 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPOLLO: SGD-like Memory, AdamW-level Performance
Dec 09, 2024



Large language models (LLMs) are notoriously memory-intensive during training, particularly with the popular AdamW optimizer. This memory burden necessitates using more or higher-end GPUs or reducing batch sizes, limiting training scalability and throughput. To address this, various memory-efficient optimizers have been proposed to reduce optimizer memory usage. However, they face critical challenges: (i) reliance on costly SVD operations; (ii) significant performance trade-offs compared to AdamW; and (iii) still substantial optimizer memory overhead to maintain competitive performance. In this work, we identify that AdamW's learning rate adaptation rule can be effectively coarsened as a structured learning rate update. Based on this insight, we propose Approximated Gradient Scaling for Memory-Efficient LLM Optimization (APOLLO), which approximates learning rate scaling using an auxiliary low-rank optimizer state based on pure random projection. This structured learning rate update rule makes APOLLO highly tolerant to further memory reductions while delivering comparable pre-training performance. Even its rank-1 variant, APOLLO-Mini, achieves superior pre-training performance compared to AdamW with SGD-level memory costs. Extensive experiments demonstrate that the APOLLO series performs on-par with or better than AdamW, while achieving greater memory savings by nearly eliminating the optimization states of AdamW. These savings provide significant system-level benefits: (1) Enhanced Throughput: 3x throughput on an 8xA100-80GB setup compared to AdamW by supporting 4x larger batch sizes. (2) Improved Model Scalability: Pre-training LLaMA-13B with naive DDP on A100-80GB GPUs without system-level optimizations. (3) Low-End GPU Friendly Pre-training: Pre-training LLaMA-7B on a single GPU using less than 12 GB of memory with weight quantization.
PACE: Pacing Operator Learning to Accurate Optical Field Simulation for Complicated Photonic Devices
Nov 05, 2024



Electromagnetic field simulation is central to designing, optimizing, and validating photonic devices and circuits. However, costly computation associated with numerical simulation poses a significant bottleneck, hindering scalability and turnaround time in the photonic circuit design process. Neural operators offer a promising alternative, but existing SOTA approaches, NeurOLight, struggle with predicting high-fidelity fields for real-world complicated photonic devices, with the best reported 0.38 normalized mean absolute error in NeurOLight. The inter-plays of highly complex light-matter interaction, e.g., scattering and resonance, sensitivity to local structure details, non-uniform learning complexity for full-domain simulation, and rich frequency information, contribute to the failure of existing neural PDE solvers. In this work, we boost the prediction fidelity to an unprecedented level for simulating complex photonic devices with a novel operator design driven by the above challenges. We propose a novel cross-axis factorized PACE operator with a strong long-distance modeling capacity to connect the full-domain complex field pattern with local device structures. Inspired by human learning, we further divide and conquer the simulation task for extremely hard cases into two progressively easy tasks, with a first-stage model learning an initial solution refined by a second model. On various complicated photonic device benchmarks, we demonstrate one sole PACE model is capable of achieving 73% lower error with 50% fewer parameters compared with various recent ML for PDE solvers. The two-stage setup further advances high-fidelity simulation for even more intricate cases. In terms of runtime, PACE demonstrates 154-577x and 11.8-12x simulation speedup over numerical solver using scipy or highly-optimized pardiso solver, respectively. We open sourced the code and dataset.
Differentiable Edge-based OPC
Aug 16, 2024



Optical proximity correction (OPC) is crucial for pushing the boundaries of semiconductor manufacturing and enabling the continued scaling of integrated circuits. While pixel-based OPC, termed as inverse lithography technology (ILT), has gained research interest due to its flexibility and precision. Its complexity and intricate features can lead to challenges in mask writing, increased defects, and higher costs, hence hindering widespread industrial adoption. In this paper, we propose DiffOPC, a differentiable OPC framework that enjoys the virtue of both edge-based OPC and ILT. By employing a mask rule-aware gradient-based optimization approach, DiffOPC efficiently guides mask edge segment movement during mask optimization, minimizing wafer error by propagating true gradients from the cost function back to the mask edges. Our approach achieves lower edge placement error while reducing manufacturing cost by half compared to state-of-the-art OPC techniques, bridging the gap between the high accuracy of pixel-based OPC and the practicality required for industrial adoption, thus offering a promising solution for advanced semiconductor manufacturing.
INSIGHT: Universal Neural Simulator for Analog Circuits Harnessing Autoregressive Transformers
Jul 10, 2024



Analog front-end design heavily relies on specialized human expertise and costly trial-and-error simulations, which motivated many prior works on analog design automation. However, efficient and effective exploration of the vast and complex design space remains constrained by the time-consuming nature of CPU-based SPICE simulations, making effective design automation a challenging endeavor. In this paper, we introduce INSIGHT, a GPU-powered, technology-independent, effective universal neural simulator in the analog front-end design automation loop. INSIGHT accurately predicts the performance metrics of analog circuits across various technology nodes, significantly reducing inference time. Notably, its autoregressive capabilities enable INSIGHT to accurately predict simulation-costly critical transient specifications leveraging less expensive performance metric information. The low cost and high fidelity feature make INSIGHT a good substitute for standard simulators in analog front-end optimization frameworks. INSIGHT is compatible with any optimization framework, facilitating enhanced design space exploration for sample efficiency through sophisticated offline learning and adaptation techniques. Our experiments demonstrate that INSIGHT-M, a model-based batch reinforcement learning framework that leverages INSIGHT for analog sizing, achieves at least 50X improvement in sample efficiency across circuits. To the best of our knowledge, this marks the first use of autoregressive transformers in analog front-end design.
LLM-Enhanced Bayesian Optimization for Efficient Analog Layout Constraint Generation
Jun 07, 2024



Analog layout synthesis faces significant challenges due to its dependence on manual processes, considerable time requirements, and performance instability. Current Bayesian Optimization (BO)-based techniques for analog layout synthesis, despite their potential for automation, suffer from slow convergence and extensive data needs, limiting their practical application. This paper presents the \texttt{LLANA} framework, a novel approach that leverages Large Language Models (LLMs) to enhance BO by exploiting the few-shot learning abilities of LLMs for more efficient generation of analog design-dependent parameter constraints. Experimental results demonstrate that \texttt{LLANA} not only achieves performance comparable to state-of-the-art (SOTA) BO methods but also enables a more effective exploration of the analog circuit design space, thanks to LLM's superior contextual understanding and learning efficiency. The code is available at \url{https://github.com/dekura/LLANA}.
AnalogCoder: Analog Circuit Design via Training-Free Code Generation
May 23, 2024



Analog circuit design is a significant task in modern chip technology, focusing on the selection of component types, connectivity, and parameters to ensure proper circuit functionality. Despite advances made by Large Language Models (LLMs) in digital circuit design, the complexity and scarcity of data in analog circuitry pose significant challenges. To mitigate these issues, we introduce AnalogCoder, the first training-free LLM agent for designing analog circuits through Python code generation. Firstly, AnalogCoder incorporates a feedback-enhanced flow with tailored domain-specific prompts, enabling the automated and self-correcting design of analog circuits with a high success rate. Secondly, it proposes a circuit tool library to archive successful designs as reusable modular sub-circuits, simplifying composite circuit creation. Thirdly, extensive experiments on a benchmark designed to cover a wide range of analog circuit tasks show that AnalogCoder outperforms other LLM-based methods. It has successfully designed 20 circuits, 5 more than standard GPT-4o. We believe AnalogCoder can significantly improve the labor-intensive chip design process, enabling non-experts to design analog circuits efficiently. Codes and the benchmark are provided at https://github.com/anonyanalog/AnalogCoder.
Scalable and Effective Arithmetic Tree Generation for Adder and Multiplier Designs
May 10, 2024
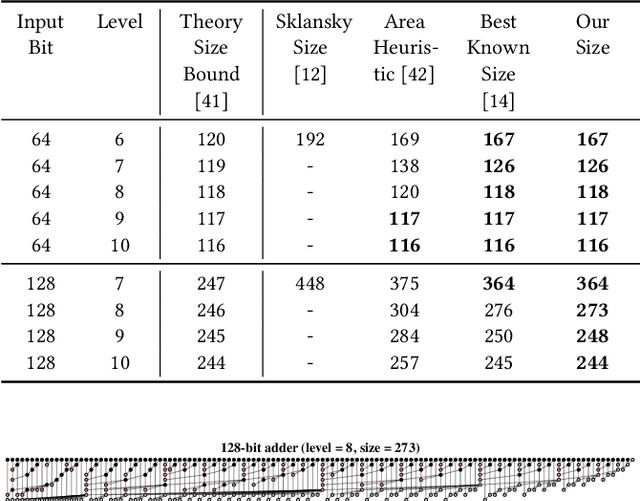


Across a wide range of hardware scenarios, the computational efficiency and physical size of the arithmetic units significantly influence the speed and footprint of the overall hardware system. Nevertheless, the effectiveness of prior arithmetic design techniques proves inadequate, as it does not sufficiently optimize speed and area, resulting in a reduced processing rate and larger module size. To boost the arithmetic performance, in this work, we focus on the two most common and fundamental arithmetic modules: adders and multipliers. We cast the design tasks as single-player tree generation games, leveraging reinforcement learning techniques to optimize their arithmetic tree structures. Such a tree generation formulation allows us to efficiently navigate the vast search space and discover superior arithmetic designs that improve computational efficiency and hardware size within just a few hours. For adders, our approach discovers designs of 128-bit adders that achieve Pareto optimality in theoretical metrics. Compared with the state-of-the-art PrefixRL, our method decreases computational delay and hardware size by up to 26% and 30%, respectively. For multipliers, when compared to RL-MUL, our approach increases speed and reduces size by as much as 49% and 45%. Moreover, the inherent flexibility and scalability of our method enable us to deploy our designs into cutting-edge technologies, as we show that they can be seamlessly integrated into 7nm technology. We believe our work will offer valuable insights into hardware design, further accelerating speed and reducing size through the refined search space and our tree generation methodologies. See our introduction video at https://bit.ly/ArithmeticTree. Codes are released at https://github.com/laiyao1/ArithmeticTree.
Subgraph Extraction-based Feedback-guided Iterative Scheduling for HLS
Jan 22, 2024



This paper proposes ISDC, a novel feedback-guided iterative system of difference constraints (SDC) scheduling algorithm for high-level synthesis (HLS). ISDC leverages subgraph extraction-based low-level feedback from downstream tools like logic synthesizers to iteratively refine HLS scheduling. Technical innovations include: (1) An enhanced SDC formulation that effectively integrates low-level feedback into the linear-programming (LP) problem; (2) A fanout and window-based subgraph extraction mechanism driving the feedback cycle; (3) A no-human-in-loop ISDC flow compatible with a wide range of downstream tools and process design kits (PDKs). Evaluation shows that ISDC reduces register usage by 28.5% against an industrial-strength open-source HLS tool.
QuantumSEA: In-Time Sparse Exploration for Noise Adaptive Quantum Circuits
Jan 10, 2024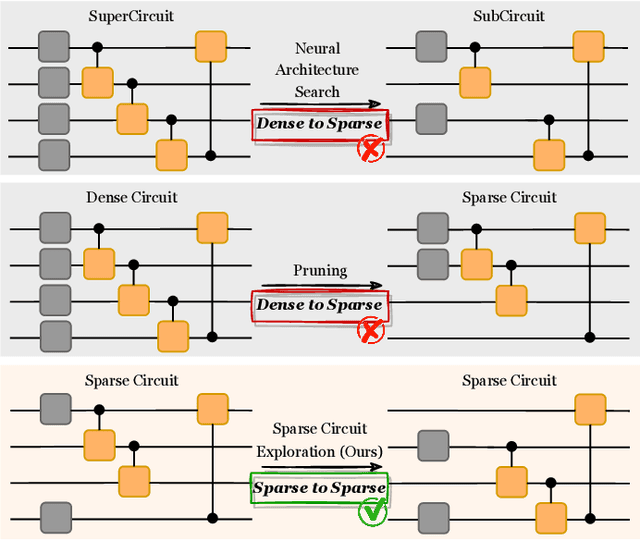
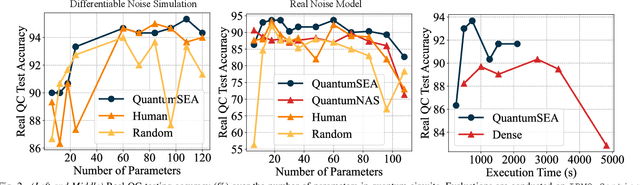
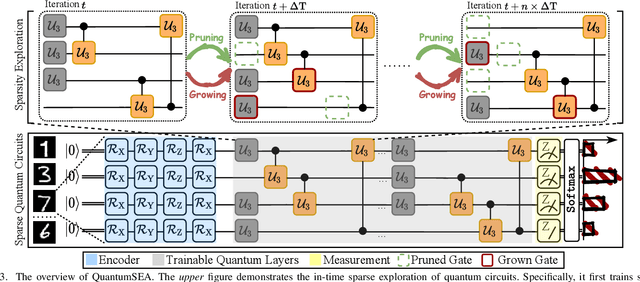
Parameterized Quantum Circuits (PQC) have obtained increasing popularity thanks to their great potential for near-term Noisy Intermediate-Scale Quantum (NISQ) computers. Achieving quantum advantages usually requires a large number of qubits and quantum circuits with enough capacity. However, limited coherence time and massive quantum noises severely constrain the size of quantum circuits that can be executed reliably on real machines. To address these two pain points, we propose QuantumSEA, an in-time sparse exploration for noise-adaptive quantum circuits, aiming to achieve two key objectives: (1) implicit circuits capacity during training - by dynamically exploring the circuit's sparse connectivity and sticking a fixed small number of quantum gates throughout the training which satisfies the coherence time and enjoy light noises, enabling feasible executions on real quantum devices; (2) noise robustness - by jointly optimizing the topology and parameters of quantum circuits under real device noise models. In each update step of sparsity, we leverage the moving average of historical gradients to grow necessary gates and utilize salience-based pruning to eliminate insignificant gates. Extensive experiments are conducted with 7 Quantum Machine Learning (QML) and Variational Quantum Eigensolver (VQE) benchmarks on 6 simulated or real quantum computers, where QuantumSEA consistently surpasses noise-aware search, human-designed, and randomly generated quantum circuit baselines by a clear performance margin. For example, even in the most challenging on-chip training regime, our method establishes state-of-the-art results with only half the number of quantum gates and ~2x time saving of circuit executions. Codes are available at https://github.com/VITA-Group/QuantumSEA.
Transformer-QEC: Quantum Error Correction Code Decoding with Transferable Transformers
Nov 27, 2023



Quantum computing has the potential to solve problems that are intractable for classical systems, yet the high error rates in contemporary quantum devices often exceed tolerable limits for useful algorithm execution. Quantum Error Correction (QEC) mitigates this by employing redundancy, distributing quantum information across multiple data qubits and utilizing syndrome qubits to monitor their states for errors. The syndromes are subsequently interpreted by a decoding algorithm to identify and correct errors in the data qubits. This task is complex due to the multiplicity of error sources affecting both data and syndrome qubits as well as syndrome extraction operations. Additionally, identical syndromes can emanate from different error sources, necessitating a decoding algorithm that evaluates syndromes collectively. Although machine learning (ML) decoders such as multi-layer perceptrons (MLPs) and convolutional neural networks (CNNs) have been proposed, they often focus on local syndrome regions and require retraining when adjusting for different code distances. We introduce a transformer-based QEC decoder which employs self-attention to achieve a global receptive field across all input syndromes. It incorporates a mixed loss training approach, combining both local physical error and global parity label losses. Moreover, the transformer architecture's inherent adaptability to variable-length inputs allows for efficient transfer learning, enabling the decoder to adapt to varying code distances without retraining. Evaluation on six code distances and ten different error configurations demonstrates that our model consistently outperforms non-ML decoders, such as Union Find (UF) and Minimum Weight Perfect Matching (MWPM), and other ML decoders, thereby achieving best logical error rates. Moreover, the transfer learning can save over 10x of training cost.