 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechMoE: Scaling to Large Acoustic Models with Dynamic Routing Mixture of Experts
Paper and Code
May 07, 2021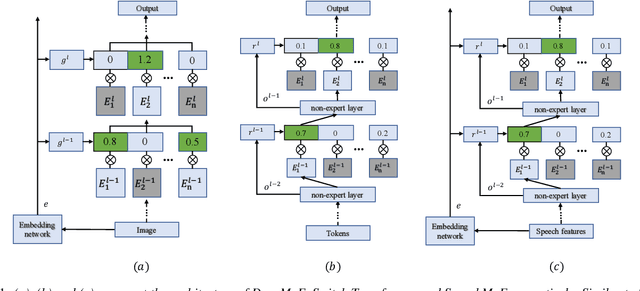
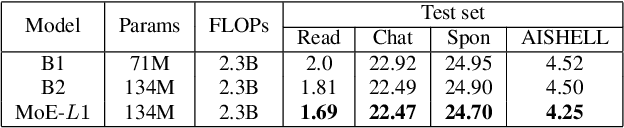
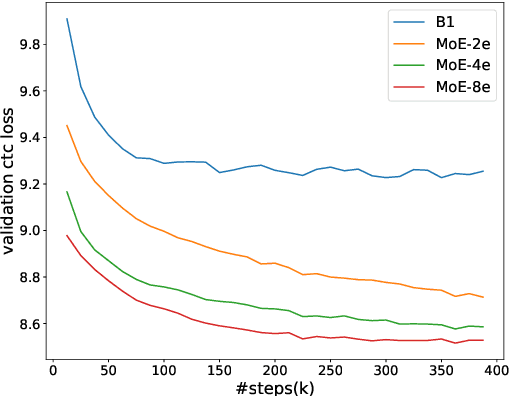
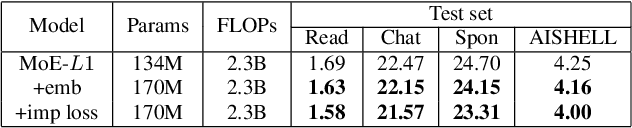
Recently, Mixture of Experts (MoE) based Transformer has shown promising results in many domains. This is largely due to the following advantages of this architecture: firstly, MoE based Transformer can increase model capacity without computational cost increasing both at training and inference time. Besides, MoE based Transformer is a dynamic network which can adapt to the varying complexity of input instances in realworld applications. In this work, we explore the MoE based model for speech recognition, named SpeechMoE. To further control the sparsity of router activation and improve the diversity of gate values, we propose a sparsity L1 loss and a mean importance loss respectively. In addition, a new router architecture is used in SpeechMoE which can simultaneously utilize the information from a shared embedding network and the hierarchical representation of different MoE layers. Experimental results show that SpeechMoE can achieve lower character error rate (CER) with comparable computation cost than traditional static networks, providing 7.0%-23.0% relative CER improvements on four evaluation datasets.