 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Feedback to Checklists: Grounded Evaluation of AI-Generated Clinical Notes
Jul 23, 2025



AI-generated clinical notes are increasingly used in healthcare, but evaluating their quality remains a challenge due to high subjectivity and limited scalability of expert review. Existing automated metrics often fail to align with real-world physician preferences. To address this, we propose a pipeline that systematically distills real user feedback into structured checklists for note evaluation. These checklists are designed to be interpretable, grounded in human feedback, and enforceable by LLM-based evaluators. Using deidentified data from over 21,000 clinical encounters, prepared in accordance with the HIPAA safe harbor standard, from a deployed AI medical scribe system, we show that our feedback-derived checklist outperforms baseline approaches in our offline evaluations in coverage, diversity, and predictive power for human ratings. Extensive experiments confirm the checklist's robustness to quality-degrading perturbations, significant alignment with clinician preferences, and practical value as an evaluation methodology. In offline research settings, the checklist can help identify notes likely to fall below our chosen quality thresholds.
No Free Lunch: Non-Asymptotic Analysis of Prediction-Powered Inference
May 26, 2025Prediction-Powered Inference (PPI) is a popular strategy for combining gold-standard and possibly noisy pseudo-labels to perform statistical estimation. Prior work has shown an asymptotic "free lunch" for PPI++, an adaptive form of PPI, showing that the *asymptotic* variance of PPI++ is always less than or equal to the variance obtained from using gold-standard labels alone. Notably, this result holds *regardless of the quality of the pseudo-labels*. In this work, we demystify this result by conducting an exact finite-sample analysis of the estimation error of PPI++ on the mean estimation problem. We give a "no free lunch" result, characterizing the settings (and sample sizes) where PPI++ has provably worse estimation error than using gold-standard labels alone. Specifically, PPI++ will outperform if and only if the correlation between pseudo- and gold-standard is above a certain level that depends on the number of labeled samples ($n$). In some cases our results simplify considerably: For Gaussian data, the correlation must be at least $1/\sqrt{n - 2}$ in order to see improvement, and a similar result holds for binary labels. In experiments, we illustrate that our theoretical findings hold on real-world datasets, and give insights into trade-offs between single-sample and sample-splitting variants of PPI++.
The Limited Impact of Medical Adaptation of Large Language and Vision-Language Models
Nov 13, 2024



Several recent works seek to develop foundation models specifically for medical applications, adapting general-purpose large language models (LLMs) and vision-language models (VLMs) via continued pretraining on publicly available biomedical corpora. These works typically claim that such domain-adaptive pretraining (DAPT) improves performance on downstream medical tasks, such as answering medical licensing exam questions. In this paper, we compare ten public "medical" LLMs and two VLMs against their corresponding base models, arriving at a different conclusion: all medical VLMs and nearly all medical LLMs fail to consistently improve over their base models in the zero-/few-shot prompting and supervised fine-tuning regimes for medical question-answering (QA). For instance, across all tasks and model pairs we consider in the 3-shot setting, medical LLMs only outperform their base models in 22.7% of cases, reach a (statistical) tie in 36.8% of cases, and are significantly worse than their base models in the remaining 40.5% of cases. Our conclusions are based on (i) comparing each medical model head-to-head, directly against the corresponding base model; (ii) optimizing the prompts for each model separately in zero-/few-shot prompting; and (iii) accounting for statistical uncertainty in comparisons. While these basic practices are not consistently adopted in the literature, our ablations show that they substantially impact conclusions. Meanwhile, we find that after fine-tuning on specific QA tasks, medical LLMs can show performance improvements, but the benefits do not carry over to tasks based on clinical notes. Our findings suggest that state-of-the-art general-domain models may already exhibit strong medical knowledge and reasoning capabilities, and offer recommendations to strengthen the conclusions of future studies.
Unsupervised Learning under Latent Label Shift
Jul 26, 2022
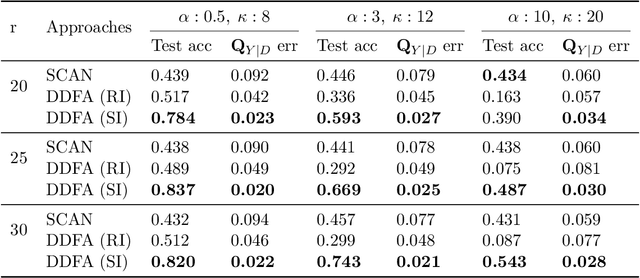

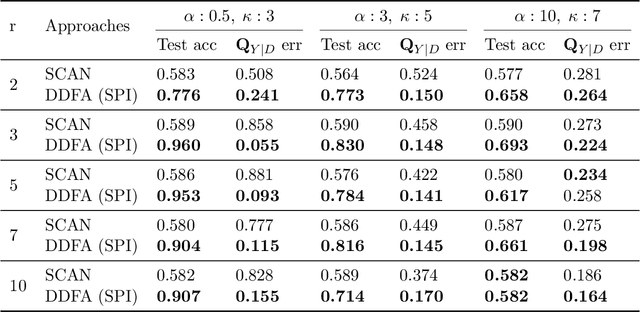
What sorts of structure might enable a learner to discover classes from unlabeled data? Traditional approaches rely on feature-space similarity and heroic assumptions on the data. In this paper, we introduce unsupervised learning under Latent Label Shift (LLS), where we have access to unlabeled data from multiple domains such that the label marginals $p_d(y)$ can shift across domains but the class conditionals $p(\mathbf{x}|y)$ do not. This work instantiates a new principle for identifying classes: elements that shift together group together. For finite input spaces, we establish an isomorphism between LLS and topic modeling: inputs correspond to words, domains to documents, and labels to topics. Addressing continuous data, we prove that when each label's support contains a separable region, analogous to an anchor word, oracle access to $p(d|\mathbf{x})$ suffices to identify $p_d(y)$ and $p_d(y|\mathbf{x})$ up to permutation. Thus motivated, we introduce a practical algorithm that leverages domain-discriminative models as follows: (i) push examples through domain discriminator $p(d|\mathbf{x})$; (ii) discretize the data by clustering examples in $p(d|\mathbf{x})$ space; (iii) perform non-negative matrix factorization on the discrete data; (iv) combine the recovered $p(y|d)$ with the discriminator outputs $p(d|\mathbf{x})$ to compute $p_d(y|x) \; \forall d$. With semi-synthetic experiments, we show that our algorithm can leverage domain information to improve state of the art unsupervised classification methods. We reveal a failure mode of standard unsupervised classification methods when feature-space similarity does not indicate true groupings, and show empirically that our method better handles this case. Our results establish a deep connection between distribution shift and topic modeling, opening promising lines for future work.
Ant Colony Inspired Machine Learning Algorithm for Identifying and Emulating Virtual Sensors
Nov 02, 2020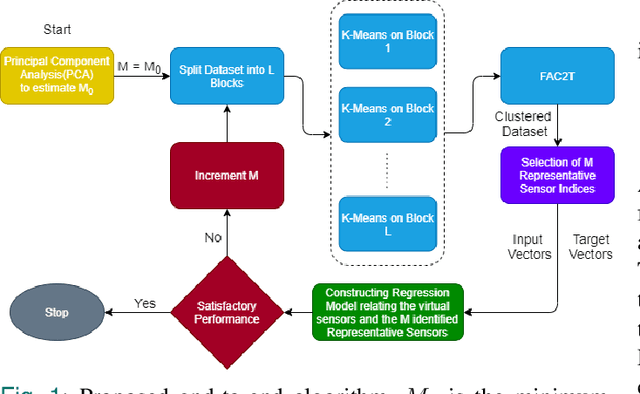
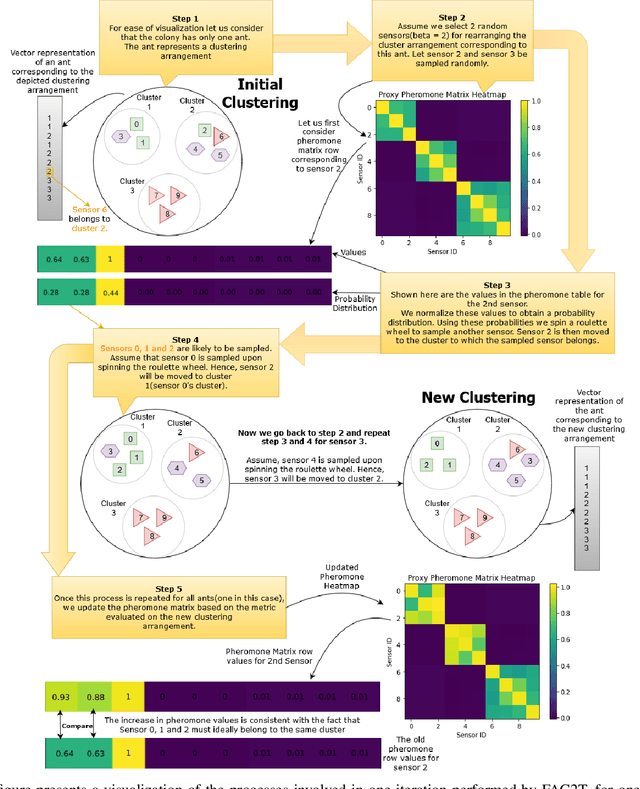
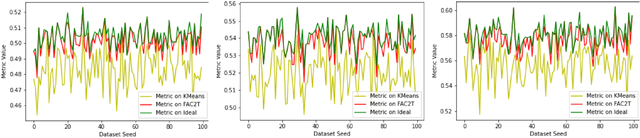
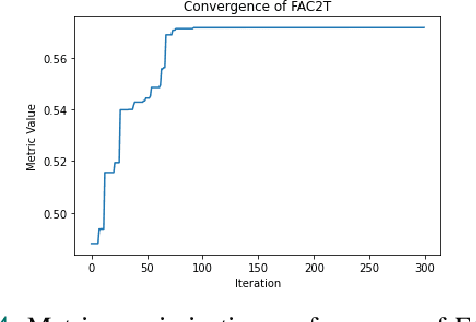
The scale of systems employed in industrial environments demands a large number of sensors to facilitate meticulous monitoring and functioning. These requirements could potentially lead to inefficient system designs. The data coming from various sensors are often correlated due to the underlying relations in the system parameters that the sensors monitor. In theory, it should be possible to emulate the output of certain sensors based on other sensors. Tapping into such possibilities holds tremendous advantages in terms of reducing system design complexity. In order to identify the subset of sensors whose readings can be emulated, the sensors must be grouped into clusters. Complex systems generally have a large quantity of sensors that collect and store data over prolonged periods of time. This leads to the accumulation of massive amounts of data. In this paper we propose an end-to-end algorithmic solution, to realise virtual sensors in such systems. This algorithm splits the dataset into blocks and clusters each of them individually. It then fuses these clustering solutions to obtain a global solution using an Ant Colony inspired technique, FAC2T. Having grouped the sensors into clusters, we select representative sensors from each cluster. These sensors are retained in the system while the other sensors readings are emulated by applying supervised learning algorithms.