 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Introduction to Electrocatalyst Design using Machine Learning for Renewable Energy Storage
Oct 14, 2020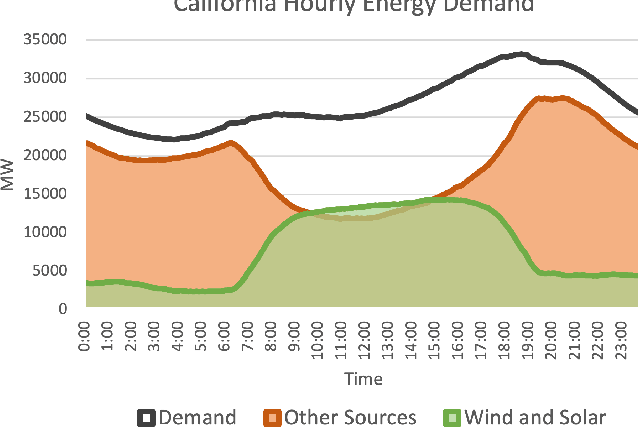
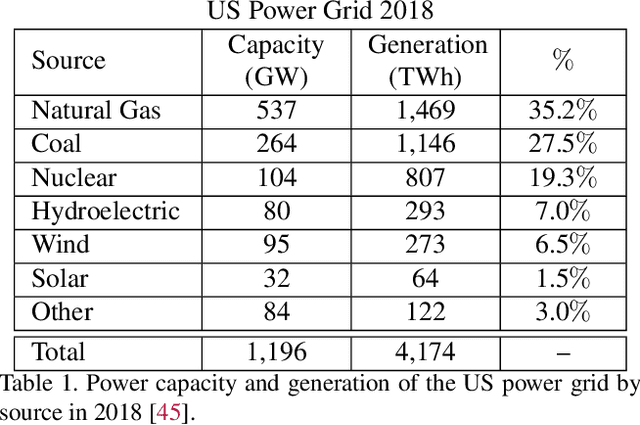
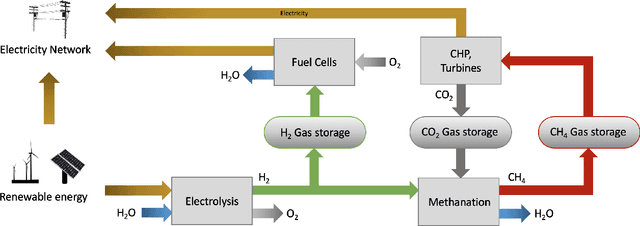
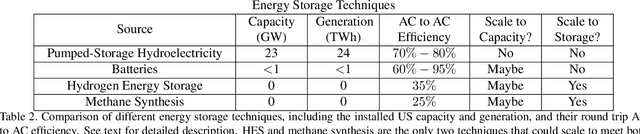
Scalable and cost-effective solutions to renewable energy storage are essential to addressing the world's rising energy needs while reducing climate change. As we increase our reliance on renewable energy sources such as wind and solar, which produce intermittent power, storage is needed to transfer power from times of peak generation to peak demand. This may require the storage of power for hours, days, or months. One solution that offers the potential of scaling to nation-sized grids is the conversion of renewable energy to other fuels, such as hydrogen or methane. To be widely adopted, this process requires cost-effective solutions to running electrochemical reactions. An open challenge is finding low-cost electrocatalysts to drive these reactions at high rates. Through the use of quantum mechanical simulations (density functional theory), new catalyst structures can be tested and evaluated. Unfortunately, the high computational cost of these simulations limits the number of structures that may be tested. The use of machine learning may provide a method to efficiently approximate these calculations, leading to new approaches in finding effective electrocatalysts. In this paper, we provide an introduction to the challenges in finding suitable electrocatalysts, how machine learning may be applied to the problem, and the use of the Open Catalyst Project OC20 dataset for model training.
Contrast and Classify: Alternate Training for Robust VQA
Oct 13, 2020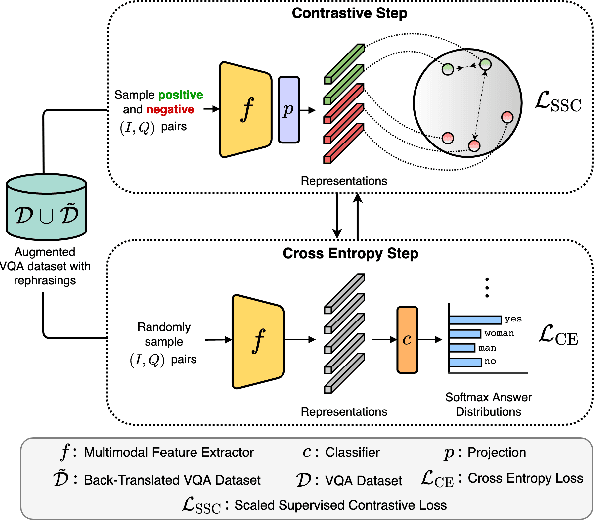
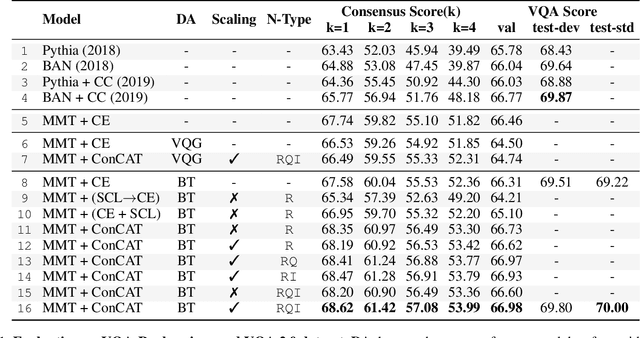
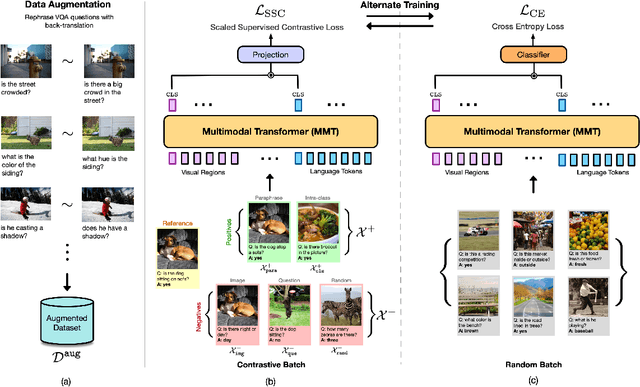
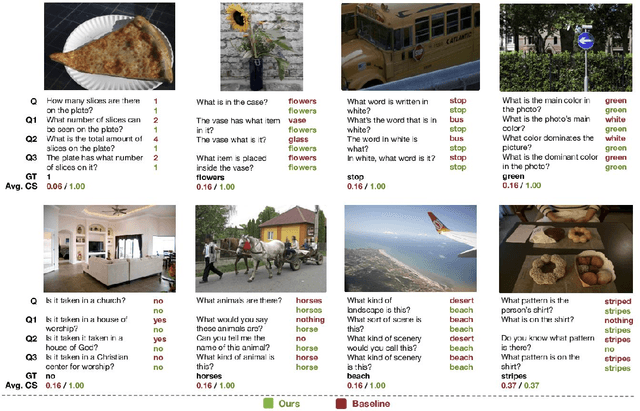
Recent Visual Question Answering (VQA) models have shown impressive performance on the VQA benchmark but remain sensitive to small linguistic variations in input questions. Existing approaches address this by augmenting the dataset with question paraphrases from visual question generation models or adversarial perturbations. These approaches use the combined data to learn an answer classifier by minimizing the standard cross-entropy loss. To more effectively leverage the augmented data, we build on the recent success in contrastive learning. We propose a novel training paradigm (ConCAT) that alternately optimizes cross-entropy and contrastive losses. The contrastive loss encourages representations to be robust to linguistic variations in questions while the cross-entropy loss preserves the discriminative power of the representations for answer classification. We find that alternately optimizing both losses is key to effective training. VQA models trained with ConCAT achieve higher consensus scores on the VQA-Rephrasings dataset as well as higher VQA accuracy on the VQA 2.0 dataset compared to existing approaches across a variety of data augmentation strategies.
Integrating Egocentric Localization for More Realistic Point-Goal Navigation Agents
Sep 07, 2020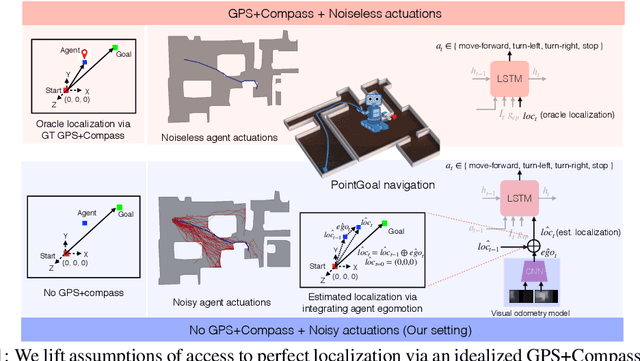
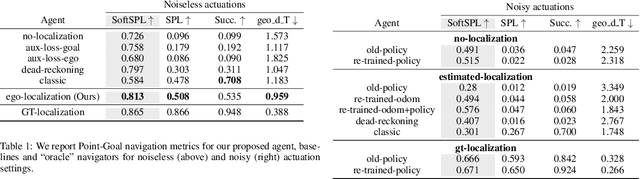
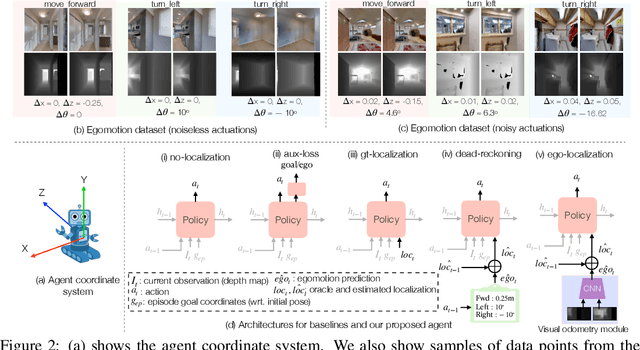
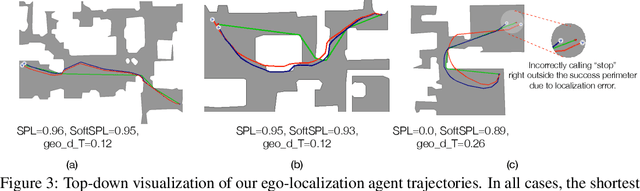
Recent work has presented embodied agents that can navigate to point-goal targets in novel indoor environments with near-perfect accuracy. However, these agents are equipped with idealized sensors for localization and take deterministic actions. This setting is practically sterile by comparison to the dirty reality of noisy sensors and actuations in the real world -- wheels can slip, motion sensors have error, actuations can rebound. In this work, we take a step towards this noisy reality, developing point-goal navigation agents that rely on visual estimates of egomotion under noisy action dynamics. We find these agents outperform naive adaptions of current point-goal agents to this setting as well as those incorporating classic localization baselines. Further, our model conceptually divides learning agent dynamics or odometry (where am I?) from task-specific navigation policy (where do I want to go?). This enables a seamless adaption to changing dynamics (a different robot or floor type) by simply re-calibrating the visual odometry model -- circumventing the expense of re-training of the navigation policy. Our agent was the runner-up in the PointNav track of CVPR 2020 Habitat Challenge.
Dialog without Dialog Data: Learning Visual Dialog Agents from VQA Data
Jul 24, 2020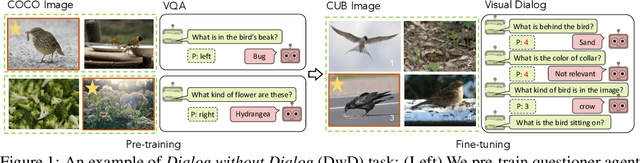
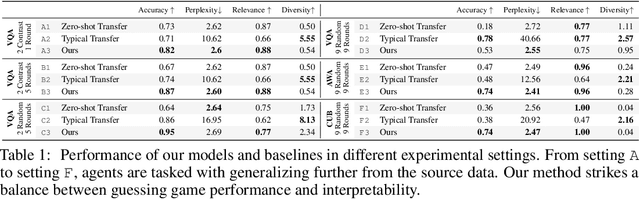
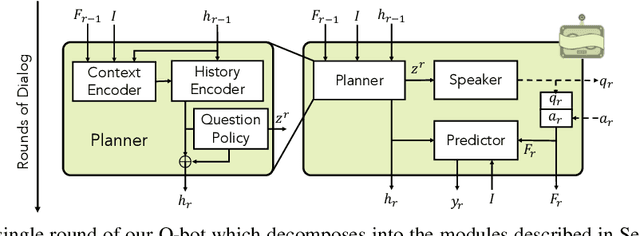
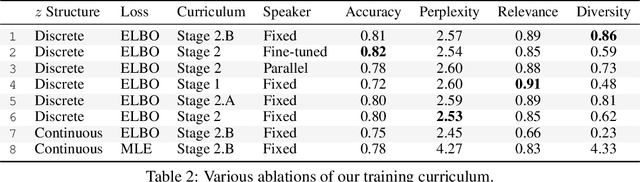
Can we develop visually grounded dialog agents that can efficiently adapt to new tasks without forgetting how to talk to people? Such agents could leverage a larger variety of existing data to generalize to new tasks, minimizing expensive data collection and annotation. In this work, we study a setting we call "Dialog without Dialog", which requires agents to develop visually grounded dialog models that can adapt to new tasks without language level supervision. By factorizing intention and language, our model minimizes linguistic drift after fine-tuning for new tasks. We present qualitative results, automated metrics, and human studies that all show our model can adapt to new tasks and maintain language quality. Baselines either fail to perform well at new tasks or experience language drift, becoming unintelligible to humans. Code has been made available at https://github.com/mcogswell/dialog_without_dialog
Spatially Aware Multimodal Transformers for TextVQA
Jul 23, 2020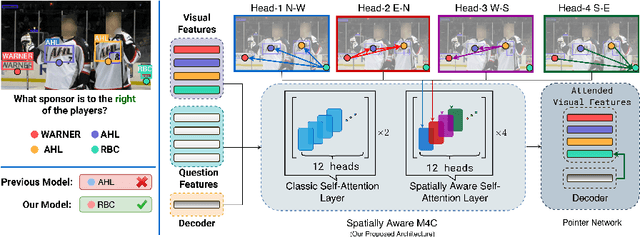
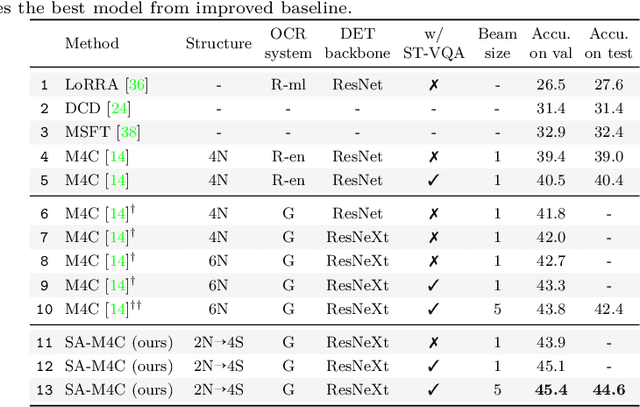
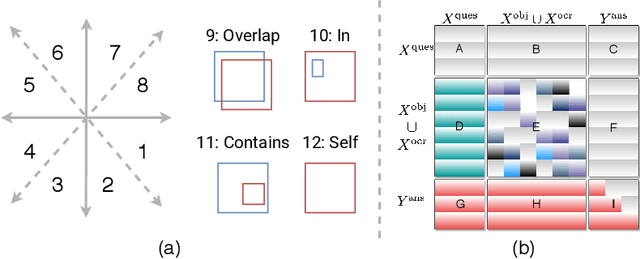
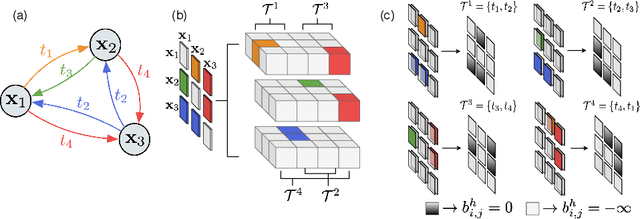
Textual cues are essential for everyday tasks like buying groceries and using public transport. To develop this assistive technology, we study the TextVQA task, i.e., reasoning about text in images to answer a question. Existing approaches are limited in their use of spatial relations and rely on fully-connected transformer-like architectures to implicitly learn the spatial structure of a scene. In contrast, we propose a novel spatially aware self-attention layer such that each visual entity only looks at neighboring entities defined by a spatial graph. Further, each head in our multi-head self-attention layer focuses on a different subset of relations. Our approach has two advantages: (1) each head considers local context instead of dispersing the attention amongst all visual entities; (2) we avoid learning redundant features. We show that our model improves the absolute accuracy of current state-of-the-art methods on TextVQA by 2.2% overall over an improved baseline, and 4.62% on questions that involve spatial reasoning and can be answered correctly using OCR tokens. Similarly on ST-VQA, we improve the absolute accuracy by 4.2%. We further show that spatially aware self-attention improves visual grounding.
Seeing the Un-Scene: Learning Amodal Semantic Maps for Room Navigation
Jul 20, 2020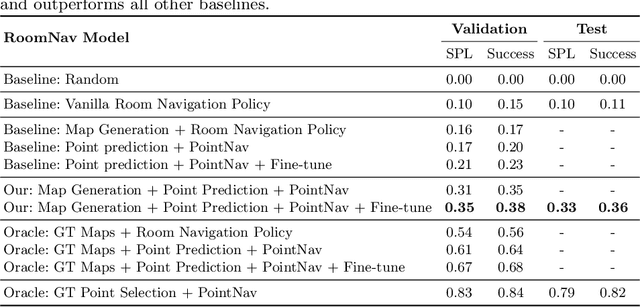
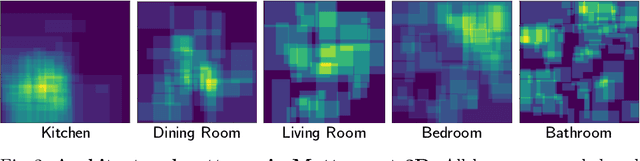
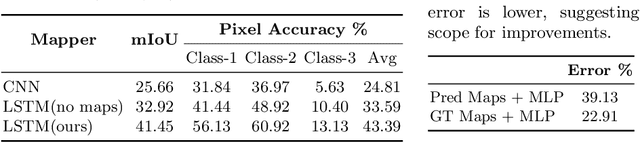
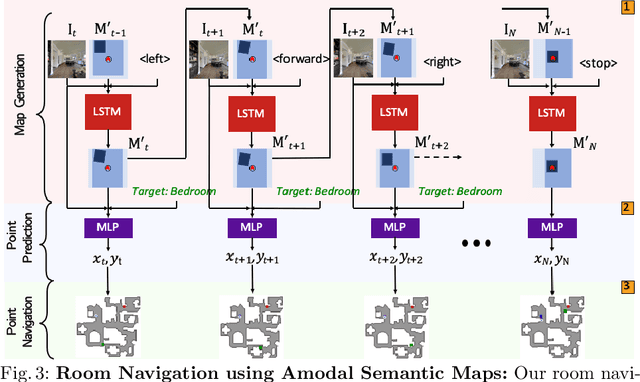
We introduce a learning-based approach for room navigation using semantic maps. Our proposed architecture learns to predict top-down belief maps of regions that lie beyond the agent's field of view while modeling architectural and stylistic regularities in houses. First, we train a model to generate amodal semantic top-down maps indicating beliefs of location, size, and shape of rooms by learning the underlying architectural patterns in houses. Next, we use these maps to predict a point that lies in the target room and train a policy to navigate to the point. We empirically demonstrate that by predicting semantic maps, the model learns common correlations found in houses and generalizes to novel environments. We also demonstrate that reducing the task of room navigation to point navigation improves the performance further.
Neuro-Symbolic Generative Art: A Preliminary Study
Jul 04, 2020


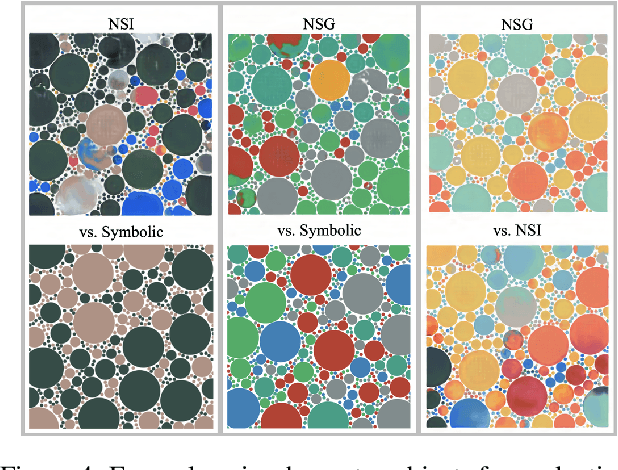
There are two classes of generative art approaches: neural, where a deep model is trained to generate samples from a data distribution, and symbolic or algorithmic, where an artist designs the primary parameters and an autonomous system generates samples within these constraints. In this work, we propose a new hybrid genre: neuro-symbolic generative art. As a preliminary study, we train a generative deep neural network on samples from the symbolic approach. We demonstrate through human studies that subjects find the final artifacts and the creation process using our neuro-symbolic approach to be more creative than the symbolic approach 61% and 82% of the time respectively.
Feel The Music: Automatically Generating A Dance For An Input Song
Jun 23, 2020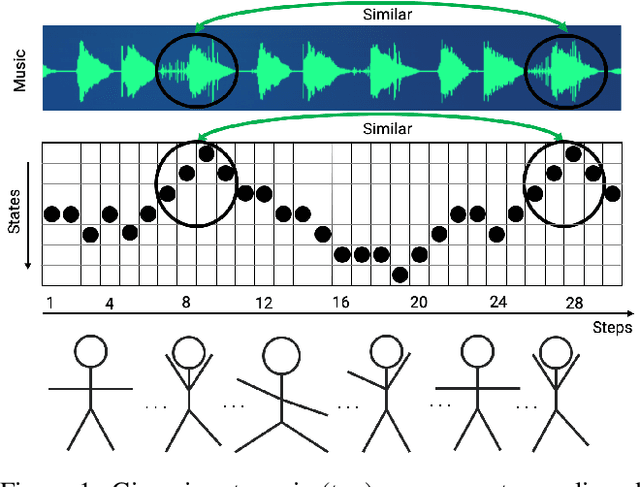
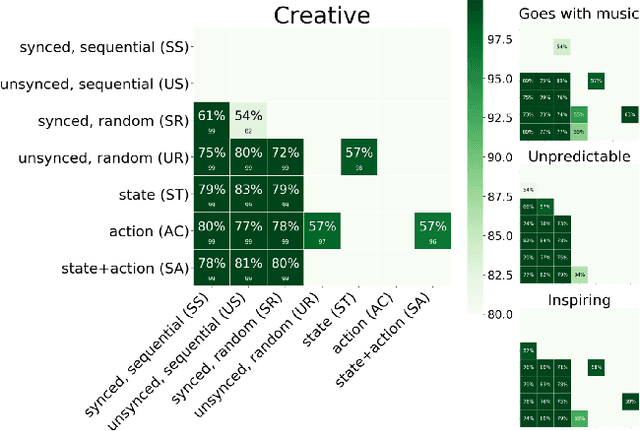
We present a general computational approach that enables a machine to generate a dance for any input music. We encode intuitive, flexible heuristics for what a 'good' dance is: the structure of the dance should align with the structure of the music. This flexibility allows the agent to discover creative dances. Human studies show that participants find our dances to be more creative and inspiring compared to meaningful baselines. We also evaluate how perception of creativity changes based on different presentations of the dance. Our code is available at https://github.com/purvaten/feel-the-music.
Exploring Crowd Co-creation Scenarios for Sketches
May 22, 2020
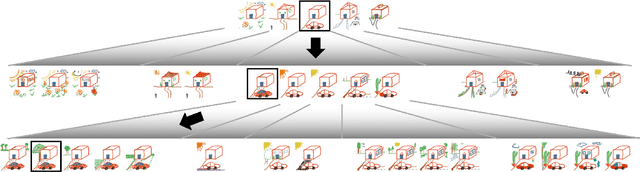


As a first step towards studying the ability of human crowds and machines to effectively co-create, we explore several human-only collaborative co-creation scenarios. The goal in each scenario is to create a digital sketch using a simple web interface. We find that settings in which multiple humans iteratively add strokes and vote on the best additions result in the sketches with highest perceived creativity (value + novelty). Lack of collaboration leads to a higher variance in quality and lower novelty or surprise. Collaboration without voting leads to high novelty but low quality.
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web
May 01, 2020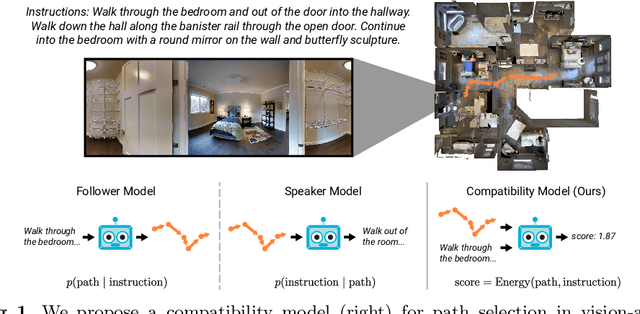
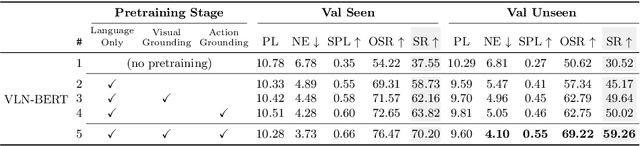

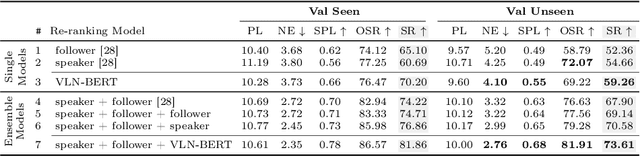
Following a navigation instruction such as 'Walk down the stairs and stop at the brown sofa' requires embodied AI agents to ground scene elements referenced via language (e.g. 'stairs') to visual content in the environment (pixels corresponding to 'stairs'). We ask the following question -- can we leverage abundant 'disembodied' web-scraped vision-and-language corpora (e.g. Conceptual Captions) to learn visual groundings (what do 'stairs' look like?) that improve performance on a relatively data-starved embodied perception task (Vision-and-Language Navigation)? Specifically, we develop VLN-BERT, a visiolinguistic transformer-based model for scoring the compatibility between an instruction ('...stop at the brown sofa') and a sequence of panoramic RGB images captured by the agent. We demonstrate that pretraining VLN-BERT on image-text pairs from the web before fine-tuning on embodied path-instruction data significantly improves performance on VLN -- outperforming the prior state-of-the-art in the fully-observed setting by 4 absolute percentage points on success rate. Ablations of our pretraining curriculum show each stage to be impactful -- with their combination resulting in further positive synergistic effects.