 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Approaches to Grasp Synthesis: A Review
Jul 06, 2022


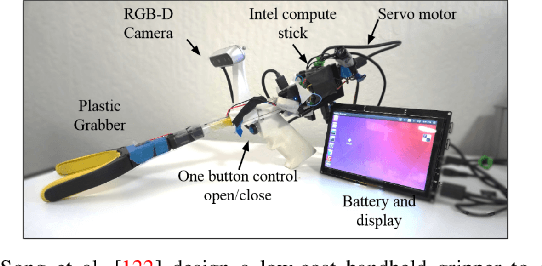
Grasping is the process of picking an object by applying forces and torques at a set of contacts. Recent advances in deep-learning methods have allowed rapid progress in robotic object grasping. We systematically surveyed the publications over the last decade, with a particular interest in grasping an object using all 6 degrees of freedom of the end-effector pose. Our review found four common methodologies for robotic grasping: sampling-based approaches, direct regression, reinforcement learning, and exemplar approaches. Furthermore, we found two 'supporting methods' around grasping that use deep-learning to support the grasping process, shape approximation, and affordances. We have distilled the publications found in this systematic review (85 papers) into ten key takeaways we consider crucial for future robotic grasping and manipulation research. An online version of the survey is available at https://rhys-newbury.github.io/projects/6dof/
Active Nearest Neighbor Regression Through Delaunay Refinement
Jun 16, 2022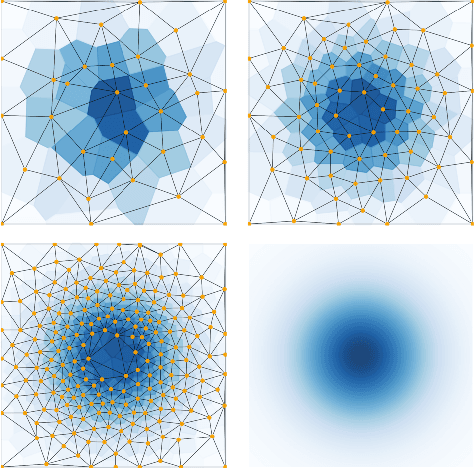
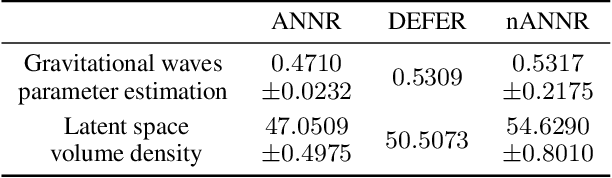
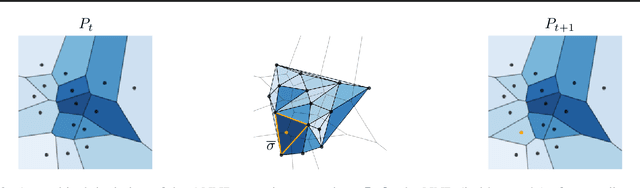

We introduce an algorithm for active function approximation based on nearest neighbor regression. Our Active Nearest Neighbor Regressor (ANNR) relies on the Voronoi-Delaunay framework from computational geometry to subdivide the space into cells with constant estimated function value and select novel query points in a way that takes the geometry of the function graph into account. We consider the recent state-of-the-art active function approximator called DEFER, which is based on incremental rectangular partitioning of the space, as the main baseline. The ANNR addresses a number of limitations that arise from the space subdivision strategy used in DEFER. We provide a computationally efficient implementation of our method, as well as theoretical halting guarantees. Empirical results show that ANNR outperforms the baseline for both closed-form functions and real-world examples, such as gravitational wave parameter inference and exploration of the latent space of a generative model.
Training and Evaluation of Deep Policies using Reinforcement Learning and Generative Models
Apr 18, 2022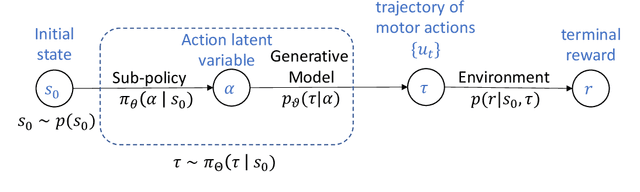
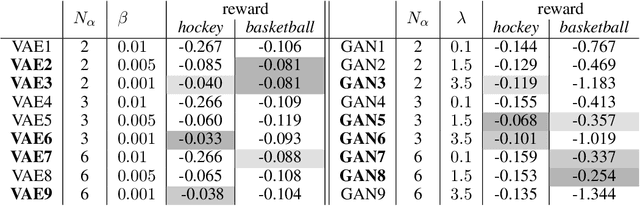
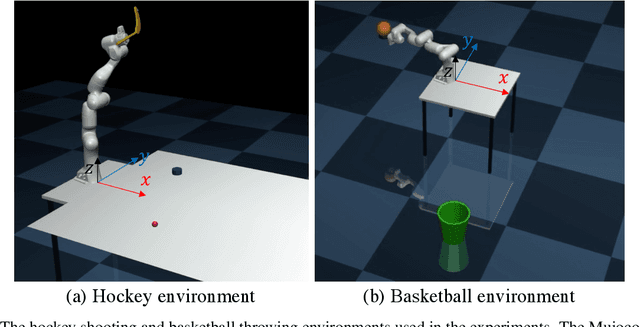
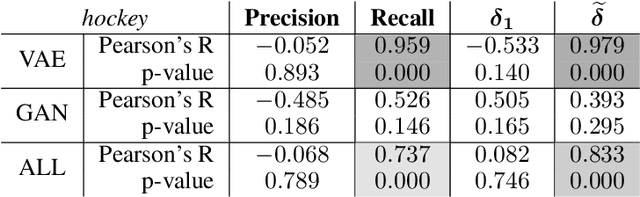
We present a data-efficient framework for solving sequential decision-making problems which exploits the combination of reinforcement learning (RL) and latent variable generative models. The framework, called GenRL, trains deep policies by introducing an action latent variable such that the feed-forward policy search can be divided into two parts: (i) training a sub-policy that outputs a distribution over the action latent variable given a state of the system, and (ii) unsupervised training of a generative model that outputs a sequence of motor actions conditioned on the latent action variable. GenRL enables safe exploration and alleviates the data-inefficiency problem as it exploits prior knowledge about valid sequences of motor actions. Moreover, we provide a set of measures for evaluation of generative models such that we are able to predict the performance of the RL policy training prior to the actual training on a physical robot. We experimentally determine the characteristics of generative models that have most influence on the performance of the final policy training on two robotics tasks: shooting a hockey puck and throwing a basketball. Furthermore, we empirically demonstrate that GenRL is the only method which can safely and efficiently solve the robotics tasks compared to two state-of-the-art RL methods.
Augment-Connect-Explore: a Paradigm for Visual Action Planning with Data Scarcity
Mar 24, 2022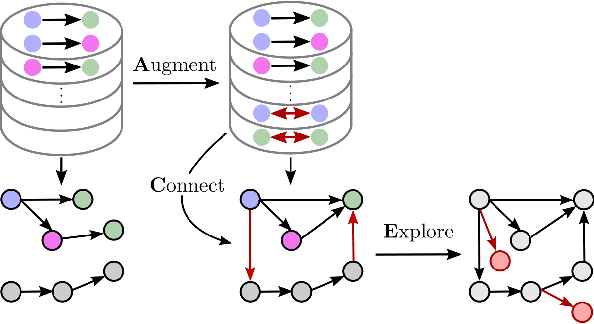
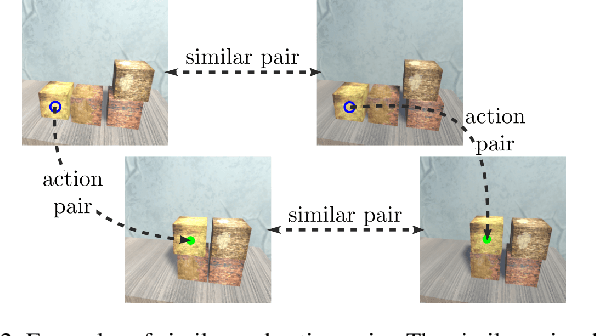
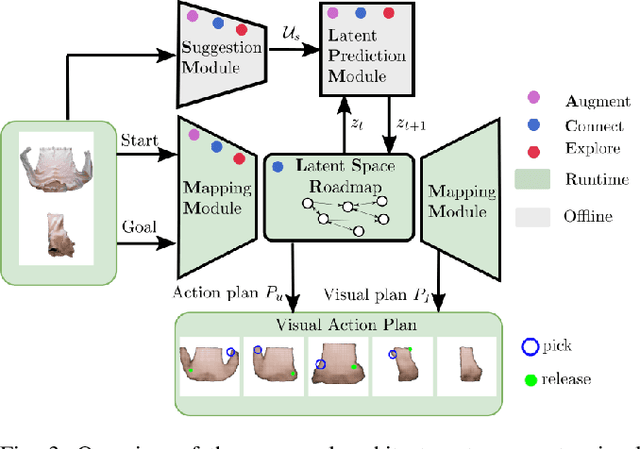
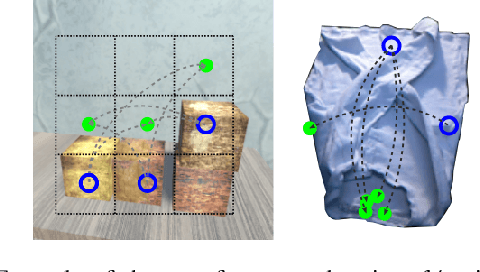
Visual action planning particularly excels in applications where the state of the system cannot be computed explicitly, such as manipulation of deformable objects, as it enables planning directly from raw images. Even though the field has been significantly accelerated by deep learning techniques, a crucial requirement for their success is the availability of a large amount of data. In this work, we propose the Augment-Connect-Explore (ACE) paradigm to enable visual action planning in cases of data scarcity. We build upon the Latent Space Roadmap (LSR) framework which performs planning with a graph built in a low dimensional latent space. In particular, ACE is used to i) Augment the available training dataset by autonomously creating new pairs of datapoints, ii) create new unobserved Connections among representations of states in the latent graph, and iii) Explore new regions of the latent space in a targeted manner. We validate the proposed approach on both simulated box stacking and real-world folding task showing the applicability for rigid and deformable object manipulation tasks, respectively.
Delaunay Component Analysis for Evaluation of Data Representations
Feb 14, 2022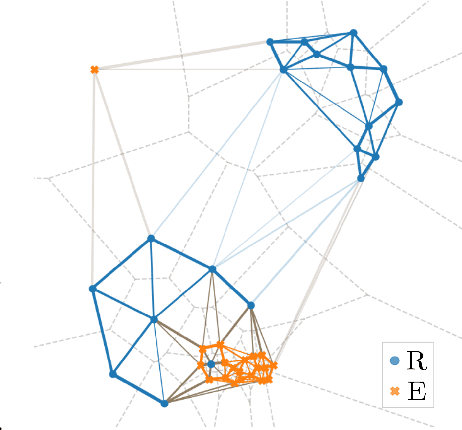

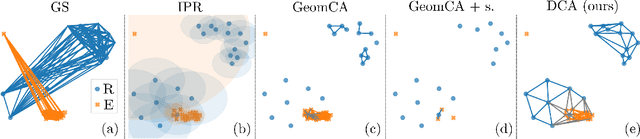

Advanced representation learning techniques require reliable and general evaluation methods. Recently, several algorithms based on the common idea of geometric and topological analysis of a manifold approximated from the learned data representations have been proposed. In this work, we introduce Delaunay Component Analysis (DCA) - an evaluation algorithm which approximates the data manifold using a more suitable neighbourhood graph called Delaunay graph. This provides a reliable manifold estimation even for challenging geometric arrangements of representations such as clusters with varying shape and density as well as outliers, which is where existing methods often fail. Furthermore, we exploit the nature of Delaunay graphs and introduce a framework for assessing the quality of individual novel data representations. We experimentally validate the proposed DCA method on representations obtained from neural networks trained with contrastive objective, supervised and generative models, and demonstrate various use cases of our extended single point evaluation framework.
GraphDCA -- a Framework for Node Distribution Comparison in Real and Synthetic Graphs
Feb 09, 2022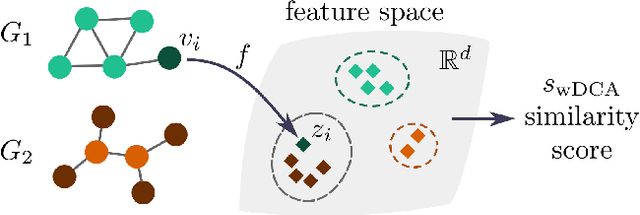
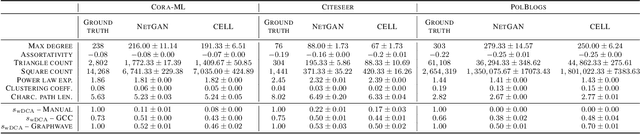
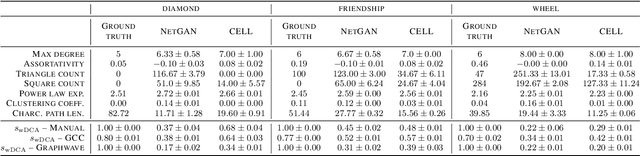
We argue that when comparing two graphs, the distribution of node structural features is more informative than global graph statistics which are often used in practice, especially to evaluate graph generative models. Thus, we present GraphDCA - a framework for evaluating similarity between graphs based on the alignment of their respective node representation sets. The sets are compared using a recently proposed method for comparing representation spaces, called Delaunay Component Analysis (DCA), which we extend to graph data. To evaluate our framework, we generate a benchmark dataset of graphs exhibiting different structural patterns and show, using three node structure feature extractors, that GraphDCA recognizes graphs with both similar and dissimilar local structure. We then apply our framework to evaluate three publicly available real-world graph datasets and demonstrate, using gradual edge perturbations, that GraphDCA satisfyingly captures gradually decreasing similarity, unlike global statistics. Finally, we use GraphDCA to evaluate two state-of-the-art graph generative models, NetGAN and CELL, and conclude that further improvements are needed for these models to adequately reproduce local structural features.
GMC -- Geometric Multimodal Contrastive Representation Learning
Feb 08, 2022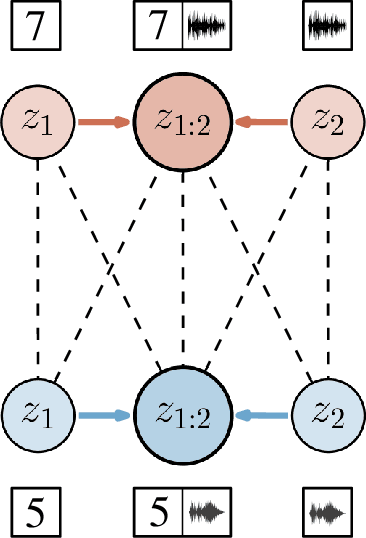



Learning representations of multimodal data that are both informative and robust to missing modalities at test time remains a challenging problem due to the inherent heterogeneity of data obtained from different channels. To address it, we present a novel Geometric Multimodal Contrastive (GMC) representation learning method comprised of two main components: i) a two-level architecture consisting of modality-specific base encoder, allowing to process an arbitrary number of modalities to an intermediate representation of fixed dimensionality, and a shared projection head, mapping the intermediate representations to a latent representation space; ii) a multimodal contrastive loss function that encourages the geometric alignment of the learned representations. We experimentally demonstrate that GMC representations are semantically rich and achieve state-of-the-art performance with missing modality information on three different learning problems including prediction and reinforcement learning tasks.
Comparing Reconstruction- and Contrastive-based Models for Visual Task Planning
Sep 14, 2021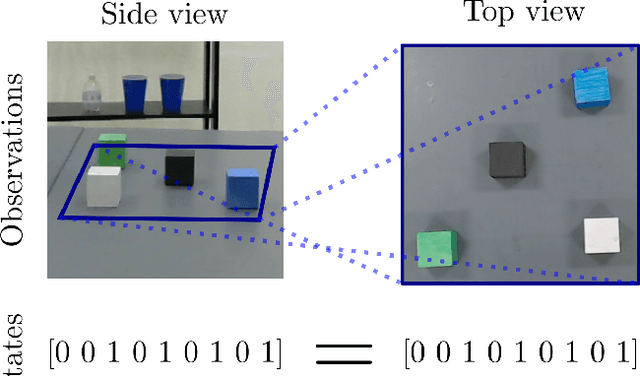

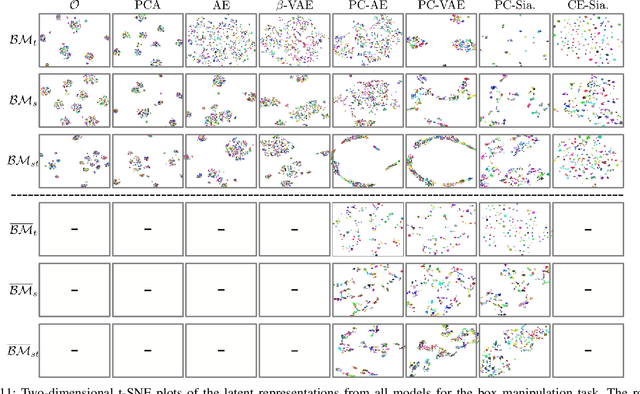
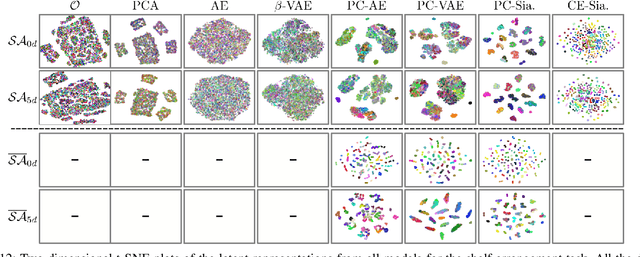
Learning state representations enables robotic planning directly from raw observations such as images. Most methods learn state representations by utilizing losses based on the reconstruction of the raw observations from a lower-dimensional latent space. The similarity between observations in the space of images is often assumed and used as a proxy for estimating similarity between the underlying states of the system. However, observations commonly contain task-irrelevant factors of variation which are nonetheless important for reconstruction, such as varying lighting and different camera viewpoints. In this work, we define relevant evaluation metrics and perform a thorough study of different loss functions for state representation learning. We show that models exploiting task priors, such as Siamese networks with a simple contrastive loss, outperform reconstruction-based representations in visual task planning.
Batch Curation for Unsupervised Contrastive Representation Learning
Aug 19, 2021
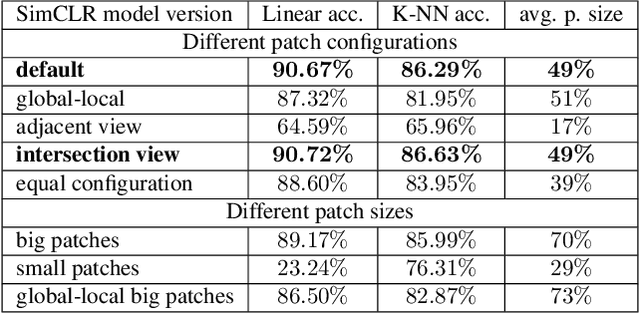
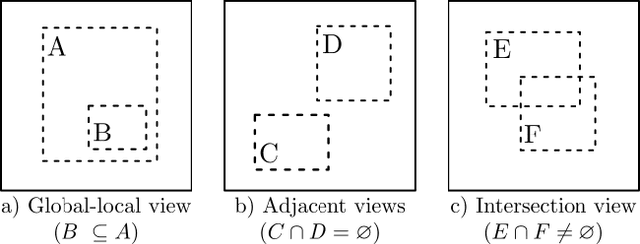

The state-of-the-art unsupervised contrastive visual representation learning methods that have emerged recently (SimCLR, MoCo, SwAV) all make use of data augmentations in order to construct a pretext task of instant discrimination consisting of similar and dissimilar pairs of images. Similar pairs are constructed by randomly extracting patches from the same image and applying several other transformations such as color jittering or blurring, while transformed patches from different image instances in a given batch are regarded as dissimilar pairs. We argue that this approach can result similar pairs that are \textit{semantically} dissimilar. In this work, we address this problem by introducing a \textit{batch curation} scheme that selects batches during the training process that are more inline with the underlying contrastive objective. We provide insights into what constitutes beneficial similar and dissimilar pairs as well as validate \textit{batch curation} on CIFAR10 by integrating it in the SimCLR model.
GeomCA: Geometric Evaluation of Data Representations
May 26, 2021
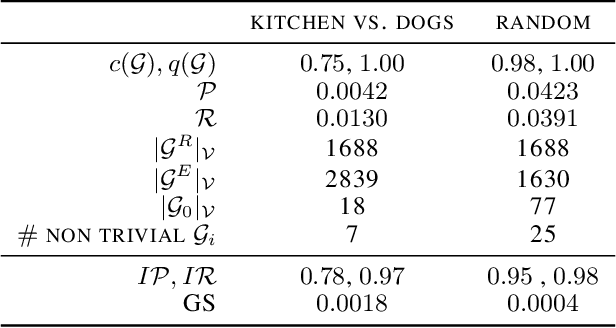
Evaluating the quality of learned representations without relying on a downstream task remains one of the challenges in representation learning. In this work, we present Geometric Component Analysis (GeomCA) algorithm that evaluates representation spaces based on their geometric and topological properties. GeomCA can be applied to representations of any dimension, independently of the model that generated them. We demonstrate its applicability by analyzing representations obtained from a variety of scenarios, such as contrastive learning models, generative models and supervised learning models.