 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Prior Knowledge Needed in Challenging Chinese Machine Reading Comprehension
Paper and Code



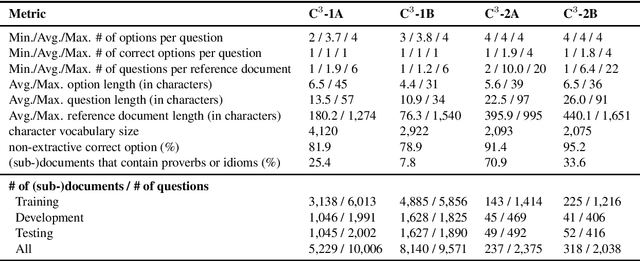
With an ultimate goal of narrowing the gap between human and machine readers in text comprehension, we present the first collection of Challenging Chinese machine reading Comprehension datasets (C^3) collected from language and professional certification exams, which contains 13,924 documents and their associated 23,990 multiple-choice questions. Most of the questions in C^3 cannot be answered merely by surface-form matching against the given text. As a pilot study, we closely analyze the prior knowledge (i.e., linguistic, domain-specific, and general world knowledge) needed in these real-world reading comprehension tasks. We further explore how to leverage linguistic knowledge including a lexicon of idioms and proverbs, graphs of general world knowledge (e.g., ConceptNet), and domain-specific knowledge such as textbooks to aid machine readers, through fine-tuning a pre-trained language model. Experimental results demonstrate that linguistic and general world knowledge may help improve the performance of the baseline reader in both general and domain-specific tasks. C^3 will be available at http://dataset.org/c3/.