 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Video Representations from Textual Web Supervision
Jul 29, 2020
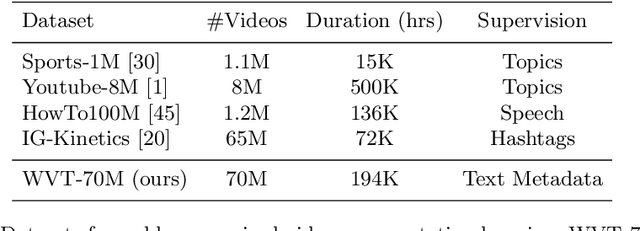
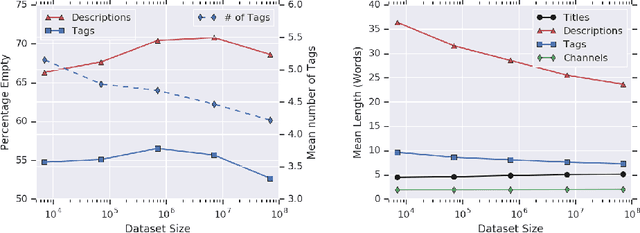

Videos found on the Internet are paired with pieces of text, such as titles and descriptions. This text typically describes the most important content in the video, such as the objects in the scene and the actions being performed. Based on this observation, we propose to use such text as a method for learning video representations. To accomplish this, we propose a data collection process and use it to collect 70M video clips shared publicly on the Internet, and we then train a model to pair each video with its associated text. We fine-tune the model on several down-stream action recognition tasks, including Kinetics, HMDB-51, and UCF-101. We find that this approach is an effective method of pretraining video representations. Specifically, it leads to improvements over from-scratch training on all benchmarks, outperforms many methods for self-supervised and webly-supervised video representation learning, and achieves an improvement of 2.2% accuracy on HMDB-51.
Uncertainty-Aware Weakly Supervised Action Detection from Untrimmed Videos
Jul 21, 2020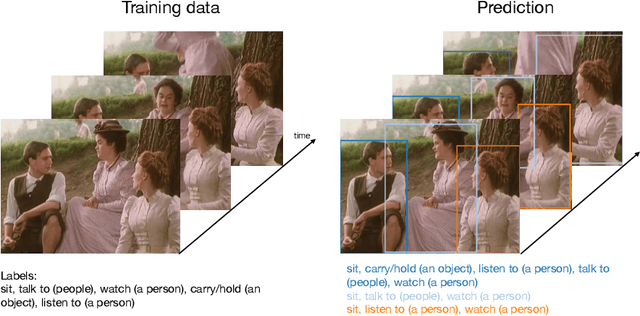
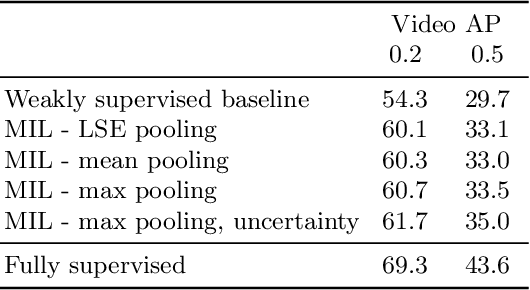
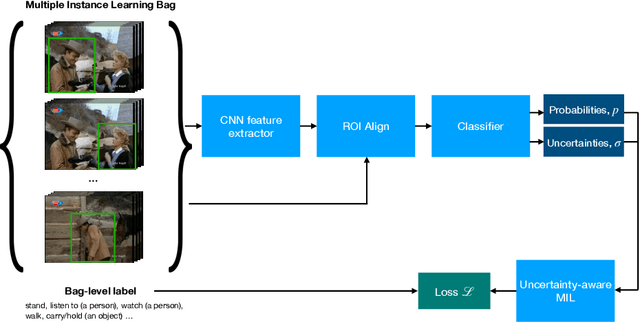

Despite the recent advances in video classification, progress in spatio-temporal action recognition has lagged behind. A major contributing factor has been the prohibitive cost of annotating videos frame-by-frame. In this paper, we present a spatio-temporal action recognition model that is trained with only video-level labels, which are significantly easier to annotate. Our method leverages per-frame person detectors which have been trained on large image datasets within a Multiple Instance Learning framework. We show how we can apply our method in cases where the standard Multiple Instance Learning assumption, that each bag contains at least one instance with the specified label, is invalid using a novel probabilistic variant of MIL where we estimate the uncertainty of each prediction. Furthermore, we report the first weakly-supervised results on the AVA dataset and state-of-the-art results among weakly-supervised methods on UCF101-24.
Multi-modal Transformer for Video Retrieval
Jul 21, 2020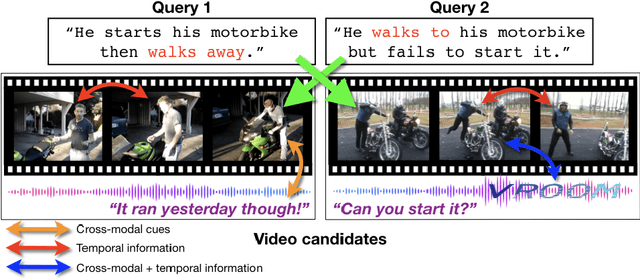

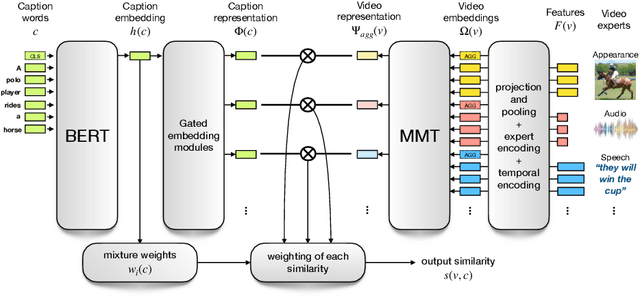
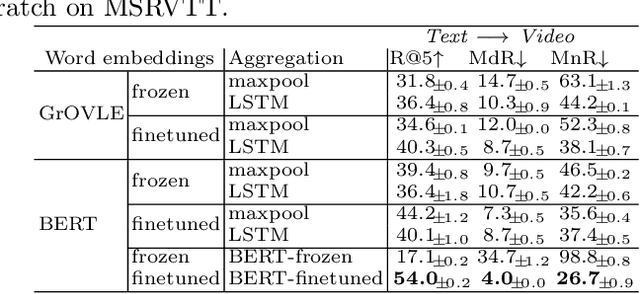
The task of retrieving video content relevant to natural language queries plays a critical role in effectively handling internet-scale datasets. Most of the existing methods for this caption-to-video retrieval problem do not fully exploit cross-modal cues present in video. Furthermore, they aggregate per-frame visual features with limited or no temporal information. In this paper, we present a multi-modal transformer to jointly encode the different modalities in video, which allows each of them to attend to the others. The transformer architecture is also leveraged to encode and model the temporal information. On the natural language side, we investigate the best practices to jointly optimize the language embedding together with the multi-modal transformer. This novel framework allows us to establish state-of-the-art results for video retrieval on three datasets. More details are available at http://thoth.inrialpes.fr/research/MMT.
Unsupervised Learning of Video Representations via Dense Trajectory Clustering
Jun 28, 2020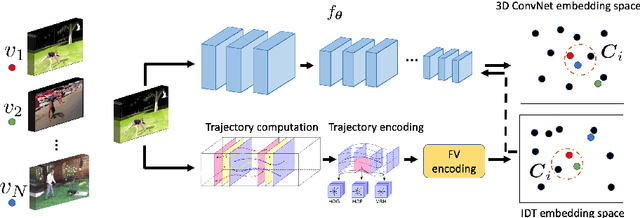
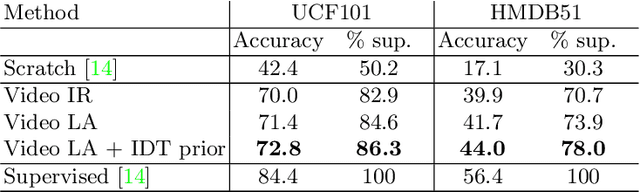
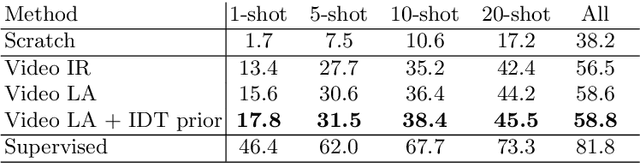

This paper addresses the task of unsupervised learning of representations for action recognition in videos. Previous works proposed to utilize future prediction, or other domain-specific objectives to train a network, but achieved only limited success. In contrast, in the relevant field of image representation learning, simpler, discrimination-based methods have recently bridged the gap to fully-supervised performance. We first propose to adapt two top performing objectives in this class - instance recognition and local aggregation, to the video domain. In particular, the latter approach iterates between clustering the videos in the feature space of a network and updating it to respect the cluster with a non-parametric classification loss. We observe promising performance, but qualitative analysis shows that the learned representations fail to capture motion patterns, grouping the videos based on appearance. To mitigate this issue, we turn to the heuristic-based IDT descriptors, that were manually designed to encode motion patterns in videos. We form the clusters in the IDT space, using these descriptors as a an unsupervised prior in the iterative local aggregation algorithm. Our experiments demonstrates that this approach outperform prior work on UCF101 and HMDB51 action recognition benchmarks. We also qualitatively analyze the learned representations and show that they successfully capture video dynamics.
Consistency Guided Scene Flow Estimation
Jun 19, 2020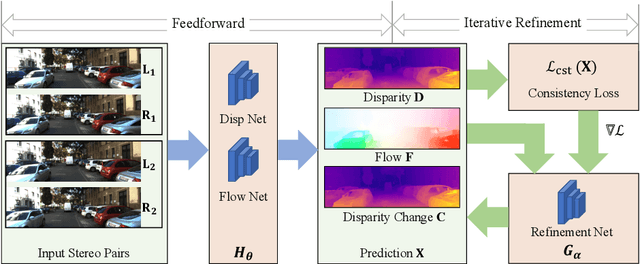


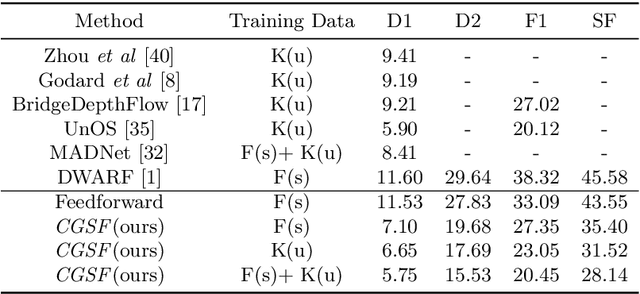
We present Consistency Guided Scene Flow Estimation (CGSF), a framework for joint estimation of 3D scene structure and motion from stereo videos. The model takes two temporal stereo pairs as input, and predicts disparity and scene flow. The model self-adapts at test time by iteratively refining its predictions. The refinement process is guided by a consistency loss, which combines stereo and temporal photo-consistency with a geometric term that couples the disparity and 3D motion. To handle the noise in the consistency loss, we further propose a learned, output refinement network, which takes the initial predictions, the loss, and the gradient as input, and efficiently predicts a correlated output update. We demonstrate with extensive experiments that the proposed model can reliably predict disparity and scene flow in many challenging scenarios, and achieves better generalization than the state-of-the-arts.
TAO: A Large-Scale Benchmark for Tracking Any Object
May 20, 2020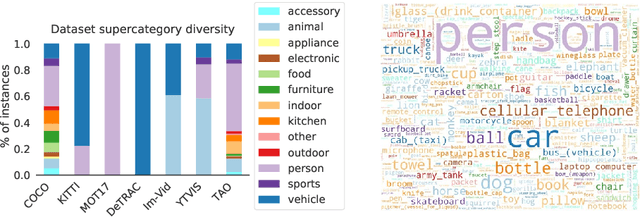
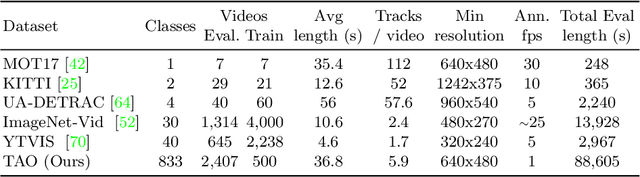


For many years, multi-object tracking benchmarks have focused on a handful of categories. Motivated primarily by surveillance and self-driving applications, these datasets provide tracks for people, vehicles, and animals, ignoring the vast majority of objects in the world. By contrast, in the related field of object detection, the introduction of large-scale, diverse datasets (e.g., COCO) have fostered significant progress in developing highly robust solutions. To bridge this gap, we introduce a similarly diverse dataset for Tracking Any Object (TAO). It consists of 2,907 high resolution videos, captured in diverse environments, which are half a minute long on average. Importantly, we adopt a bottom-up approach for discovering a large vocabulary of 833 categories, an order of magnitude more than prior tracking benchmarks. To this end, we ask annotators to label objects that move at any point in the video, and give names to them post factum. Our vocabulary is both significantly larger and qualitatively different from existing tracking datasets. To ensure scalability of annotation, we employ a federated approach that focuses manual effort on labeling tracks for those relevant objects in a video (e.g., those that move). We perform an extensive evaluation of state-of-the-art trackers and make a number of important discoveries regarding large-vocabulary tracking in an open-world. In particular, we show that existing single- and multi-object trackers struggle when applied to this scenario in the wild, and that detection-based, multi-object trackers are in fact competitive with user-initialized ones. We hope that our dataset and analysis will boost further progress in the tracking community.
What makes for good views for contrastive learning
May 20, 2020
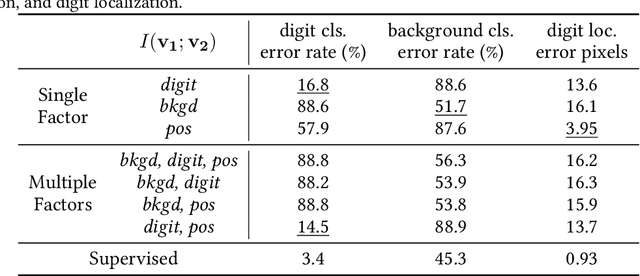
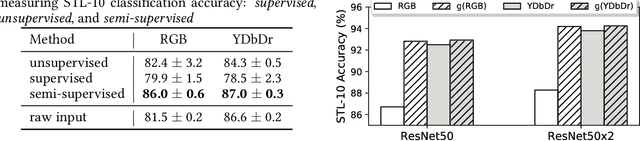
Contrastive learning between multiple views of the data has recently achieved state of the art performance in the field of self-supervised representation learning. Despite its success, the influence of different view choices has been less studied. In this paper, we use empirical analysis to better understand the importance of view selection, and argue that we should reduce the mutual information (MI) between views while keeping task-relevant information intact. To verify this hypothesis, we devise unsupervised and semi-supervised frameworks that learn effective views by aiming to reduce their MI. We also consider data augmentation as a way to reduce MI, and show that increasing data augmentation indeed leads to decreasing MI and improves downstream classification accuracy. As a by-product, we also achieve a new state-of-the-art accuracy on unsupervised pre-training for ImageNet classification ($73\%$ top-1 linear readoff with a ResNet-50). In addition, transferring our models to PASCAL VOC object detection and COCO instance segmentation consistently outperforms supervised pre-training. Code:http://github.com/HobbitLong/PyContrast
VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation
May 08, 2020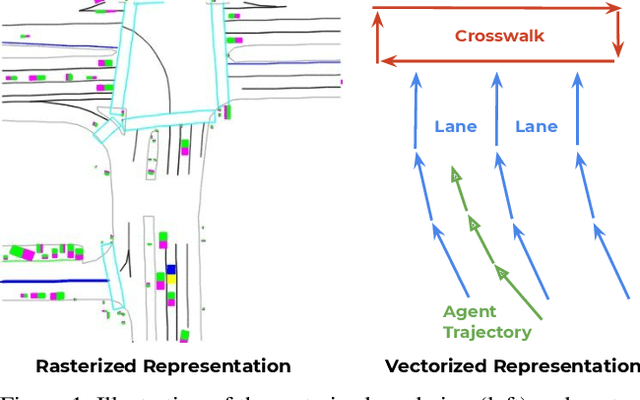
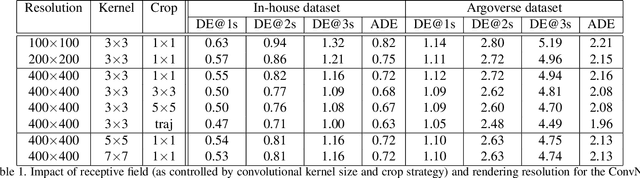
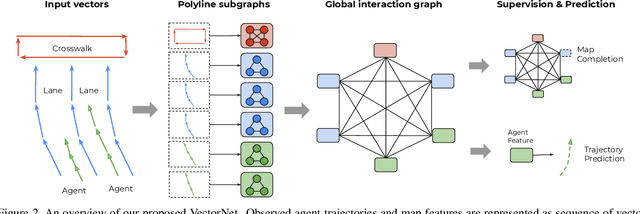
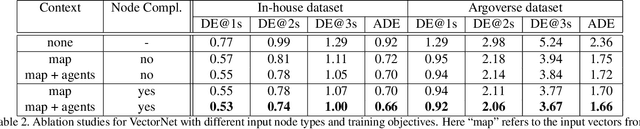
Behavior prediction in dynamic, multi-agent systems is an important problem in the context of self-driving cars, due to the complex representations and interactions of road components, including moving agents (e.g. pedestrians and vehicles) and road context information (e.g. lanes, traffic lights). This paper introduces VectorNet, a hierarchical graph neural network that first exploits the spatial locality of individual road components represented by vectors and then models the high-order interactions among all components. In contrast to most recent approaches, which render trajectories of moving agents and road context information as bird-eye images and encode them with convolutional neural networks (ConvNets), our approach operates on a vector representation. By operating on the vectorized high definition (HD) maps and agent trajectories, we avoid lossy rendering and computationally intensive ConvNet encoding steps. To further boost VectorNet's capability in learning context features, we propose a novel auxiliary task to recover the randomly masked out map entities and agent trajectories based on their context. We evaluate VectorNet on our in-house behavior prediction benchmark and the recently released Argoverse forecasting dataset. Our method achieves on par or better performance than the competitive rendering approach on both benchmarks while saving over 70% of the model parameters with an order of magnitude reduction in FLOPs. It also outperforms the state of the art on the Argoverse dataset.
Leveraging Photometric Consistency over Time for Sparsely Supervised Hand-Object Reconstruction
Apr 28, 2020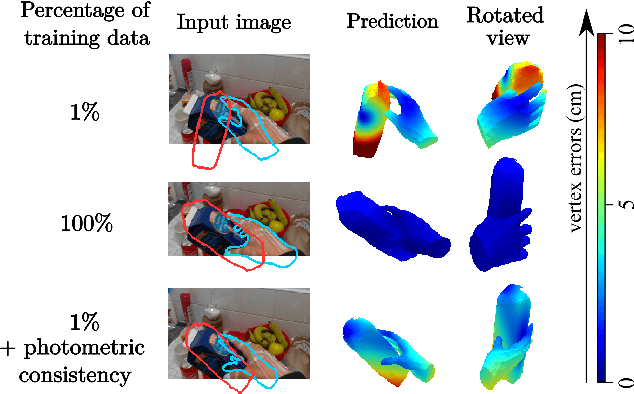

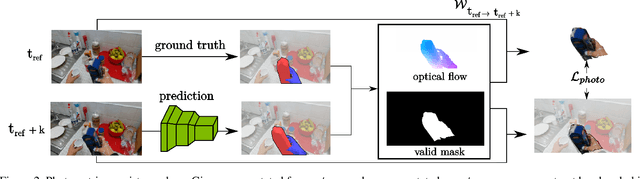

Modeling hand-object manipulations is essential for understanding how humans interact with their environment. While of practical importance, estimating the pose of hands and objects during interactions is challenging due to the large mutual occlusions that occur during manipulation. Recent efforts have been directed towards fully-supervised methods that require large amounts of labeled training samples. Collecting 3D ground-truth data for hand-object interactions, however, is costly, tedious, and error-prone. To overcome this challenge we present a method to leverage photometric consistency across time when annotations are only available for a sparse subset of frames in a video. Our model is trained end-to-end on color images to jointly reconstruct hands and objects in 3D by inferring their poses. Given our estimated reconstructions, we differentiably render the optical flow between pairs of adjacent images and use it within the network to warp one frame to another. We then apply a self-supervised photometric loss that relies on the visual consistency between nearby images. We achieve state-of-the-art results on 3D hand-object reconstruction benchmarks and demonstrate that our approach allows us to improve the pose estimation accuracy by leveraging information from neighboring frames in low-data regimes.
Learning visual policies for building 3D shape categories
Apr 15, 2020

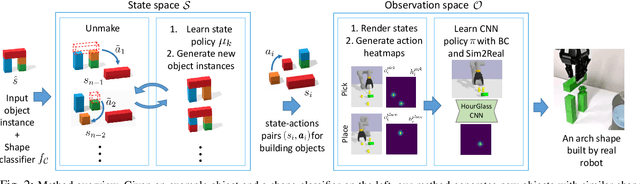
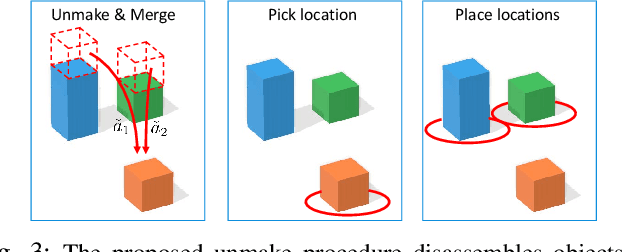
Manipulation and assembly tasks require non-trivial planning of actions depending on the environment and the final goal. Previous work in this domain often assembles particular instances of objects from known sets of primitives. In contrast, we here aim to handle varying sets of primitives and to construct different objects of the same shape category. Given a single object instance of a category, e.g. an arch, and a binary shape classifier, we learn a visual policy to assemble other instances of the same category. In particular, we propose a disassembly procedure and learn a state policy that discovers new object instances and their assembly plans in state space. We then render simulated states in the observation space and learn a heatmap representation to predict alternative actions from a given input image. To validate our approach, we first demonstrate its efficiency for building object categories in state space. We then show the success of our visual policies for building arches from different primitives. Moreover, we demonstrate (i) the reactive ability of our method to re-assemble objects using additional primitives and (ii) the robust performance of our policy for unseen primitives resembling building blocks used during training. Our visual assembly policies are trained with no real images and reach up to 95% success rate when evaluated on a real robot.