 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Evaluation for a Large Scale Knowledge Graph Question Answering Service
Jan 28, 2025



Question answering systems for knowledge graph (KGQA), answer factoid questions based on the data in the knowledge graph. KGQA systems are complex because the system has to understand the relations and entities in the knowledge-seeking natural language queries and map them to structured queries against the KG to answer them. In this paper, we introduce Chronos, a comprehensive evaluation framework for KGQA at industry scale. It is designed to evaluate such a multi-component system comprehensively, focusing on (1) end-to-end and component-level metrics, (2) scalable to diverse datasets and (3) a scalable approach to measure the performance of the system prior to release. In this paper, we discuss the unique challenges associated with evaluating KGQA systems at industry scale, review the design of Chronos, and how it addresses these challenges. We will demonstrate how it provides a base for data-driven decisions and discuss the challenges of using it to measure and improve a real-world KGQA system.
Eliciting In-context Retrieval and Reasoning for Long-context Large Language Models
Jan 14, 2025



Recent advancements in long-context language models (LCLMs) promise to transform Retrieval-Augmented Generation (RAG) by simplifying pipelines. With their expanded context windows, LCLMs can process entire knowledge bases and perform retrieval and reasoning directly -- a capability we define as In-Context Retrieval and Reasoning (ICR^2). However, existing benchmarks like LOFT often overestimate LCLM performance by providing overly simplified contexts. To address this, we introduce ICR^2, a benchmark that evaluates LCLMs in more realistic scenarios by including confounding passages retrieved with strong retrievers. We then propose three methods to enhance LCLM performance: (1) retrieve-then-generate fine-tuning, (2) retrieval-attention-probing, which uses attention heads to filter and de-noise long contexts during decoding, and (3) joint retrieval head training alongside the generation head. Our evaluation of five well-known LCLMs on LOFT and ICR^2 demonstrates significant gains with our best approach applied to Mistral-7B: +17 and +15 points by Exact Match on LOFT, and +13 and +2 points on ICR^2, compared to vanilla RAG and supervised fine-tuning, respectively. It even outperforms GPT-4-Turbo on most tasks despite being a much smaller model.
Think While You Write: Hypothesis Verification Promotes Faithful Knowledge-to-Text Generation
Nov 16, 2023



Neural knowledge-to-text generation models often struggle to faithfully generate descriptions for the input facts: they may produce hallucinations that contradict the given facts, or describe facts not present in the input. To reduce hallucinations, we propose a novel decoding method, TWEAK (Think While Effectively Articulating Knowledge). TWEAK treats the generated sequences at each decoding step and its future sequences as hypotheses, and ranks each generation candidate based on how well their corresponding hypotheses support the input facts using a Hypothesis Verification Model (HVM). We first demonstrate the effectiveness of TWEAK by using a Natural Language Inference (NLI) model as the HVM and report improved faithfulness with minimal impact on the quality. We then replace the NLI model with our task-specific HVM trained with a first-of-a-kind dataset, FATE (Fact-Aligned Textual Entailment), which pairs input facts with their faithful and hallucinated descriptions with the hallucinated spans marked. The new HVM improves the faithfulness and the quality further and runs faster. Overall the best TWEAK variants improve on average 2.22/7.17 points on faithfulness measured by FactKB over WebNLG and TekGen/GenWiki, respectively, with only 0.14/0.32 points degradation on quality measured by BERTScore over the same datasets. Since TWEAK is a decoding-only approach, it can be integrated with any neural generative model without retraining.
D-REX: Dialogue Relation Extraction with Explanations
Sep 10, 2021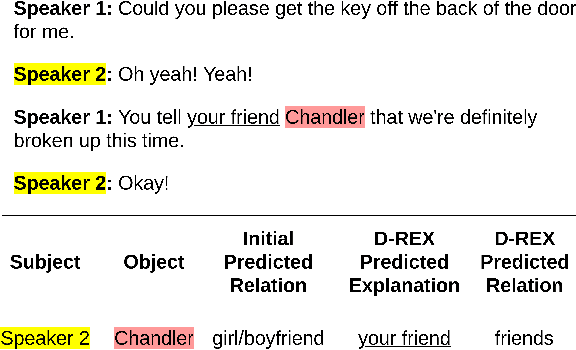

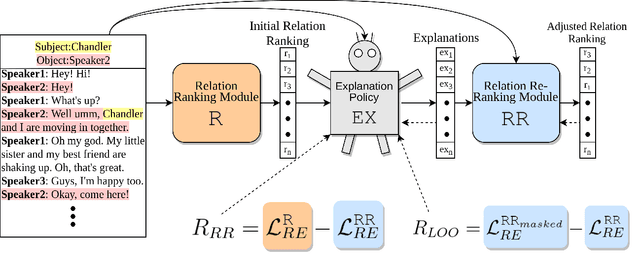
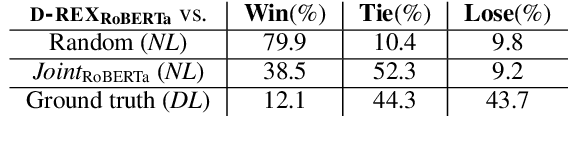
Existing research studies on cross-sentence relation extraction in long-form multi-party conversations aim to improve relation extraction without considering the explainability of such methods. This work addresses that gap by focusing on extracting explanations that indicate that a relation exists while using only partially labeled data. We propose our model-agnostic framework, D-REX, a policy-guided semi-supervised algorithm that explains and ranks relations. We frame relation extraction as a re-ranking task and include relation- and entity-specific explanations as an intermediate step of the inference process. We find that about 90% of the time, human annotators prefer D-REX's explanations over a strong BERT-based joint relation extraction and explanation model. Finally, our evaluations on a dialogue relation extraction dataset show that our method is simple yet effective and achieves a state-of-the-art F1 score on relation extraction, improving upon existing methods by 13.5%.
Estimating Aggregate Properties In Relational Networks With Unobserved Data
Jan 27, 2020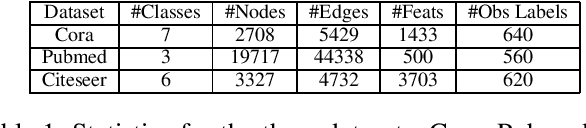
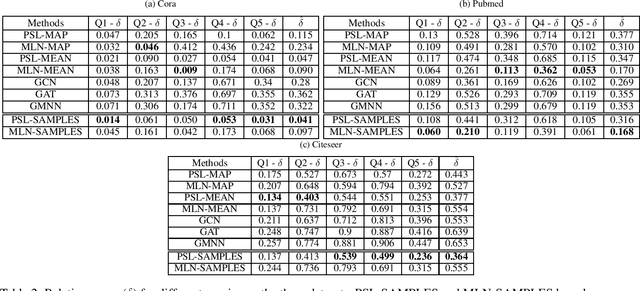
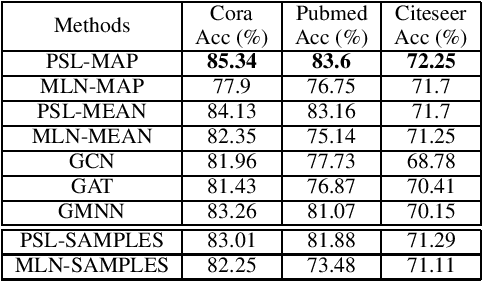
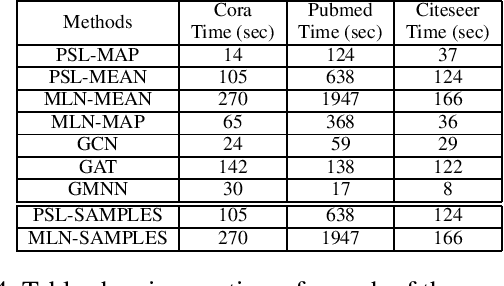
Aggregate network properties such as cluster cohesion and the number of bridge nodes can be used to glean insights about a network's community structure, spread of influence and the resilience of the network to faults. Efficiently computing network properties when the network is fully observed has received significant attention (Wasserman and Faust 1994; Cook and Holder 2006), however the problem of computing aggregate network properties when there is missing data attributes has received little attention. Computing these properties for networks with missing attributes involves performing inference over the network. Statistical relational learning (SRL) and graph neural networks (GNNs) are two classes of machine learning approaches well suited for inferring missing attributes in a graph. In this paper, we study the effectiveness of these approaches in estimating aggregate properties on networks with missing attributes. We compare two SRL approaches and three GNNs. For these approaches we estimate these properties using point estimates such as MAP and mean. For SRL-based approaches that can infer a joint distribution over the missing attributes, we also estimate these properties as an expectation over the distribution. To compute the expectation tractably for probabilistic soft logic, one of the SRL approaches that we study, we introduce a novel sampling framework. In the experimental evaluation, using three benchmark datasets, we show that SRL-based approaches tend to outperform GNN-based approaches both in computing aggregate properties and predictive accuracy. Specifically, we show that estimating the aggregate properties as an expectation over the joint distribution outperforms point estimates.
Scalable Structure Learning for Probabilistic Soft Logic
Jul 03, 2018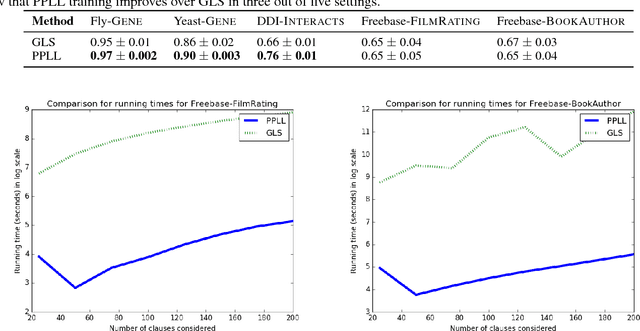
Statistical relational frameworks such as Markov logic networks and probabilistic soft logic (PSL) encode model structure with weighted first-order logical clauses. Learning these clauses from data is referred to as structure learning. Structure learning alleviates the manual cost of specifying models. However, this benefit comes with high computational costs; structure learning typically requires an expensive search over the space of clauses which involves repeated optimization of clause weights. In this paper, we propose the first two approaches to structure learning for PSL. We introduce a greedy search-based algorithm and a novel optimization method that trade-off scalability and approximations to the structure learning problem in varying ways. The highly scalable optimization method combines data-driven generation of clauses with a piecewise pseudolikelihood (PPLL) objective that learns model structure by optimizing clause weights only once. We compare both methods across five real-world tasks, showing that PPLL achieves an order of magnitude runtime speedup and AUC gains up to 15% over greedy search.