 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgress Constraints for Reinforcement Learning in Behavior Trees
Feb 06, 2026Behavior Trees (BTs) provide a structured and reactive framework for decision-making, commonly used to switch between sub-controllers based on environmental conditions. Reinforcement Learning (RL), on the other hand, can learn near-optimal controllers but sometimes struggles with sparse rewards, safe exploration, and long-horizon credit assignment. Combining BTs with RL has the potential for mutual benefit: a BT design encodes structured domain knowledge that can simplify RL training, while RL enables automatic learning of the controllers within BTs. However, naive integration of BTs and RL can lead to some controllers counteracting other controllers, possibly undoing previously achieved subgoals, thereby degrading the overall performance. To address this, we propose progress constraints, a novel mechanism where feasibility estimators constrain the allowed action set based on theoretical BT convergence results. Empirical evaluations in a 2D proof-of-concept and a high-fidelity warehouse environment demonstrate improved performance, sample efficiency, and constraint satisfaction, compared to prior methods of BT-RL integration.
Can Context Bridge the Reality Gap? Sim-to-Real Transfer of Context-Aware Policies
Nov 06, 2025Sim-to-real transfer remains a major challenge in reinforcement learning (RL) for robotics, as policies trained in simulation often fail to generalize to the real world due to discrepancies in environment dynamics. Domain Randomization (DR) mitigates this issue by exposing the policy to a wide range of randomized dynamics during training, yet leading to a reduction in performance. While standard approaches typically train policies agnostic to these variations, we investigate whether sim-to-real transfer can be improved by conditioning the policy on an estimate of the dynamics parameters -- referred to as context. To this end, we integrate a context estimation module into a DR-based RL framework and systematically compare SOTA supervision strategies. We evaluate the resulting context-aware policies in both a canonical control benchmark and a real-world pushing task using a Franka Emika Panda robot. Results show that context-aware policies outperform the context-agnostic baseline across all settings, although the best supervision strategy depends on the task.
Inverse Optimization Latent Variable Models for Learning Costs Applied to Route Problems
Sep 19, 2025Learning representations for solutions of constrained optimization problems (COPs) with unknown cost functions is challenging, as models like (Variational) Autoencoders struggle to enforce constraints when decoding structured outputs. We propose an Inverse Optimization Latent Variable Model (IO-LVM) that learns a latent space of COP cost functions from observed solutions and reconstructs feasible outputs by solving a COP with a solver in the loop. Our approach leverages estimated gradients of a Fenchel-Young loss through a non-differentiable deterministic solver to shape the latent space. Unlike standard Inverse Optimization or Inverse Reinforcement Learning methods, which typically recover a single or context-specific cost function, IO-LVM captures a distribution over cost functions, enabling the identification of diverse solution behaviors arising from different agents or conditions not available during the training process. We validate our method on real-world datasets of ship and taxi routes, as well as paths in synthetic graphs, demonstrating its ability to reconstruct paths and cycles, predict their distributions, and yield interpretable latent representations.
ZipMPC: Compressed Context-Dependent MPC Cost via Imitation Learning
Jul 17, 2025The computational burden of model predictive control (MPC) limits its application on real-time systems, such as robots, and often requires the use of short prediction horizons. This not only affects the control performance, but also increases the difficulty of designing MPC cost functions that reflect the desired long-term objective. This paper proposes ZipMPC, a method that imitates a long-horizon MPC behaviour by learning a compressed and context-dependent cost function for a short-horizon MPC. It improves performance over alternative methods, such as approximate explicit MPC and automatic cost parameter tuning, in particular in terms of i) optimizing the long term objective; ii) maintaining computational costs comparable to a short-horizon MPC; iii) ensuring constraint satisfaction; and iv) generalizing control behaviour to environments not observed during training. For this purpose, ZipMPC leverages the concept of differentiable MPC with neural networks to propagate gradients of the imitation loss through the MPC optimization. We validate our proposed method in simulation and real-world experiments on autonomous racing. ZipMPC consistently completes laps faster than selected baselines, achieving lap times close to the long-horizon MPC baseline. In challenging scenarios where the short-horizon MPC baseline fails to complete a lap, ZipMPC is able to do so. In particular, these performance gains are also observed on tracks unseen during training.
On the Fly Adaptation of Behavior Tree-Based Policies through Reinforcement Learning
Mar 08, 2025With the rising demand for flexible manufacturing, robots are increasingly expected to operate in dynamic environments where local -- such as slight offsets or size differences in workpieces -- are common. We propose to address the problem of adapting robot behaviors to these task variations with a sample-efficient hierarchical reinforcement learning approach adapting Behavior Tree (BT)-based policies. We maintain the core BT properties as an interpretable, modular framework for structuring reactive behaviors, but extend their use beyond static tasks by inherently accommodating local task variations. To show the efficiency and effectiveness of our approach, we conduct experiments both in simulation and on a Franka Emika Panda 7-DoF, with the manipulator adapting to different obstacle avoidance and pivoting tasks.
THÖR-MAGNI Act: Actions for Human Motion Modeling in Robot-Shared Industrial Spaces
Dec 18, 2024



Accurate human activity and trajectory prediction are crucial for ensuring safe and reliable human-robot interactions in dynamic environments, such as industrial settings, with mobile robots. Datasets with fine-grained action labels for moving people in industrial environments with mobile robots are scarce, as most existing datasets focus on social navigation in public spaces. This paper introduces the TH\"OR-MAGNI Act dataset, a substantial extension of the TH\"OR-MAGNI dataset, which captures participant movements alongside robots in diverse semantic and spatial contexts. TH\"OR-MAGNI Act provides 8.3 hours of manually labeled participant actions derived from egocentric videos recorded via eye-tracking glasses. These actions, aligned with the provided TH\"OR-MAGNI motion cues, follow a long-tailed distribution with diversified acceleration, velocity, and navigation distance profiles. We demonstrate the utility of TH\"OR-MAGNI Act for two tasks: action-conditioned trajectory prediction and joint action and trajectory prediction. We propose two efficient transformer-based models that outperform the baselines to address these tasks. These results underscore the potential of TH\"OR-MAGNI Act to develop predictive models for enhanced human-robot interaction in complex environments.
Learning Solutions of Stochastic Optimization Problems with Bayesian Neural Networks
Jun 05, 2024



Mathematical solvers use parametrized Optimization Problems (OPs) as inputs to yield optimal decisions. In many real-world settings, some of these parameters are unknown or uncertain. Recent research focuses on predicting the value of these unknown parameters using available contextual features, aiming to decrease decision regret by adopting end-to-end learning approaches. However, these approaches disregard prediction uncertainty and therefore make the mathematical solver susceptible to provide erroneous decisions in case of low-confidence predictions. We propose a novel framework that models prediction uncertainty with Bayesian Neural Networks (BNNs) and propagates this uncertainty into the mathematical solver with a Stochastic Programming technique. The differentiable nature of BNNs and differentiable mathematical solvers allow for two different learning approaches: In the Decoupled learning approach, we update the BNN weights to increase the quality of the predictions' distribution of the OP parameters, while in the Combined learning approach, we update the weights aiming to directly minimize the expected OP's cost function in a stochastic end-to-end fashion. We do an extensive evaluation using synthetic data with various noise properties and a real dataset, showing that decisions regret are generally lower (better) with both proposed methods.
DataSP: A Differential All-to-All Shortest Path Algorithm for Learning Costs and Predicting Paths with Context
May 08, 2024



Learning latent costs of transitions on graphs from trajectories demonstrations under various contextual features is challenging but useful for path planning. Yet, existing methods either oversimplify cost assumptions or scale poorly with the number of observed trajectories. This paper introduces DataSP, a differentiable all-to-all shortest path algorithm to facilitate learning latent costs from trajectories. It allows to learn from a large number of trajectories in each learning step without additional computation. Complex latent cost functions from contextual features can be represented in the algorithm through a neural network approximation. We further propose a method to sample paths from DataSP in order to reconstruct/mimic observed paths' distributions. We prove that the inferred distribution follows the maximum entropy principle. We show that DataSP outperforms state-of-the-art differentiable combinatorial solver and classical machine learning approaches in predicting paths on graphs.
Learning Extrinsic Dexterity with Parameterized Manipulation Primitives
Nov 02, 2023
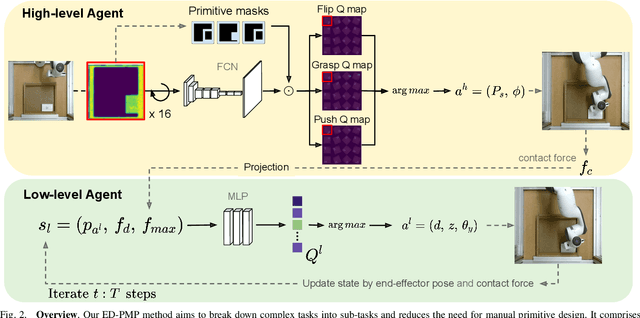
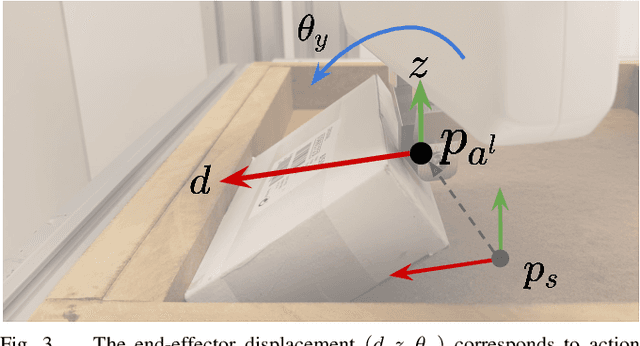
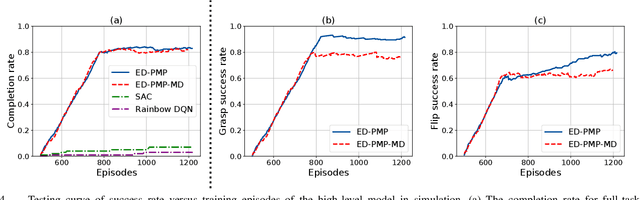
Many practically relevant robot grasping problems feature a target object for which all grasps are occluded, e.g., by the environment. Single-shot grasp planning invariably fails in such scenarios. Instead, it is necessary to first manipulate the object into a configuration that affords a grasp. We solve this problem by learning a sequence of actions that utilize the environment to change the object's pose. Concretely, we employ hierarchical reinforcement learning to combine a sequence of learned parameterized manipulation primitives. By learning the low-level manipulation policies, our approach can control the object's state through exploiting interactions between the object, the gripper, and the environment. Designing such a complex behavior analytically would be infeasible under uncontrolled conditions, as an analytic approach requires accurate physical modeling of the interaction and contact dynamics. In contrast, we learn a hierarchical policy model that operates directly on depth perception data, without the need for object detection, pose estimation, or manual design of controllers. We evaluate our approach on picking box-shaped objects of various weight, shape, and friction properties from a constrained table-top workspace. Our method transfers to a real robot and is able to successfully complete the object picking task in 98\% of experimental trials.
Heterogeneous Full-body Control of a Mobile Manipulator with Behavior Trees
Oct 16, 2022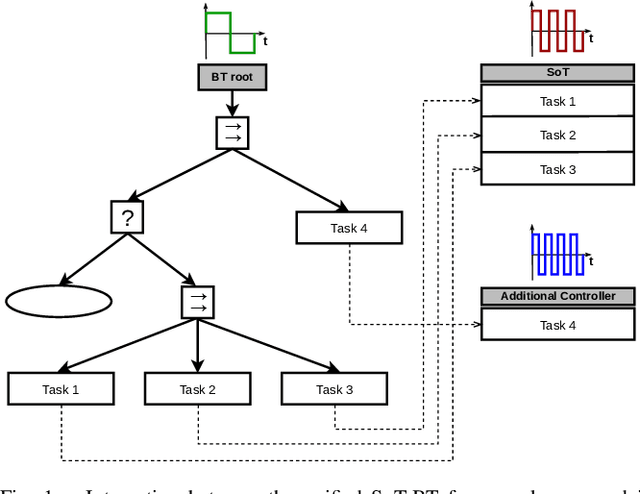
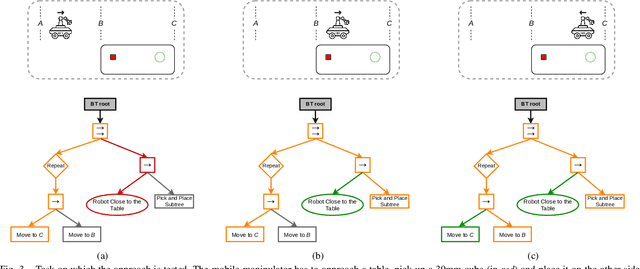
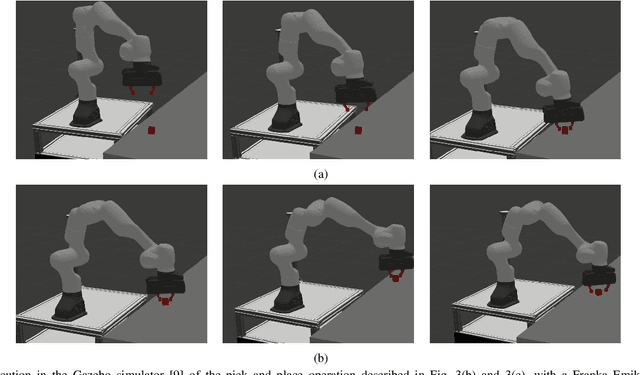
Integrating the heterogeneous controllers of a complex mechanical system, such as a mobile manipulator, within the same structure and in a modular way is still challenging. In this work we extend our framework based on Behavior Trees for the control of a redundant mechanical system to the problem of commanding more complex systems that involve multiple low-level controllers. This allows the integrated systems to achieve non-trivial goals that require coordination among the sub-systems.