 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stream Consensus Network: Submission to HACS Challenge 2021 Weakly-Supervised Learning Track
Jul 11, 2021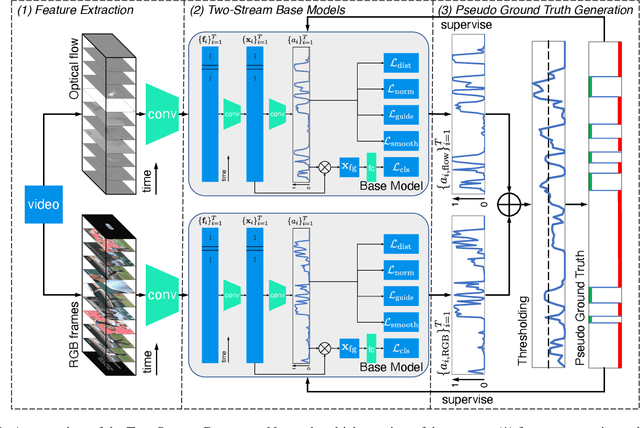
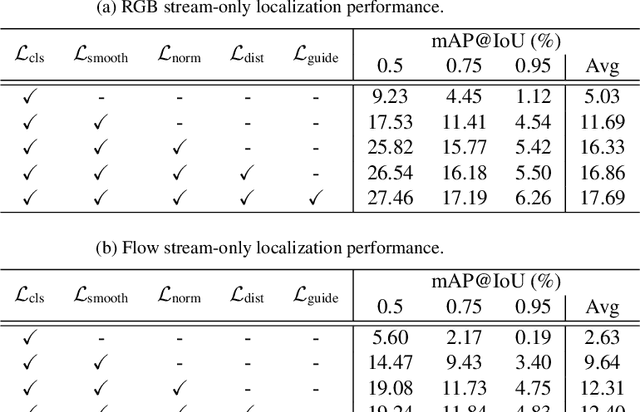
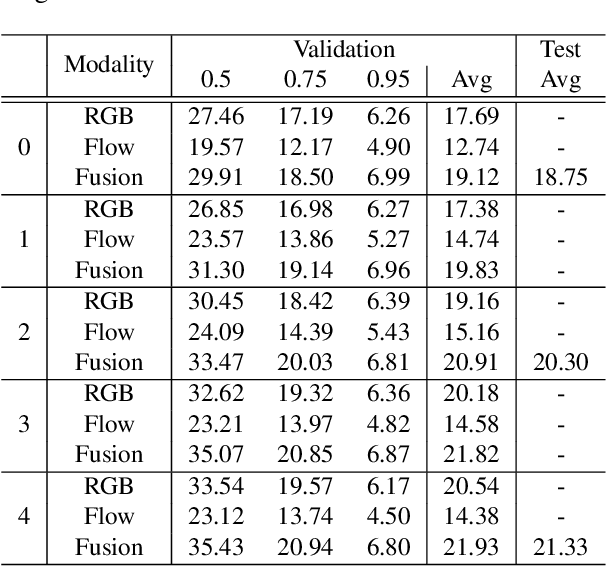
This technical report presents our solution to the HACS Temporal Action Localization Challenge 2021, Weakly-Supervised Learning Track. The goal of weakly-supervised temporal action localization is to temporally locate and classify action of interest in untrimmed videos given only video-level labels. We adopt the two-stream consensus network (TSCN) as the main framework in this challenge. The TSCN consists of a two-stream base model training procedure and a pseudo ground truth learning procedure. The base model training encourages the model to predict reliable predictions based on single modality (i.e., RGB or optical flow), based on the fusion of which a pseudo ground truth is generated and in turn used as supervision to train the base models. On the HACS v1.1.1 dataset, without fine-tuning the feature-extraction I3D models, our method achieves 22.20% on the validation set and 21.68% on the testing set in terms of average mAP. Our solution ranked the 2rd in this challenge, and we hope our method can serve as a baseline for future academic research.
Cogradient Descent for Dependable Learning
Jun 20, 2021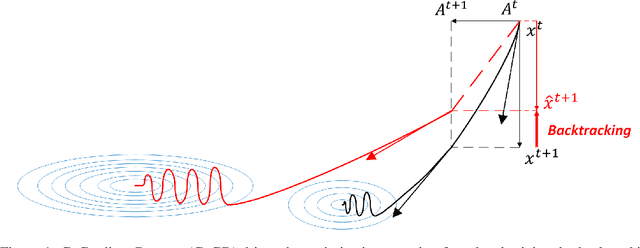
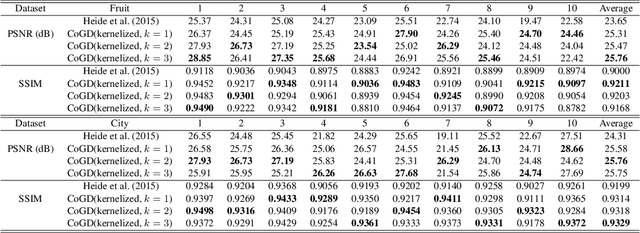
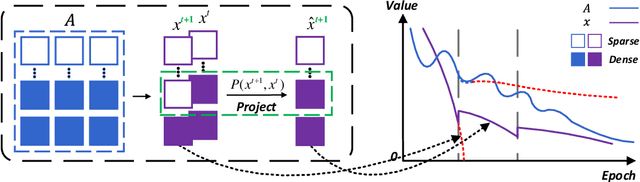
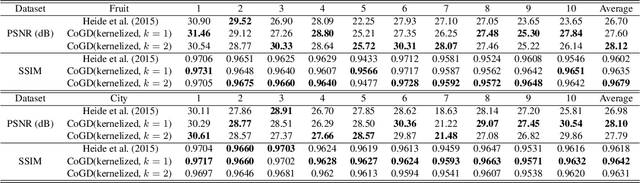
Conventional gradient descent methods compute the gradients for multiple variables through the partial derivative. Treating the coupled variables independently while ignoring the interaction, however, leads to an insufficient optimization for bilinear models. In this paper, we propose a dependable learning based on Cogradient Descent (CoGD) algorithm to address the bilinear optimization problem, providing a systematic way to coordinate the gradients of coupling variables based on a kernelized projection function. CoGD is introduced to solve bilinear problems when one variable is with sparsity constraint, as often occurs in modern learning paradigms. CoGD can also be used to decompose the association of features and weights, which further generalizes our method to better train convolutional neural networks (CNNs) and improve the model capacity. CoGD is applied in representative bilinear problems, including image reconstruction, image inpainting, network pruning and CNN training. Extensive experiments show that CoGD improves the state-of-the-arts by significant margins. Code is available at {https://github.com/bczhangbczhang/CoGD}.
Oriented Object Detection with Transformer
Jun 06, 2021
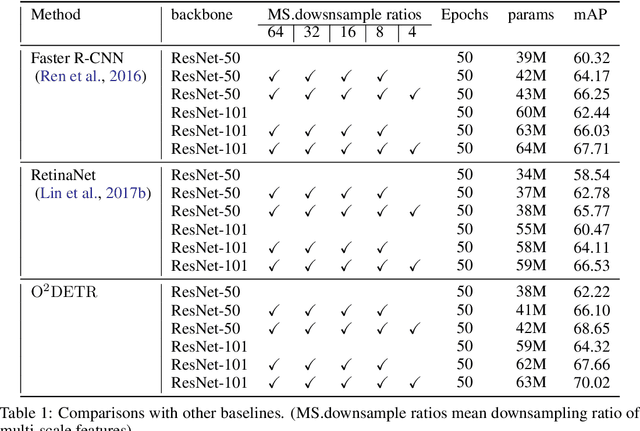
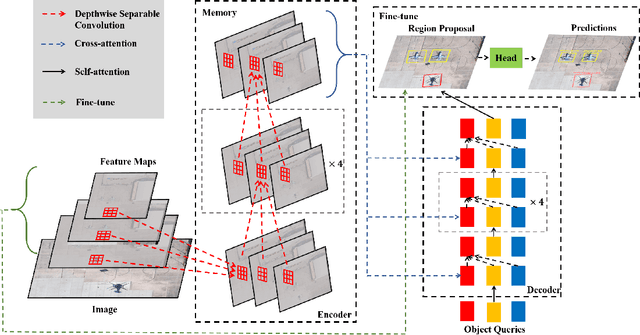
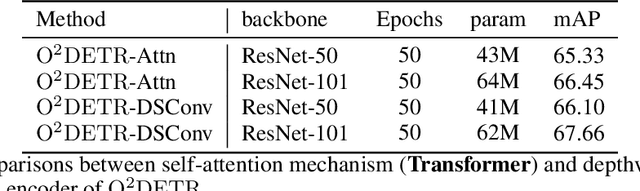
Object detection with Transformers (DETR) has achieved a competitive performance over traditional detectors, such as Faster R-CNN. However, the potential of DETR remains largely unexplored for the more challenging task of arbitrary-oriented object detection problem. We provide the first attempt and implement Oriented Object DEtection with TRansformer ($\bf O^2DETR$) based on an end-to-end network. The contributions of $\rm O^2DETR$ include: 1) we provide a new insight into oriented object detection, by applying Transformer to directly and efficiently localize objects without a tedious process of rotated anchors as in conventional detectors; 2) we design a simple but highly efficient encoder for Transformer by replacing the attention mechanism with depthwise separable convolution, which can significantly reduce the memory and computational cost of using multi-scale features in the original Transformer; 3) our $\rm O^2DETR$ can be another new benchmark in the field of oriented object detection, which achieves up to 3.85 mAP improvement over Faster R-CNN and RetinaNet. We simply fine-tune the head mounted on $\rm O^2DETR$ in a cascaded architecture and achieve a competitive performance over SOTA in the DOTA dataset.
Probabilistic Ranking-Aware Ensembles for Enhanced Object Detections
May 07, 2021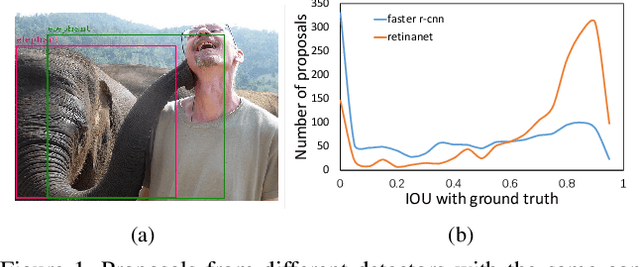

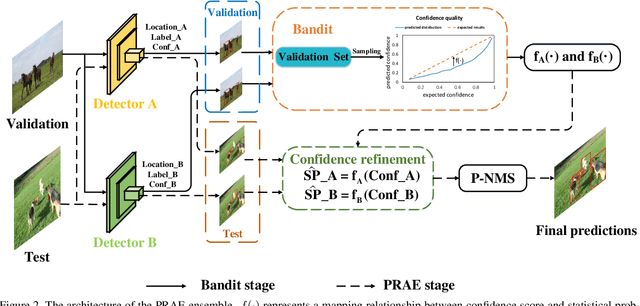

Model ensembles are becoming one of the most effective approaches for improving object detection performance already optimized for a single detector. Conventional methods directly fuse bounding boxes but typically fail to consider proposal qualities when combining detectors. This leads to a new problem of confidence discrepancy for the detector ensembles. The confidence has little effect on single detectors but significantly affects detector ensembles. To address this issue, we propose a novel ensemble called the Probabilistic Ranking Aware Ensemble (PRAE) that refines the confidence of bounding boxes from detectors. By simultaneously considering the category and the location on the same validation set, we obtain a more reliable confidence based on statistical probability. We can then rank the detected bounding boxes for assembly. We also introduce a bandit approach to address the confidence imbalance problem caused by the need to deal with different numbers of boxes at different confidence levels. We use our PRAE-based non-maximum suppression (P-NMS) to replace the conventional NMS method in ensemble learning. Experiments on the PASCAL VOC and COCO2017 datasets demonstrate that our PRAE method consistently outperforms state-of-the-art methods by significant margins.
Scalable Coverage Path Planning of Multi-Robot Teams for Monitoring Non-Convex Areas
Mar 26, 2021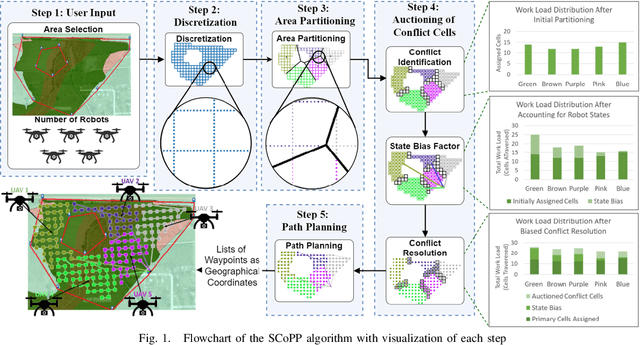
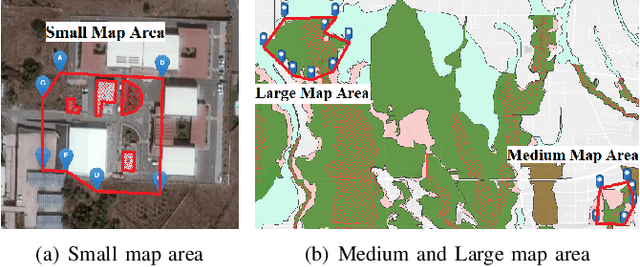
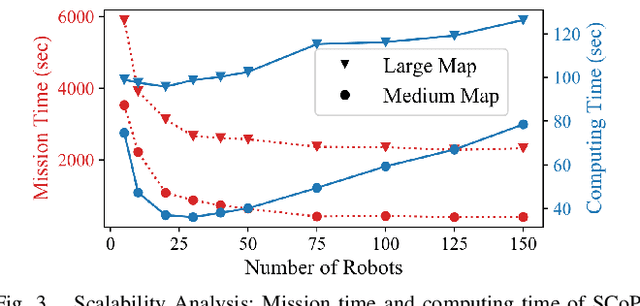
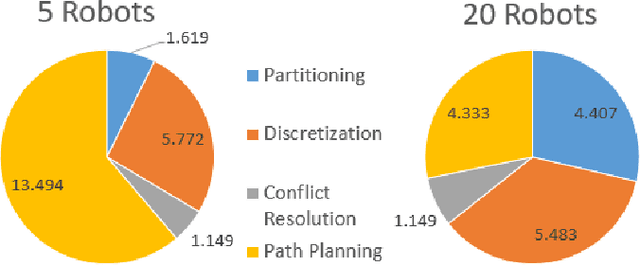
This paper presents a novel multi-robot coverage path planning (CPP) algorithm - aka SCoPP - that provides a time-efficient solution, with workload balanced plans for each robot in a multi-robot system, based on their initial states. This algorithm accounts for discontinuities (e.g., no-fly zones) in a specified area of interest, and provides an optimized ordered list of way-points per robot using a discrete, computationally efficient, nearest neighbor path planning algorithm. This algorithm involves five main stages, which include the transformation of the user's input as a set of vertices in geographical coordinates, discretization, load-balanced partitioning, auctioning of conflict cells in a discretized space, and a path planning procedure. To evaluate the effectiveness of the primary algorithm, a multi-unmanned aerial vehicle (UAV) post-flood assessment application is considered, and the performance of the algorithm is tested on three test maps of varying sizes. Additionally, our method is compared with a state-of-the-art method created by Guasella et al. Further analyses on scalability and computational time of SCoPP are conducted. The results show that SCoPP is superior in terms of mission completion time; its computing time is found to be under 2 mins for a large map covered by a 150-robot team, thereby demonstrating its computationally scalability.
Multi-UAV Mobile Edge Computing and Path Planning Platform based on Reinforcement Learning
Feb 14, 2021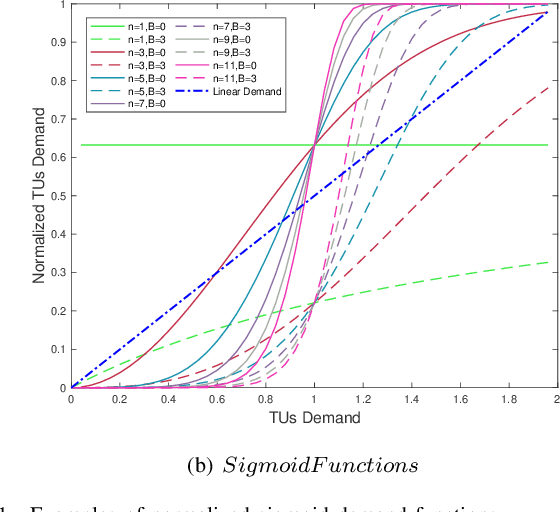
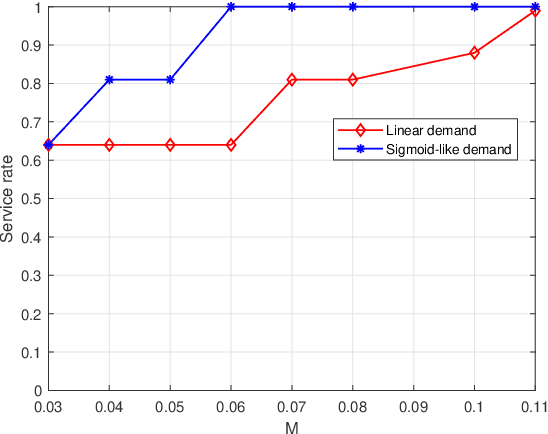
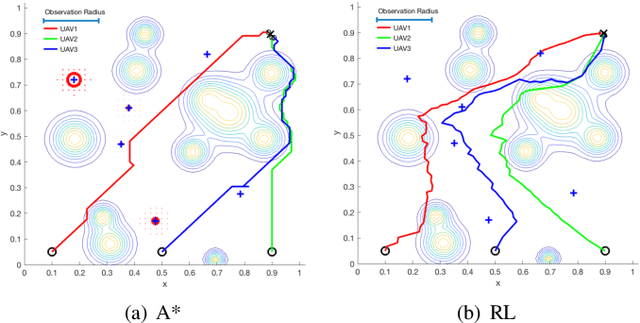
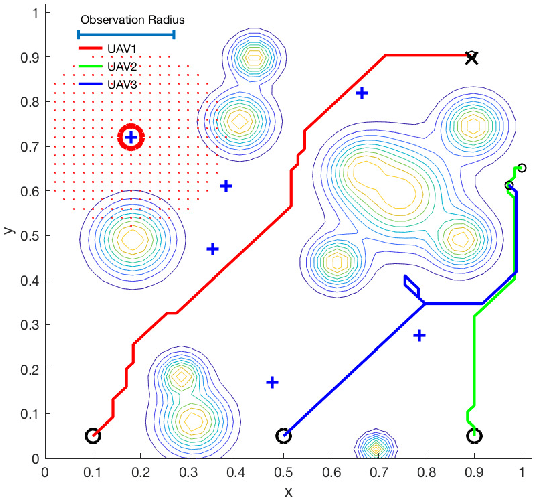
Unmanned Aerial vehicles (UAVs) are widely used as network processors in mobile networks, but more recently, UAVs have been used in Mobile Edge Computing as mobile servers. However, there are significant challenges to use UAVs in complex environments with obstacles and cooperation between UAVs. We introduce a new multi-UAV Mobile Edge Computing platform, which aims to provide better Quality-of-Service and path planning based on reinforcement learning to address these issues. The contributions of our work include: 1) optimizing the quality of service for mobile edge computing and path planning in the same reinforcement learning framework; 2) using a sigmoid-like function to depict the terminal users' demand to ensure a higher quality of service; 3) applying synthetic considerations of the terminal users' demand, risk and geometric distance in reinforcement learning reward matrix to ensure the quality of service, risk avoidance, and the cost-savings. Simulations have shown the effectiveness and feasibility of our platform, which can help advance related researches.
Deformable Gabor Feature Networks for Biomedical Image Classification
Dec 07, 2020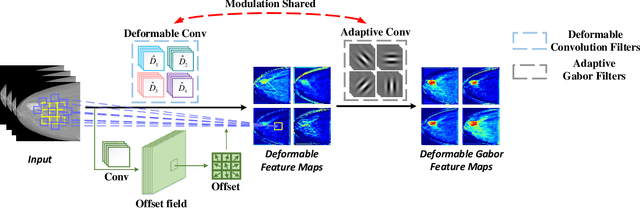
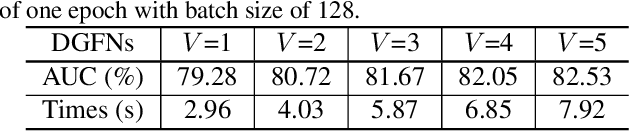
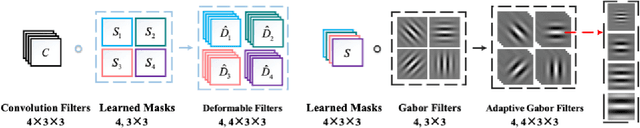
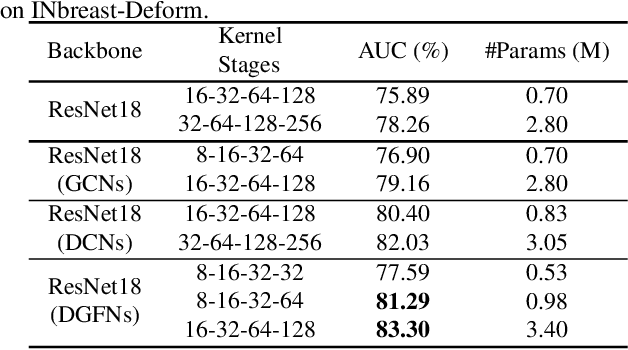
In recent years, deep learning has dominated progress in the field of medical image analysis. We find however, that the ability of current deep learning approaches to represent the complex geometric structures of many medical images is insufficient. One limitation is that deep learning models require a tremendous amount of data, and it is very difficult to obtain a sufficient amount with the necessary detail. A second limitation is that there are underlying features of these medical images that are well established, but the black-box nature of existing convolutional neural networks (CNNs) do not allow us to exploit them. In this paper, we revisit Gabor filters and introduce a deformable Gabor convolution (DGConv) to expand deep networks interpretability and enable complex spatial variations. The features are learned at deformable sampling locations with adaptive Gabor convolutions to improve representativeness and robustness to complex objects. The DGConv replaces standard convolutional layers and is easily trained end-to-end, resulting in deformable Gabor feature network (DGFN) with few additional parameters and minimal additional training cost. We introduce DGFN for addressing deep multi-instance multi-label classification on the INbreast dataset for mammograms and on the ChestX-ray14 dataset for pulmonary x-ray images.
A Review of Recent Advances of Binary Neural Networks for Edge Computing
Nov 24, 2020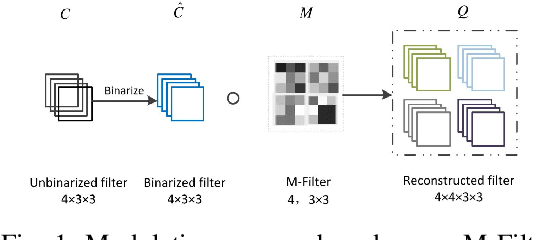
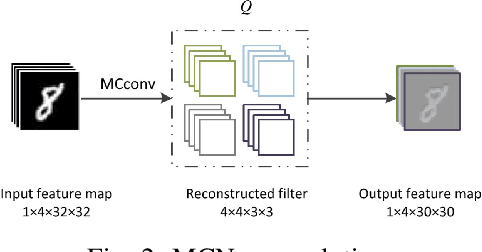
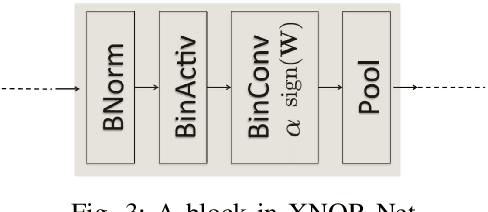
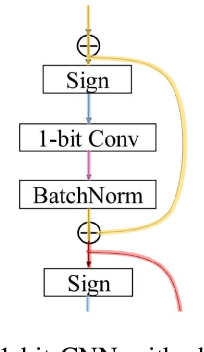
Edge computing is promising to become one of the next hottest topics in artificial intelligence because it benefits various evolving domains such as real-time unmanned aerial systems, industrial applications, and the demand for privacy protection. This paper reviews recent advances on binary neural network (BNN) and 1-bit CNN technologies that are well suitable for front-end, edge-based computing. We introduce and summarize existing work and classify them based on gradient approximation, quantization, architecture, loss functions, optimization method, and binary neural architecture search. We also introduce applications in the areas of computer vision and speech recognition and discuss future applications for edge computing.
Binarized Neural Architecture Search for Efficient Object Recognition
Sep 08, 2020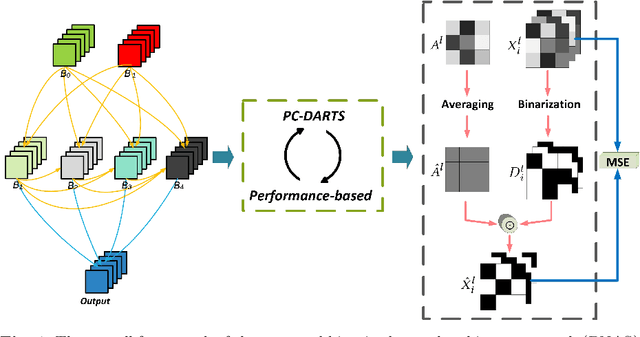

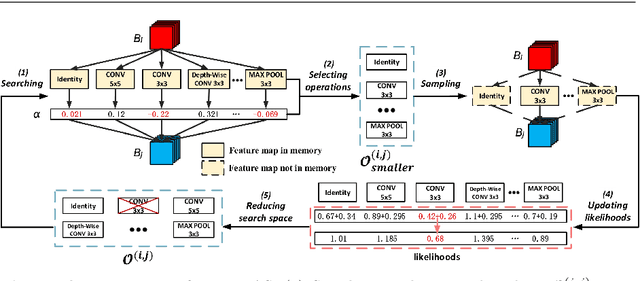
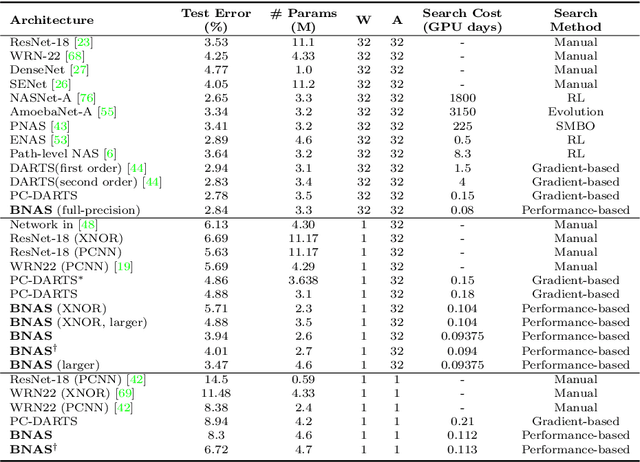
Traditional neural architecture search (NAS) has a significant impact in computer vision by automatically designing network architectures for various tasks. In this paper, binarized neural architecture search (BNAS), with a search space of binarized convolutions, is introduced to produce extremely compressed models to reduce huge computational cost on embedded devices for edge computing. The BNAS calculation is more challenging than NAS due to the learning inefficiency caused by optimization requirements and the huge architecture space, and the performance loss when handling the wild data in various computing applications. To address these issues, we introduce operation space reduction and channel sampling into BNAS to significantly reduce the cost of searching. This is accomplished through a performance-based strategy that is robust to wild data, which is further used to abandon less potential operations. Furthermore, we introduce the Upper Confidence Bound (UCB) to solve 1-bit BNAS. Two optimization methods for binarized neural networks are used to validate the effectiveness of our BNAS. Extensive experiments demonstrate that the proposed BNAS achieves a comparable performance to NAS on both CIFAR and ImageNet databases. An accuracy of $96.53\%$ vs. $97.22\%$ is achieved on the CIFAR-10 dataset, but with a significantly compressed model, and a $40\%$ faster search than the state-of-the-art PC-DARTS. On the wild face recognition task, our binarized models achieve a performance similar to their corresponding full-precision models.
Anti-Bandit Neural Architecture Search for Model Defense
Aug 05, 2020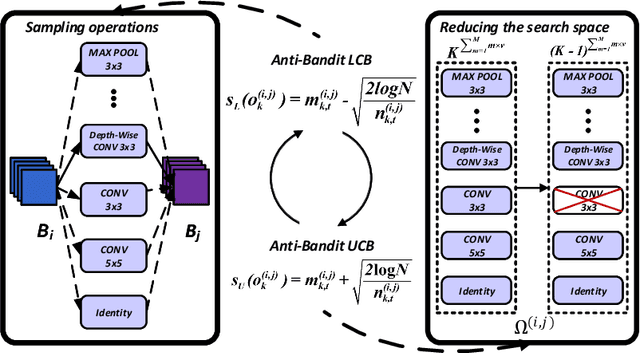

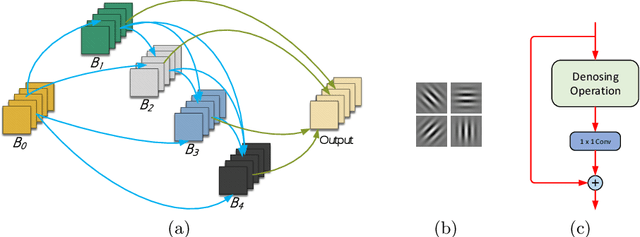
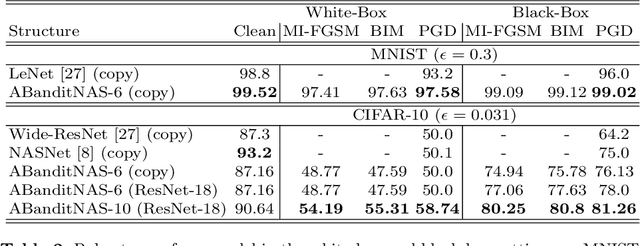
Deep convolutional neural networks (DCNNs) have dominated as the best performers in machine learning, but can be challenged by adversarial attacks. In this paper, we defend against adversarial attacks using neural architecture search (NAS) which is based on a comprehensive search of denoising blocks, weight-free operations, Gabor filters and convolutions. The resulting anti-bandit NAS (ABanditNAS) incorporates a new operation evaluation measure and search process based on the lower and upper confidence bounds (LCB and UCB). Unlike the conventional bandit algorithm using UCB for evaluation only, we use UCB to abandon arms for search efficiency and LCB for a fair competition between arms. Extensive experiments demonstrate that ABanditNAS is faster than other NAS methods, while achieving an $8.73\%$ improvement over prior arts on CIFAR-10 under PGD-$7$.