 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Reinforcement Learning Approach to Marginalized Importance Sampling with the Successor Representation
Jun 12, 2021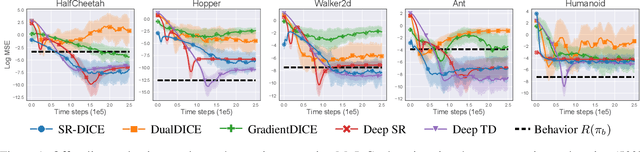
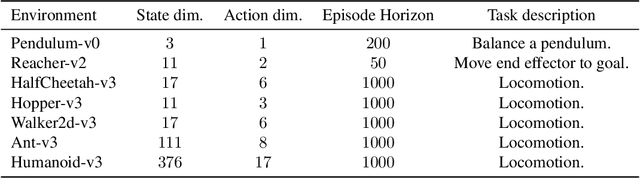
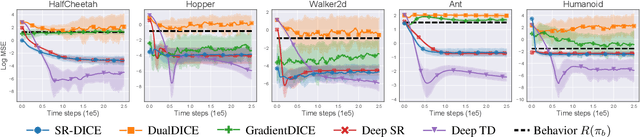
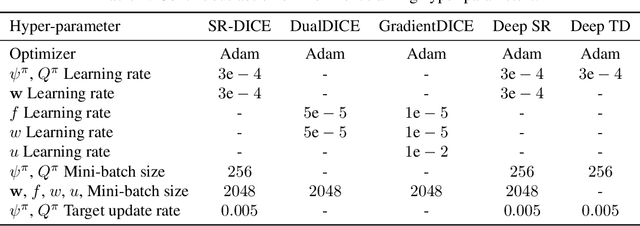
Marginalized importance sampling (MIS), which measures the density ratio between the state-action occupancy of a target policy and that of a sampling distribution, is a promising approach for off-policy evaluation. However, current state-of-the-art MIS methods rely on complex optimization tricks and succeed mostly on simple toy problems. We bridge the gap between MIS and deep reinforcement learning by observing that the density ratio can be computed from the successor representation of the target policy. The successor representation can be trained through deep reinforcement learning methodology and decouples the reward optimization from the dynamics of the environment, making the resulting algorithm stable and applicable to high-dimensional domains. We evaluate the empirical performance of our approach on a variety of challenging Atari and MuJoCo environments.
Learning Intuitive Physics with Multimodal Generative Models
Jan 19, 2021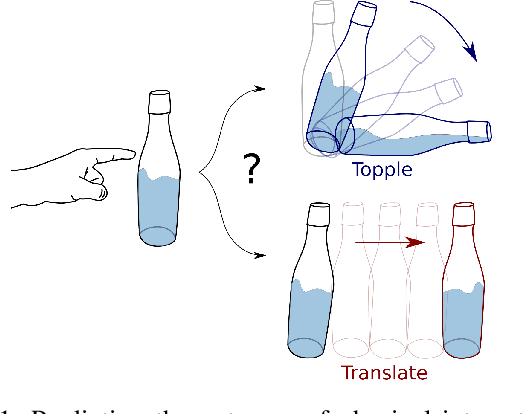
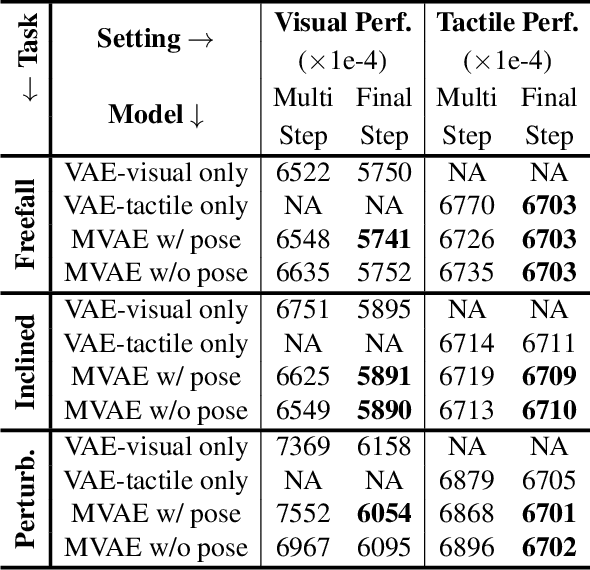

Predicting the future interaction of objects when they come into contact with their environment is key for autonomous agents to take intelligent and anticipatory actions. This paper presents a perception framework that fuses visual and tactile feedback to make predictions about the expected motion of objects in dynamic scenes. Visual information captures object properties such as 3D shape and location, while tactile information provides critical cues about interaction forces and resulting object motion when it makes contact with the environment. Utilizing a novel See-Through-your-Skin (STS) sensor that provides high resolution multimodal sensing of contact surfaces, our system captures both the visual appearance and the tactile properties of objects. We interpret the dual stream signals from the sensor using a Multimodal Variational Autoencoder (MVAE), allowing us to capture both modalities of contacting objects and to develop a mapping from visual to tactile interaction and vice-versa. Additionally, the perceptual system can be used to infer the outcome of future physical interactions, which we validate through simulated and real-world experiments in which the resting state of an object is predicted from given initial conditions.
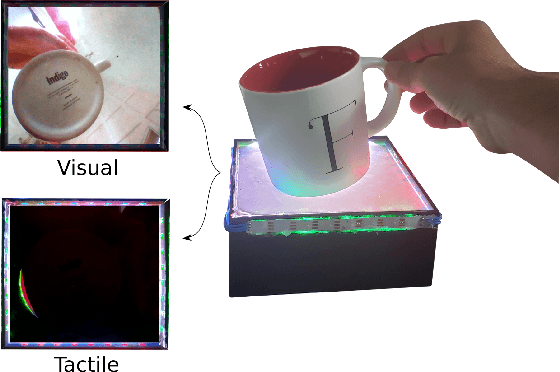
Seeing Through your Skin: Recognizing Objects with a Novel Visuotactile Sensor
Dec 14, 2020
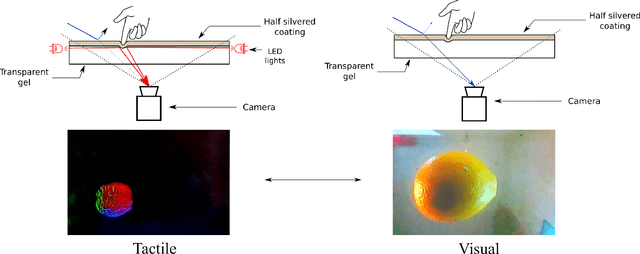
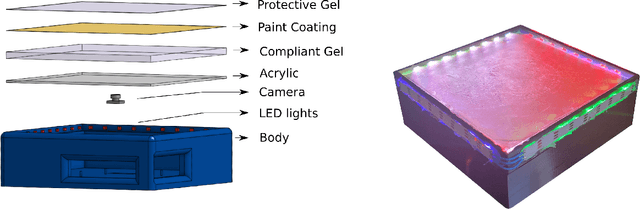
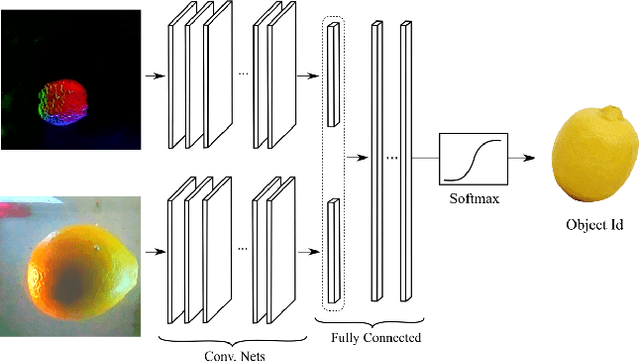
We introduce a new class of vision-based sensor and associated algorithmic processes that combine visual imaging with high-resolution tactile sending, all in a uniform hardware and computational architecture. We demonstrate the sensor's efficacy for both multi-modal object recognition and metrology. Object recognition is typically formulated as an unimodal task, but by combining two sensor modalities we show that we can achieve several significant performance improvements. This sensor, named the See-Through-your-Skin sensor (STS), is designed to provide rich multi-modal sensing of contact surfaces. Inspired by recent developments in optical tactile sensing technology, we address a key missing feature of these sensors: the ability to capture a visual perspective of the region beyond the contact surface. Whereas optical tactile sensors are typically opaque, we present a sensor with a semitransparent skin that has the dual capabilities of acting as a tactile sensor and/or as a visual camera depending on its internal lighting conditions. This paper details the design of the sensor, showcases its dual sensing capabilities, and presents a deep learning architecture that fuses vision and touch. We validate the ability of the sensor to classify household objects, recognize fine textures, and infer their physical properties both through numerical simulations and experiments with a smart countertop prototype.
Intervention Design for Effective Sim2Real Transfer
Dec 03, 2020
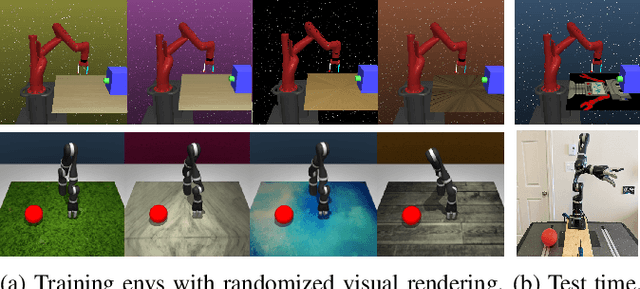
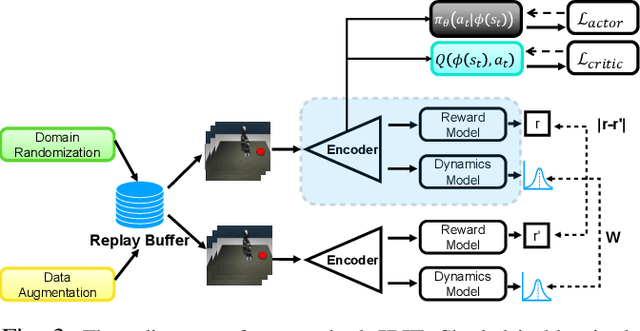
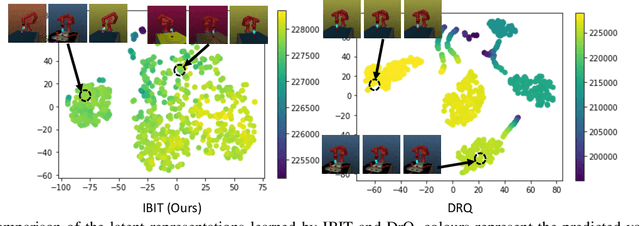
The goal of this work is to address the recent success of domain randomization and data augmentation for the sim2real setting. We explain this success through the lens of causal inference, positioning domain randomization and data augmentation as interventions on the environment which encourage invariance to irrelevant features. Such interventions include visual perturbations that have no effect on reward and dynamics. This encourages the learning algorithm to be robust to these types of variations and learn to attend to the true causal mechanisms for solving the task. This connection leads to two key findings: (1) perturbations to the environment do not have to be realistic, but merely show variation along dimensions that also vary in the real world, and (2) use of an explicit invariance-inducing objective improves generalization in sim2sim and sim2real transfer settings over just data augmentation or domain randomization alone. We demonstrate the capability of our method by performing zero-shot transfer of a robot arm reach task on a 7DoF Jaco arm learning from pixel observations.
Multimodal dynamics modeling for off-road autonomous vehicles
Nov 23, 2020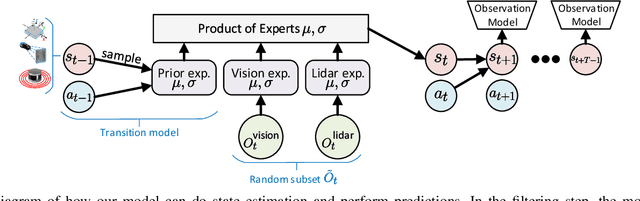

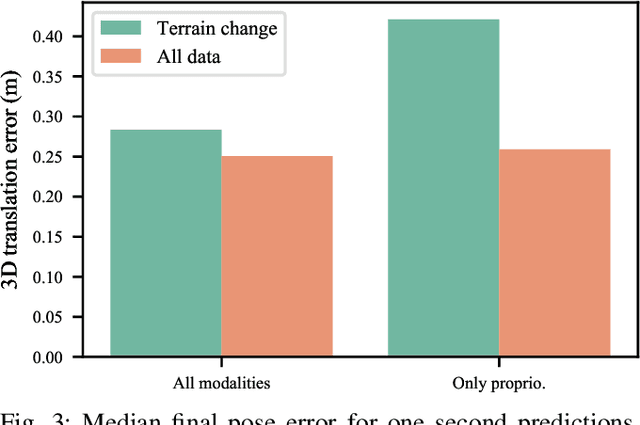

Dynamics modeling in outdoor and unstructured environments is difficult because different elements in the environment interact with the robot in ways that can be hard to predict. Leveraging multiple sensors to perceive maximal information about the robot's environment is thus crucial when building a model to perform predictions about the robot's dynamics with the goal of doing motion planning. We design a model capable of long-horizon motion predictions, leveraging vision, lidar and proprioception, which is robust to arbitrarily missing modalities at test time. We demonstrate in simulation that our model is able to leverage vision to predict traction changes. We then test our model using a real-world challenging dataset of a robot navigating through a forest, performing predictions in trajectories unseen during training. We try different modality combinations at test time and show that, while our model performs best when all modalities are present, it is still able to perform better than the baseline even when receiving only raw vision input and no proprioception, as well as when only receiving proprioception. Overall, our study demonstrates the importance of leveraging multiple sensors when doing dynamics modeling in outdoor conditions.
Learning the Latent Space of Robot Dynamics for Cutting Interaction Inference
Jul 22, 2020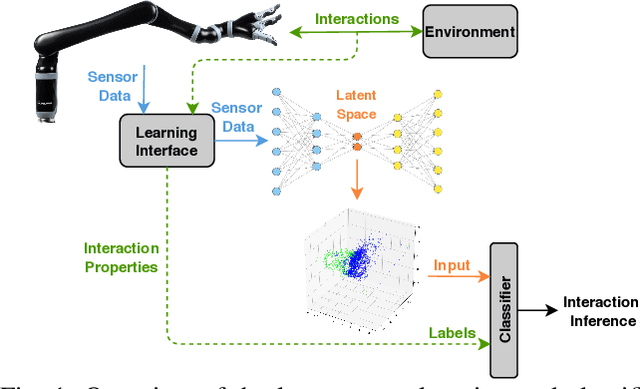
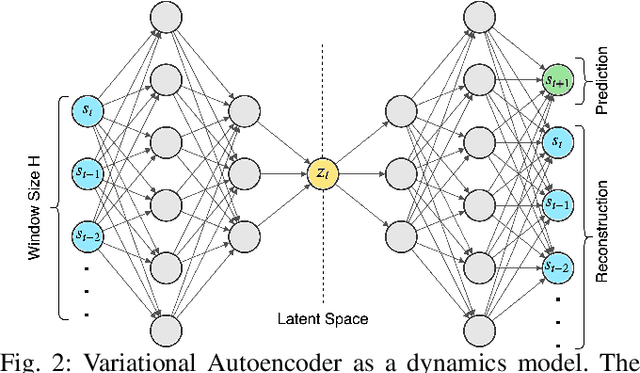

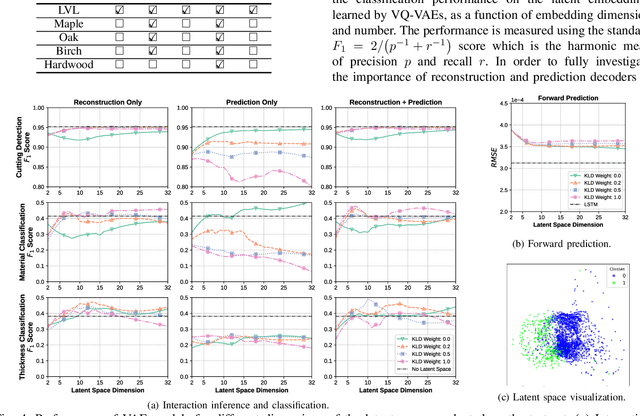
Utilization of latent space to capture a lower-dimensional representation of a complex dynamics model is explored in this work. The targeted application is of a robotic manipulator executing a complex environment interaction task, in particular, cutting a wooden object. We train two flavours of Variational Autoencoders---standard and Vector-Quantised---to learn the latent space which is then used to infer certain properties of the cutting operation, such as whether the robot is cutting or not, as well as, material and geometry of the object being cut. The two VAE models are evaluated with reconstruction, prediction and a combined reconstruction/prediction decoders. The results demonstrate the expressiveness of the latent space for robotic interaction inference and the competitive prediction performance against recurrent neural networks.
An Equivalence between Loss Functions and Non-Uniform Sampling in Experience Replay
Jul 12, 2020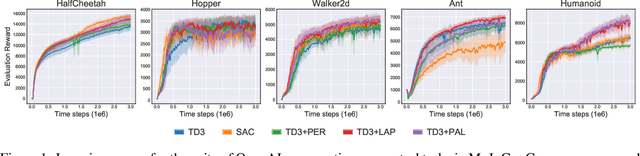
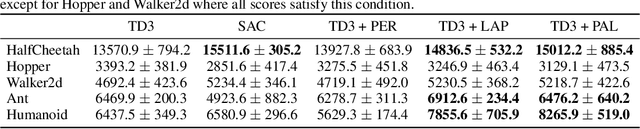
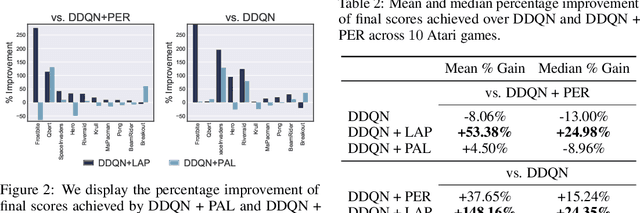
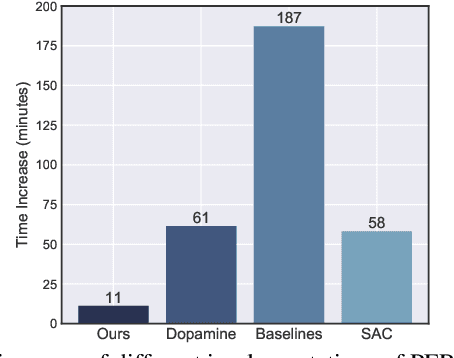
Prioritized Experience Replay (PER) is a deep reinforcement learning technique in which agents learn from transitions sampled with non-uniform probability proportionate to their temporal-difference error. We show that any loss function evaluated with non-uniformly sampled data can be transformed into another uniformly sampled loss function with the same expected gradient. Surprisingly, we find in some environments PER can be replaced entirely by this new loss function without impact to empirical performance. Furthermore, this relationship suggests a new branch of improvements to PER by correcting its uniformly sampled loss function equivalent. We demonstrate the effectiveness of our proposed modifications to PER and the equivalent loss function in several MuJoCo and Atari environments.
3D Shape Reconstruction from Vision and Touch
Jul 07, 2020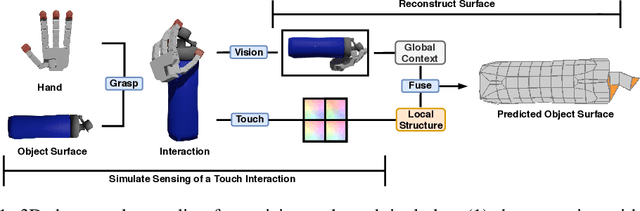
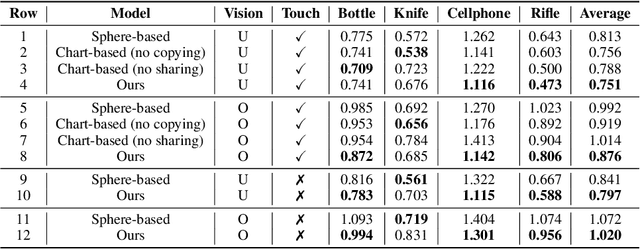
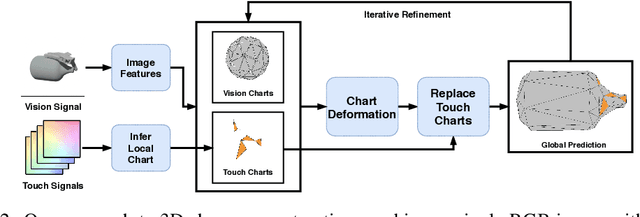

When a toddler is presented a new toy, their instinctual behaviour is to pick it up and inspect it with their hand and eyes in tandem, clearly searching over its surface to properly understand what they are playing with. Here, touch provides high fidelity localized information while vision provides complementary global context. However, in 3D shape reconstruction, the complementary fusion of visual and haptic modalities remains largely unexplored. In this paper, we study this problem and present an effective chart-based approach to fusing vision and touch, which leverages advances in graph convolutional networks. To do so, we introduce a dataset of simulated touch and vision signals from the interaction between a robotic hand and a large array of 3D objects. Our results show that (1) leveraging both vision and touch signals consistently improves single-modality baselines; (2) our approach outperforms alternative modality fusion methods and strongly benefits from the proposed chart-based structure; (3) the reconstruction quality increases with the number of grasps provided; and (4) the touch information not only enhances the reconstruction at the touch site but also extrapolates to its local neighborhood.
Vision-Based Goal-Conditioned Policies for Underwater Navigation in the Presence of Obstacles
Jun 29, 2020
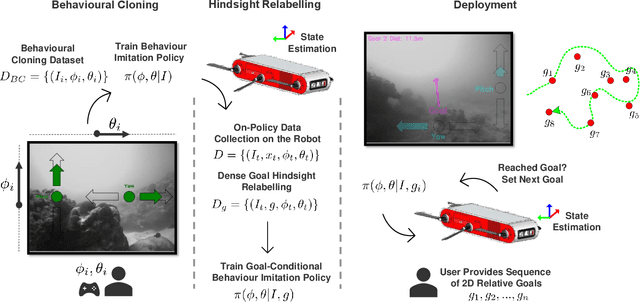
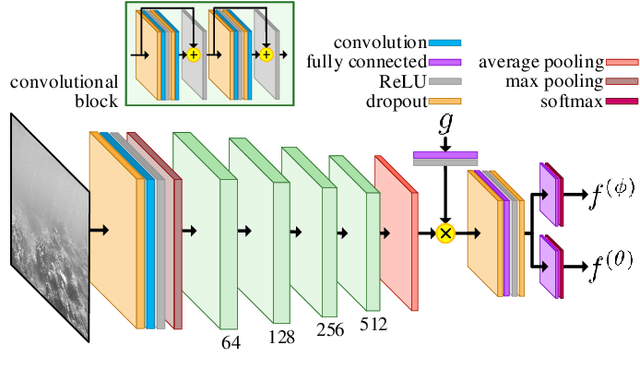
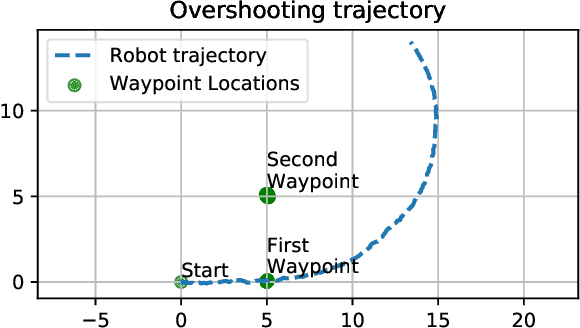
We present Nav2Goal, a data-efficient and end-to-end learning method for goal-conditioned visual navigation. Our technique is used to train a navigation policy that enables a robot to navigate close to sparse geographic waypoints provided by a user without any prior map, all while avoiding obstacles and choosing paths that cover user-informed regions of interest. Our approach is based on recent advances in conditional imitation learning. General-purpose, safe and informative actions are demonstrated by a human expert. The learned policy is subsequently extended to be goal-conditioned by training with hindsight relabelling, guided by the robot's relative localization system, which requires no additional manual annotation. We deployed our method on an underwater vehicle in the open ocean to collect scientifically relevant data of coral reefs, which allowed our robot to operate safely and autonomously, even at very close proximity to the coral. Our field deployments have demonstrated over a kilometer of autonomous visual navigation, where the robot reaches on the order of 40 waypoints, while collecting scientifically relevant data. This is done while travelling within 0.5 m altitude from sensitive corals and exhibiting significant learned agility to overcome turbulent ocean conditions and to actively avoid collisions.
Learning to Drive Off Road on Smooth Terrain in Unstructured Environments Using an On-Board Camera and Sparse Aerial Images
Apr 09, 2020
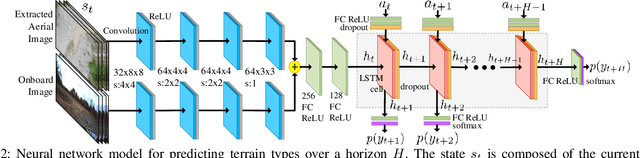

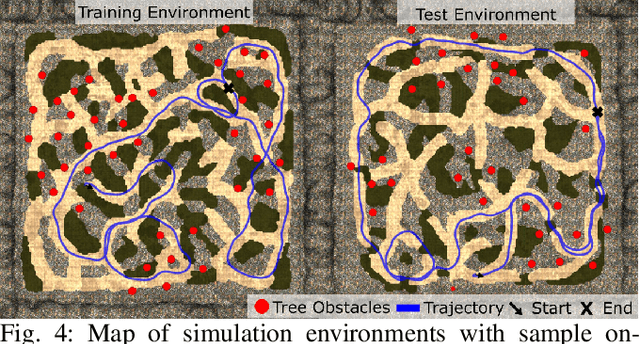
We present a method for learning to drive on smooth terrain while simultaneously avoiding collisions in challenging off-road and unstructured outdoor environments using only visual inputs. Our approach applies a hybrid model-based and model-free reinforcement learning method that is entirely self-supervised in labeling terrain roughness and collisions using on-board sensors. Notably, we provide both first-person and overhead aerial image inputs to our model. We find that the fusion of these complementary inputs improves planning foresight and makes the model robust to visual obstructions. Our results show the ability to generalize to environments with plentiful vegetation, various types of rock, and sandy trails. During evaluation, our policy attained 90% smooth terrain traversal and reduced the proportion of rough terrain driven over by 6.1 times compared to a model using only first-person imagery.