 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-Consistent Search: Question Reconstructability as a Proxy Reward for Search Agent Training
Apr 14, 2026Reinforcement Learning (RL) has shown strong potential for optimizing search agents in complex information retrieval tasks. However, existing approaches predominantly rely on gold supervision, such as ground-truth answers, which is difficult to scale. To address this limitation, we propose Cycle-Consistent Search (CCS), a gold-supervision-free framework for training search agents, inspired by cycle-consistency techniques from unsupervised machine translation and image-to-image translation. Our key hypothesis is that an optimal search trajectory, unlike insufficient or irrelevant ones, serves as a lossless encoding of the question's intent. Consequently, a high-quality trajectory should preserve the information required to accurately reconstruct the original question, thereby inducing a reward signal for policy optimization. However, naive cycle-consistency objectives are vulnerable to information leakage, as reconstruction may rely on superficial lexical cues rather than the underlying search process. To reduce this effect, we apply information bottlenecks, including exclusion of the final response and named entity recognition (NER) masking of search queries. These constraints force reconstruction to rely on retrieved observations together with the structural scaffold, ensuring that the resulting reward signal reflects informational adequacy rather than linguistic redundancy. Experiments on question-answering benchmarks show that CCS achieves performance comparable to supervised baselines while outperforming prior methods that do not rely on gold supervision. These results suggest that CCS provides a scalable training paradigm for training search agents in settings where gold supervision is unavailable.
FRESCO: Benchmarking and Optimizing Re-rankers for Evolving Semantic Conflict in Retrieval-Augmented Generation
Apr 14, 2026Retrieval-Augmented Generation (RAG) is a key approach to mitigating the temporal staleness of large language models (LLMs) by grounding responses in up-to-date evidence. Within the RAG pipeline, re-rankers play a pivotal role in selecting the most useful documents from retrieved candidates. However, existing benchmarks predominantly evaluate re-rankers in static settings and do not adequately assess performance under evolving information -- a critical gap, as real-world systems often must choose among temporally different pieces of evidence. To address this limitation, we introduce FRESCO (Factual Recency and Evolving Semantic COnflict), a benchmark for evaluating re-rankers in temporally dynamic contexts. By pairing recency-seeking queries with historical Wikipedia revisions, FRESCO tests whether re-rankers can prioritize factually recent evidence while maintaining semantic relevance. Our evaluation reveals a consistent failure mode across existing re-rankers: a strong bias toward older, semantically rich documents, even when they are factually obsolete. We further investigate an instruction optimization framework to mitigate this issue. By identifying Pareto-optimal instructions that balance Evolving and Non-Evolving Knowledge tasks, we obtain gains of up to 27% on Evolving Knowledge tasks while maintaining competitive performance on Non-Evolving Knowledge tasks.
Efficient and robust 3D blind harmonization for large domain gaps
Apr 30, 2025Blind harmonization has emerged as a promising technique for MR image harmonization to achieve scale-invariant representations, requiring only target domain data (i.e., no source domain data necessary). However, existing methods face limitations such as inter-slice heterogeneity in 3D, moderate image quality, and limited performance for a large domain gap. To address these challenges, we introduce BlindHarmonyDiff, a novel blind 3D harmonization framework that leverages an edge-to-image model tailored specifically to harmonization. Our framework employs a 3D rectified flow trained on target domain images to reconstruct the original image from an edge map, then yielding a harmonized image from the edge of a source domain image. We propose multi-stride patch training for efficient 3D training and a refinement module for robust inference by suppressing hallucination. Extensive experiments demonstrate that BlindHarmonyDiff outperforms prior arts by harmonizing diverse source domain images to the target domain, achieving higher correspondence to the target domain characteristics. Downstream task-based quality assessments such as tissue segmentation and age prediction on diverse MR scanners further confirm the effectiveness of our approach and demonstrate the capability of our robust and generalizable blind harmonization.
Diffusion-based Neural Network Weights Generation
Feb 28, 2024



Transfer learning is a topic of significant interest in recent deep learning research because it enables faster convergence and improved performance on new tasks. While the performance of transfer learning depends on the similarity of the source data to the target data, it is costly to train a model on a large number of datasets. Therefore, pretrained models are generally blindly selected with the hope that they will achieve good performance on the given task. To tackle such suboptimality of the pretrained models, we propose an efficient and adaptive transfer learning scheme through dataset-conditioned pretrained weights sampling. Specifically, we use a latent diffusion model with a variational autoencoder that can reconstruct the neural network weights, to learn the distribution of a set of pretrained weights conditioned on each dataset for transfer learning on unseen datasets. By learning the distribution of a neural network on a variety pretrained models, our approach enables adaptive sampling weights for unseen datasets achieving faster convergence and reaching competitive performance.
Co-training and Co-distillation for Quality Improvement and Compression of Language Models
Nov 07, 2023



Knowledge Distillation (KD) compresses computationally expensive pre-trained language models (PLMs) by transferring their knowledge to smaller models, allowing their use in resource-constrained or real-time settings. However, most smaller models fail to surpass the performance of the original larger model, resulting in sacrificing performance to improve inference speed. To address this issue, we propose Co-Training and Co-Distillation (CTCD), a novel framework that improves performance and inference speed together by co-training two models while mutually distilling knowledge. The CTCD framework successfully achieves this based on two significant findings: 1) Distilling knowledge from the smaller model to the larger model during co-training improves the performance of the larger model. 2) The enhanced performance of the larger model further boosts the performance of the smaller model. The CTCD framework shows promise as it can be combined with existing techniques like architecture design or data augmentation, replacing one-way KD methods, to achieve further performance improvement. Extensive ablation studies demonstrate the effectiveness of CTCD, and the small model distilled by CTCD outperforms the original larger model by a significant margin of 1.66 on the GLUE benchmark.
DiffusionNAG: Task-guided Neural Architecture Generation with Diffusion Models
May 26, 2023



Neural Architecture Search (NAS) has emerged as a powerful technique for automating neural architecture design. However, existing NAS methods either require an excessive amount of time for repetitive training or sampling of many task-irrelevant architectures. Moreover, they lack generalization across different tasks and usually require searching for optimal architectures for each task from scratch without reusing the knowledge from the previous NAS tasks. To tackle such limitations of existing NAS methods, we propose a novel transferable task-guided Neural Architecture Generation (NAG) framework based on diffusion models, dubbed DiffusionNAG. With the guidance of a surrogate model, such as a performance predictor for a given task, our DiffusionNAG can generate task-optimal architectures for diverse tasks, including unseen tasks. DiffusionNAG is highly efficient as it generates task-optimal neural architectures by leveraging the prior knowledge obtained from the previous tasks and neural architecture distribution. Furthermore, we introduce a score network to ensure the generation of valid architectures represented as directed acyclic graphs, unlike existing graph generative models that focus on generating undirected graphs. Extensive experiments demonstrate that DiffusionNAG significantly outperforms the state-of-the-art transferable NAG model in architecture generation quality, as well as previous NAS methods on four computer vision datasets with largely reduced computational cost.
A Study on Knowledge Distillation from Weak Teacher for Scaling Up Pre-trained Language Models
May 26, 2023Distillation from Weak Teacher (DWT) is a method of transferring knowledge from a smaller, weaker teacher model to a larger student model to improve its performance. Previous studies have shown that DWT can be effective in the vision domain and natural language processing (NLP) pre-training stage. Specifically, DWT shows promise in practical scenarios, such as enhancing new generation or larger models using pre-trained yet older or smaller models and lacking a resource budget. However, the optimal conditions for using DWT have yet to be fully investigated in NLP pre-training. Therefore, this study examines three key factors to optimize DWT, distinct from those used in the vision domain or traditional knowledge distillation. These factors are: (i) the impact of teacher model quality on DWT effectiveness, (ii) guidelines for adjusting the weighting value for DWT loss, and (iii) the impact of parameter remapping as a student model initialization technique for DWT.
Meta-prediction Model for Distillation-Aware NAS on Unseen Datasets
May 26, 2023



Distillation-aware Neural Architecture Search (DaNAS) aims to search for an optimal student architecture that obtains the best performance and/or efficiency when distilling the knowledge from a given teacher model. Previous DaNAS methods have mostly tackled the search for the neural architecture for fixed datasets and the teacher, which are not generalized well on a new task consisting of an unseen dataset and an unseen teacher, thus need to perform a costly search for any new combination of the datasets and the teachers. For standard NAS tasks without KD, meta-learning-based computationally efficient NAS methods have been proposed, which learn the generalized search process over multiple tasks (datasets) and transfer the knowledge obtained over those tasks to a new task. However, since they assume learning from scratch without KD from a teacher, they might not be ideal for DaNAS scenarios. To eliminate the excessive computational cost of DaNAS methods and the sub-optimality of rapid NAS methods, we propose a distillation-aware meta accuracy prediction model, DaSS (Distillation-aware Student Search), which can predict a given architecture's final performances on a dataset when performing KD with a given teacher, without having actually to train it on the target task. The experimental results demonstrate that our proposed meta-prediction model successfully generalizes to multiple unseen datasets for DaNAS tasks, largely outperforming existing meta-NAS methods and rapid NAS baselines. Code is available at https://github.com/CownowAn/DaSS
SuperNet in Neural Architecture Search: A Taxonomic Survey
Apr 08, 2022
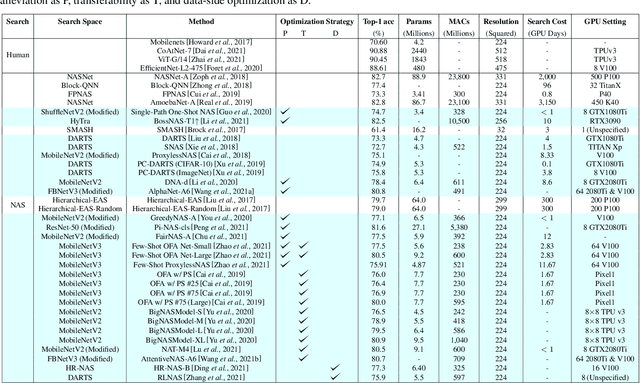
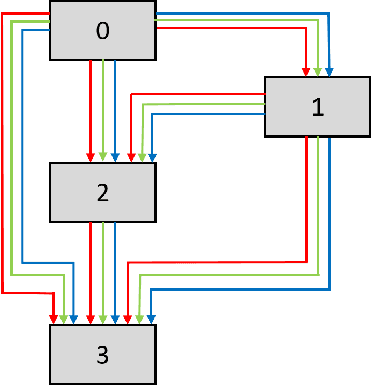
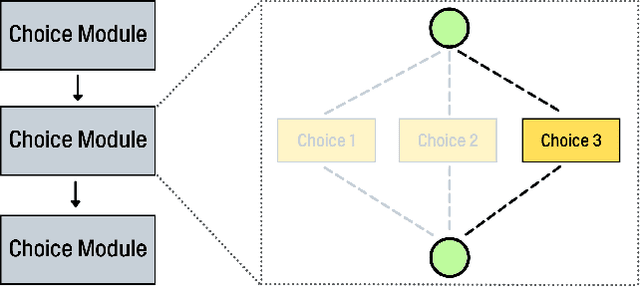
Deep Neural Networks (DNN) have made significant progress in a wide range of visual recognition tasks such as image classification, object detection, and semantic segmentation. The evolution of convolutional architectures has led to better performance by incurring expensive computational costs. In addition, network design has become a difficult task, which is labor-intensive and requires a high level of domain knowledge. To mitigate such issues, there have been studies for a variety of neural architecture search methods that automatically search for optimal architectures, achieving models with impressive performance that outperform human-designed counterparts. This survey aims to provide an overview of existing works in this field of research and specifically focus on the supernet optimization that builds a neural network that assembles all the architectures as its sub models by using weight sharing. We aim to accomplish that by categorizing supernet optimization by proposing them as solutions to the common challenges found in the literature: data-side optimization, poor rank correlation alleviation, and transferable NAS for a number of deployment scenarios.
Online Hyperparameter Meta-Learning with Hypergradient Distillation
Oct 06, 2021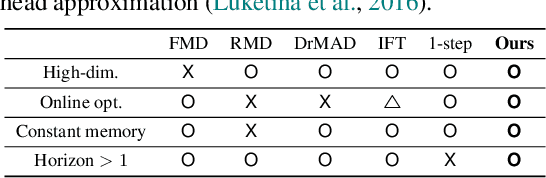
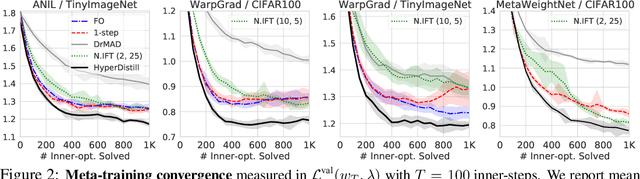
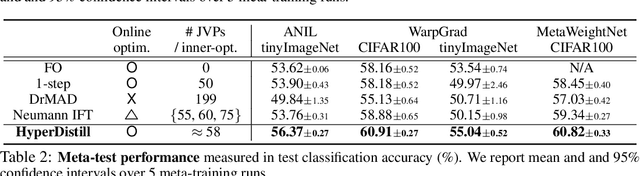
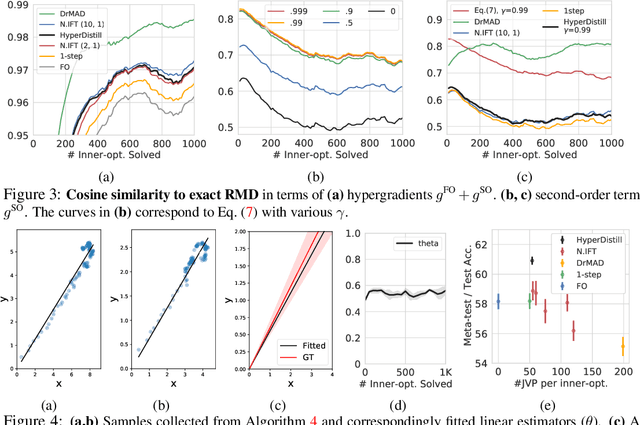
Many gradient-based meta-learning methods assume a set of parameters that do not participate in inner-optimization, which can be considered as hyperparameters. Although such hyperparameters can be optimized using the existing gradient-based hyperparameter optimization (HO) methods, they suffer from the following issues. Unrolled differentiation methods do not scale well to high-dimensional hyperparameters or horizon length, Implicit Function Theorem (IFT) based methods are restrictive for online optimization, and short horizon approximations suffer from short horizon bias. In this work, we propose a novel HO method that can overcome these limitations, by approximating the second-order term with knowledge distillation. Specifically, we parameterize a single Jacobian-vector product (JVP) for each HO step and minimize the distance from the true second-order term. Our method allows online optimization and also is scalable to the hyperparameter dimension and the horizon length. We demonstrate the effectiveness of our method on two different meta-learning methods and three benchmark datasets.