 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Resource Multilingual Model Transfer: Learning What to Share
Paper and Code
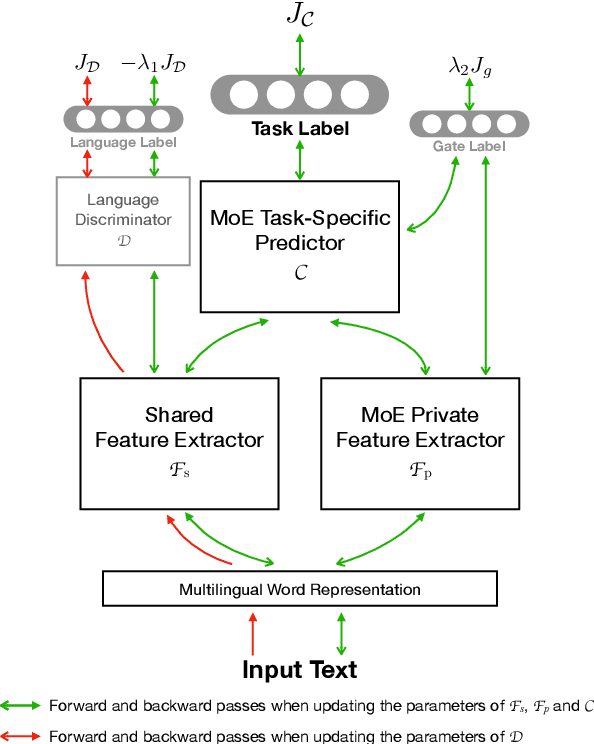
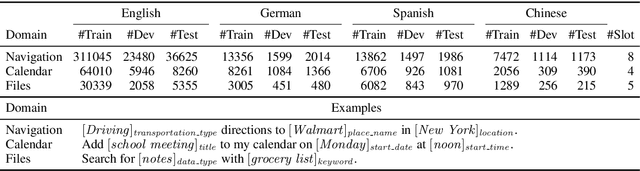
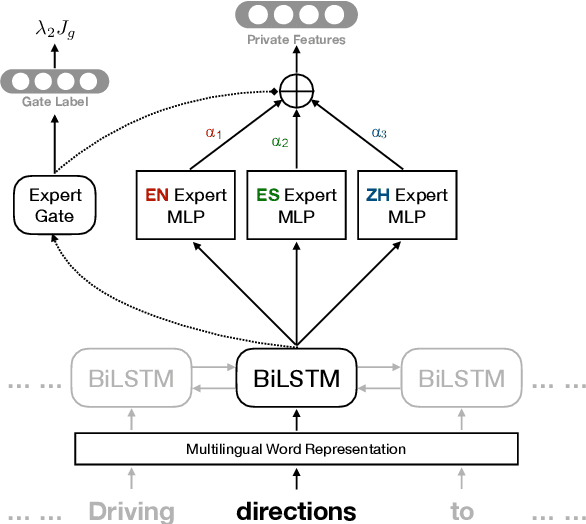
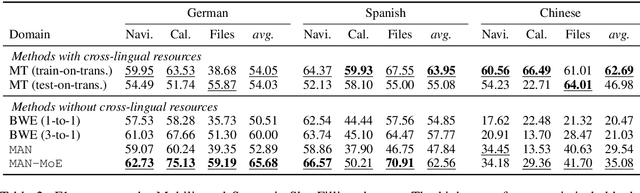
Modern natural language processing and understanding applications have enjoyed a great boost utilizing neural networks models. However, this is not the case for most languages especially low-resource ones with insufficient annotated training data. Cross-lingual transfer learning methods improve the performance on a low-resource target language by leveraging labeled data from other (source) languages, typically with the help of cross-lingual resources such as parallel corpora. In this work, we propose the first zero-resource multilingual transfer learning model that can utilize training data in multiple source languages, while not requiring target language training data nor cross-lingual supervision. Unlike existing methods that only rely on language-invariant features for cross-lingual transfer, our approach utilizes both language-invariant and language-specific features in a coherent way. Our model leverages adversarial networks to learn language-invariant features and mixture-of-experts models to dynamically exploit the relation between the target language and each individual source language. This enables our model to learn effectively what to share between various languages in the multilingual setup. It results in significant performance gains over prior art, as shown in an extensive set of experiments over multiple text classification and sequence tagging tasks including a large-scale real-world industry dataset.