 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Video Diffusion Transformers with Massive Activations
Mar 18, 2026Despite rapid progress in video diffusion transformers, how their internal model signals can be leveraged with minimal overhead to enhance video generation quality remains underexplored. In this work, we study the role of Massive Activations (MAs), which are rare, high-magnitude hidden state spikes in video diffusion transformers. We observed that MAs emerge consistently across all visual tokens, with a clear magnitude hierarchy: first-frame tokens exhibit the largest MA magnitudes, latent-frame boundary tokens (the head and tail portions of each temporal chunk in the latent space) show elevated but slightly lower MA magnitudes than the first frame, and interior tokens within each latent frame remain elevated, yet are comparatively moderate in magnitude. This structured pattern suggests that the model implicitly prioritizes token positions aligned with the temporal chunking in the latent space. Based on this observation, we propose Structured Activation Steering (STAS), a training-free self-guidance-like method that steers MA values at first-frame and boundary tokens toward a scaled global maximum reference magnitude. STAS achieves consistent improvements in terms of video quality and temporal coherence across different text-to-video models, while introducing negligible computational overhead.
AnyCrowd: Instance-Isolated Identity-Pose Binding for Arbitrary Multi-Character Animation
Mar 16, 2026Controllable character animation has advanced rapidly in recent years, yet multi-character animation remains underexplored. As the number of characters grows, multi-character reference encoding becomes more susceptible to latent identity entanglement, resulting in identity bleeding and reduced controllability. Moreover, learning precise and spatio-temporally consistent correspondences between reference identities and driving pose sequences becomes increasingly challenging, often leading to identity-pose mis-binding and inconsistency in generated videos. To address these challenges, we propose AnyCrowd, a Diffusion Transformer (DiT)-based video generation framework capable of scaling to an arbitrary number of characters. Specifically, we first introduce an Instance-Isolated Latent Representation (IILR), which encodes character instances independently prior to DiT processing to prevent latent identity entanglement. Building on this disentangled representation, we further propose Tri-Stage Decoupled Attention (TSDA) to bind identities to driving poses by decomposing self-attention into: (i) instance-aware foreground attention, (ii) background-centric interaction, and (iii) global foreground-background coordination. Furthermore, to mitigate token ambiguity in overlapping regions, an Adaptive Gated Fusion (AGF) module is integrated within TSDA to predict identity-aware weights, effectively fusing competing token groups into identity-consistent representations...
LUIVITON: Learned Universal Interoperable VIrtual Try-ON
Sep 05, 2025



We present LUIVITON, an end-to-end system for fully automated virtual try-on, capable of draping complex, multi-layer clothing onto diverse and arbitrarily posed humanoid characters. To address the challenge of aligning complex garments with arbitrary and highly diverse body shapes, we use SMPL as a proxy representation and separate the clothing-to-body draping problem into two correspondence tasks: 1) clothing-to-SMPL and 2) body-to-SMPL correspondence, where each has its unique challenges. While we address the clothing-to-SMPL fitting problem using a geometric learning-based approach for partial-to-complete shape correspondence prediction, we introduce a diffusion model-based approach for body-to-SMPL correspondence using multi-view consistent appearance features and a pre-trained 2D foundation model. Our method can handle complex geometries, non-manifold meshes, and generalizes effectively to a wide range of humanoid characters -- including humans, robots, cartoon subjects, creatures, and aliens, while maintaining computational efficiency for practical adoption. In addition to offering a fully automatic fitting solution, LUIVITON supports fast customization of clothing size, allowing users to adjust clothing sizes and material properties after they have been draped. We show that our system can produce high-quality 3D clothing fittings without any human labor, even when 2D clothing sewing patterns are not available.
oneDNN Graph Compiler: A Hybrid Approach for High-Performance Deep Learning Compilation
Jan 03, 2023



With the rapid development of deep learning models and hardware support for dense computing, the deep learning (DL) workload characteristics changed significantly from a few hot spots on compute-intensive operations to a broad range of operations scattered across the models. Accelerating a few compute-intensive operations using the expert-tuned implementation of primitives does not fully exploit the performance potential of AI hardware. Various efforts are made to compile a full deep neural network (DNN) graph. One of the biggest challenges is to achieve end-to-end compilation by generating expert-level performance code for the dense compute-intensive operations and applying compilation optimization at the scope of DNN computation graph across multiple compute-intensive operations. We present oneDNN Graph Compiler, a tensor compiler that employs a hybrid approach of using techniques from both compiler optimization and expert-tuned kernels for high-performance code generation of the deep neural network graph. oneDNN Graph Compiler addresses unique optimization challenges in the deep learning domain, such as low-precision computation, aggressive fusion, optimization for static tensor shapes and memory layout, constant weight optimization, and memory buffer reuse. Experimental results demonstrate up to 2x performance gains over primitives-based optimization for performance-critical DNN computation graph patterns on Intel Xeon Scalable Processors.
Predicate correlation learning for scene graph generation
Jul 06, 2021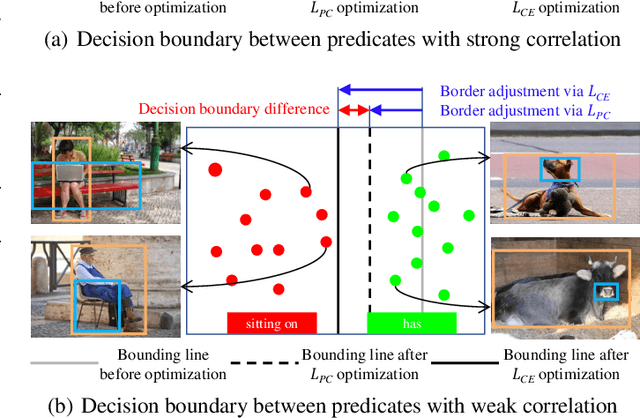
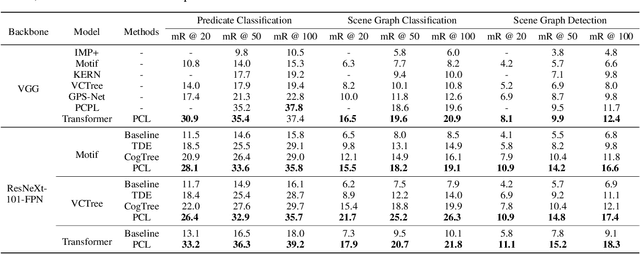
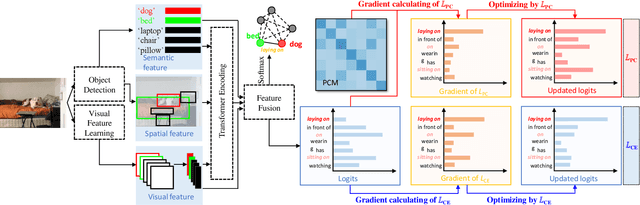
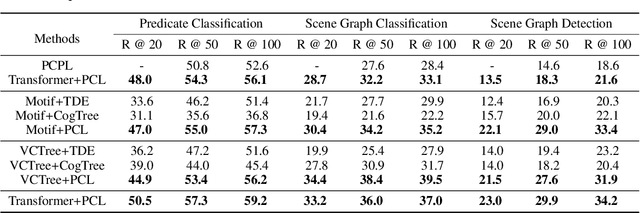
For a typical Scene Graph Generation (SGG) method, there is often a large gap in the performance of the predicates' head classes and tail classes. This phenomenon is mainly caused by the semantic overlap between different predicates as well as the long-tailed data distribution. In this paper, a Predicate Correlation Learning (PCL) method for SGG is proposed to address the above two problems by taking the correlation between predicates into consideration. To describe the semantic overlap between strong-correlated predicate classes, a Predicate Correlation Matrix (PCM) is defined to quantify the relationship between predicate pairs, which is dynamically updated to remove the matrix's long-tailed bias. In addition, PCM is integrated into a Predicate Correlation Loss function ($L_{PC}$) to reduce discouraging gradients of unannotated classes. The proposed method is evaluated on Visual Genome benchmark, where the performance of the tail classes is significantly improved when built on the existing methods.
Multiple Video Frame Interpolation via Enhanced Deformable Separable Convolution
Jun 15, 2020
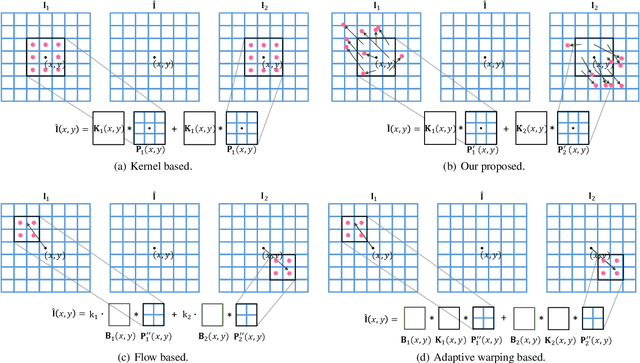

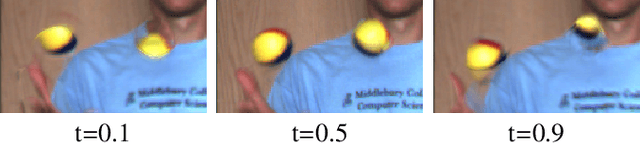
Generating non-existing frames from a consecutive video sequence has been an interesting and challenging problem in the video processing field. Recent kernel-based interpolation methods predict pixels with a single convolution process that convolves source frames with spatially adaptive local kernels. However, when scene motion is larger than the pre-defined kernel size, these methods are prone to yield less plausible results and they cannot directly generate a frame at an arbitrary temporal position because the learned kernels are tied to the midpoint in time between the input frames. In this paper, we try to solve these problems and propose a novel approach that we refer to as enhanced deformable separable convolution (EDSC) to estimate not only adaptive kernels, but also offsets, masks and biases to make the network obtain information from non-local neighborhood. During the learning process, different intermediate time step can be involved as a control variable by means of the coord-conv trick, allowing the estimated components to vary with different input temporal information. This makes our method capable to produce multiple in-between frames. Furthermore, we investigate the relationships between our method and other typical kernel- and flow-based methods. Experimental results show that our method performs favorably against the state-of-the-art methods across a broad range of datasets. Code will be publicly available on URL: \url{https://github.com/Xianhang/EDSC-pytorch}.