 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlow-WaveGAN: Learning Speech Representations from GAN-based Variational Auto-Encoder For High Fidelity Flow-based Speech Synthesis
Jun 22, 2021
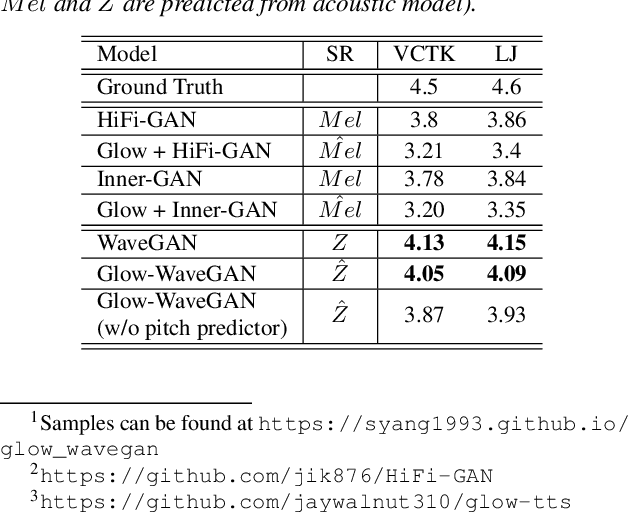
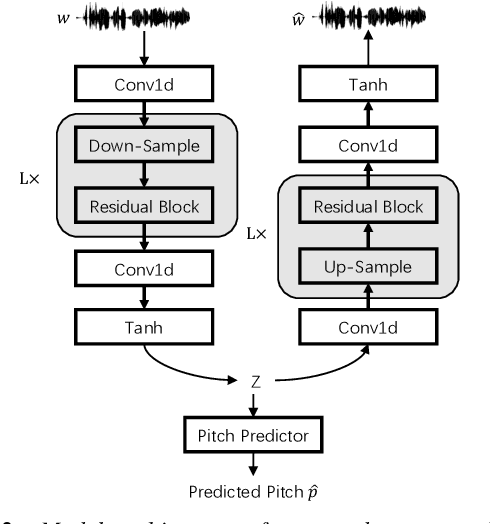
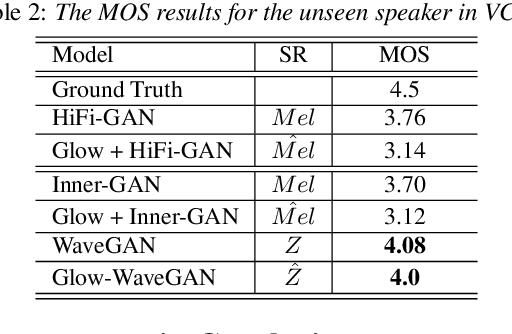
Current two-stage TTS framework typically integrates an acoustic model with a vocoder -- the acoustic model predicts a low resolution intermediate representation such as Mel-spectrum while the vocoder generates waveform from the intermediate representation. Although the intermediate representation is served as a bridge, there still exists critical mismatch between the acoustic model and the vocoder as they are commonly separately learned and work on different distributions of representation, leading to inevitable artifacts in the synthesized speech. In this work, different from using pre-designed intermediate representation in most previous studies, we propose to use VAE combining with GAN to learn a latent representation directly from speech and then utilize a flow-based acoustic model to model the distribution of the latent representation from text. In this way, the mismatch problem is migrated as the two stages work on the same distribution. Results demonstrate that the flow-based acoustic model can exactly model the distribution of our learned speech representation and the proposed TTS framework, namely Glow-WaveGAN, can produce high fidelity speech outperforming the state-of-the-art GAN-based model.
Controllable Context-aware Conversational Speech Synthesis
Jun 21, 2021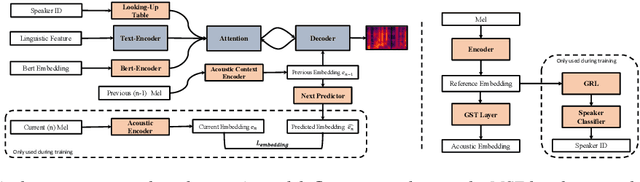
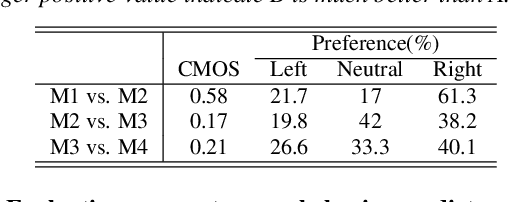

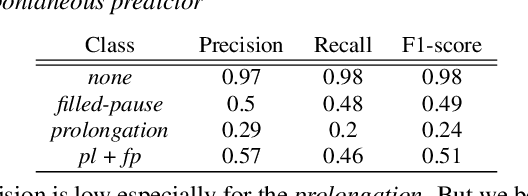
In spoken conversations, spontaneous behaviors like filled pause and prolongations always happen. Conversational partner tends to align features of their speech with their interlocutor which is known as entrainment. To produce human-like conversations, we propose a unified controllable spontaneous conversational speech synthesis framework to model the above two phenomena. Specifically, we use explicit labels to represent two typical spontaneous behaviors filled-pause and prolongation in the acoustic model and develop a neural network based predictor to predict the occurrences of the two behaviors from text. We subsequently develop an algorithm based on the predictor to control the occurrence frequency of the behaviors, making the synthesized speech vary from less disfluent to more disfluent. To model the speech entrainment at acoustic level, we utilize a context acoustic encoder to extract a global style embedding from the previous speech conditioning on the synthesizing of current speech. Furthermore, since the current and previous utterances belong to the different speakers in a conversation, we add a domain adversarial training module to eliminate the speaker-related information in the acoustic encoder while maintaining the style-related information. Experiments show that our proposed approach can synthesize realistic conversations and control the occurrences of the spontaneous behaviors naturally.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021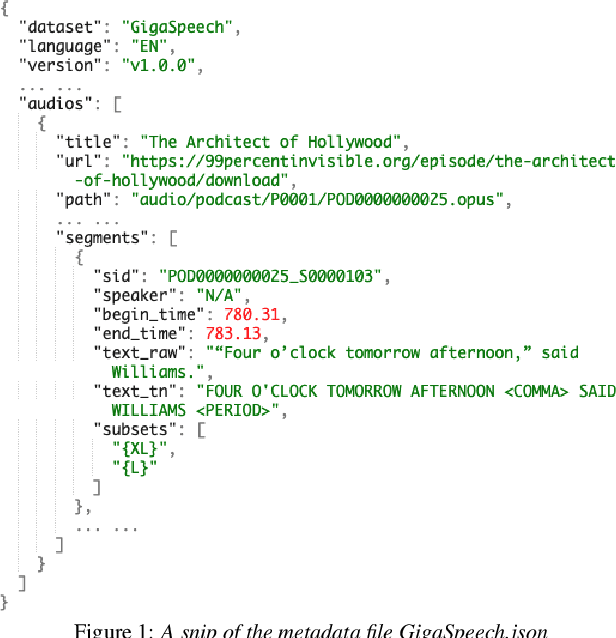
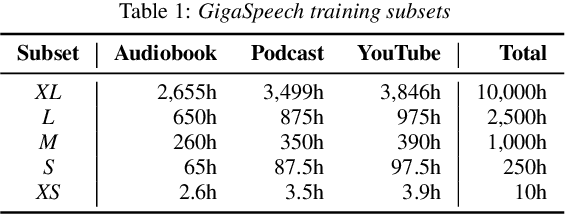
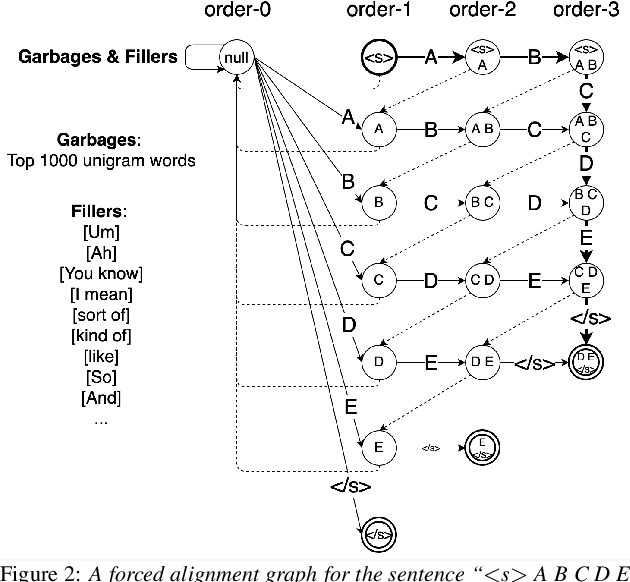
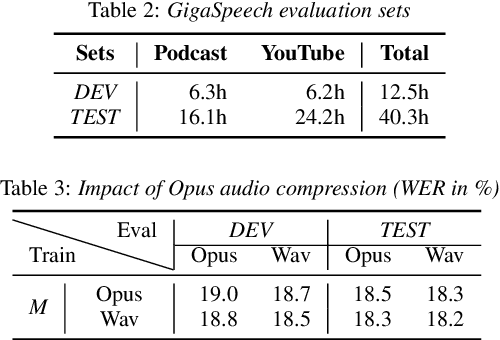
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
Spoken Style Learning with Multi-modal Hierarchical Context Encoding for Conversational Text-to-Speech Synthesis
Jun 11, 2021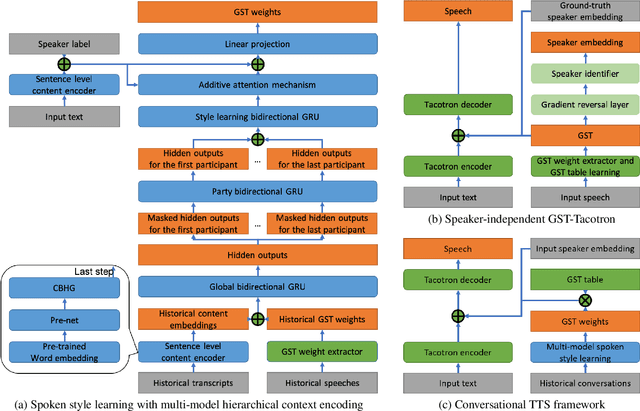

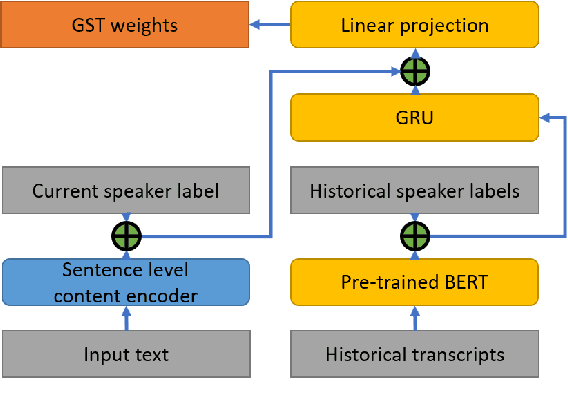

For conversational text-to-speech (TTS) systems, it is vital that the systems can adjust the spoken styles of synthesized speech according to different content and spoken styles in historical conversations. However, the study about learning spoken styles from historical conversations is still in its infancy. Only the transcripts of the historical conversations are considered, which neglects the spoken styles in historical speeches. Moreover, only the interactions of the global aspect between speakers are modeled, missing the party aspect self interactions inside each speaker. In this paper, to achieve better spoken style learning for conversational TTS, we propose a spoken style learning approach with multi-modal hierarchical context encoding. The textual information and spoken styles in the historical conversations are processed through multiple hierarchical recurrent neural networks to learn the spoken style related features in global and party aspects. The attention mechanism is further employed to summarize these features into a conversational context encoding. Experimental results demonstrate the effectiveness of our proposed approach, which outperform a baseline method using context encoding learnt only from the transcripts in global aspects, with MOS score on the naturalness of synthesized speech increasing from 3.138 to 3.408 and ABX preference rate exceeding the baseline method by 36.45%.
Raw Waveform Encoder with Multi-Scale Globally Attentive Locally Recurrent Networks for End-to-End Speech Recognition
Jun 08, 2021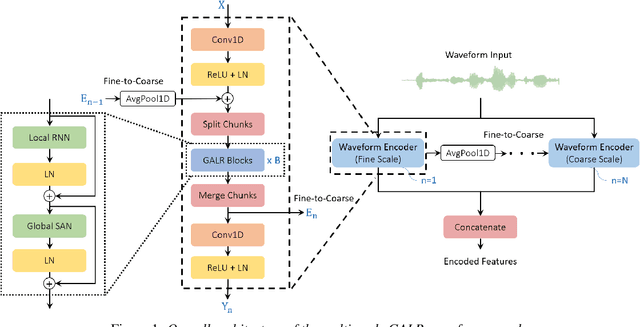
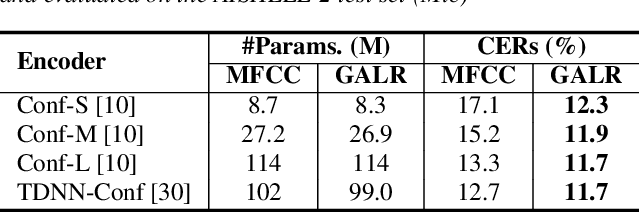
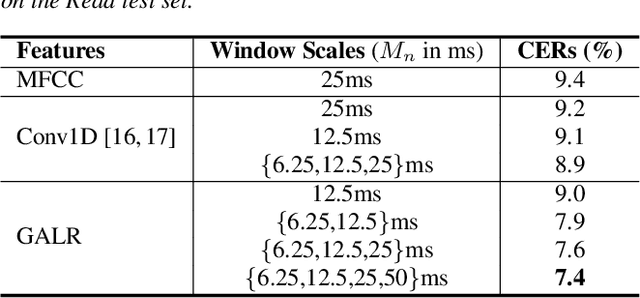
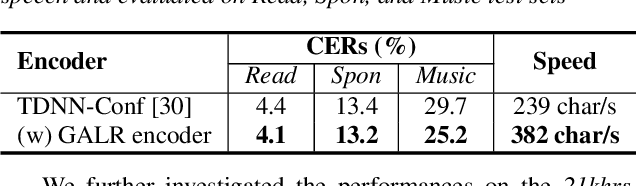
End-to-end speech recognition generally uses hand-engineered acoustic features as input and excludes the feature extraction module from its joint optimization. To extract learnable and adaptive features and mitigate information loss, we propose a new encoder that adopts globally attentive locally recurrent (GALR) networks and directly takes raw waveform as input. We observe improved ASR performance and robustness by applying GALR on different window lengths to aggregate fine-grain temporal information into multi-scale acoustic features. Experiments are conducted on a benchmark dataset AISHELL-2 and two large-scale Mandarin speech corpus of 5,000 hours and 21,000 hours. With faster speed and comparable model size, our proposed multi-scale GALR waveform encoder achieved consistent character error rate reductions (CERRs) from 7.9% to 28.1% relative over strong baselines, including Conformer and TDNN-Conformer. In particular, our approach demonstrated notable robustness than the traditional handcrafted features and outperformed the baseline MFCC-based TDNN-Conformer model by a 15.2% CERR on a music-mixed real-world speech test set.
Improve Query Focused Abstractive Summarization by Incorporating Answer Relevance
May 31, 2021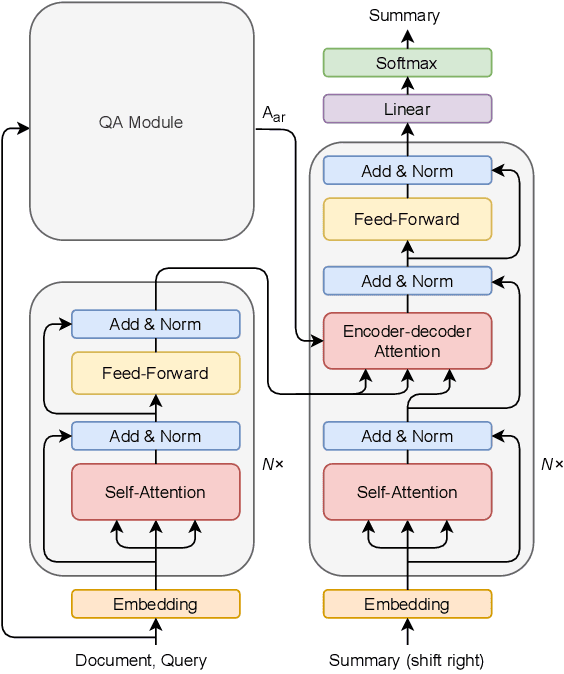
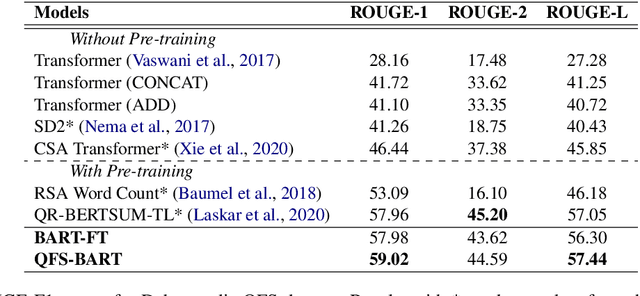

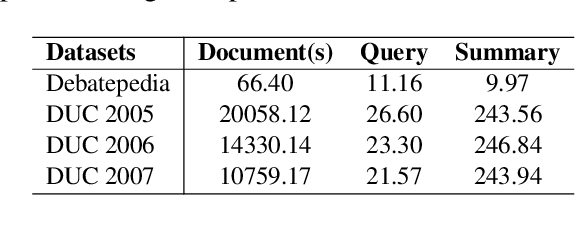
Query focused summarization (QFS) models aim to generate summaries from source documents that can answer the given query. Most previous work on QFS only considers the query relevance criterion when producing the summary. However, studying the effect of answer relevance in the summary generating process is also important. In this paper, we propose QFS-BART, a model that incorporates the explicit answer relevance of the source documents given the query via a question answering model, to generate coherent and answer-related summaries. Furthermore, our model can take advantage of large pre-trained models which improve the summarization performance significantly. Empirical results on the Debatepedia dataset show that the proposed model achieves the new state-of-the-art performance.
DiffSVC: A Diffusion Probabilistic Model for Singing Voice Conversion
May 28, 2021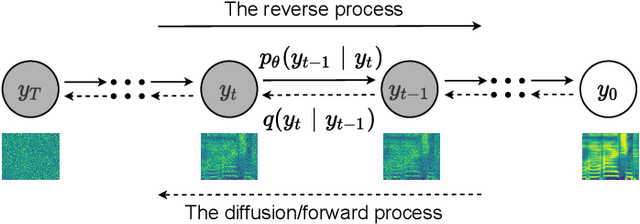
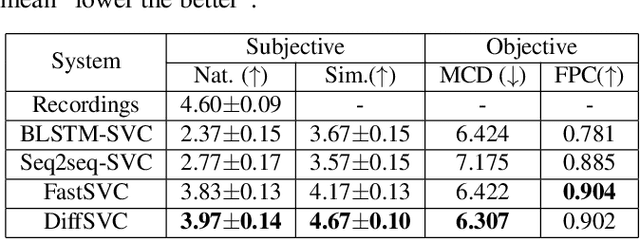
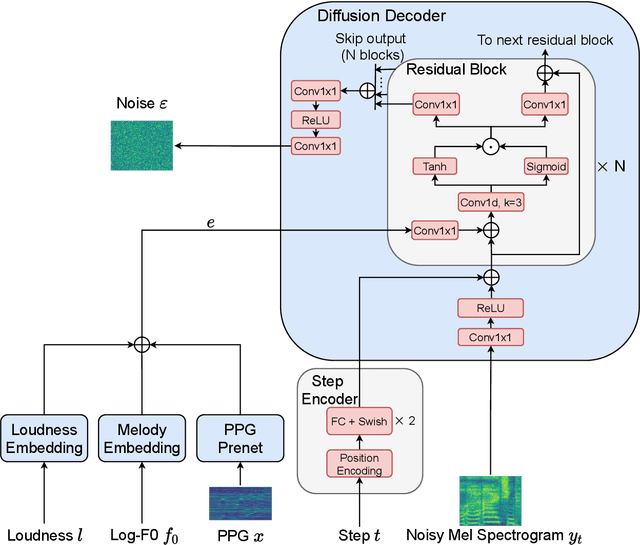
Singing voice conversion (SVC) is one promising technique which can enrich the way of human-computer interaction by endowing a computer the ability to produce high-fidelity and expressive singing voice. In this paper, we propose DiffSVC, an SVC system based on denoising diffusion probabilistic model. DiffSVC uses phonetic posteriorgrams (PPGs) as content features. A denoising module is trained in DiffSVC, which takes destroyed mel spectrogram produced by the diffusion/forward process and its corresponding step information as input to predict the added Gaussian noise. We use PPGs, fundamental frequency features and loudness features as auxiliary input to assist the denoising process. Experiments show that DiffSVC can achieve superior conversion performance in terms of naturalness and voice similarity to current state-of-the-art SVC approaches.
Retrieval-Free Knowledge-Grounded Dialogue Response Generation with Adapters
May 13, 2021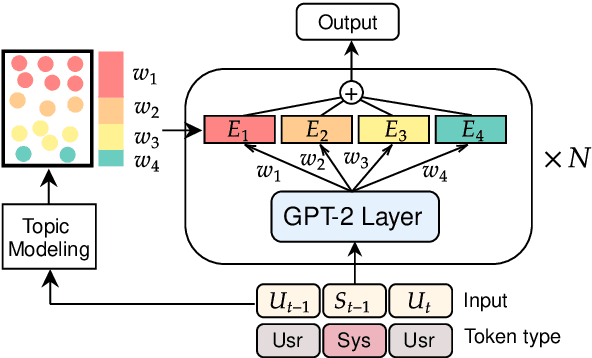
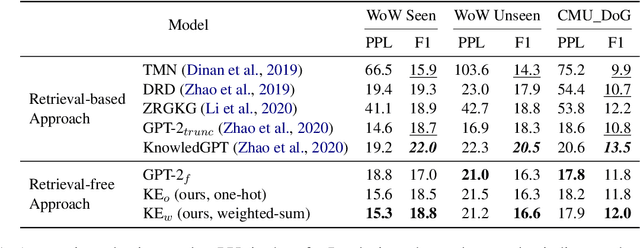
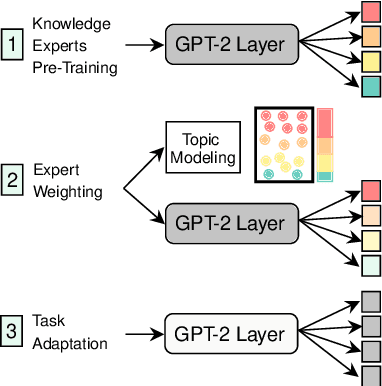

To diversify and enrich generated dialogue responses, knowledge-grounded dialogue has been investigated in recent years. Despite the success of the existing methods, they mainly follow the paradigm of retrieving the relevant sentences over a large corpus and augment the dialogues with explicit extra information, which is time- and resource-consuming. In this paper, we propose KnowExpert, an end-to-end framework to bypass the retrieval process by injecting prior knowledge into the pre-trained language models with lightweight adapters. To the best of our knowledge, this is the first attempt to tackle this task relying solely on a generation-based approach. Experimental results show that KnowExpert performs comparably with the retrieval-based baselines, demonstrating the potential of our proposed direction.
Latency-Controlled Neural Architecture Search for Streaming Speech Recognition
May 08, 2021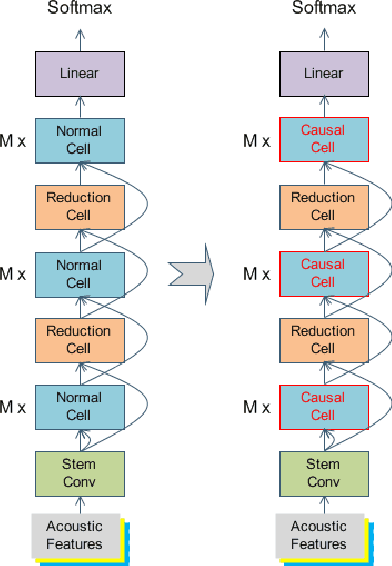


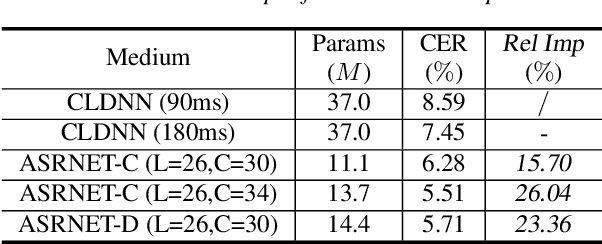
Recently, neural architecture search (NAS) has attracted much attention and has been explored for automatic speech recognition (ASR). Our prior work has shown promising results compared with hand-designed neural networks. In this work, we focus on streaming ASR scenarios and propose the latency-controlled NAS for acoustic modeling. First, based on the vanilla neural architecture, normal cells are altered to be causal cells, in order to control the total latency of the neural network. Second, a revised operation space with a smaller receptive field is proposed to generate the final architecture with low latency. Extensive experiments show that: 1) Based on the proposed neural architecture, the neural networks with a medium latency of 550ms (millisecond) and a low latency of 190ms can be learned in the vanilla and revised operation space respectively. 2) For the low latency setting, the evaluation network can achieve more than 19\% (average on the four test sets) relative improvements compared with the hybrid CLDNN baseline, on a 10k-hour large-scale dataset. Additional 11\% relative improvements can be achieved if the latency of the neural network is relaxed to the medium latency setting.
SpeechMoE: Scaling to Large Acoustic Models with Dynamic Routing Mixture of Experts
May 07, 2021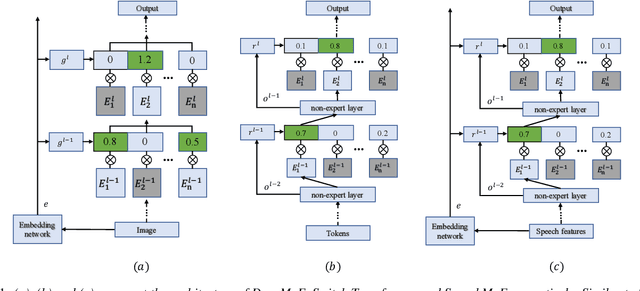
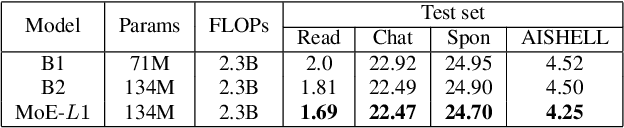
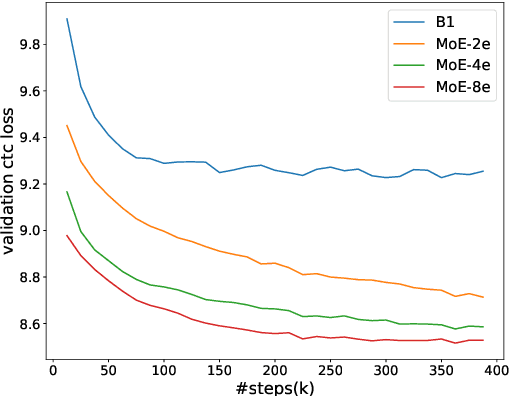
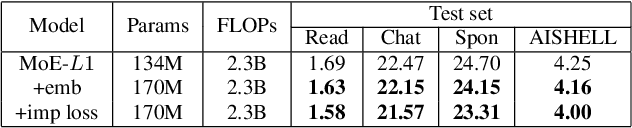
Recently, Mixture of Experts (MoE) based Transformer has shown promising results in many domains. This is largely due to the following advantages of this architecture: firstly, MoE based Transformer can increase model capacity without computational cost increasing both at training and inference time. Besides, MoE based Transformer is a dynamic network which can adapt to the varying complexity of input instances in realworld applications. In this work, we explore the MoE based model for speech recognition, named SpeechMoE. To further control the sparsity of router activation and improve the diversity of gate values, we propose a sparsity L1 loss and a mean importance loss respectively. In addition, a new router architecture is used in SpeechMoE which can simultaneously utilize the information from a shared embedding network and the hierarchical representation of different MoE layers. Experimental results show that SpeechMoE can achieve lower character error rate (CER) with comparable computation cost than traditional static networks, providing 7.0%-23.0% relative CER improvements on four evaluation datasets.