 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-training with progressive augmentation for unsupervised cross-domain person re-identification
Jul 31, 2019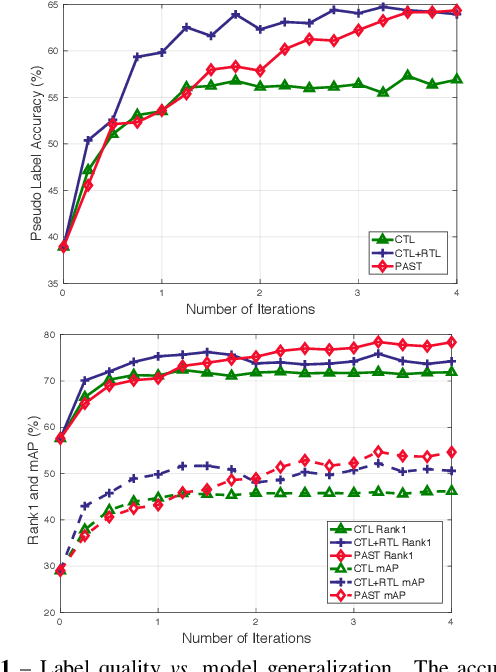
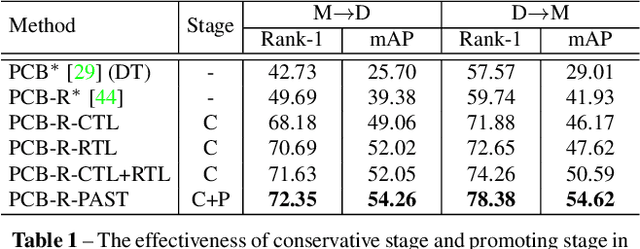
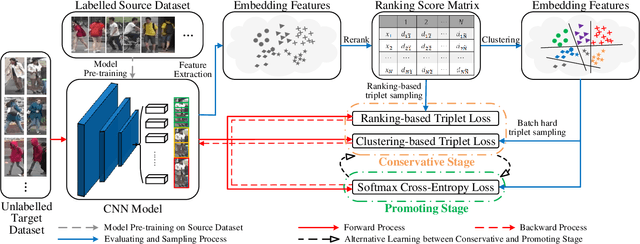
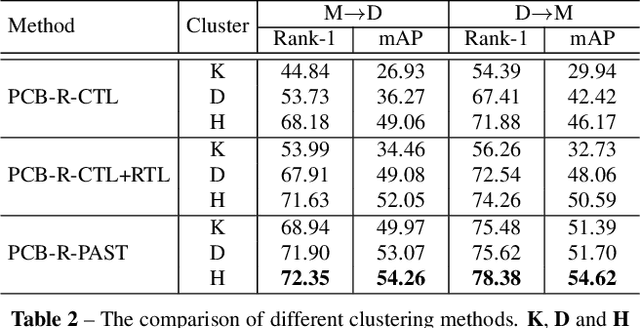
Person re-identification (Re-ID) has achieved great improvement with deep learning and a large amount of labelled training data. However, it remains a challenging task for adapting a model trained in a source domain of labelled data to a target domain of only unlabelled data available. In this work, we develop a self-training method with progressive augmentation framework (PAST) to promote the model performance progressively on the target dataset. Specially, our PAST framework consists of two stages, namely, conservative stage and promoting stage. The conservative stage captures the local structure of target-domain data points with triplet-based loss functions, leading to improved feature representations. The promoting stage continuously optimizes the network by appending a changeable classification layer to the last layer of the model, enabling the use of global information about the data distribution. Importantly, we propose a new self-training strategy that progressively augments the model capability by adopting conservative and promoting stages alternately. Furthermore, to improve the reliability of selected triplet samples, we introduce a ranking-based triplet loss in the conservative stage, which is a label-free objective function basing on the similarities between data pairs. Experiments demonstrate that the proposed method achieves state-of-the-art person Re-ID performance under the unsupervised cross-domain setting. Code is available at: https://tinyurl.com/PASTReID
Regularizing Proxies with Multi-Adversarial Training for Unsupervised Domain-Adaptive Semantic Segmentation
Jul 29, 2019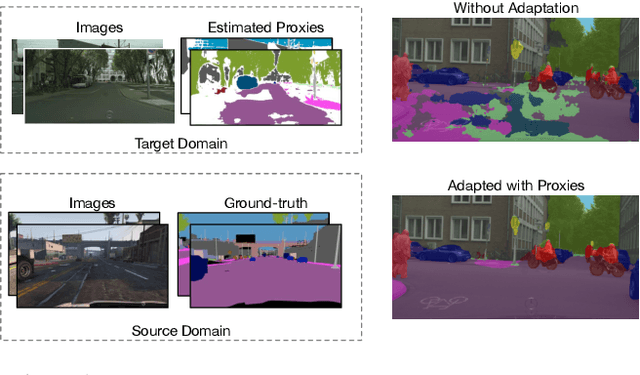
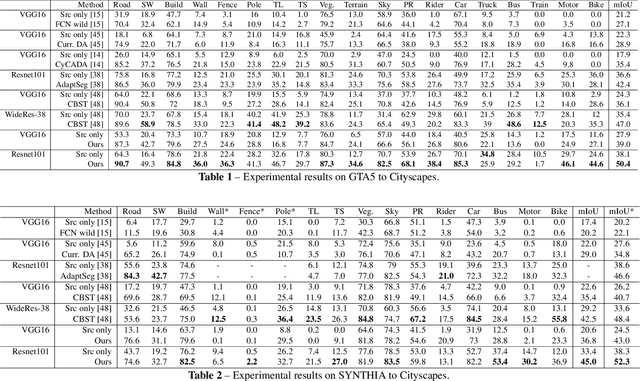
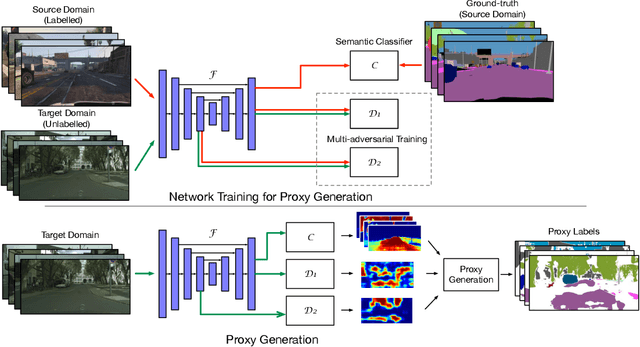
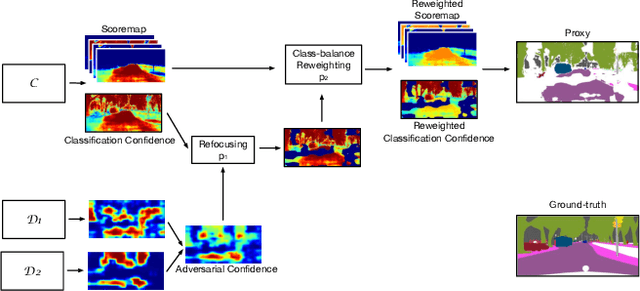
Training a semantic segmentation model requires a large amount of pixel-level annotation, hampering its application at scale. With computer graphics, we can generate almost unlimited training data with precise annotation. However,a deep model trained with synthetic data usually cannot directly generalize well to realistic images due to domain shift. It has been observed that highly confident labels for the unlabeled real images may be predicted relying on the labeled synthetic data. To tackle the unsupervised domain adaptation problem, we explore the possibilities to generate high-quality labels as proxy labels to supervise the training on target data. Specifically, we propose a novel proxy-based method using multi-adversarial training. We first train the model using synthetic data (source domain). Multiple discriminators are used to align the features be-tween the source and target domain (real images) at different levels. Then we focus on obtaining and selecting high-quality proxy labels by incorporating both the confidence of the class predictor and that from the adversarial discriminators. Our discriminators not only work as a regularizer to encourage feature alignment but also provide an alternative confidence measure for generating proxy labels. Relying on the generated high-quality proxies, our model can be trained in a "supervised manner" on the target do-main. On two major tasks, GTA5->Cityscapes and SYNTHIA->Cityscapes, our method achieves state-of-the-art results, outperforming the previous by a large margin.
V-PROM: A Benchmark for Visual Reasoning Using Visual Progressive Matrices
Jul 29, 2019
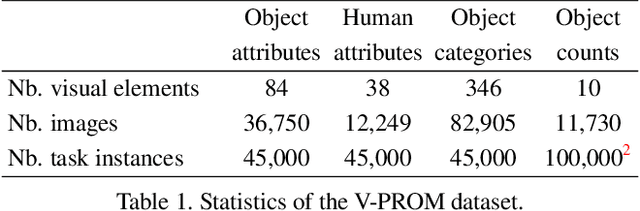

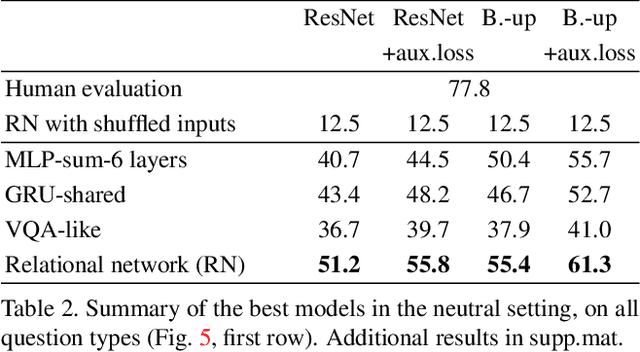
One of the primary challenges faced by deep learning is the degree to which current methods exploit superficial statistics and dataset bias, rather than learning to generalise over the specific representations they have experienced. This is a critical concern because generalisation enables robust reasoning over unseen data, whereas leveraging superficial statistics is fragile to even small changes in data distribution. To illuminate the issue and drive progress towards a solution, we propose a test that explicitly evaluates abstract reasoning over visual data. We introduce a large-scale benchmark of visual questions that involve operations fundamental to many high-level vision tasks, such as comparisons of counts and logical operations on complex visual properties. The benchmark directly measures a method's ability to infer high-level relationships and to generalise them over image-based concepts. It includes multiple training/test splits that require controlled levels of generalization. We evaluate a range of deep learning architectures, and find that existing models, including those popular for vision-and-language tasks, are unable to solve seemingly-simple instances. Models using relational networks fare better but leave substantial room for improvement.
A Generalized Framework for Edge-preserving and Structure-preserving Image Smoothing
Jul 23, 2019
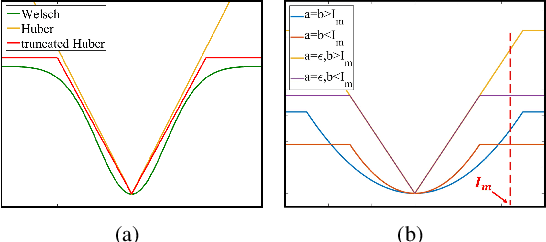

Image smoothing is a fundamental procedure in applications of both computer vision and graphics. The required smoothing properties can be different or even contradictive among different tasks. Nevertheless, the inherent smoothing nature of one smoothing operator is usually fixed and thus cannot meet the various requirements of different applications. In this paper, a non-convex non-smooth optimization framework is proposed to achieve diverse smoothing natures where even contradictive smoothing behaviors can be achieved. To this end, we first introduce the truncated Huber penalty function which has seldom been used in image smoothing. A robust framework is then proposed. When combined with the strong flexibility of the truncated Huber penalty function, our framework is capable of a range of applications and can outperform the state-of-the-art approaches in several tasks. In addition, an efficient numerical solution is provided and its convergence is theoretically guaranteed even the optimization framework is non-convex and non-smooth. The effectiveness and superior performance of our approach are validated through comprehensive experimental results in a range of applications.
Towards End-to-End Text Spotting in Natural Scenes
Jun 17, 2019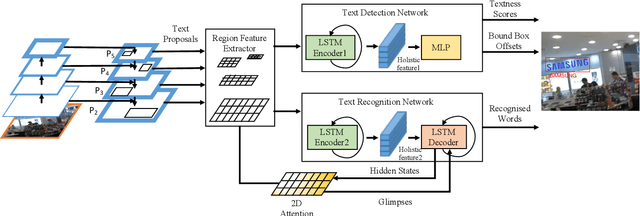
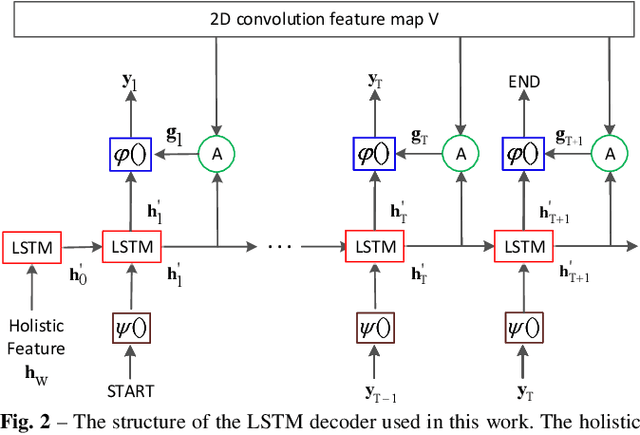


Text spotting in natural scene images is of great importance for many image understanding tasks. It includes two sub-tasks: text detection and recognition. In this work, we propose a unified network that simultaneously localizes and recognizes text with a single forward pass, avoiding intermediate processes such as image cropping and feature re-calculation, word separation, and character grouping. In contrast to existing approaches that consider text detection and recognition as two distinct tasks and tackle them one by one, the proposed framework settles these two tasks concurrently. The whole framework can be trained end-to-end and is able to handle text of arbitrary shapes. The convolutional features are calculated only once and shared by both detection and recognition modules. Through multi-task training, the learned features become more discriminate and improve the overall performance. By employing the $2$D attention model in word recognition, the irregularity of text can be robustly addressed. It provides the spatial location for each character, which not only helps local feature extraction in word recognition, but also indicates an orientation angle to refine text localization. Our proposed method has achieved state-of-the-art performance on several standard text spotting benchmarks, including both regular and irregular ones.
NAS-FCOS: Fast Neural Architecture Search for Object Detection
Jun 12, 2019

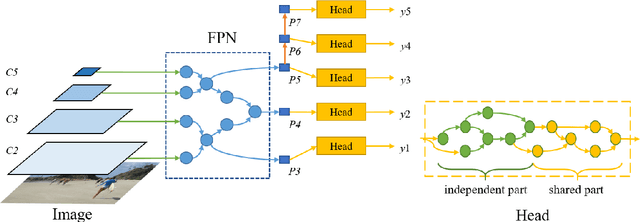
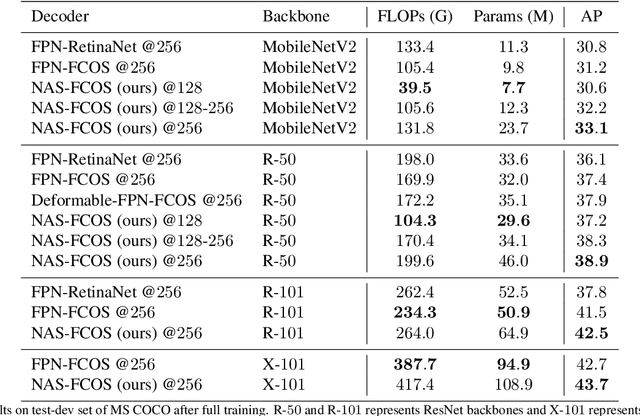
The success of deep neural networks relies on significant architecture engineering. Recently neural architecture search (NAS) has emerged as a promise to greatly reduce manual effort in network design by automatically searching for optimal architectures, although typically such algorithms need an excessive amount of computational resources, e.g., a few thousand GPU-days. To date, on challenging vision tasks such as object detection, NAS, especially fast versions of NAS, is less studied. Here we propose to search for the decoder structure of object detectors with search efficiency being taken into consideration. To be more specific, we aim to efficiently search for the feature pyramid network (FPN) as well as the prediction head of a simple anchor-free object detector, namely FCOS [20], using a tailored reinforcement learning paradigm. With carefully designed search space, search algorithms and strategies for evaluating network quality, we are able to efficiently search more than 2, 000 architectures in around 30 GPU-days. The discovered architecture surpasses state-of-the-art object detection models (such as Faster R-CNN, RetinaNet and FCOS) by 1 to 1.9 points in AP on the COCO dataset, with comparable computation complexity and memory footprint, demonstrating the efficacy of the proposed NAS for object detection.
Attention-guided Network for Ghost-free High Dynamic Range Imaging
Apr 23, 2019
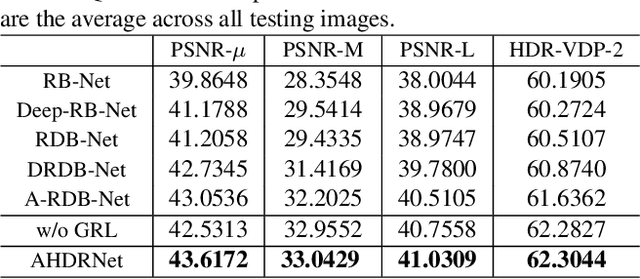
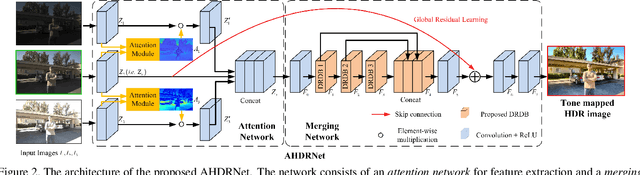

Ghosting artifacts caused by moving objects or misalignments is a key challenge in high dynamic range (HDR) imaging for dynamic scenes. Previous methods first register the input low dynamic range (LDR) images using optical flow before merging them, which are error-prone and cause ghosts in results. A very recent work tries to bypass optical flows via a deep network with skip-connections, however, which still suffers from ghosting artifacts for severe movement. To avoid the ghosting from the source, we propose a novel attention-guided end-to-end deep neural network (AHDRNet) to produce high-quality ghost-free HDR images. Unlike previous methods directly stacking the LDR images or features for merging, we use attention modules to guide the merging according to the reference image. The attention modules automatically suppress undesired components caused by misalignments and saturation and enhance desirable fine details in the non-reference images. In addition to the attention model, we use dilated residual dense block (DRDB) to make full use of the hierarchical features and increase the receptive field for hallucinating the missing details. The proposed AHDRNet is a non-flow-based method, which can also avoid the artifacts generated by optical-flow estimation error. Experiments on different datasets show that the proposed AHDRNet can achieve state-of-the-art quantitative and qualitative results.
RERERE: Remote Embodied Referring Expressions in Real indoor Environments
Apr 23, 2019
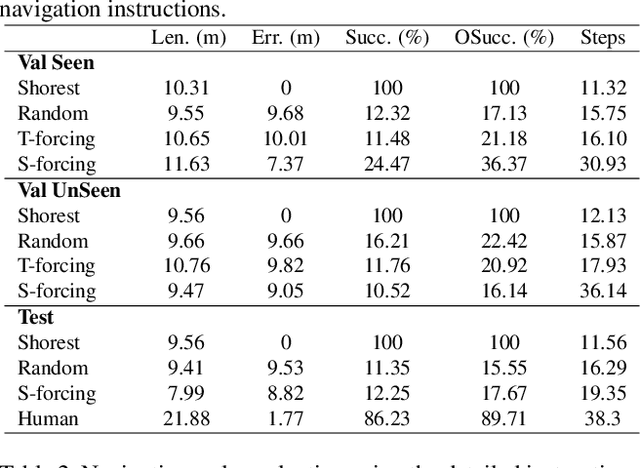

One of the long-term challenges of robotics is to enable humans to communicate with robots about the world. It is essential if they are to collaborate. Humans are visual animals, and we communicate primarily through language, so human-robot communication is inevitably at least partly a vision-and-language problem. This has motivated both Referring Expression datasets, and Vision and Language Navigation datasets. These partition the problem into that of identifying an object of interest, or navigating to another location. Many of the most appealing uses of robots, however, require communication about remote objects and thus do not reflect the dichotomy in the datasets. We thus propose the first Remote Embodied Referring Expression dataset of natural language references to remote objects in real images. Success requires navigating through a previously unseen environment to select an object identified through general natural language. This represents a complex challenge, but one that closely reflects one of the core visual problems in robotics. A Navigator-Pointer model which provides a strong baseline on the task is also proposed.
FCOS: Fully Convolutional One-Stage Object Detection
Apr 14, 2019

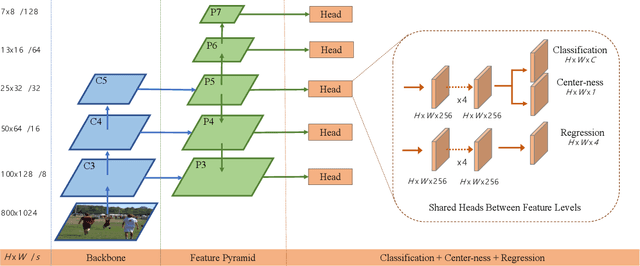

We propose a fully convolutional one-stage object detector (FCOS) to solve object detection in a per-pixel prediction fashion, analogue to semantic segmentation. Almost all state-of-the-art object detectors such as RetinaNet, SSD, YOLOv3, and Faster R-CNN rely on pre-defined anchor boxes. In contrast, our proposed detector FCOS is anchor-box free, as well as proposal free. By eliminating the pre-defined set of anchor boxes, FCOS completely avoids the complicated computation related to anchor boxes such as calculating overlapping during training and significantly reduces the training memory footprint. More importantly, we also avoid all hyper-parameters related to anchor boxes, which are often very sensitive to the final detection performance. With the only post-processing non-maximum suppression (NMS), our detector FCOS outperforms previous anchor-based one-stage detectors with the advantage of being much simpler. For the first time, we demonstrate a much simpler and flexible detection framework achieving improved detection accuracy. We hope that the proposed FCOS framework can serve as a simple and strong alternative for many other instance-level tasks. Code is available at: https://tinyurl.com/FCOSv1
Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation
Apr 05, 2019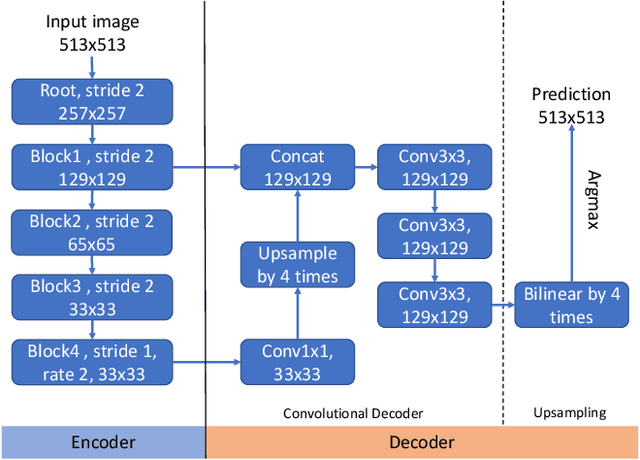
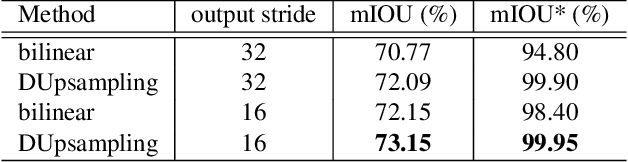
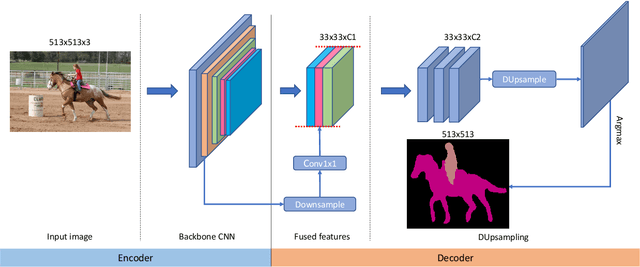
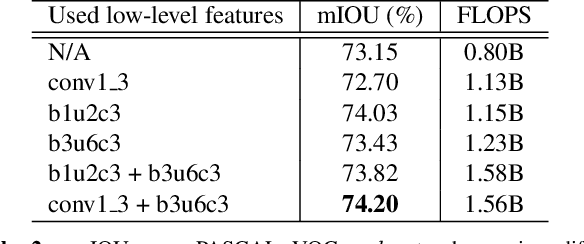
Recent semantic segmentation methods exploit encoder-decoder architectures to produce the desired pixel-wise segmentation prediction. The last layer of the decoders is typically a bilinear upsampling procedure to recover the final pixel-wise prediction. We empirically show that this oversimple and data-independent bilinear upsampling may lead to sub-optimal results. In this work, we propose a data-dependent upsampling (DUpsampling) to replace bilinear, which takes advantages of the redundancy in the label space of semantic segmentation and is able to recover the pixel-wise prediction from low-resolution outputs of CNNs. The main advantage of the new upsampling layer lies in that with a relatively lower-resolution feature map such as $\frac{1}{16}$ or $\frac{1}{32}$ of the input size, we can achieve even better segmentation accuracy, significantly reducing computation complexity. This is made possible by 1) the new upsampling layer's much improved reconstruction capability; and more importantly 2) the DUpsampling based decoder's flexibility in leveraging almost arbitrary combinations of the CNN encoders' features. Experiments demonstrate that our proposed decoder outperforms the state-of-the-art decoder, with only $\sim$20\% of computation. Finally, without any post-processing, the framework equipped with our proposed decoder achieves new state-of-the-art performance on two datasets: 88.1\% mIOU on PASCAL VOC with 30\% computation of the previously best model; and 52.5\% mIOU on PASCAL Context.