 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordances from Human Videos as a Versatile Representation for Robotics
Apr 17, 2023



Building a robot that can understand and learn to interact by watching humans has inspired several vision problems. However, despite some successful results on static datasets, it remains unclear how current models can be used on a robot directly. In this paper, we aim to bridge this gap by leveraging videos of human interactions in an environment centric manner. Utilizing internet videos of human behavior, we train a visual affordance model that estimates where and how in the scene a human is likely to interact. The structure of these behavioral affordances directly enables the robot to perform many complex tasks. We show how to seamlessly integrate our affordance model with four robot learning paradigms including offline imitation learning, exploration, goal-conditioned learning, and action parameterization for reinforcement learning. We show the efficacy of our approach, which we call VRB, across 4 real world environments, over 10 different tasks, and 2 robotic platforms operating in the wild. Results, visualizations and videos at https://robo-affordances.github.io/
Your Diffusion Model is Secretly a Zero-Shot Classifier
Mar 29, 2023



The recent wave of large-scale text-to-image diffusion models has dramatically increased our text-based image generation abilities. These models can generate realistic images for a staggering variety of prompts and exhibit impressive compositional generalization abilities. Almost all use cases thus far have solely focused on sampling; however, diffusion models can also provide conditional density estimates, which are useful for tasks beyond image generation. In this paper, we show that the density estimates from large-scale text-to-image diffusion models like Stable Diffusion can be leveraged to perform zero-shot classification without any additional training. Our generative approach to classification, which we call Diffusion Classifier, attains strong results on a variety of benchmarks and outperforms alternative methods of extracting knowledge from diffusion models. Although a gap remains between generative and discriminative approaches on zero-shot recognition tasks, we find that our diffusion-based approach has stronger multimodal relational reasoning abilities than competing discriminative approaches. Finally, we use Diffusion Classifier to extract standard classifiers from class-conditional diffusion models trained on ImageNet. Even though these models are trained with weak augmentations and no regularization, they approach the performance of SOTA discriminative classifiers. Overall, our results are a step toward using generative over discriminative models for downstream tasks. Results and visualizations at https://diffusion-classifier.github.io/
Legs as Manipulator: Pushing Quadrupedal Agility Beyond Locomotion
Mar 22, 2023Locomotion has seen dramatic progress for walking or running across challenging terrains. However, robotic quadrupeds are still far behind their biological counterparts, such as dogs, which display a variety of agile skills and can use the legs beyond locomotion to perform several basic manipulation tasks like interacting with objects and climbing. In this paper, we take a step towards bridging this gap by training quadruped robots not only to walk but also to use the front legs to climb walls, press buttons, and perform object interaction in the real world. To handle this challenging optimization, we decouple the skill learning broadly into locomotion, which involves anything that involves movement whether via walking or climbing a wall, and manipulation, which involves using one leg to interact while balancing on the other three legs. These skills are trained in simulation using curriculum and transferred to the real world using our proposed sim2real variant that builds upon recent locomotion success. Finally, we combine these skills into a robust long-term plan by learning a behavior tree that encodes a high-level task hierarchy from one clean expert demonstration. We evaluate our method in both simulation and real-world showing successful executions of both short as well as long-range tasks and how robustness helps confront external perturbations. Videos at https://robot-skills.github.io
Internet Explorer: Targeted Representation Learning on the Open Web
Feb 27, 2023



Modern vision models typically rely on fine-tuning general-purpose models pre-trained on large, static datasets. These general-purpose models only capture the knowledge within their pre-training datasets, which are tiny, out-of-date snapshots of the Internet -- where billions of images are uploaded each day. We suggest an alternate approach: rather than hoping our static datasets transfer to our desired tasks after large-scale pre-training, we propose dynamically utilizing the Internet to quickly train a small-scale model that does extremely well on the task at hand. Our approach, called Internet Explorer, explores the web in a self-supervised manner to progressively find relevant examples that improve performance on a desired target dataset. It cycles between searching for images on the Internet with text queries, self-supervised training on downloaded images, determining which images were useful, and prioritizing what to search for next. We evaluate Internet Explorer across several datasets and show that it outperforms or matches CLIP oracle performance by using just a single GPU desktop to actively query the Internet for 30--40 hours. Results, visualizations, and videos at https://internet-explorer-ssl.github.io/
ALAN: Autonomously Exploring Robotic Agents in the Real World
Feb 13, 2023Robotic agents that operate autonomously in the real world need to continuously explore their environment and learn from the data collected, with minimal human supervision. While it is possible to build agents that can learn in such a manner without supervision, current methods struggle to scale to the real world. Thus, we propose ALAN, an autonomously exploring robotic agent, that can perform tasks in the real world with little training and interaction time. This is enabled by measuring environment change, which reflects object movement and ignores changes in the robot position. We use this metric directly as an environment-centric signal, and also maximize the uncertainty of predicted environment change, which provides agent-centric exploration signal. We evaluate our approach on two different real-world play kitchen settings, enabling a robot to efficiently explore and discover manipulation skills, and perform tasks specified via goal images. Website at https://robo-explorer.github.io/
Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models
Jan 18, 2023



The ability to quickly learn a new task with minimal instruction - known as few-shot learning - is a central aspect of intelligent agents. Classical few-shot benchmarks make use of few-shot samples from a single modality, but such samples may not be sufficient to characterize an entire concept class. In contrast, humans use cross-modal information to learn new concepts efficiently. In this work, we demonstrate that one can indeed build a better ${\bf visual}$ dog classifier by ${\bf read}$ing about dogs and ${\bf listen}$ing to them bark. To do so, we exploit the fact that recent multimodal foundation models such as CLIP are inherently cross-modal, mapping different modalities to the same representation space. Specifically, we propose a simple cross-modal adaptation approach that learns from few-shot examples spanning different modalities. By repurposing class names as additional one-shot training samples, we achieve SOTA results with an embarrassingly simple linear classifier for vision-language adaptation. Furthermore, we show that our approach can benefit existing methods such as prefix tuning, adapters, and classifier ensembling. Finally, to explore other modalities beyond vision and language, we construct the first (to our knowledge) audiovisual few-shot benchmark and use cross-modal training to improve the performance of both image and audio classification.
VideoDex: Learning Dexterity from Internet Videos
Dec 08, 2022To build general robotic agents that can operate in many environments, it is often imperative for the robot to collect experience in the real world. However, this is often not feasible due to safety, time, and hardware restrictions. We thus propose leveraging the next best thing as real-world experience: internet videos of humans using their hands. Visual priors, such as visual features, are often learned from videos, but we believe that more information from videos can be utilized as a stronger prior. We build a learning algorithm, VideoDex, that leverages visual, action, and physical priors from human video datasets to guide robot behavior. These actions and physical priors in the neural network dictate the typical human behavior for a particular robot task. We test our approach on a robot arm and dexterous hand-based system and show strong results on various manipulation tasks, outperforming various state-of-the-art methods. Videos at https://video-dex.github.io
HERD: Continuous Human-to-Robot Evolution for Learning from Human Demonstration
Dec 08, 2022The ability to learn from human demonstration endows robots with the ability to automate various tasks. However, directly learning from human demonstration is challenging since the structure of the human hand can be very different from the desired robot gripper. In this work, we show that manipulation skills can be transferred from a human to a robot through the use of micro-evolutionary reinforcement learning, where a five-finger human dexterous hand robot gradually evolves into a commercial robot, while repeated interacting in a physics simulator to continuously update the policy that is first learned from human demonstration. To deal with the high dimensions of robot parameters, we propose an algorithm for multi-dimensional evolution path searching that allows joint optimization of both the robot evolution path and the policy. Through experiments on human object manipulation datasets, we show that our framework can efficiently transfer the expert human agent policy trained from human demonstrations in diverse modalities to target commercial robots.
Legged Locomotion in Challenging Terrains using Egocentric Vision
Nov 14, 2022Animals are capable of precise and agile locomotion using vision. Replicating this ability has been a long-standing goal in robotics. The traditional approach has been to decompose this problem into elevation mapping and foothold planning phases. The elevation mapping, however, is susceptible to failure and large noise artifacts, requires specialized hardware, and is biologically implausible. In this paper, we present the first end-to-end locomotion system capable of traversing stairs, curbs, stepping stones, and gaps. We show this result on a medium-sized quadruped robot using a single front-facing depth camera. The small size of the robot necessitates discovering specialized gait patterns not seen elsewhere. The egocentric camera requires the policy to remember past information to estimate the terrain under its hind feet. We train our policy in simulation. Training has two phases - first, we train a policy using reinforcement learning with a cheap-to-compute variant of depth image and then in phase 2 distill it into the final policy that uses depth using supervised learning. The resulting policy transfers to the real world and is able to run in real-time on the limited compute of the robot. It can traverse a large variety of terrain while being robust to perturbations like pushes, slippery surfaces, and rocky terrain. Videos are at https://vision-locomotion.github.io
Deep Whole-Body Control: Learning a Unified Policy for Manipulation and Locomotion
Oct 18, 2022
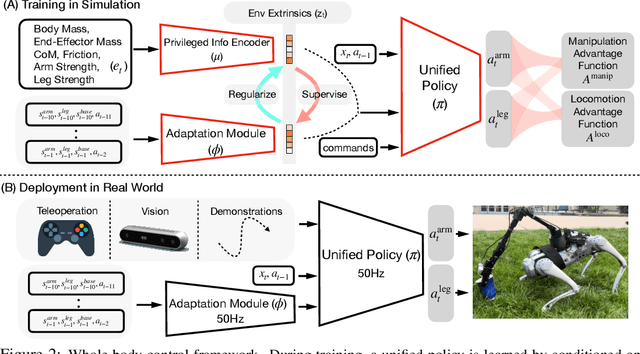
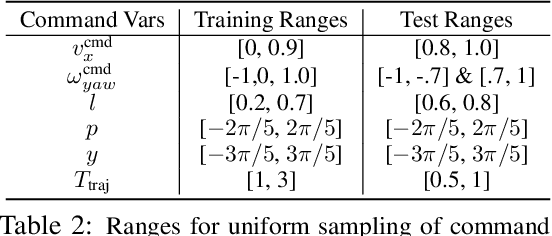
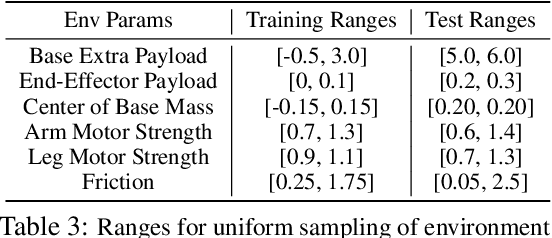
An attached arm can significantly increase the applicability of legged robots to several mobile manipulation tasks that are not possible for the wheeled or tracked counterparts. The standard hierarchical control pipeline for such legged manipulators is to decouple the controller into that of manipulation and locomotion. However, this is ineffective. It requires immense engineering to support coordination between the arm and legs, and error can propagate across modules causing non-smooth unnatural motions. It is also biological implausible given evidence for strong motor synergies across limbs. In this work, we propose to learn a unified policy for whole-body control of a legged manipulator using reinforcement learning. We propose Regularized Online Adaptation to bridge the Sim2Real gap for high-DoF control, and Advantage Mixing exploiting the causal dependency in the action space to overcome local minima during training the whole-body system. We also present a simple design for a low-cost legged manipulator, and find that our unified policy can demonstrate dynamic and agile behaviors across several task setups. Videos are at https://maniploco.github.io