 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttriBoT: A Bag of Tricks for Efficiently Approximating Leave-One-Out Context Attribution
Nov 22, 2024



The influence of contextual input on the behavior of large language models (LLMs) has prompted the development of context attribution methods that aim to quantify each context span's effect on an LLM's generations. The leave-one-out (LOO) error, which measures the change in the likelihood of the LLM's response when a given span of the context is removed, provides a principled way to perform context attribution, but can be prohibitively expensive to compute for large models. In this work, we introduce AttriBoT, a series of novel techniques for efficiently computing an approximation of the LOO error for context attribution. Specifically, AttriBoT uses cached activations to avoid redundant operations, performs hierarchical attribution to reduce computation, and emulates the behavior of large target models with smaller proxy models. Taken together, AttriBoT can provide a >300x speedup while remaining more faithful to a target model's LOO error than prior context attribution methods. This stark increase in performance makes computing context attributions for a given response 30x faster than generating the response itself, empowering real-world applications that require computing attributions at scale. We release a user-friendly and efficient implementation of AttriBoT to enable efficient LLM interpretability as well as encourage future development of efficient context attribution methods.
Realistic Evaluation of Model Merging for Compositional Generalization
Sep 26, 2024Merging has become a widespread way to cheaply combine individual models into a single model that inherits their capabilities and attains better performance. This popularity has spurred rapid development of many new merging methods, which are typically validated in disparate experimental settings and frequently differ in the assumptions made about model architecture, data availability, and computational budget. In this work, we characterize the relative merits of different merging methods by evaluating them in a shared experimental setting and precisely identifying the practical requirements of each method. Specifically, our setting focuses on using merging for compositional generalization of capabilities in image classification, image generation, and natural language processing. Additionally, we measure the computational costs of different merging methods as well as how they perform when scaling the number of models being merged. Taken together, our results clarify the state of the field of model merging and provide a comprehensive and rigorous experimental setup to test new methods.
A Survey on Model MoErging: Recycling and Routing Among Specialized Experts for Collaborative Learning
Aug 13, 2024
The availability of performant pre-trained models has led to a proliferation of fine-tuned expert models that are specialized to a particular domain or task. Model MoErging methods aim to recycle expert models to create an aggregate system with improved performance or generalization. A key component of MoErging methods is the creation of a router that decides which expert model(s) to use for a particular input or application. The promise, effectiveness, and large design space of MoErging has spurred the development of many new methods over the past few years. This rapid pace of development has made it challenging to compare different MoErging methods, which are rarely compared to one another and are often validated in different experimental setups. To remedy such gaps, we present a comprehensive survey of MoErging methods that includes a novel taxonomy for cataloging key design choices and clarifying suitable applications for each method. Apart from surveying MoErging research, we inventory software tools and applications that make use of MoErging. We additionally discuss related fields of study such as model merging, multitask learning, and mixture-of-experts models. Taken as a whole, our survey provides a unified overview of existing MoErging methods and creates a solid foundation for future work in this burgeoning field.
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Jun 25, 2024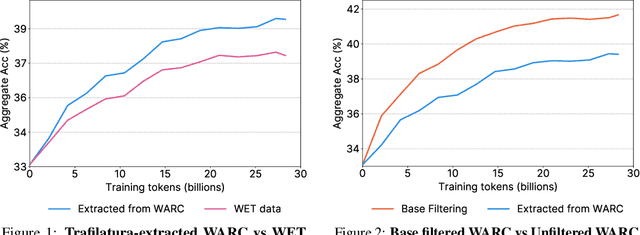
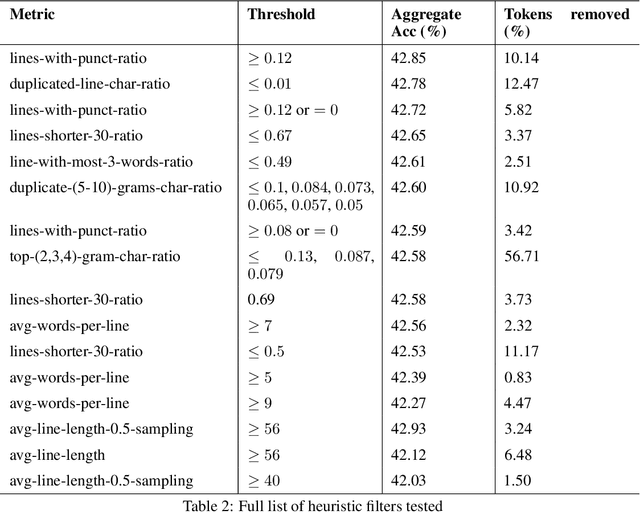
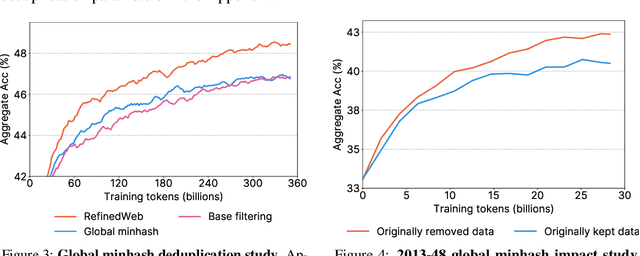
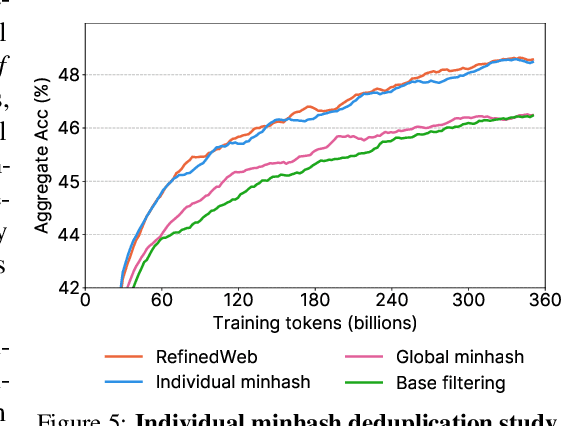
The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3 and Mixtral are not publicly available and very little is known about how they were created. In this work, we introduce FineWeb, a 15-trillion token dataset derived from 96 Common Crawl snapshots that produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies. In addition, we introduce FineWeb-Edu, a 1.3-trillion token collection of educational text filtered from FineWeb. LLMs pretrained on FineWeb-Edu exhibit dramatically better performance on knowledge- and reasoning-intensive benchmarks like MMLU and ARC. Along with our datasets, we publicly release our data curation codebase and all of the models trained during our ablation experiments.
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Apr 08, 2024



Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$\times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$\times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86\times$ faster than similar dense models like Mistral-7B, and between $1.50\times$ and $1.71\times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
A Survey on Data Selection for Language Models
Mar 08, 2024A major factor in the recent success of large language models is the use of enormous and ever-growing text datasets for unsupervised pre-training. However, naively training a model on all available data may not be optimal (or feasible), as the quality of available text data can vary. Filtering out data can also decrease the carbon footprint and financial costs of training models by reducing the amount of training required. Data selection methods aim to determine which candidate data points to include in the training dataset and how to appropriately sample from the selected data points. The promise of improved data selection methods has caused the volume of research in the area to rapidly expand. However, because deep learning is mostly driven by empirical evidence and experimentation on large-scale data is expensive, few organizations have the resources for extensive data selection research. Consequently, knowledge of effective data selection practices has become concentrated within a few organizations, many of which do not openly share their findings and methodologies. To narrow this gap in knowledge, we present a comprehensive review of existing literature on data selection methods and related research areas, providing a taxonomy of existing approaches. By describing the current landscape of research, this work aims to accelerate progress in data selection by establishing an entry point for new and established researchers. Additionally, throughout this review we draw attention to noticeable holes in the literature and conclude the paper by proposing promising avenues for future research.
DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows
Feb 16, 2024Large language models (LLMs) have become a dominant and important tool for NLP researchers in a wide range of tasks. Today, many researchers use LLMs in synthetic data generation, task evaluation, fine-tuning, distillation, and other model-in-the-loop research workflows. However, challenges arise when using these models that stem from their scale, their closed source nature, and the lack of standardized tooling for these new and emerging workflows. The rapid rise to prominence of these models and these unique challenges has had immediate adverse impacts on open science and on the reproducibility of work that uses them. In this paper, we introduce DataDreamer, an open source Python library that allows researchers to write simple code to implement powerful LLM workflows. DataDreamer also helps researchers adhere to best practices that we propose to encourage open science and reproducibility. The library and documentation are available at https://github.com/datadreamer-dev/DataDreamer .
Learning to Route Among Specialized Experts for Zero-Shot Generalization
Feb 08, 2024



Recently, there has been a widespread proliferation of "expert" language models that are specialized to a specific task or domain through parameter-efficient fine-tuning. How can we recycle large collections of expert language models to improve zero-shot generalization to unseen tasks? In this work, we propose Post-Hoc Adaptive Tokenwise Gating Over an Ocean of Specialized Experts (PHATGOOSE), which learns to route among specialized modules that were produced through parameter-efficient fine-tuning. Unlike past methods that learn to route among specialized models, PHATGOOSE explores the possibility that zero-shot generalization will be improved if different experts can be adaptively chosen for each token and at each layer in the model. Crucially, our method is post-hoc - it does not require simultaneous access to the datasets used to create the specialized models and only requires a modest amount of additional compute after each expert model is trained. In experiments covering a range of specialized model collections and zero-shot generalization benchmarks, we find that PHATGOOSE outperforms past methods for post-hoc routing and, in some cases, outperforms explicit multitask training (which requires simultaneous data access). To better understand the routing strategy learned by PHATGOOSE, we perform qualitative experiments to validate that PHATGOOSE's performance stems from its ability to make adaptive per-token and per-module expert choices. We release all of our code to support future work on improving zero-shot generalization by recycling specialized experts.
Distributed Inference and Fine-tuning of Large Language Models Over The Internet
Dec 13, 2023



Large language models (LLMs) are useful in many NLP tasks and become more capable with size, with the best open-source models having over 50 billion parameters. However, using these 50B+ models requires high-end hardware, making them inaccessible to most researchers. In this work, we investigate methods for cost-efficient inference and fine-tuning of LLMs, comparing local and distributed strategies. We observe that a large enough model (50B+) can run efficiently even on geodistributed devices in a consumer-grade network. This could allow running LLM efficiently by pooling together idle compute resources of multiple research groups and volunteers. We address two open problems: (1) how to perform inference and fine-tuning reliably if any device can disconnect abruptly and (2) how to partition LLMs between devices with uneven hardware, joining and leaving at will. In order to do that, we develop special fault-tolerant inference algorithms and load-balancing protocols that automatically assign devices to maximize the total system throughput. We showcase these algorithms in Petals - a decentralized system that runs Llama 2 (70B) and BLOOM (176B) over the Internet up to 10x faster than offloading for interactive generation. We evaluate the performance of our system in simulated conditions and a real-world setup spanning two continents.
Merging by Matching Models in Task Subspaces
Dec 07, 2023Model merging aims to cheaply combine individual task-specific models into a single multitask model. In this work, we view past merging methods as leveraging different notions of a ''task subspace'' in which models are matched before being merged. We connect the task subspace of a given model to its loss landscape and formalize how this approach to model merging can be seen as solving a linear system of equations. While past work has generally been limited to linear systems that have a closed-form solution, we consider using the conjugate gradient method to find a solution. We show that using the conjugate gradient method can outperform closed-form solutions, enables merging via linear systems that are otherwise intractable to solve, and flexibly allows choosing from a wide variety of initializations and estimates for the ''task subspace''. We ultimately demonstrate that our merging framework called ''Matching Models in their Task Subspace'' (MaTS) achieves state-of-the-art results in multitask and intermediate-task model merging. We release all of the code and checkpoints used in our work at https://github.com/r-three/mats.