benchmark for this task. Dubbed 'nocaps', for novel object captioning at scale, our benchmark consists of 166,100 human-generated captions describing 15,100 images from the Open Images validation and test sets. The associated training data consists of COCO image-caption pairs, plus Open Images image-level labels and object bounding boxes. Since Open Images contains many more classes than COCO, more than 500 object classes seen in test images have no training captions (hence, nocaps). We evaluate several existing approaches to novel object captioning on our challenging benchmark. In automatic evaluations these approaches show modest improvements over a strong baseline trained only on image-caption data. However, even when using ground-truth object detections, the results are significantly weaker than our human baseline - indicating substantial room for improvement.