 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Plain Vision Transformer Towards Remote Sensing Foundation Model
Aug 10, 2022
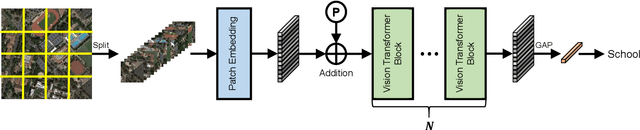
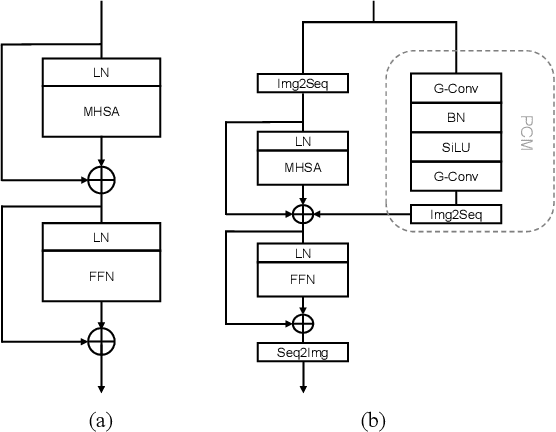
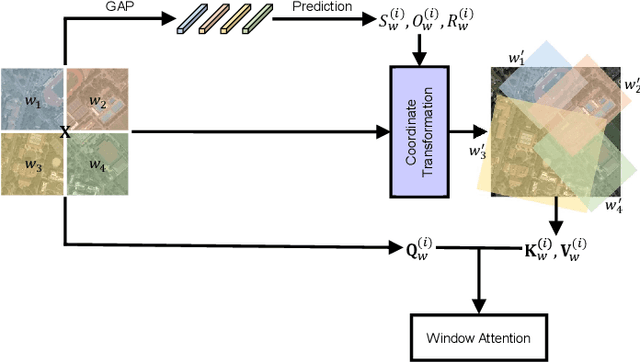
Large-scale vision foundation models have made significant progress in visual tasks on natural images, where the vision transformers are the primary choice for their good scalability and representation ability. However, the utilization of large models in the remote sensing (RS) community remains under-explored where existing models are still at small-scale, which limits the performance. In this paper, we resort to plain vision transformers with about 100 million parameters and make the first attempt to propose large vision models customized for RS tasks and explore how such large models perform. Specifically, to handle the large image size and objects of various orientations in RS images, we propose a new rotated varied-size window attention to substitute the original full attention in transformers, which could significantly reduce the computational cost and memory footprint while learn better object representation by extracting rich context from the generated diverse windows. Experiments on detection tasks demonstrate the superiority of our model over all state-of-the-art models, achieving 81.16% mAP on the DOTA-V1.0 dataset. The results of our models on downstream classification and segmentation tasks also demonstrate competitive performance compared with the existing advanced methods. Further experiments show the advantages of our models on computational complexity and few-shot learning.
Balancing Stability and Plasticity through Advanced Null Space in Continual Learning
Jul 25, 2022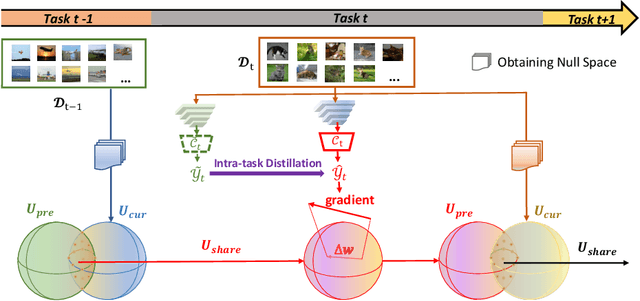
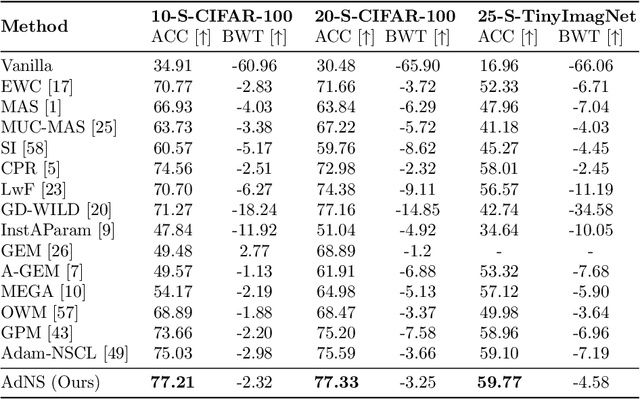
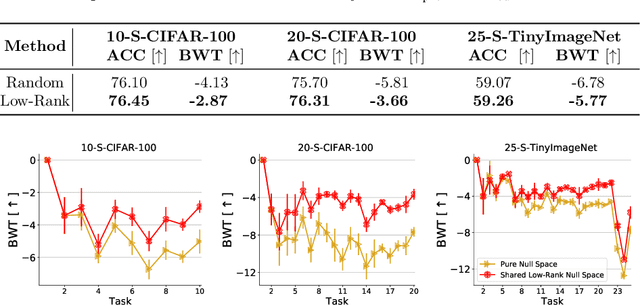
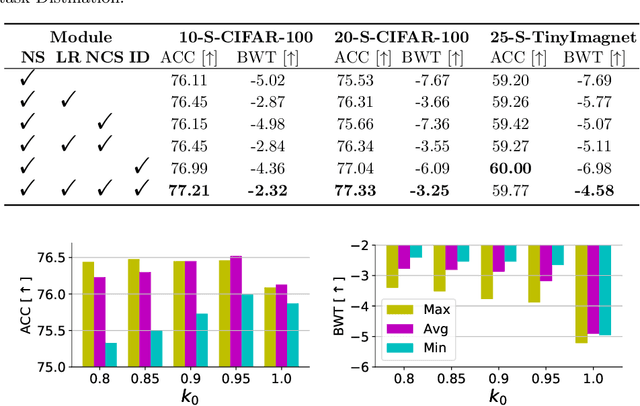
Continual learning is a learning paradigm that learns tasks sequentially with resources constraints, in which the key challenge is stability-plasticity dilemma, i.e., it is uneasy to simultaneously have the stability to prevent catastrophic forgetting of old tasks and the plasticity to learn new tasks well. In this paper, we propose a new continual learning approach, Advanced Null Space (AdNS), to balance the stability and plasticity without storing any old data of previous tasks. Specifically, to obtain better stability, AdNS makes use of low-rank approximation to obtain a novel null space and projects the gradient onto the null space to prevent the interference on the past tasks. To control the generation of the null space, we introduce a non-uniform constraint strength to further reduce forgetting. Furthermore, we present a simple but effective method, intra-task distillation, to improve the performance of the current task. Finally, we theoretically find that null space plays a key role in plasticity and stability, respectively. Experimental results show that the proposed method can achieve better performance compared to state-of-the-art continual learning approaches.
Online Continual Learning with Contrastive Vision Transformer
Jul 24, 2022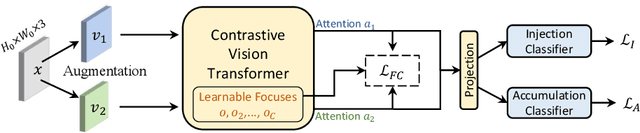
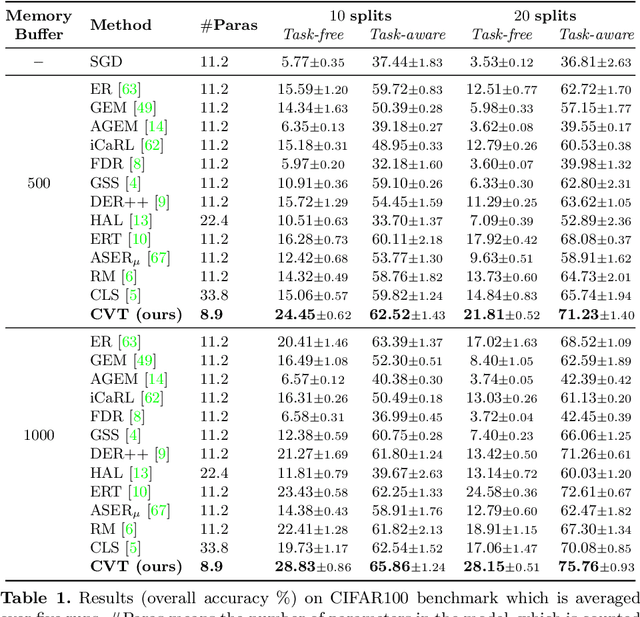
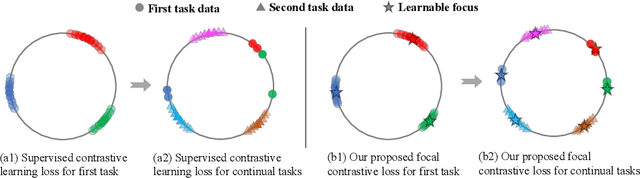
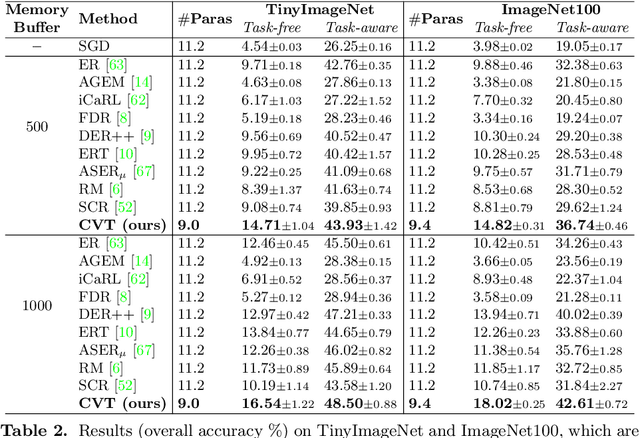
Online continual learning (online CL) studies the problem of learning sequential tasks from an online data stream without task boundaries, aiming to adapt to new data while alleviating catastrophic forgetting on the past tasks. This paper proposes a framework Contrastive Vision Transformer (CVT), which designs a focal contrastive learning strategy based on a transformer architecture, to achieve a better stability-plasticity trade-off for online CL. Specifically, we design a new external attention mechanism for online CL that implicitly captures previous tasks' information. Besides, CVT contains learnable focuses for each class, which could accumulate the knowledge of previous classes to alleviate forgetting. Based on the learnable focuses, we design a focal contrastive loss to rebalance contrastive learning between new and past classes and consolidate previously learned representations. Moreover, CVT contains a dual-classifier structure for decoupling learning current classes and balancing all observed classes. The extensive experimental results show that our approach achieves state-of-the-art performance with even fewer parameters on online CL benchmarks and effectively alleviates the catastrophic forgetting.
Learning Graph Neural Networks for Image Style Transfer
Jul 24, 2022
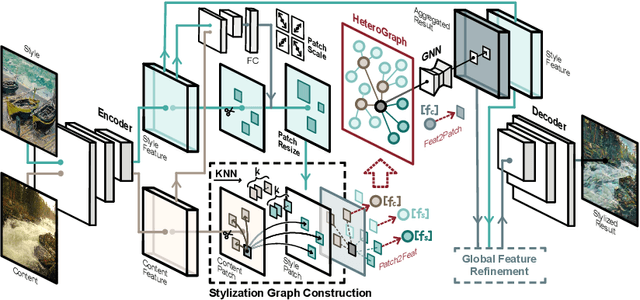

State-of-the-art parametric and non-parametric style transfer approaches are prone to either distorted local style patterns due to global statistics alignment, or unpleasing artifacts resulting from patch mismatching. In this paper, we study a novel semi-parametric neural style transfer framework that alleviates the deficiency of both parametric and non-parametric stylization. The core idea of our approach is to establish accurate and fine-grained content-style correspondences using graph neural networks (GNNs). To this end, we develop an elaborated GNN model with content and style local patches as the graph vertices. The style transfer procedure is then modeled as the attention-based heterogeneous message passing between the style and content nodes in a learnable manner, leading to adaptive many-to-one style-content correlations at the local patch level. In addition, an elaborated deformable graph convolutional operation is introduced for cross-scale style-content matching. Experimental results demonstrate that the proposed semi-parametric image stylization approach yields encouraging results on the challenging style patterns, preserving both global appearance and exquisite details. Furthermore, by controlling the number of edges at the inference stage, the proposed method also triggers novel functionalities like diversified patch-based stylization with a single model.
ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning
Jul 18, 2022
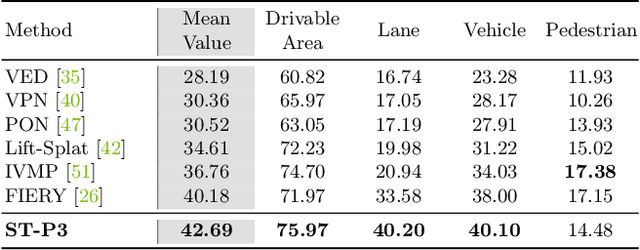
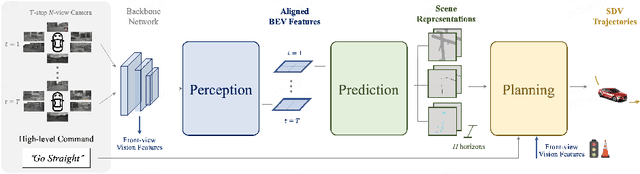
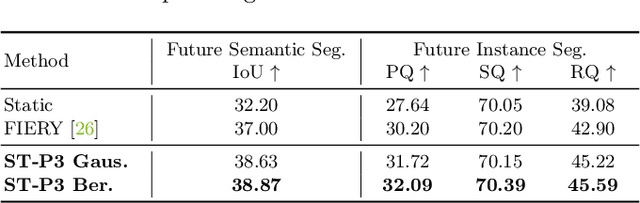
Many existing autonomous driving paradigms involve a multi-stage discrete pipeline of tasks. To better predict the control signals and enhance user safety, an end-to-end approach that benefits from joint spatial-temporal feature learning is desirable. While there are some pioneering works on LiDAR-based input or implicit design, in this paper we formulate the problem in an interpretable vision-based setting. In particular, we propose a spatial-temporal feature learning scheme towards a set of more representative features for perception, prediction and planning tasks simultaneously, which is called ST-P3. Specifically, an egocentric-aligned accumulation technique is proposed to preserve geometry information in 3D space before the bird's eye view transformation for perception; a dual pathway modeling is devised to take past motion variations into account for future prediction; a temporal-based refinement unit is introduced to compensate for recognizing vision-based elements for planning. To the best of our knowledge, we are the first to systematically investigate each part of an interpretable end-to-end vision-based autonomous driving system. We benchmark our approach against previous state-of-the-arts on both open-loop nuScenes dataset as well as closed-loop CARLA simulation. The results show the effectiveness of our method. Source code, model and protocol details are made publicly available at https://github.com/OpenPerceptionX/ST-P3.
JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes
Jul 16, 2022
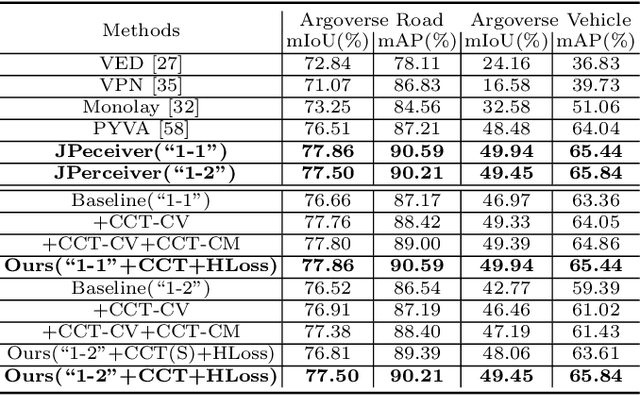
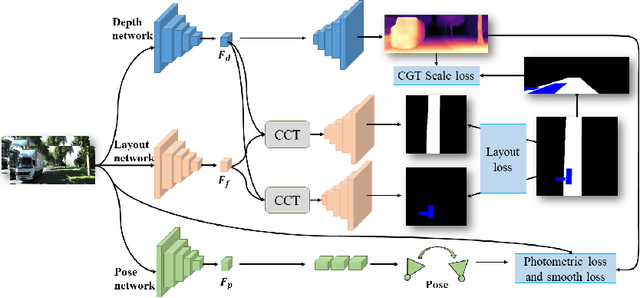
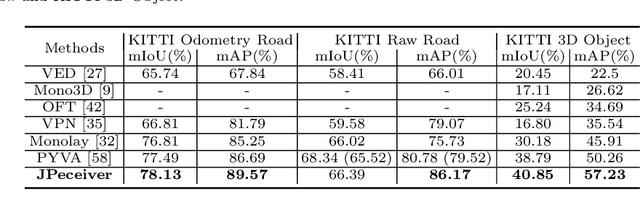
Depth estimation, visual odometry (VO), and bird's-eye-view (BEV) scene layout estimation present three critical tasks for driving scene perception, which is fundamental for motion planning and navigation in autonomous driving. Though they are complementary to each other, prior works usually focus on each individual task and rarely deal with all three tasks together. A naive way is to accomplish them independently in a sequential or parallel manner, but there are many drawbacks, i.e., 1) the depth and VO results suffer from the inherent scale ambiguity issue; 2) the BEV layout is directly predicted from the front-view image without using any depth-related information, although the depth map contains useful geometry clues for inferring scene layouts. In this paper, we address these issues by proposing a novel joint perception framework named JPerceiver, which can simultaneously estimate scale-aware depth and VO as well as BEV layout from a monocular video sequence. It exploits the cross-view geometric transformation (CGT) to propagate the absolute scale from the road layout to depth and VO based on a carefully-designed scale loss. Meanwhile, a cross-view and cross-modal transfer (CCT) module is devised to leverage the depth clues for reasoning road and vehicle layout through an attention mechanism. JPerceiver can be trained in an end-to-end multi-task learning way, where the CGT scale loss and CCT module promote inter-task knowledge transfer to benefit feature learning of each task. Experiments on Argoverse, Nuscenes and KITTI show the superiority of JPerceiver over existing methods on all the above three tasks in terms of accuracy, model size, and inference speed. The code and models are available at~\href{https://github.com/sunnyHelen/JPerceiver}{https://github.com/sunnyHelen/JPerceiver}.
ReAct: Temporal Action Detection with Relational Queries
Jul 14, 2022
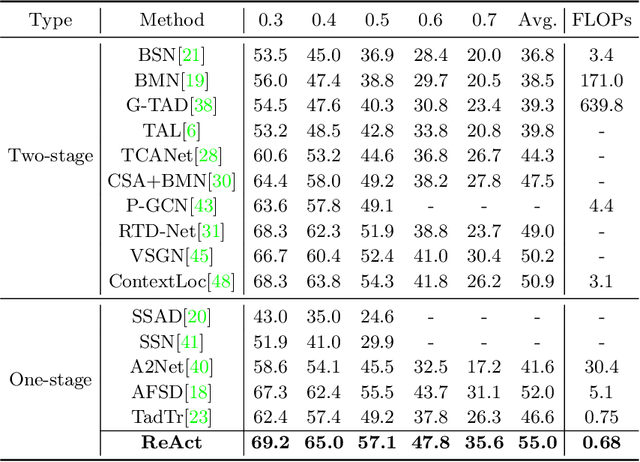
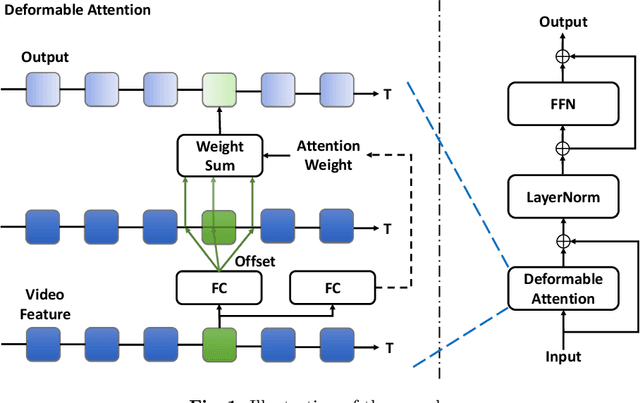
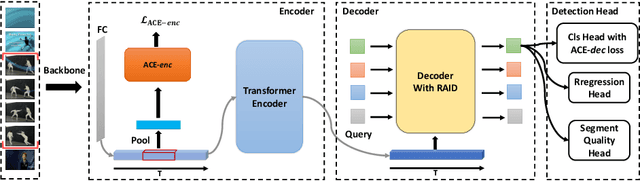
This work aims at advancing temporal action detection (TAD) using an encoder-decoder framework with action queries, similar to DETR, which has shown great success in object detection. However, the framework suffers from several problems if directly applied to TAD: the insufficient exploration of inter-query relation in the decoder, the inadequate classification training due to a limited number of training samples, and the unreliable classification scores at inference. To this end, we first propose a relational attention mechanism in the decoder, which guides the attention among queries based on their relations. Moreover, we propose two losses to facilitate and stabilize the training of action classification. Lastly, we propose to predict the localization quality of each action query at inference in order to distinguish high-quality queries. The proposed method, named ReAct, achieves the state-of-the-art performance on THUMOS14, with much lower computational costs than previous methods. Besides, extensive ablation studies are conducted to verify the effectiveness of each proposed component. The code is available at https://github.com/sssste/React.
Transformer-based Context Condensation for Boosting Feature Pyramids in Object Detection
Jul 14, 2022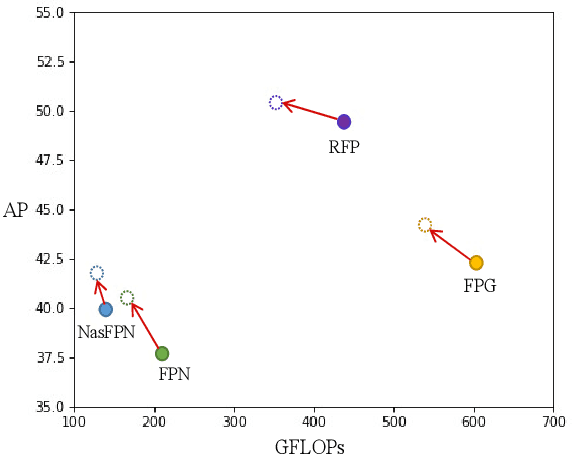
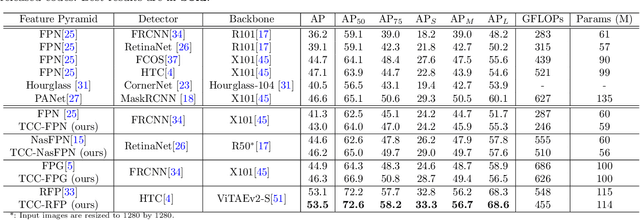
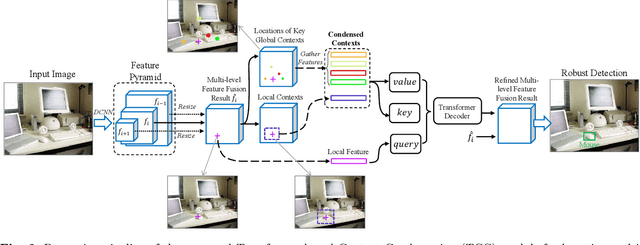

Current object detectors typically have a feature pyramid (FP) module for multi-level feature fusion (MFF) which aims to mitigate the gap between features from different levels and form a comprehensive object representation to achieve better detection performance. However, they usually require heavy cross-level connections or iterative refinement to obtain better MFF result, making them complicated in structure and inefficient in computation. To address these issues, we propose a novel and efficient context modeling mechanism that can help existing FPs deliver better MFF results while reducing the computational costs effectively. In particular, we introduce a novel insight that comprehensive contexts can be decomposed and condensed into two types of representations for higher efficiency. The two representations include a locally concentrated representation and a globally summarized representation, where the former focuses on extracting context cues from nearby areas while the latter extracts key representations of the whole image scene as global context cues. By collecting the condensed contexts, we employ a Transformer decoder to investigate the relations between them and each local feature from the FP and then refine the MFF results accordingly. As a result, we obtain a simple and light-weight Transformer-based Context Condensation (TCC) module, which can boost various FPs and lower their computational costs simultaneously. Extensive experimental results on the challenging MS COCO dataset show that TCC is compatible to four representative FPs and consistently improves their detection accuracy by up to 7.8 % in terms of average precision and reduce their complexities by up to around 20% in terms of GFLOPs, helping them achieve state-of-the-art performance more efficiently. Code will be released.
Towards Scale-Aware, Robust, and Generalizable Unsupervised Monocular Depth Estimation by Integrating IMU Motion Dynamics
Jul 11, 2022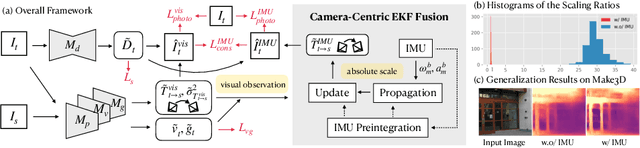
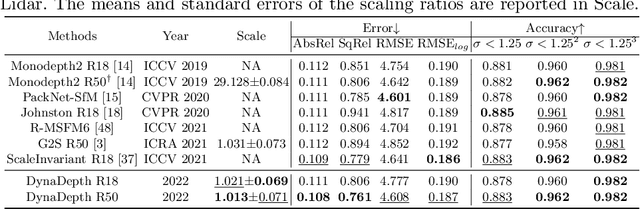
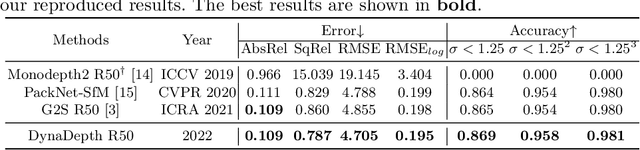
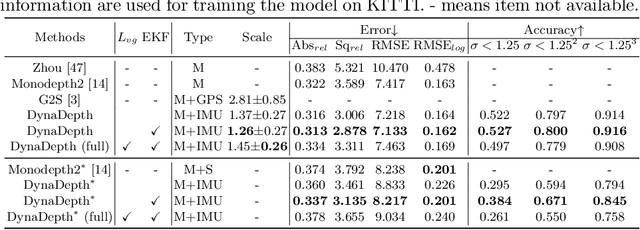
Unsupervised monocular depth and ego-motion estimation has drawn extensive research attention in recent years. Although current methods have reached a high up-to-scale accuracy, they usually fail to learn the true scale metric due to the inherent scale ambiguity from training with monocular sequences. In this work, we tackle this problem and propose DynaDepth, a novel scale-aware framework that integrates information from vision and IMU motion dynamics. Specifically, we first propose an IMU photometric loss and a cross-sensor photometric consistency loss to provide dense supervision and absolute scales. To fully exploit the complementary information from both sensors, we further drive a differentiable camera-centric extended Kalman filter (EKF) to update the IMU preintegrated motions when observing visual measurements. In addition, the EKF formulation enables learning an ego-motion uncertainty measure, which is non-trivial for unsupervised methods. By leveraging IMU during training, DynaDepth not only learns an absolute scale, but also provides a better generalization ability and robustness against vision degradation such as illumination change and moving objects. We validate the effectiveness of DynaDepth by conducting extensive experiments and simulations on the KITTI and Make3D datasets.
DPText-DETR: Towards Better Scene Text Detection with Dynamic Points in Transformer
Jul 10, 2022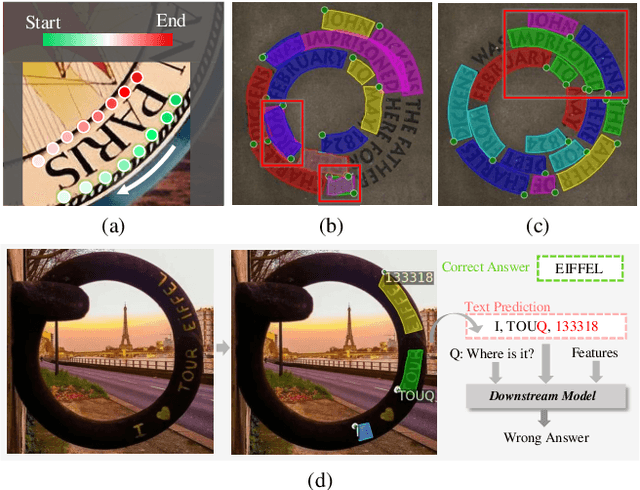
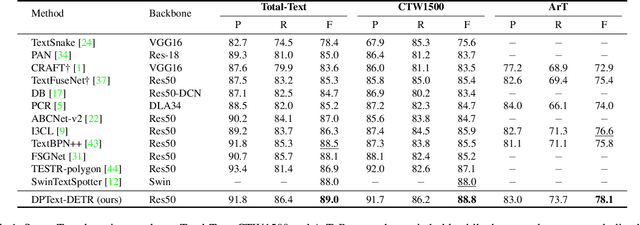
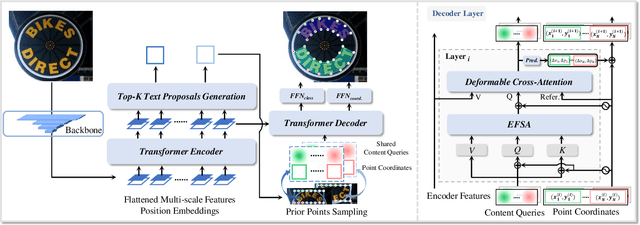
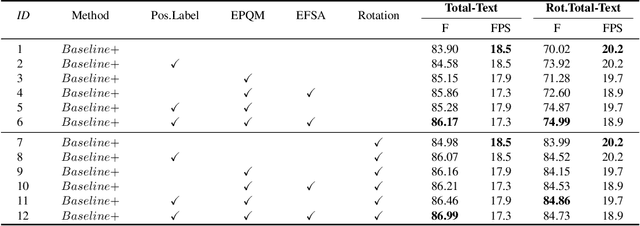
Recently, Transformer-based methods, which predict polygon points or Bezier curve control points to localize texts, are quite popular in scene text detection. However, the used point label form implies the reading order of humans, which affects the robustness of Transformer model. As for the model architecture, the formulation of queries used in decoder has not been fully explored by previous methods. In this paper, we propose a concise dynamic point scene text detection Transformer network termed DPText-DETR, which directly uses point coordinates as queries and dynamically updates them between decoder layers. We point out a simple yet effective positional point label form to tackle the side effect of the original one. Moreover, an Enhanced Factorized Self-Attention module is designed to explicitly model the circular shape of polygon point sequences beyond non-local attention. Extensive experiments prove the training efficiency, robustness, and state-of-the-art performance on various arbitrary shape scene text benchmarks. Beyond detector, we observe that existing end-to-end spotters struggle to recognize inverse-like texts. To evaluate their performance objectively and facilitate future research, we propose an Inverse-Text test set containing 500 manually labeled images. The code and Inverse-Text test set will be available at https://github.com/ymy-k/DPText-DETR.