Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Dynamic Computation Graphs via Sparse Latent Structure
Paper and Code
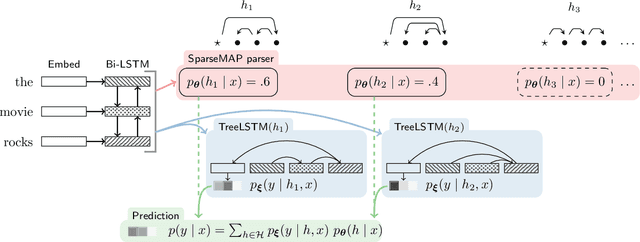
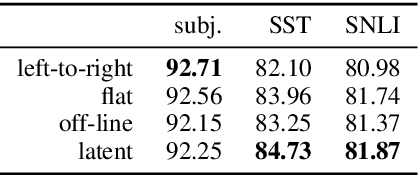
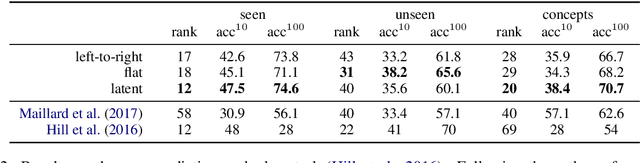
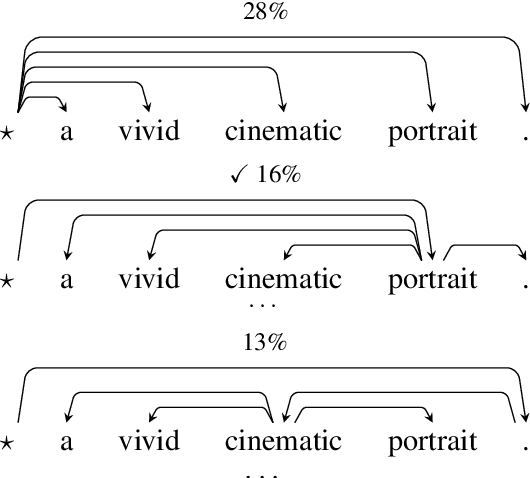
Deep NLP models benefit from underlying structures in the data---e.g., parse trees---typically extracted using off-the-shelf parsers. Recent attempts to jointly learn the latent structure encounter a tradeoff: either make factorization assumptions that limit expressiveness, or sacrifice end-to-end differentiability. Using the recently proposed SparseMAP inference, which retrieves a sparse distribution over latent structures, we propose a novel approach for end-to-end learning of latent structure predictors jointly with a downstream predictor. To the best of our knowledge, our method is the first to enable unrestricted dynamic computation graph construction from the global latent structure, while maintaining differentiability.
* EMNLP 2018; 9 pages (incl. appendix)
View paper on