 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Teaching Machines to Read and Comprehend with Large-Scale Multi-Subject Question Answering Data
Feb 01, 2021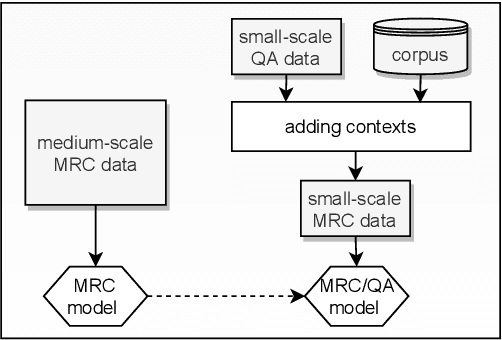
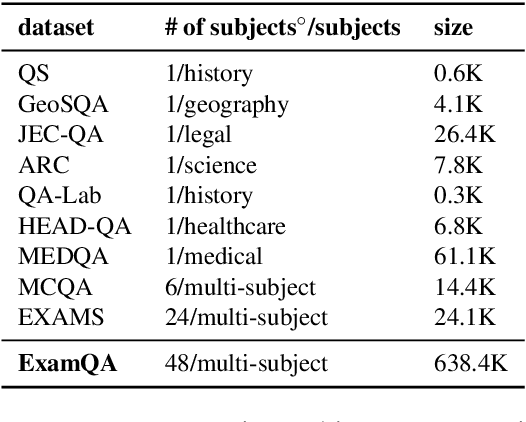

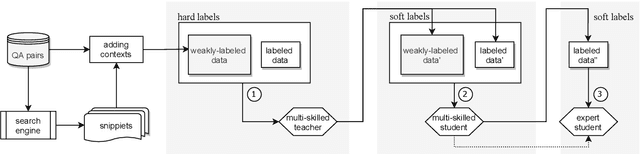
In spite of much recent research in the area, it is still unclear whether subject-area question-answering data is useful for machine reading comprehension (MRC) tasks. In this paper, we investigate this question. We collect a large-scale multi-subject multiple-choice question-answering dataset, ExamQA, and use incomplete and noisy snippets returned by a web search engine as the relevant context for each question-answering instance to convert it into a weakly-labeled MRC instance. We then propose a self-teaching paradigm to better use the generated weakly-labeled MRC instances to improve a target MRC task. Experimental results show that we can obtain an improvement of 5.1% in accuracy on a multiple-choice MRC dataset, C^3, demonstrating the effectiveness of our framework and the usefulness of large-scale subject-area question-answering data for machine reading comprehension.
Intentonomy: a Dataset and Study towards Human Intent Understanding
Nov 11, 2020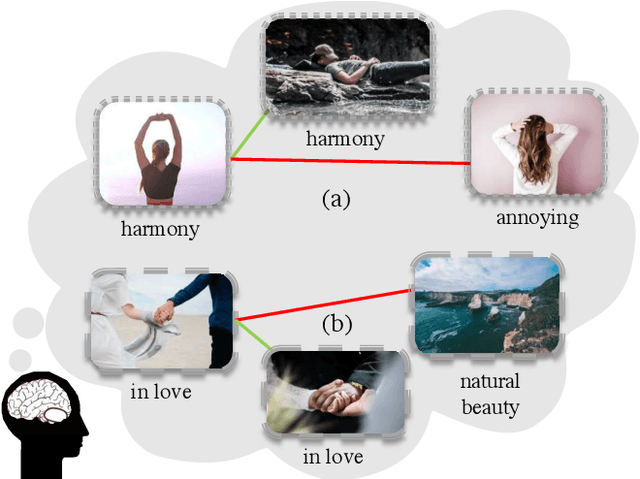

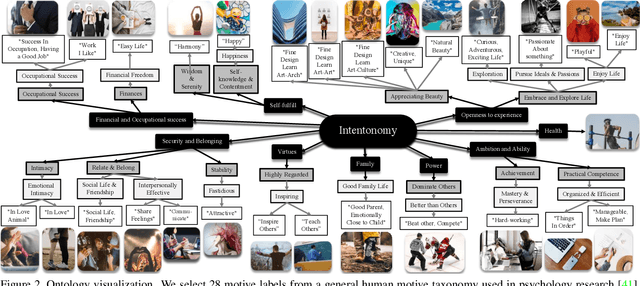
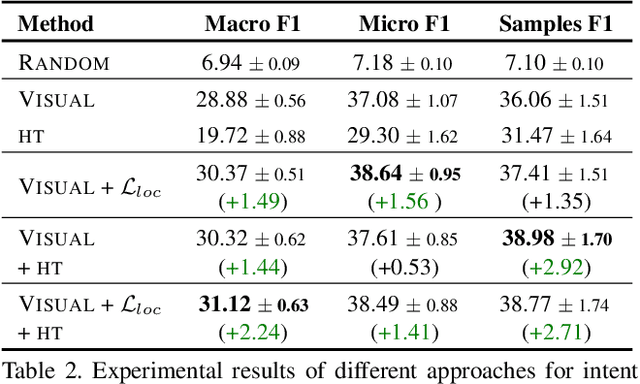
An image is worth a thousand words, conveying information that goes beyond the mere visual content therein. In this paper, we study the intent behind social media images with an aim to analyze how visual information can facilitate recognition of human intent. Towards this goal, we introduce an intent dataset, Intentonomy, comprising 14K images covering a wide range of everyday scenes. These images are manually annotated with 28 intent categories derived from a social psychology taxonomy. We then systematically study whether, and to what extent, commonly used visual information, i.e., object and context, contribute to human motive understanding. Based on our findings, we conduct further study to quantify the effect of attending to object and context classes as well as textual information in the form of hashtags when training an intent classifier. Our results quantitatively and qualitatively shed light on how visual and textual information can produce observable effects when predicting intent.
Improving Event Duration Prediction via Time-aware Pre-training
Nov 05, 2020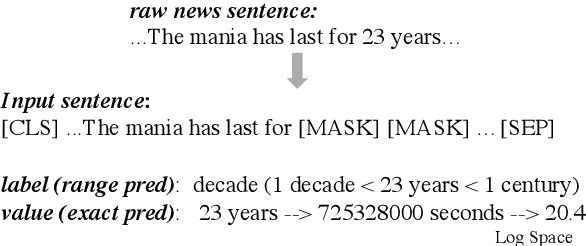
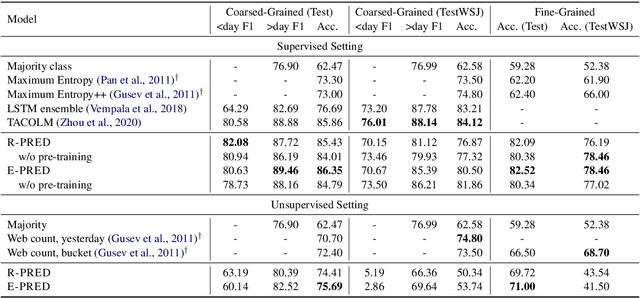
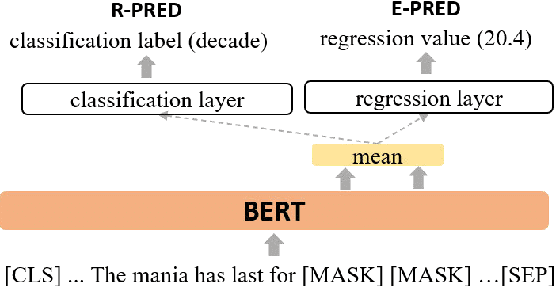
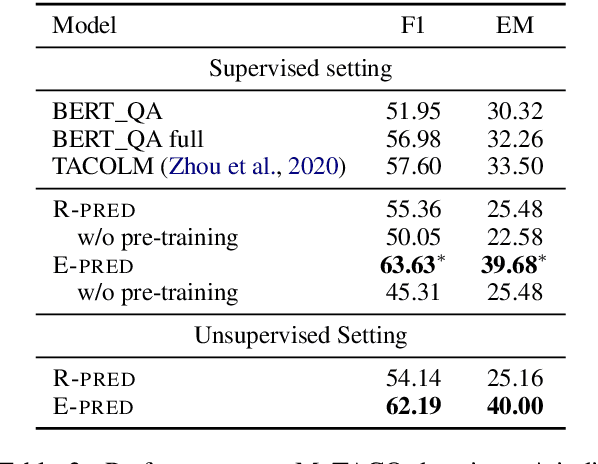
End-to-end models in NLP rarely encode external world knowledge about length of time. We introduce two effective models for duration prediction, which incorporate external knowledge by reading temporal-related news sentences (time-aware pre-training). Specifically, one model predicts the range/unit where the duration value falls in (R-pred); and the other predicts the exact duration value E-pred. Our best model -- E-pred, substantially outperforms previous work, and captures duration information more accurately than R-pred. We also demonstrate our models are capable of duration prediction in the unsupervised setting, outperforming the baselines.
Adding Chit-Chats to Enhance Task-Oriented Dialogues
Oct 24, 2020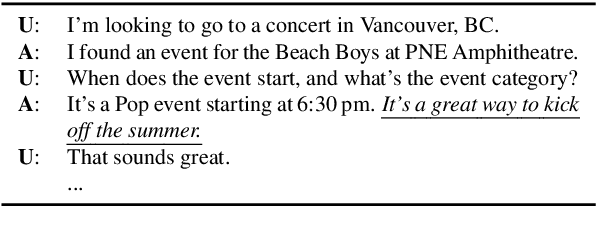
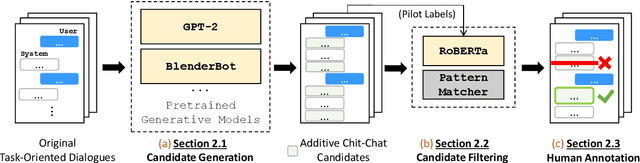
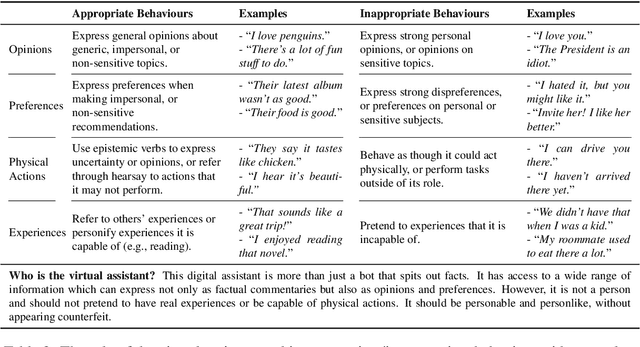
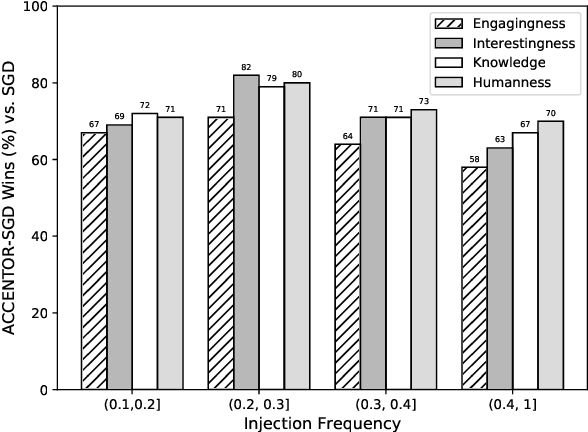
The existing dialogue corpora and models are typically designed under two disjoint motives: while task-oriented systems focus on achieving functional goals (e.g., booking hotels), open-domain chatbots aim at making socially engaging conversations. In this work, we propose to integrate both types of systems by Adding Chit-Chats to ENhance Task-ORiented dialogues (ACCENTOR), with the goal of making virtual assistant conversations more engaging and interactive. Specifically, we propose a flexible approach for generating diverse chit-chat responses to augment task-oriented dialogues with minimal annotation effort. We then present our new chit-chat annotations to 23.8K dialogues from the popular task-oriented datasets (Schema-Guided Dialogue and MultiWOZ 2.1) and demonstrate their advantage over the originals via human evaluation. Lastly, we propose three new models for ACCENTOR explicitly trained to predict user goals and to generate contextually relevant chit-chat responses. Automatic and human evaluations show that, compared with the state-of-the-art task-oriented baseline, our models can code-switch between task and chit-chat to be more engaging, interesting, knowledgeable, and humanlike, while maintaining competitive task performance.
Exploring the Role of Argument Structure in Online Debate Persuasion
Oct 07, 2020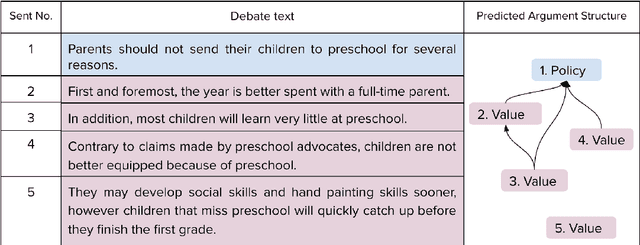

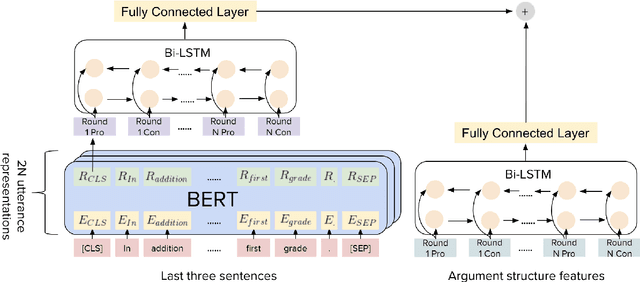
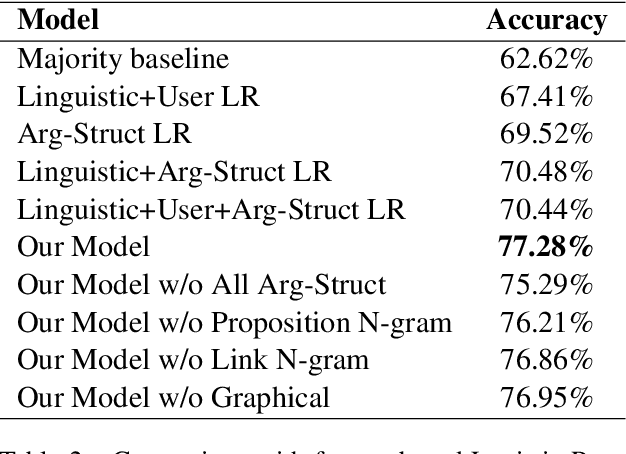
Online debate forums provide users a platform to express their opinions on controversial topics while being exposed to opinions from diverse set of viewpoints. Existing work in Natural Language Processing (NLP) has shown that linguistic features extracted from the debate text and features encoding the characteristics of the audience are both critical in persuasion studies. In this paper, we aim to further investigate the role of discourse structure of the arguments from online debates in their persuasiveness. In particular, we use the factor graph model to obtain features for the argument structure of debates from an online debating platform and incorporate these features to an LSTM-based model to predict the debater that makes the most convincing arguments. We find that incorporating argument structure features play an essential role in achieving the better predictive performance in assessing the persuasiveness of the arguments in online debates.
WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization
Oct 07, 2020


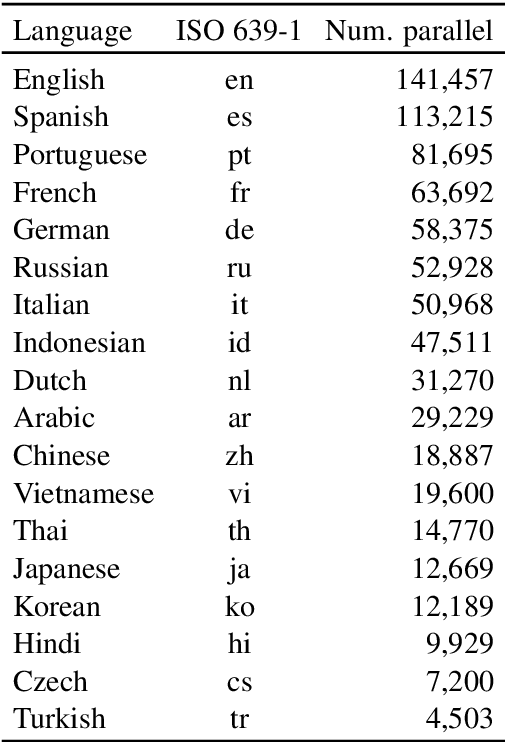
We introduce WikiLingua, a large-scale, multilingual dataset for the evaluation of crosslingual abstractive summarization systems. We extract article and summary pairs in 18 languages from WikiHow, a high quality, collaborative resource of how-to guides on a diverse set of topics written by human authors. We create gold-standard article-summary alignments across languages by aligning the images that are used to describe each how-to step in an article. As a set of baselines for further studies, we evaluate the performance of existing cross-lingual abstractive summarization methods on our dataset. We further propose a method for direct crosslingual summarization (i.e., without requiring translation at inference time) by leveraging synthetic data and Neural Machine Translation as a pre-training step. Our method significantly outperforms the baseline approaches, while being more cost efficient during inference.
Improving Machine Reading Comprehension with Contextualized Commonsense Knowledge
Sep 12, 2020
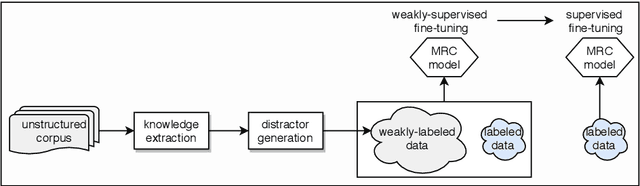
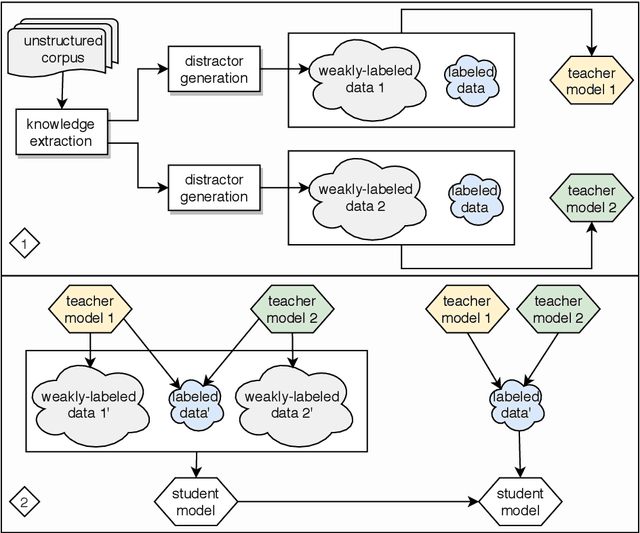
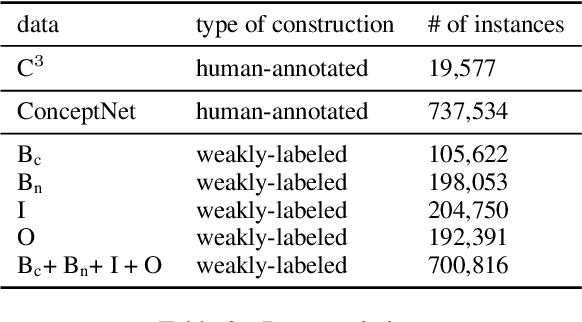
In this paper, we aim to extract commonsense knowledge to improve machine reading comprehension. We propose to represent relations implicitly by situating structured knowledge in a context instead of relying on a pre-defined set of relations, and we call it contextualized knowledge. Each piece of contextualized knowledge consists of a pair of interrelated verbal and nonverbal messages extracted from a script and the scene in which they occur as context to implicitly represent the relation between the verbal and nonverbal messages, which are originally conveyed by different modalities within the script. We propose a two-stage fine-tuning strategy to use the large-scale weakly-labeled data based on a single type of contextualized knowledge and employ a teacher-student paradigm to inject multiple types of contextualized knowledge into a student machine reader. Experimental results demonstrate that our method outperforms a state-of-the-art baseline by a 4.3% improvement in accuracy on the machine reading comprehension dataset C^3, wherein most of the questions require unstated prior knowledge.
Document-level Event-based Extraction Using Generative Template-filling Transformers
Aug 21, 2020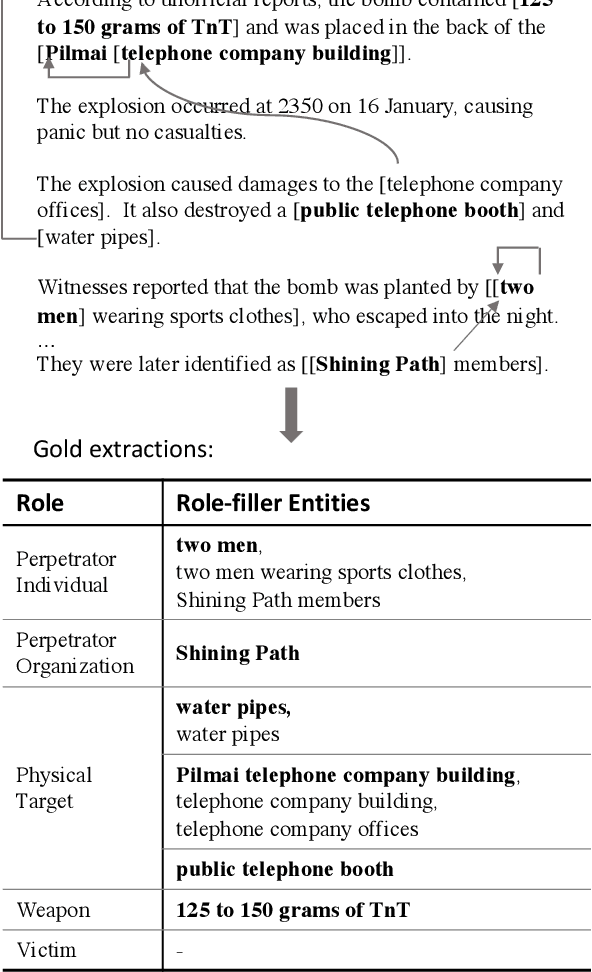

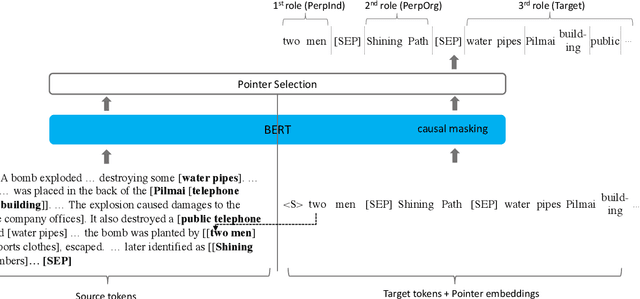
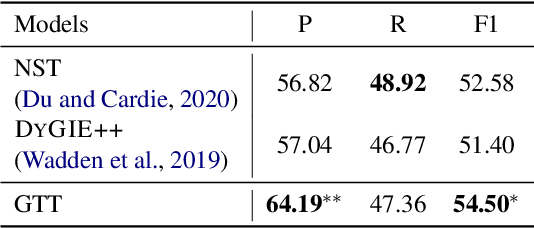
We revisit the classic information extraction problem of document-level template filling. We argue that sentence-level approaches are ill-suited to the task and introduce a generative transformer-based encoder-decoder framework that is designed to model context at the document level: it can make extraction decisions across sentence boundaries; is \emph{implicitly} aware of noun phrase coreference structure, and has the capacity to respect cross-role dependencies in the template structure. We evaluate our approach on the MUC-4 dataset, and show that our model performs substantially better than prior work. We also show that our modeling choices contribute to model performance, e.g., by implicitly capturing linguistic knowledge such as recognizing coreferent entity mentions. Our code for the evaluation script and models will be open-sourced at https://github.com/xinyadu/doc_event_entity for reproduction purposes.
Document-Level Event Role Filler Extraction using Multi-Granularity Contextualized Encoding
May 13, 2020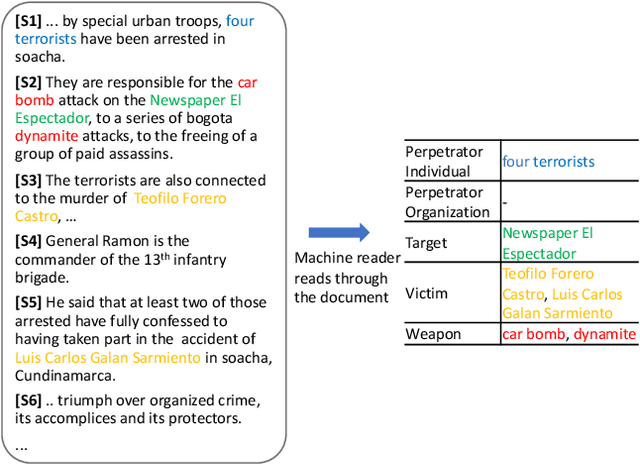
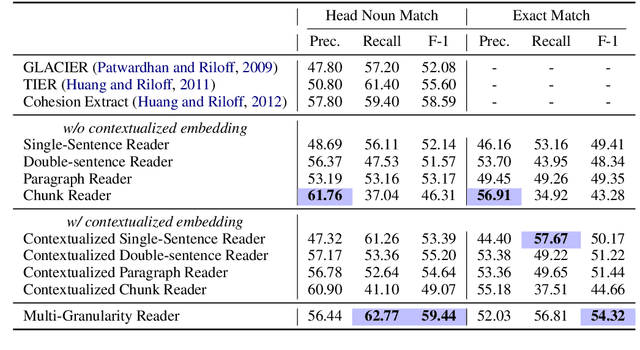
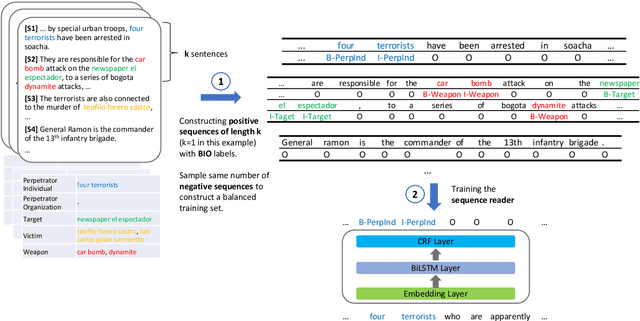
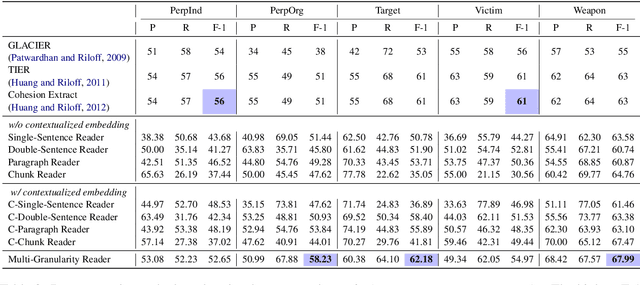
Few works in the literature of event extraction have gone beyond individual sentences to make extraction decisions. This is problematic when the information needed to recognize an event argument is spread across multiple sentences. We argue that document-level event extraction is a difficult task since it requires a view of a larger context to determine which spans of text correspond to event role fillers. We first investigate how end-to-end neural sequence models (with pre-trained language model representations) perform on document-level role filler extraction, as well as how the length of context captured affects the models' performance. To dynamically aggregate information captured by neural representations learned at different levels of granularity (e.g., the sentence- and paragraph-level), we propose a novel multi-granularity reader. We evaluate our models on the MUC-4 event extraction dataset, and show that our best system performs substantially better than prior work. We also report findings on the relationship between context length and neural model performance on the task.
Event Extraction by Answering (Almost) Natural Questions
Apr 28, 2020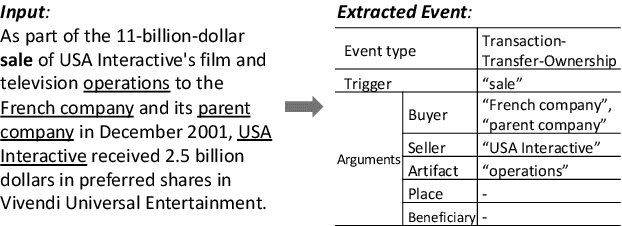

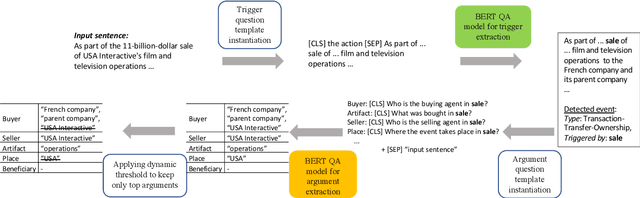
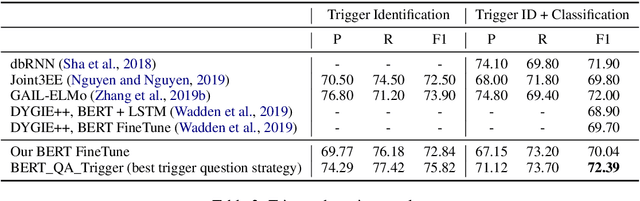
The problem of event extraction requires detecting the event trigger and extracting its corresponding arguments. Existing work in event argument extraction typically relies heavily on entity recognition as a preprocessing/concurrent step, causing the well-known problem of error propagation. To avoid this issue, we introduce a new paradigm for event extraction by formulating it as a question answering (QA) task, which extracts the event arguments in an end-to-end manner. Empirical results demonstrate that our framework outperforms prior methods substantially; in addition, it is capable of extracting event arguments for roles not seen at training time (zero-shot learning setting).