 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-channel Weighted Nuclear Norm Minimization for Real Color Image Denoising
May 28, 2017
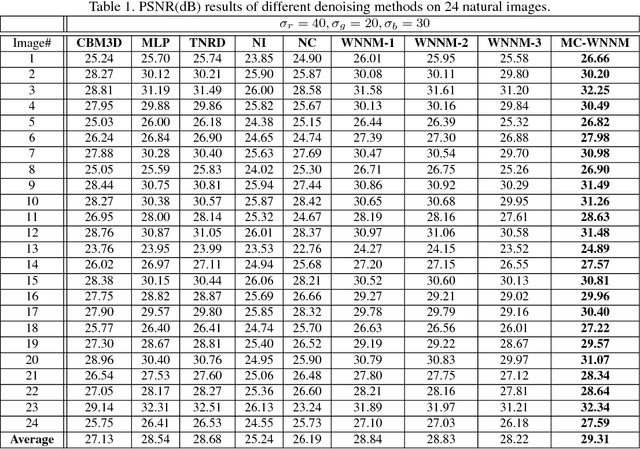

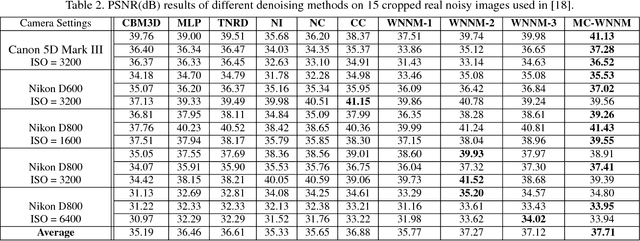
Most of the existing denoising algorithms are developed for grayscale images, while it is not a trivial work to extend them for color image denoising because the noise statistics in R, G, B channels can be very different for real noisy images. In this paper, we propose a multi-channel (MC) optimization model for real color image denoising under the weighted nuclear norm minimization (WNNM) framework. We concatenate the RGB patches to make use of the channel redundancy, and introduce a weight matrix to balance the data fidelity of the three channels in consideration of their different noise statistics. The proposed MC-WNNM model does not have an analytical solution. We reformulate it into a linear equality-constrained problem and solve it with the alternating direction method of multipliers. Each alternative updating step has closed-form solution and the convergence can be guaranteed. Extensive experiments on both synthetic and real noisy image datasets demonstrate the superiority of the proposed MC-WNNM over state-of-the-art denoising methods.
GPU Activity Prediction using Representation Learning
Mar 27, 2017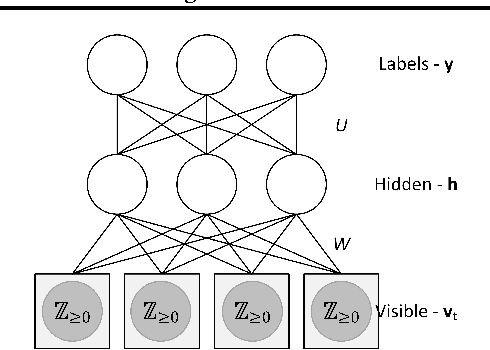
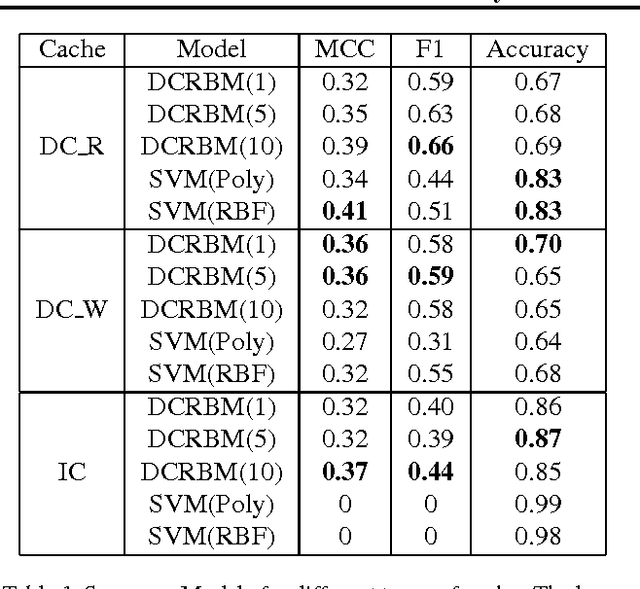
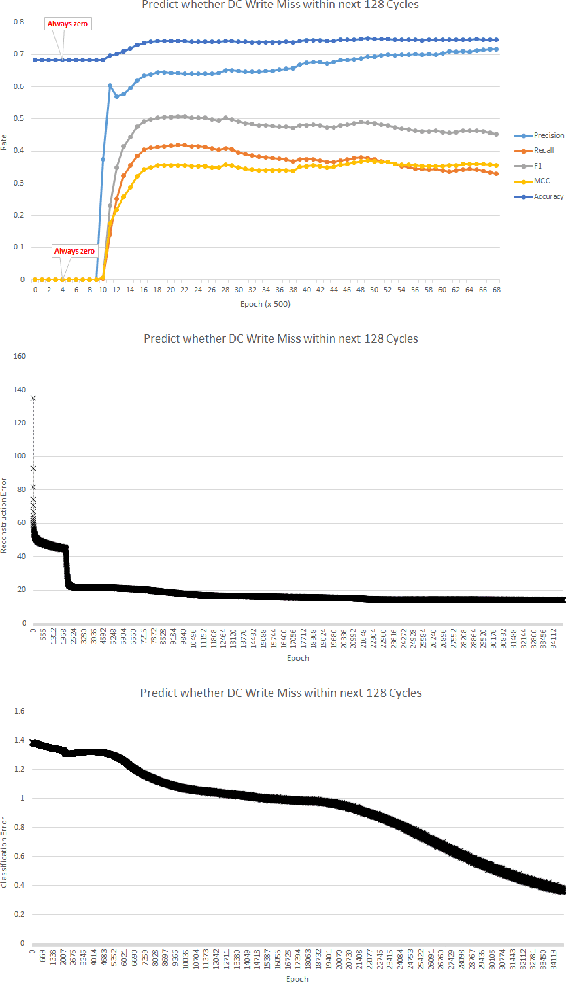
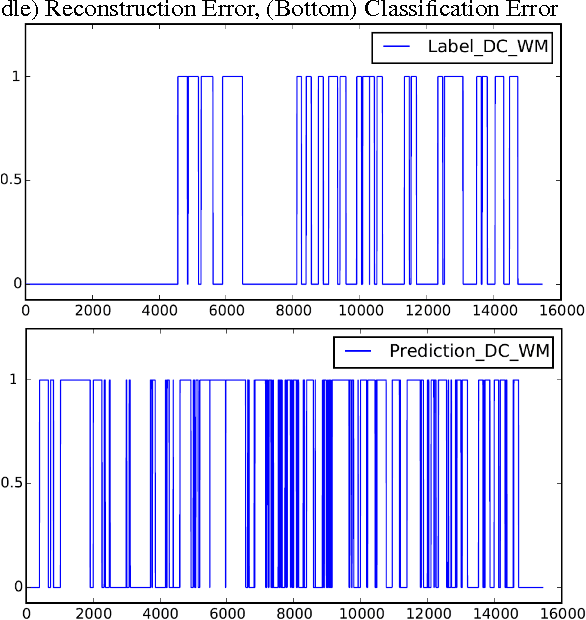
GPU activity prediction is an important and complex problem. This is due to the high level of contention among thousands of parallel threads. This problem was mostly addressed using heuristics. We propose a representation learning approach to address this problem. We model any performance metric as a temporal function of the executed instructions with the intuition that the flow of instructions can be identified as distinct activities of the code. Our experiments show high accuracy and non-trivial predictive power of representation learning on a benchmark.
Low Precision Neural Networks using Subband Decomposition
Mar 24, 2017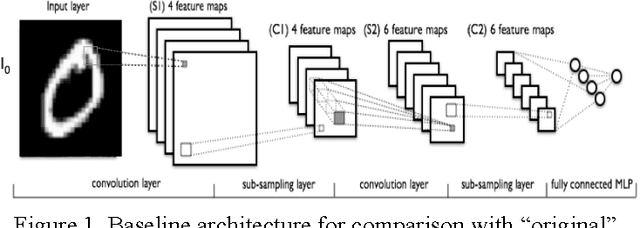
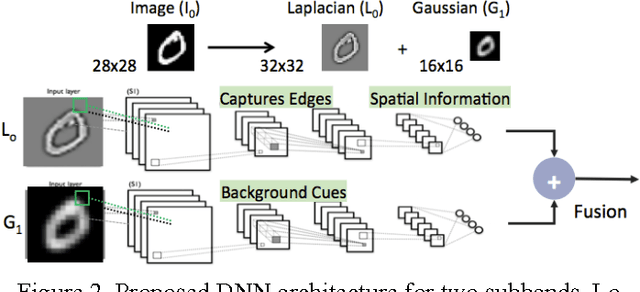
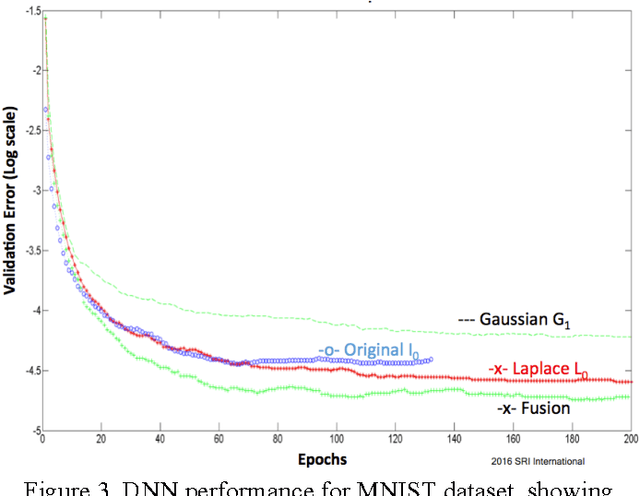
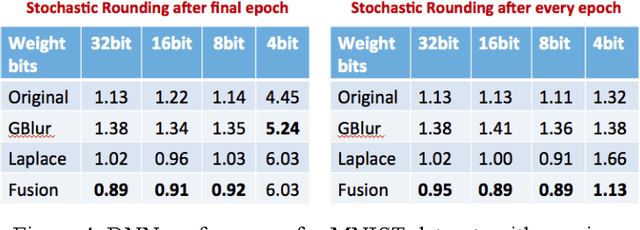
Large-scale deep neural networks (DNN) have been successfully used in a number of tasks from image recognition to natural language processing. They are trained using large training sets on large models, making them computationally and memory intensive. As such, there is much interest in research development for faster training and test time. In this paper, we present a unique approach using lower precision weights for more efficient and faster training phase. We separate imagery into different frequency bands (e.g. with different information content) such that the neural net can better learn using less bits. We present this approach as a complement existing methods such as pruning network connections and encoding learning weights. We show results where this approach supports more stable learning with 2-4X reduction in precision with 17X reduction in DNN parameters.
Deep Identity-aware Transfer of Facial Attributes
Oct 18, 2016
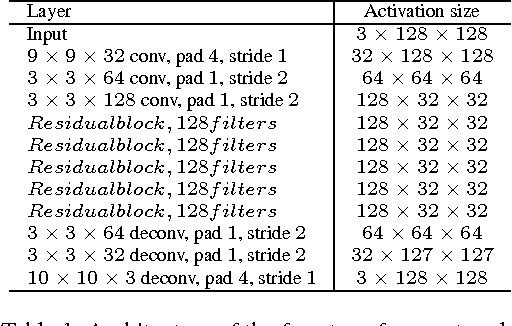
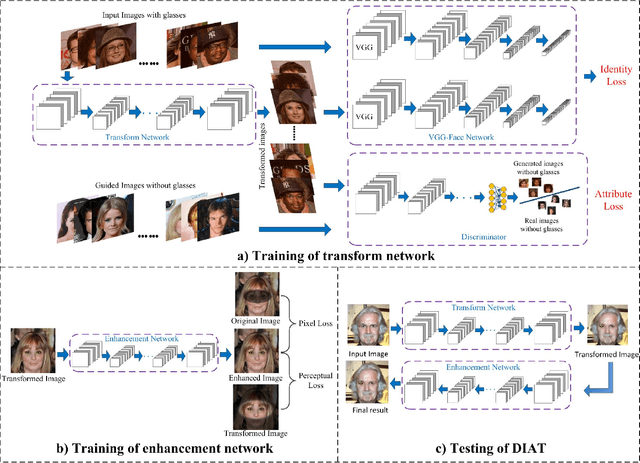
This paper presents a Deep convolutional network model for Identity-Aware Transfer (DIAT) of facial attributes. Given the source input image and the reference attribute, DIAT aims to generate a facial image (i.e., target image) that not only owns the reference attribute but also keep the same or similar identity to the input image. We develop a two-stage scheme to transfer the input image to each reference attribute label. A feed-forward transform network is first trained by combining perceptual identity-aware loss and GAN-based attribute loss, and a face enhancement network is then introduced to improve the visual quality. We further define perceptual identity loss on the convolutional feature maps of the attribute discriminator, resulting in a DIAT-A model. Our DIAT and DIAT-A models can provide a unified solution for several representative facial attribute transfer tasks such as expression transfer, accessory removal, age progression, and gender transfer. The experimental results validate their effectiveness. Even for some identity-related attribute (e.g., gender), our DIAT-A can obtain visually impressive results by changing the attribute while retaining most identity features of the source image.
Evolutionary Cost-sensitive Extreme Learning Machine
Sep 22, 2016
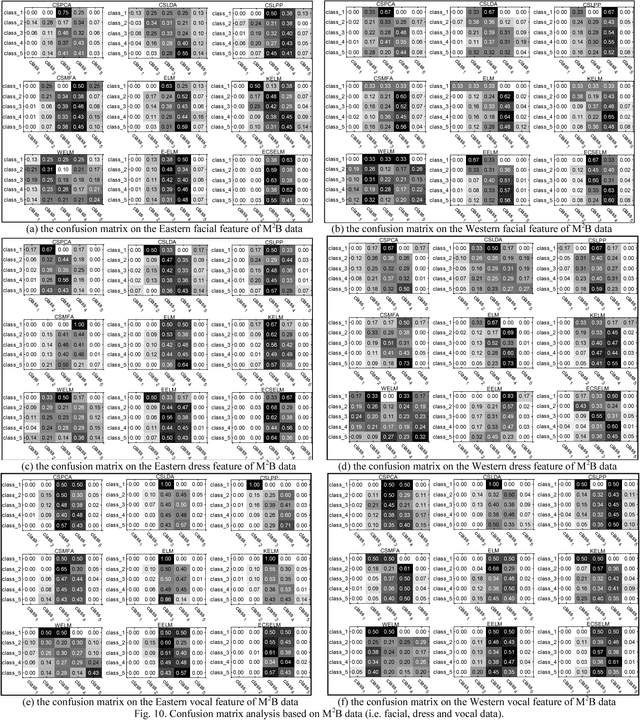
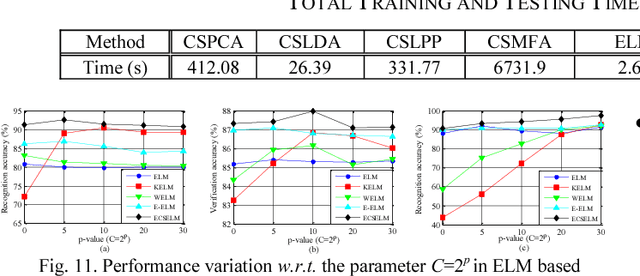
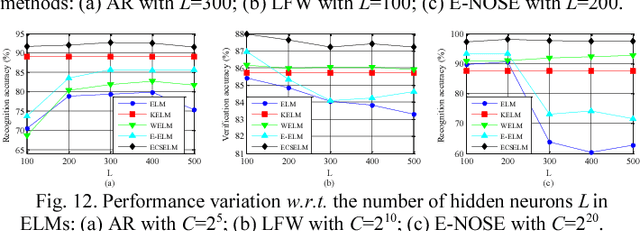
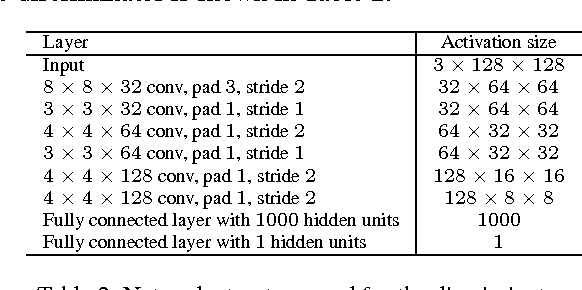
Conventional extreme learning machines solve a Moore-Penrose generalized inverse of hidden layer activated matrix and analytically determine the output weights to achieve generalized performance, by assuming the same loss from different types of misclassification. The assumption may not hold in cost-sensitive recognition tasks, such as face recognition based access control system, where misclassifying a stranger as a family member may result in more serious disaster than misclassifying a family member as a stranger. Though recent cost-sensitive learning can reduce the total loss with a given cost matrix that quantifies how severe one type of mistake against another, in many realistic cases the cost matrix is unknown to users. Motivated by these concerns, this paper proposes an evolutionary cost-sensitive extreme learning machine (ECSELM), with the following merits: 1) to our best knowledge, it is the first proposal of ELM in evolutionary cost-sensitive classification scenario; 2) it well addresses the open issue of how to define the cost matrix in cost-sensitive learning tasks; 3) an evolutionary backtracking search algorithm is induced for adaptive cost matrix optimization. Experiments in a variety of cost-sensitive tasks well demonstrate the effectiveness of the proposed approaches, with about 5%~10% improvements.
Convolutional Network for Attribute-driven and Identity-preserving Human Face Generation
Aug 23, 2016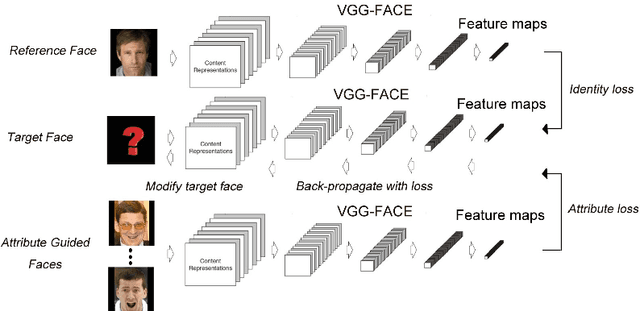
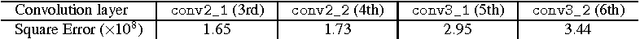
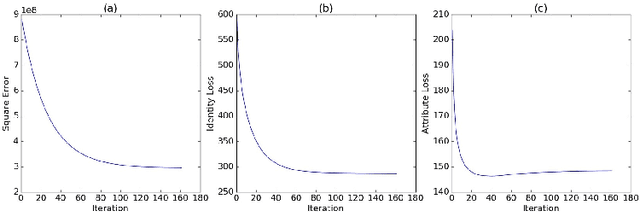
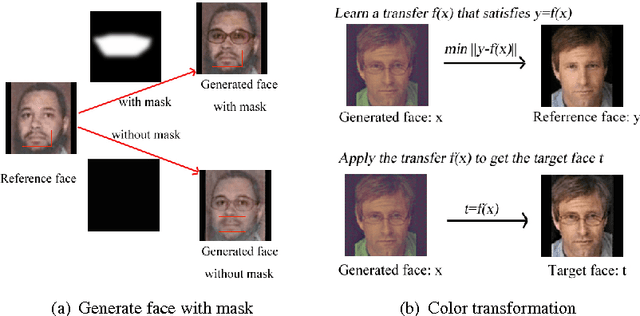
This paper focuses on the problem of generating human face pictures from specific attributes. The existing CNN-based face generation models, however, either ignore the identity of the generated face or fail to preserve the identity of the reference face image. Here we address this problem from the view of optimization, and suggest an optimization model to generate human face with the given attributes while keeping the identity of the reference image. The attributes can be obtained from the attribute-guided image or by tuning the attribute features of the reference image. With the deep convolutional network "VGG-Face", the loss is defined on the convolutional feature maps. We then apply the gradient decent algorithm to solve this optimization problem. The results validate the effectiveness of our method for attribute driven and identity-preserving face generation.
Robust Visual Knowledge Transfer via EDA
Aug 09, 2016

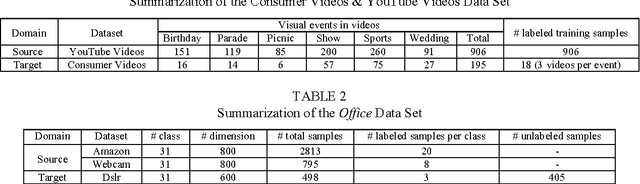
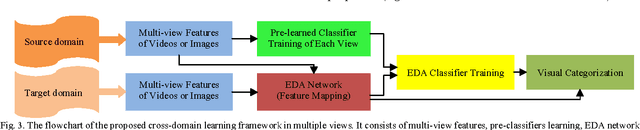
We address the problem of visual knowledge adaptation by leveraging labeled patterns from source domain and a very limited number of labeled instances in target domain to learn a robust classifier for visual categorization. This paper proposes a new extreme learning machine based cross-domain network learning framework, that is called Extreme Learning Machine (ELM) based Domain Adaptation (EDA). It allows us to learn a category transformation and an ELM classifier with random projection by minimizing the l_(2,1)-norm of the network output weights and the learning error simultaneously. The unlabeled target data, as useful knowledge, is also integrated as a fidelity term to guarantee the stability during cross domain learning. It minimizes the matching error between the learned classifier and a base classifier, such that many existing classifiers can be readily incorporated as base classifiers. The network output weights cannot only be analytically determined, but also transferrable. Additionally, a manifold regularization with Laplacian graph is incorporated, such that it is beneficial to semi-supervised learning. Extensively, we also propose a model of multiple views, referred as MvEDA. Experiments on benchmark visual datasets for video event recognition and object recognition, demonstrate that our EDA methods outperform existing cross-domain learning methods.
Multi-modal Fusion for Diabetes Mellitus and Impaired Glucose Regulation Detection
Apr 12, 2016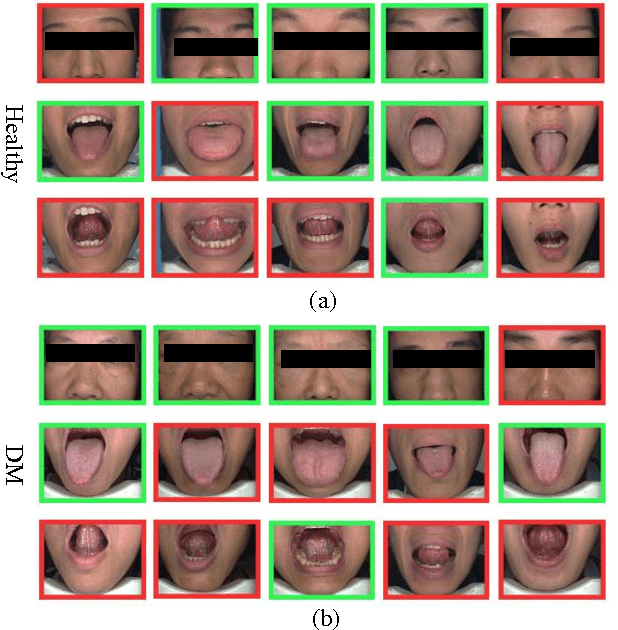
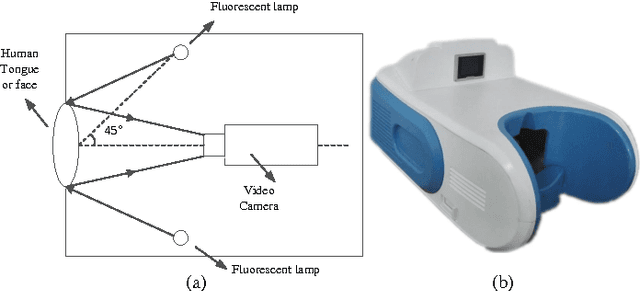
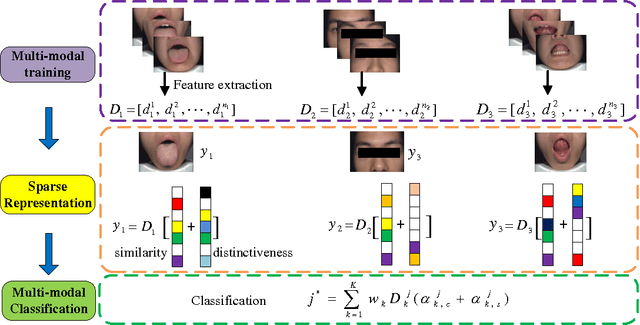
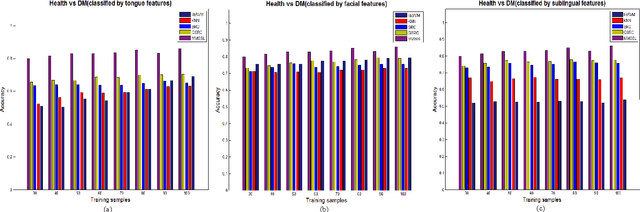
Effective and accurate diagnosis of Diabetes Mellitus (DM), as well as its early stage Impaired Glucose Regulation (IGR), has attracted much attention recently. Traditional Chinese Medicine (TCM) [3], [5] etc. has proved that tongue, face and sublingual diagnosis as a noninvasive method is a reasonable way for disease detection. However, most previous works only focus on a single modality (tongue, face or sublingual) for diagnosis, although different modalities may provide complementary information for the diagnosis of DM and IGR. In this paper, we propose a novel multi-modal classification method to discriminate between DM (or IGR) and healthy controls. Specially, the tongue, facial and sublingual images are first collected by using a non-invasive capture device. The color, texture and geometry features of these three types of images are then extracted, respectively. Finally, our so-called multi-modal similar and specific learning (MMSSL) approach is proposed to combine features of tongue, face and sublingual, which not only exploits the correlation but also extracts individual components among them. Experimental results on a dataset consisting of 192 Healthy, 198 DM and 114 IGR samples (all samples were obtained from Guangdong Provincial Hospital of Traditional Chinese Medicine) substantiate the effectiveness and superiority of our proposed method for the diagnosis of DM and IGR, compared to the case of using a single modality.
Quadratic Projection Based Feature Extraction with Its Application to Biometric Recognition
Mar 25, 2016
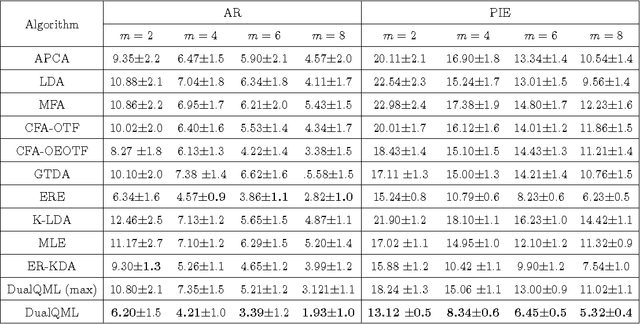
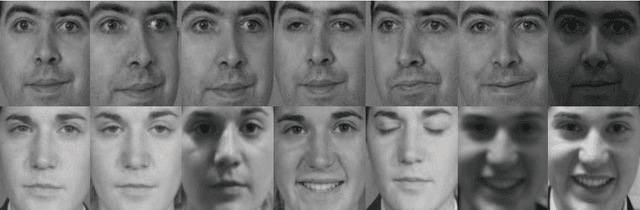
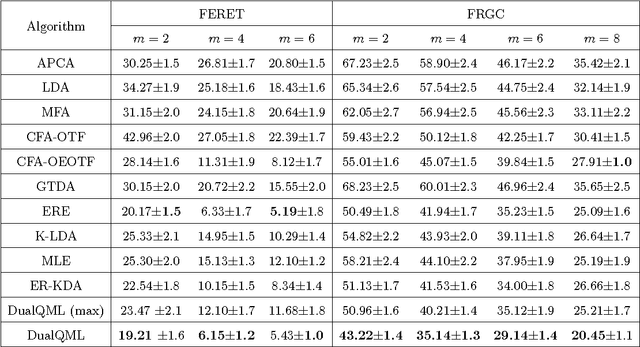
This paper presents a novel quadratic projection based feature extraction framework, where a set of quadratic matrices is learned to distinguish each class from all other classes. We formulate quadratic matrix learning (QML) as a standard semidefinite programming (SDP) problem. However, the con- ventional interior-point SDP solvers do not scale well to the problem of QML for high-dimensional data. To solve the scalability of QML, we develop an efficient algorithm, termed DualQML, based on the Lagrange duality theory, to extract nonlinear features. To evaluate the feasibility and effectiveness of the proposed framework, we conduct extensive experiments on biometric recognition. Experimental results on three representative biometric recogni- tion tasks, including face, palmprint, and ear recognition, demonstrate the superiority of the DualQML-based feature extraction algorithm compared to the current state-of-the-art algorithms
A survey of sparse representation: algorithms and applications
Feb 23, 2016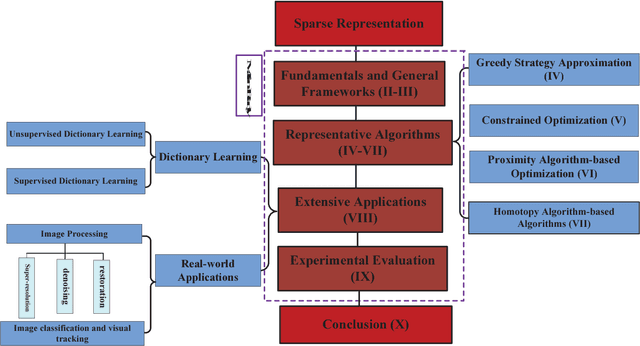
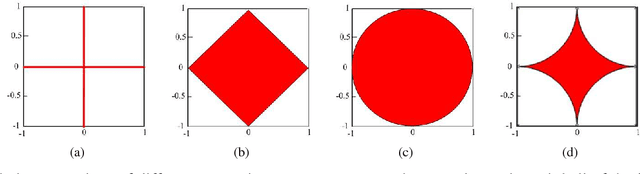
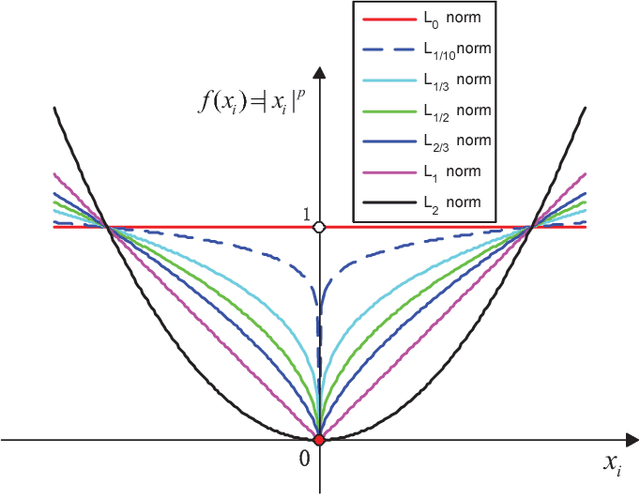
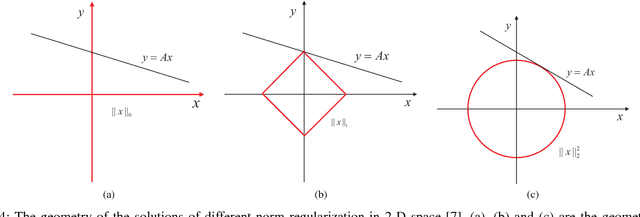
Sparse representation has attracted much attention from researchers in fields of signal processing, image processing, computer vision and pattern recognition. Sparse representation also has a good reputation in both theoretical research and practical applications. Many different algorithms have been proposed for sparse representation. The main purpose of this article is to provide a comprehensive study and an updated review on sparse representation and to supply a guidance for researchers. The taxonomy of sparse representation methods can be studied from various viewpoints. For example, in terms of different norm minimizations used in sparsity constraints, the methods can be roughly categorized into five groups: sparse representation with $l_0$-norm minimization, sparse representation with $l_p$-norm (0$<$p$<$1) minimization, sparse representation with $l_1$-norm minimization and sparse representation with $l_{2,1}$-norm minimization. In this paper, a comprehensive overview of sparse representation is provided. The available sparse representation algorithms can also be empirically categorized into four groups: greedy strategy approximation, constrained optimization, proximity algorithm-based optimization, and homotopy algorithm-based sparse representation. The rationales of different algorithms in each category are analyzed and a wide range of sparse representation applications are summarized, which could sufficiently reveal the potential nature of the sparse representation theory. Specifically, an experimentally comparative study of these sparse representation algorithms was presented. The Matlab code used in this paper can be available at: http://www.yongxu.org/lunwen.html.