 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLORE: Logical Location Regression Network for Table Structure Recognition
Mar 07, 2023



Table structure recognition (TSR) aims at extracting tables in images into machine-understandable formats. Recent methods solve this problem by predicting the adjacency relations of detected cell boxes, or learning to generate the corresponding markup sequences from the table images. However, they either count on additional heuristic rules to recover the table structures, or require a huge amount of training data and time-consuming sequential decoders. In this paper, we propose an alternative paradigm. We model TSR as a logical location regression problem and propose a new TSR framework called LORE, standing for LOgical location REgression network, which for the first time combines logical location regression together with spatial location regression of table cells. Our proposed LORE is conceptually simpler, easier to train and more accurate than previous TSR models of other paradigms. Experiments on standard benchmarks demonstrate that LORE consistently outperforms prior arts. Code is available at https:// github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LORE-TSR.
Levenshtein OCR
Sep 08, 2022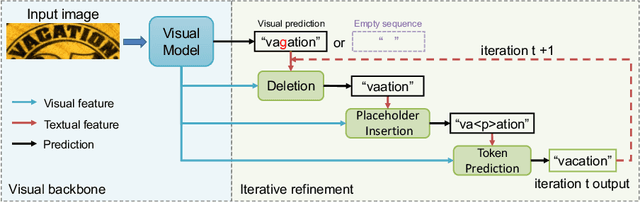
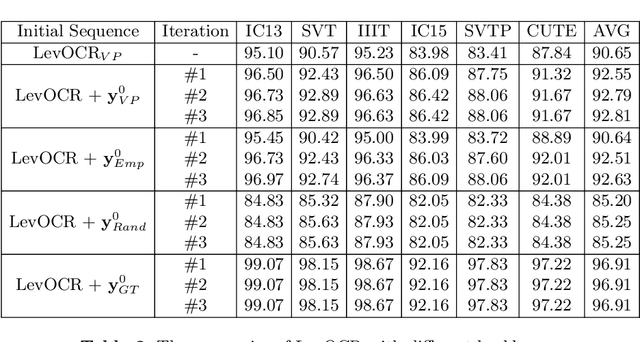
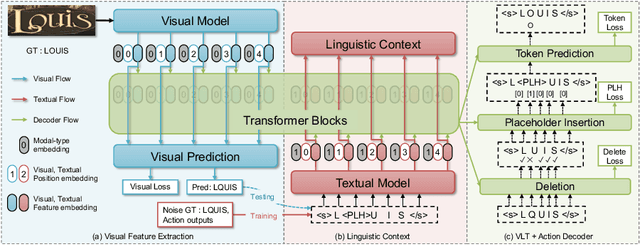
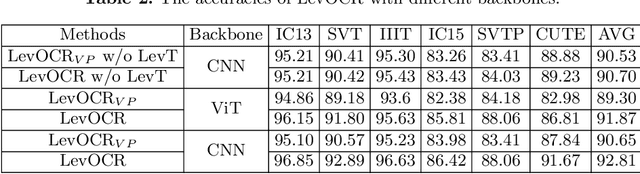
A novel scene text recognizer based on Vision-Language Transformer (VLT) is presented. Inspired by Levenshtein Transformer in the area of NLP, the proposed method (named Levenshtein OCR, and LevOCR for short) explores an alternative way for automatically transcribing textual content from cropped natural images. Specifically, we cast the problem of scene text recognition as an iterative sequence refinement process. The initial prediction sequence produced by a pure vision model is encoded and fed into a cross-modal transformer to interact and fuse with the visual features, to progressively approximate the ground truth. The refinement process is accomplished via two basic character-level operations: deletion and insertion, which are learned with imitation learning and allow for parallel decoding, dynamic length change and good interpretability. The quantitative experiments clearly demonstrate that LevOCR achieves state-of-the-art performances on standard benchmarks and the qualitative analyses verify the effectiveness and advantage of the proposed LevOCR algorithm. Code will be released soon.
Multi-Granularity Prediction for Scene Text Recognition
Sep 08, 2022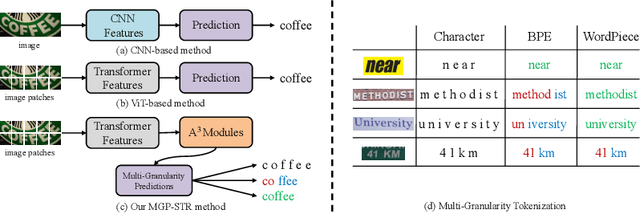
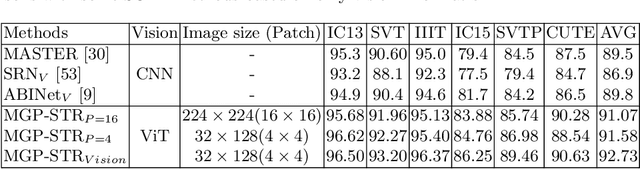
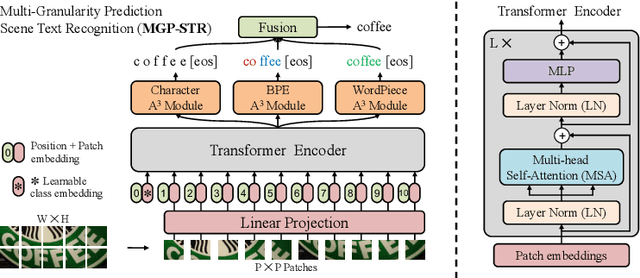

Scene text recognition (STR) has been an active research topic in computer vision for years. To tackle this challenging problem, numerous innovative methods have been successively proposed and incorporating linguistic knowledge into STR models has recently become a prominent trend. In this work, we first draw inspiration from the recent progress in Vision Transformer (ViT) to construct a conceptually simple yet powerful vision STR model, which is built upon ViT and outperforms previous state-of-the-art models for scene text recognition, including both pure vision models and language-augmented methods. To integrate linguistic knowledge, we further propose a Multi-Granularity Prediction strategy to inject information from the language modality into the model in an implicit way, i.e. , subword representations (BPE and WordPiece) widely-used in NLP are introduced into the output space, in addition to the conventional character level representation, while no independent language model (LM) is adopted. The resultant algorithm (termed MGP-STR) is able to push the performance envelop of STR to an even higher level. Specifically, it achieves an average recognition accuracy of 93.35% on standard benchmarks. Code will be released soon.
Bi-VLDoc: Bidirectional Vision-Language Modeling for Visually-Rich Document Understanding
Jun 27, 2022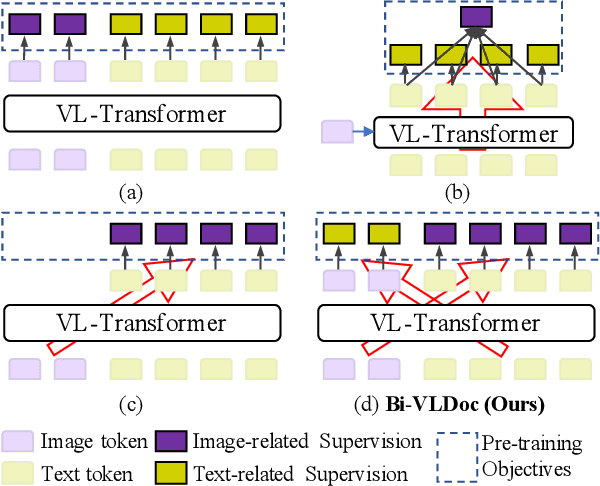
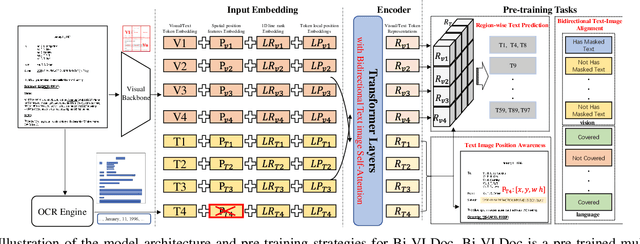
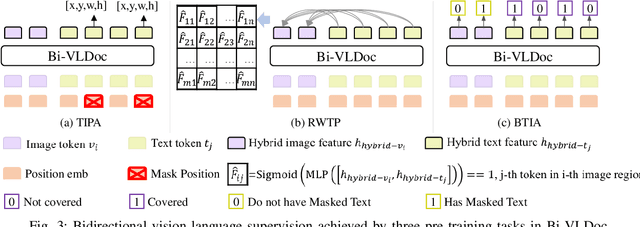
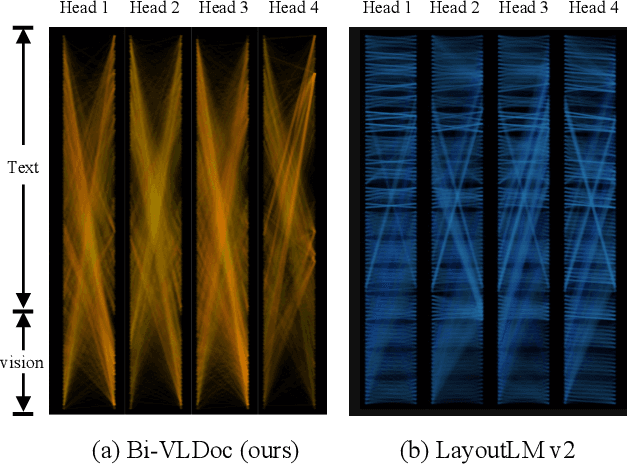
Multi-modal document pre-trained models have proven to be very effective in a variety of visually-rich document understanding (VrDU) tasks. Though existing document pre-trained models have achieved excellent performance on standard benchmarks for VrDU, the way they model and exploit the interactions between vision and language on documents has hindered them from better generalization ability and higher accuracy. In this work, we investigate the problem of vision-language joint representation learning for VrDU mainly from the perspective of supervisory signals. Specifically, a pre-training paradigm called Bi-VLDoc is proposed, in which a bidirectional vision-language supervision strategy and a vision-language hybrid-attention mechanism are devised to fully explore and utilize the interactions between these two modalities, to learn stronger cross-modal document representations with richer semantics. Benefiting from the learned informative cross-modal document representations, Bi-VLDoc significantly advances the state-of-the-art performance on three widely-used document understanding benchmarks, including Form Understanding (from 85.14% to 93.44%), Receipt Information Extraction (from 96.01% to 97.84%), and Document Classification (from 96.08% to 97.12%). On Document Visual QA, Bi-VLDoc achieves the state-of-the-art performance compared to previous single model methods.
Vision-Language Pre-Training for Boosting Scene Text Detectors
Apr 29, 2022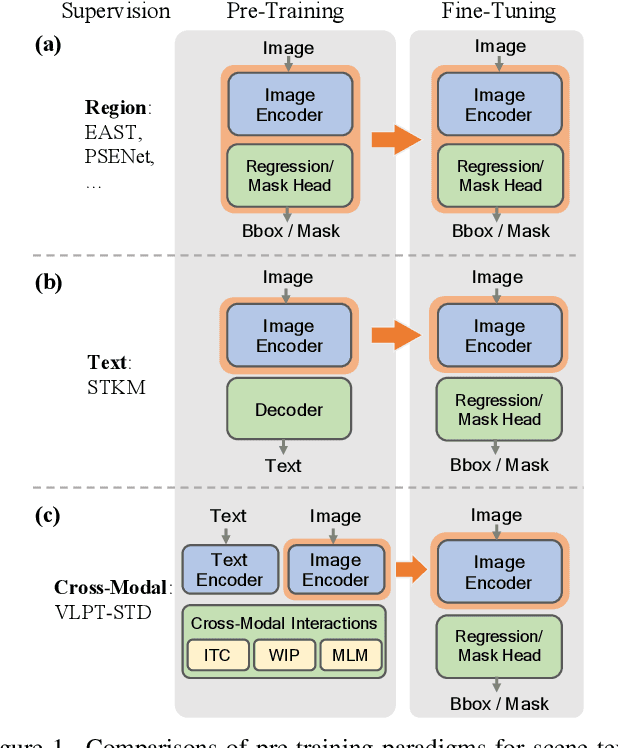
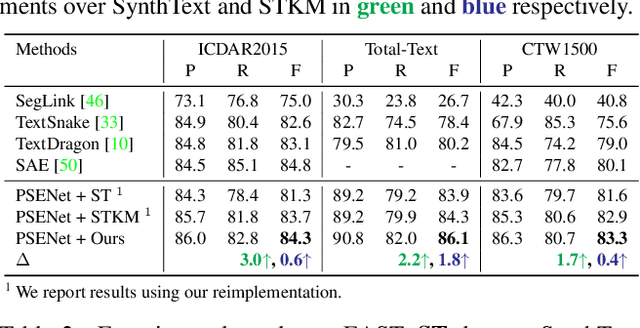
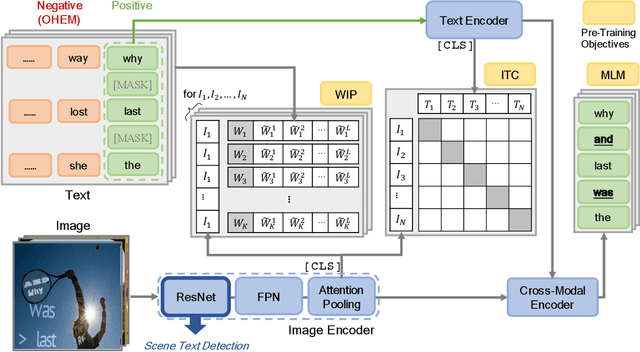
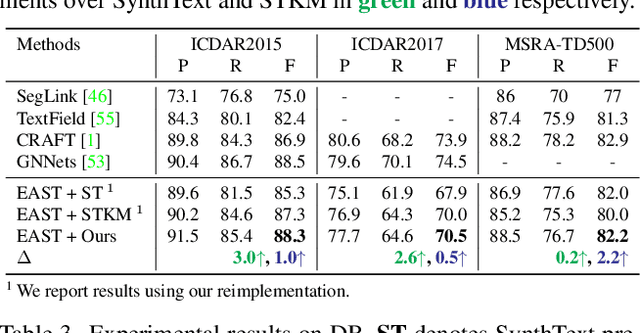
Recently, vision-language joint representation learning has proven to be highly effective in various scenarios. In this paper, we specifically adapt vision-language joint learning for scene text detection, a task that intrinsically involves cross-modal interaction between the two modalities: vision and language, since text is the written form of language. Concretely, we propose to learn contextualized, joint representations through vision-language pre-training, for the sake of enhancing the performance of scene text detectors. Towards this end, we devise a pre-training architecture with an image encoder, a text encoder and a cross-modal encoder, as well as three pretext tasks: image-text contrastive learning (ITC), masked language modeling (MLM) and word-in-image prediction (WIP). The pre-trained model is able to produce more informative representations with richer semantics, which could readily benefit existing scene text detectors (such as EAST and PSENet) in the down-stream text detection task. Extensive experiments on standard benchmarks demonstrate that the proposed paradigm can significantly improve the performance of various representative text detectors, outperforming previous pre-training approaches. The code and pre-trained models will be publicly released.
Revisiting Document Image Dewarping by Grid Regularization
Mar 31, 2022

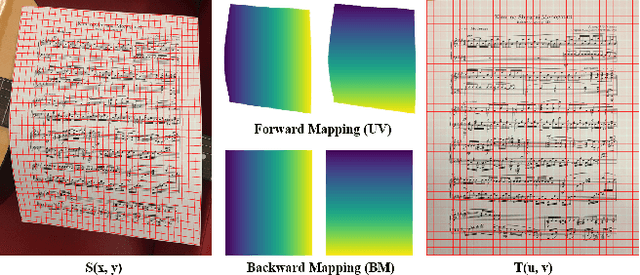
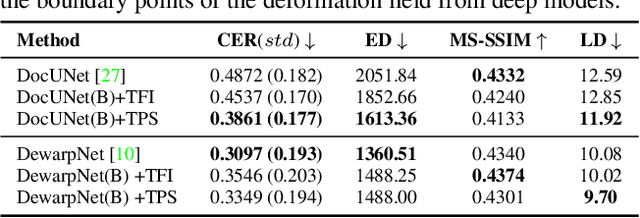
This paper addresses the problem of document image dewarping, which aims at eliminating the geometric distortion in document images for document digitization. Instead of designing a better neural network to approximate the optical flow fields between the inputs and outputs, we pursue the best readability by taking the text lines and the document boundaries into account from a constrained optimization perspective. Specifically, our proposed method first learns the boundary points and the pixels in the text lines and then follows the most simple observation that the boundaries and text lines in both horizontal and vertical directions should be kept after dewarping to introduce a novel grid regularization scheme. To obtain the final forward mapping for dewarping, we solve an optimization problem with our proposed grid regularization. The experiments comprehensively demonstrate that our proposed approach outperforms the prior arts by large margins in terms of readability (with the metrics of Character Errors Rate and the Edit Distance) while maintaining the best image quality on the publicly-available DocUNet benchmark.
Real-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion
Feb 21, 2022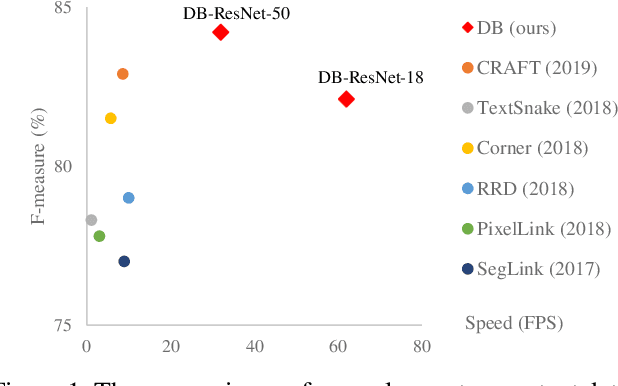
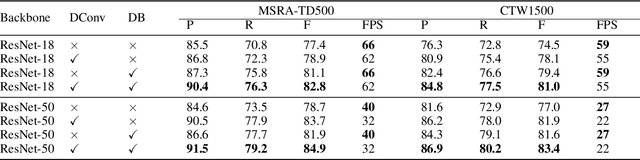
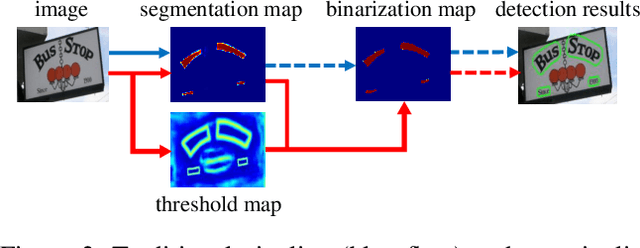
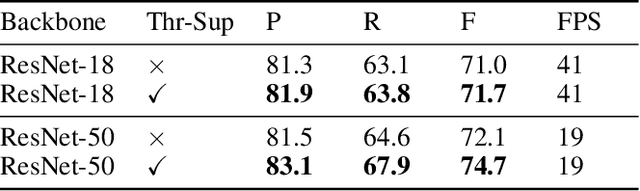
Recently, segmentation-based scene text detection methods have drawn extensive attention in the scene text detection field, because of their superiority in detecting the text instances of arbitrary shapes and extreme aspect ratios, profiting from the pixel-level descriptions. However, the vast majority of the existing segmentation-based approaches are limited to their complex post-processing algorithms and the scale robustness of their segmentation models, where the post-processing algorithms are not only isolated to the model optimization but also time-consuming and the scale robustness is usually strengthened by fusing multi-scale feature maps directly. In this paper, we propose a Differentiable Binarization (DB) module that integrates the binarization process, one of the most important steps in the post-processing procedure, into a segmentation network. Optimized along with the proposed DB module, the segmentation network can produce more accurate results, which enhances the accuracy of text detection with a simple pipeline. Furthermore, an efficient Adaptive Scale Fusion (ASF) module is proposed to improve the scale robustness by fusing features of different scales adaptively. By incorporating the proposed DB and ASF with the segmentation network, our proposed scene text detector consistently achieves state-of-the-art results, in terms of both detection accuracy and speed, on five standard benchmarks.
ARTS: Eliminating Inconsistency between Text Detection and Recognition with Auto-Rectification Text Spotter
Oct 20, 2021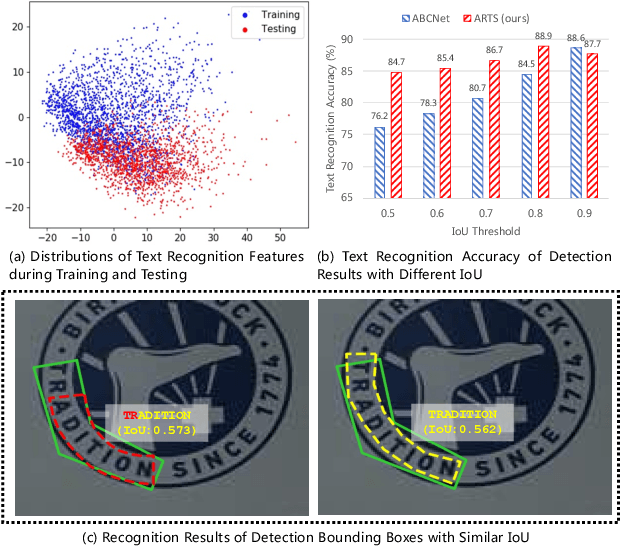
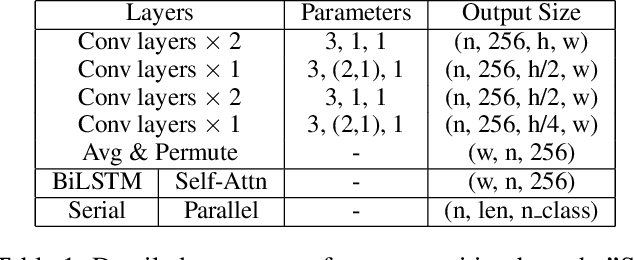
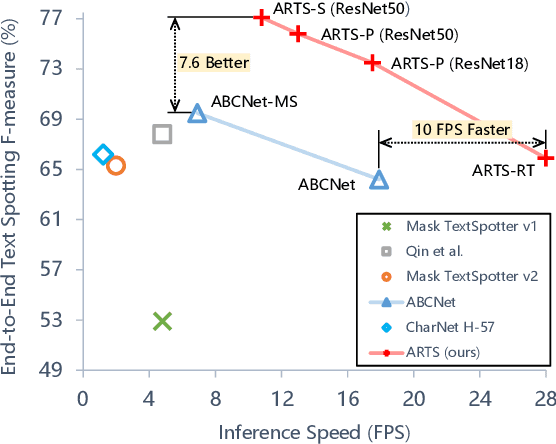
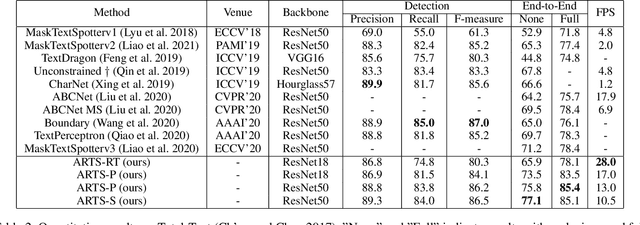
Recent approaches for end-to-end text spotting have achieved promising results. However, most of the current spotters were plagued by the inconsistency problem between text detection and recognition. In this work, we introduce and prove the existence of the inconsistency problem and analyze it from two aspects: (1) inconsistency of text recognition features between training and testing, and (2) inconsistency of optimization targets between text detection and recognition. To solve the aforementioned issues, we propose a differentiable Auto-Rectification Module (ARM) together with a new training strategy to enable propagating recognition loss back into detection branch, so that our detection branch can be jointly optimized by detection and recognition targets, which largely alleviates the inconsistency problem between text detection and recognition. Based on these designs, we present a simple yet robust end-to-end text spotting framework, termed Auto-Rectification Text Spotter (ARTS), to detect and recognize arbitrarily-shaped text in natural scenes. Extensive experiments demonstrate the superiority of our method. In particular, our ARTS-S achieves 77.1% end-to-end text spotting F-measure on Total-Text at a competitive speed of 10.5 FPS, which significantly outperforms previous methods in both accuracy and inference speed.
Facial Attribute Transformers for Precise and Robust Makeup Transfer
Apr 07, 2021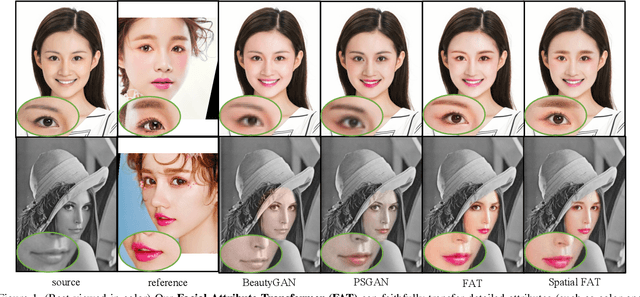

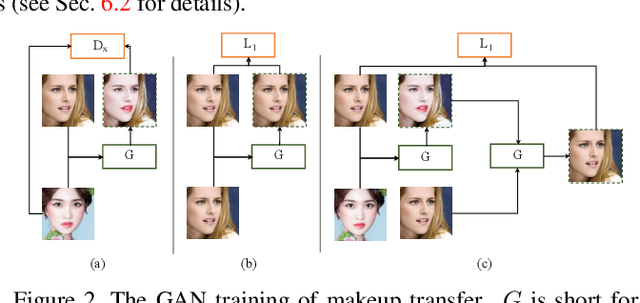
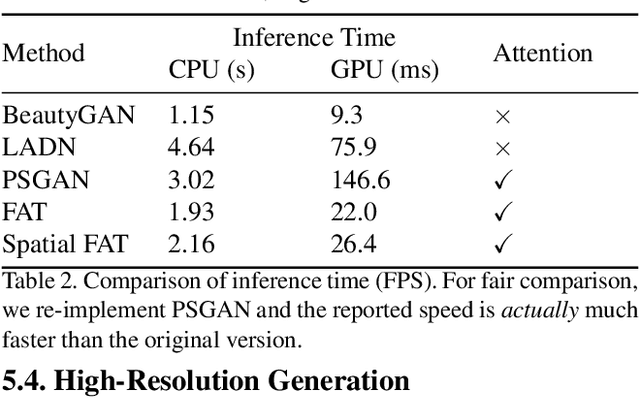
In this paper, we address the problem of makeup transfer, which aims at transplanting the makeup from the reference face to the source face while preserving the identity of the source. Existing makeup transfer methods have made notable progress in generating realistic makeup faces, but do not perform well in terms of color fidelity and spatial transformation. To tackle these issues, we propose a novel Facial Attribute Transformer (FAT) and its variant Spatial FAT for high-quality makeup transfer. Drawing inspirations from the Transformer in NLP, FAT is able to model the semantic correspondences and interactions between the source face and reference face, and then precisely estimate and transfer the facial attributes. To further facilitate shape deformation and transformation of facial parts, we also integrate thin plate splines (TPS) into FAT, thus creating Spatial FAT, which is the first method that can transfer geometric attributes in addition to color and texture. Extensive qualitative and quantitative experiments demonstrate the effectiveness and superiority of our proposed FATs in the following aspects: (1) ensuring high-fidelity color transfer; (2) allowing for geometric transformation of facial parts; (3) handling facial variations (such as poses and shadows) and (4) supporting high-resolution face generation.
MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
Apr 05, 2021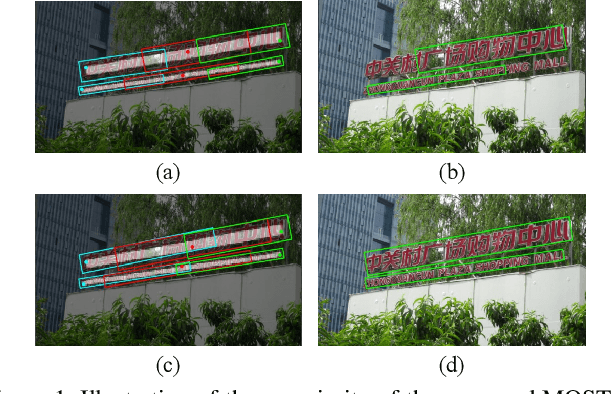
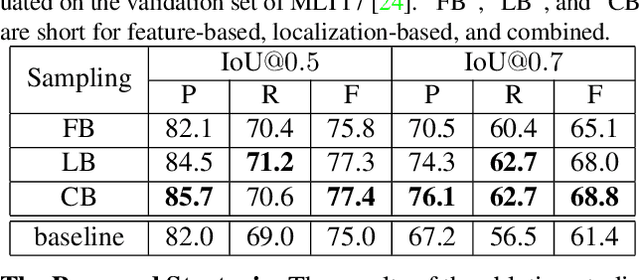
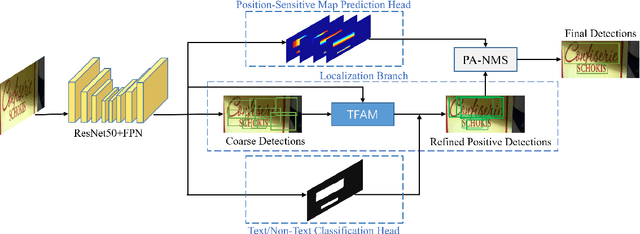
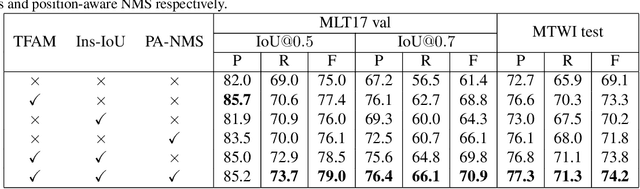
Over the past few years, the field of scene text detection has progressed rapidly that modern text detectors are able to hunt text in various challenging scenarios. However, they might still fall short when handling text instances of extreme aspect ratios and varying scales. To tackle such difficulties, we propose in this paper a new algorithm for scene text detection, which puts forward a set of strategies to significantly improve the quality of text localization. Specifically, a Text Feature Alignment Module (TFAM) is proposed to dynamically adjust the receptive fields of features based on initial raw detections; a Position-Aware Non-Maximum Suppression (PA-NMS) module is devised to selectively concentrate on reliable raw detections and exclude unreliable ones; besides, we propose an Instance-wise IoU loss for balanced training to deal with text instances of different scales. An extensive ablation study demonstrates the effectiveness and superiority of the proposed strategies. The resulting text detection system, which integrates the proposed strategies with a leading scene text detector EAST, achieves state-of-the-art or competitive performance on various standard benchmarks for text detection while keeping a fast running speed.