 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Source Video Realism: High-Fidelity Face Swapping for Cinematic Quality
Dec 08, 2025Video face swapping is crucial in film and entertainment production, where achieving high fidelity and temporal consistency over long and complex video sequences remains a significant challenge. Inspired by recent advances in reference-guided image editing, we explore whether rich visual attributes from source videos can be similarly leveraged to enhance both fidelity and temporal coherence in video face swapping. Building on this insight, this work presents LivingSwap, the first video reference guided face swapping model. Our approach employs keyframes as conditioning signals to inject the target identity, enabling flexible and controllable editing. By combining keyframe conditioning with video reference guidance, the model performs temporal stitching to ensure stable identity preservation and high-fidelity reconstruction across long video sequences. To address the scarcity of data for reference-guided training, we construct a paired face-swapping dataset, Face2Face, and further reverse the data pairs to ensure reliable ground-truth supervision. Extensive experiments demonstrate that our method achieves state-of-the-art results, seamlessly integrating the target identity with the source video's expressions, lighting, and motion, while significantly reducing manual effort in production workflows. Project webpage: https://aim-uofa.github.io/LivingSwap
R$^{2}$Seg: Training-Free OOD Medical Tumor Segmentation via Anatomical Reasoning and Statistical Rejection
Nov 16, 2025Foundation models for medical image segmentation struggle under out-of-distribution (OOD) shifts, often producing fragmented false positives on OOD tumors. We introduce R$^{2}$Seg, a training-free framework for robust OOD tumor segmentation that operates via a two-stage Reason-and-Reject process. First, the Reason step employs an LLM-guided anatomical reasoning planner to localize organ anchors and generate multi-scale ROIs. Second, the Reject step applies two-sample statistical testing to candidates generated by a frozen foundation model (BiomedParse) within these ROIs. This statistical rejection filter retains only candidates significantly different from normal tissue, effectively suppressing false positives. Our framework requires no parameter updates, making it compatible with zero-update test-time augmentation and avoiding catastrophic forgetting. On multi-center and multi-modal tumor segmentation benchmarks, R$^{2}$Seg substantially improves Dice, specificity, and sensitivity over strong baselines and the original foundation models. Code are available at https://github.com/Eurekashen/R2Seg.
Evolutionary Profiles for Protein Fitness Prediction
Oct 08, 2025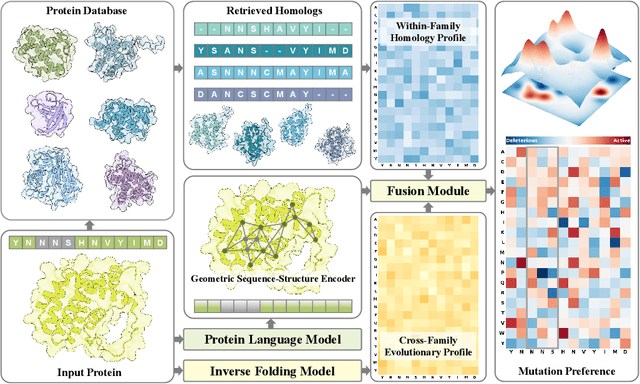
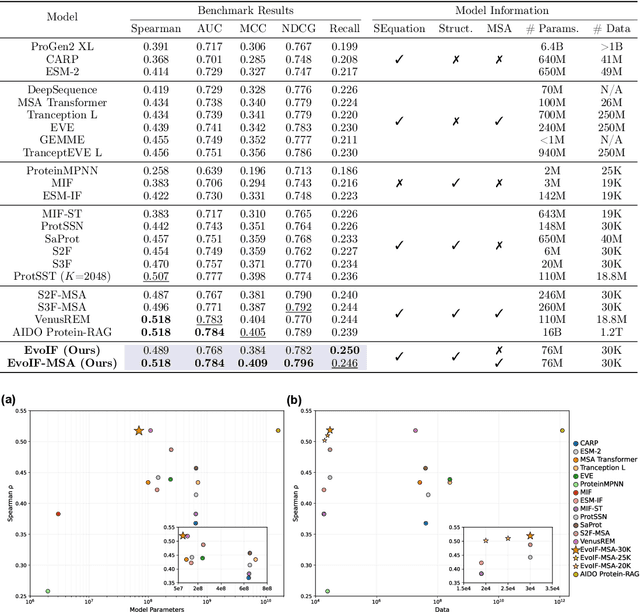
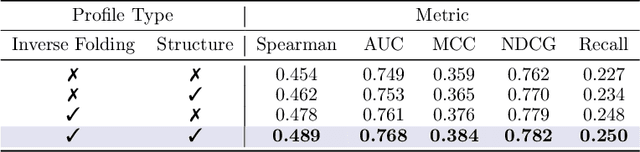
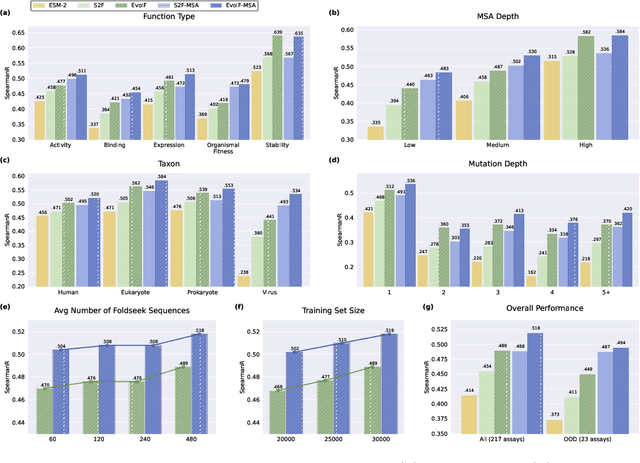
Predicting the fitness impact of mutations is central to protein engineering but constrained by limited assays relative to the size of sequence space. Protein language models (pLMs) trained with masked language modeling (MLM) exhibit strong zero-shot fitness prediction; we provide a unifying view by interpreting natural evolution as implicit reward maximization and MLM as inverse reinforcement learning (IRL), in which extant sequences act as expert demonstrations and pLM log-odds serve as fitness estimates. Building on this perspective, we introduce EvoIF, a lightweight model that integrates two complementary sources of evolutionary signal: (i) within-family profiles from retrieved homologs and (ii) cross-family structural-evolutionary constraints distilled from inverse folding logits. EvoIF fuses sequence-structure representations with these profiles via a compact transition block, yielding calibrated probabilities for log-odds scoring. On ProteinGym (217 mutational assays; >2.5M mutants), EvoIF and its MSA-enabled variant achieve state-of-the-art or competitive performance while using only 0.15% of the training data and fewer parameters than recent large models. Ablations confirm that within-family and cross-family profiles are complementary, improving robustness across function types, MSA depths, taxa, and mutation depths. The codes will be made publicly available at https://github.com/aim-uofa/EvoIF.
StaMo: Unsupervised Learning of Generalizable Robot Motion from Compact State Representation
Oct 06, 2025A fundamental challenge in embodied intelligence is developing expressive and compact state representations for efficient world modeling and decision making. However, existing methods often fail to achieve this balance, yielding representations that are either overly redundant or lacking in task-critical information. We propose an unsupervised approach that learns a highly compressed two-token state representation using a lightweight encoder and a pre-trained Diffusion Transformer (DiT) decoder, capitalizing on its strong generative prior. Our representation is efficient, interpretable, and integrates seamlessly into existing VLA-based models, improving performance by 14.3% on LIBERO and 30% in real-world task success with minimal inference overhead. More importantly, we find that the difference between these tokens, obtained via latent interpolation, naturally serves as a highly effective latent action, which can be further decoded into executable robot actions. This emergent capability reveals that our representation captures structured dynamics without explicit supervision. We name our method StaMo for its ability to learn generalizable robotic Motion from compact State representation, which is encoded from static images, challenging the prevalent dependence to learning latent action on complex architectures and video data. The resulting latent actions also enhance policy co-training, outperforming prior methods by 10.4% with improved interpretability. Moreover, our approach scales effectively across diverse data sources, including real-world robot data, simulation, and human egocentric video.
WinT3R: Window-Based Streaming Reconstruction with Camera Token Pool
Sep 05, 2025We present WinT3R, a feed-forward reconstruction model capable of online prediction of precise camera poses and high-quality point maps. Previous methods suffer from a trade-off between reconstruction quality and real-time performance. To address this, we first introduce a sliding window mechanism that ensures sufficient information exchange among frames within the window, thereby improving the quality of geometric predictions without large computation. In addition, we leverage a compact representation of cameras and maintain a global camera token pool, which enhances the reliability of camera pose estimation without sacrificing efficiency. These designs enable WinT3R to achieve state-of-the-art performance in terms of online reconstruction quality, camera pose estimation, and reconstruction speed, as validated by extensive experiments on diverse datasets. Code and model are publicly available at https://github.com/LiZizun/WinT3R.
Tinker: Diffusion's Gift to 3D--Multi-View Consistent Editing From Sparse Inputs without Per-Scene Optimization
Aug 20, 2025



We introduce Tinker, a versatile framework for high-fidelity 3D editing that operates in both one-shot and few-shot regimes without any per-scene finetuning. Unlike prior techniques that demand extensive per-scene optimization to ensure multi-view consistency or to produce dozens of consistent edited input views, Tinker delivers robust, multi-view consistent edits from as few as one or two images. This capability stems from repurposing pretrained diffusion models, which unlocks their latent 3D awareness. To drive research in this space, we curate the first large-scale multi-view editing dataset and data pipeline, spanning diverse scenes and styles. Building on this dataset, we develop our framework capable of generating multi-view consistent edited views without per-scene training, which consists of two novel components: (1) Referring multi-view editor: Enables precise, reference-driven edits that remain coherent across all viewpoints. (2) Any-view-to-video synthesizer: Leverages spatial-temporal priors from video diffusion to perform high-quality scene completion and novel-view generation even from sparse inputs. Through extensive experiments, Tinker significantly reduces the barrier to generalizable 3D content creation, achieving state-of-the-art performance on editing, novel-view synthesis, and rendering enhancement tasks. We believe that Tinker represents a key step towards truly scalable, zero-shot 3D editing. Project webpage: https://aim-uofa.github.io/Tinker
Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models
Aug 12, 2025Diffusion large language models (dLLMs) generate text through iterative denoising, yet current decoding strategies discard rich intermediate predictions in favor of the final output. Our work here reveals a critical phenomenon, temporal oscillation, where correct answers often emerge in the middle process, but are overwritten in later denoising steps. To address this issue, we introduce two complementary methods that exploit temporal consistency: 1) Temporal Self-Consistency Voting, a training-free, test-time decoding strategy that aggregates predictions across denoising steps to select the most consistent output; and 2) a post-training method termed Temporal Consistency Reinforcement, which uses Temporal Semantic Entropy (TSE), a measure of semantic stability across intermediate predictions, as a reward signal to encourage stable generations. Empirical results across multiple benchmarks demonstrate the effectiveness of our approach. Using the negative TSE reward alone, we observe a remarkable average improvement of 24.7% on the Countdown dataset over an existing dLLM. Combined with the accuracy reward, we achieve absolute gains of 2.0% on GSM8K, 4.3% on MATH500, 6.6% on SVAMP, and 25.3% on Countdown, respectively. Our findings underscore the untapped potential of temporal dynamics in dLLMs and offer two simple yet effective tools to harness them.
ODYSSEY: Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks
Aug 11, 2025



Language-guided long-horizon mobile manipulation has long been a grand challenge in embodied semantic reasoning, generalizable manipulation, and adaptive locomotion. Three fundamental limitations hinder progress: First, although large language models have improved spatial reasoning and task planning through semantic priors, existing implementations remain confined to tabletop scenarios, failing to address the constrained perception and limited actuation ranges of mobile platforms. Second, current manipulation strategies exhibit insufficient generalization when confronted with the diverse object configurations encountered in open-world environments. Third, while crucial for practical deployment, the dual requirement of maintaining high platform maneuverability alongside precise end-effector control in unstructured settings remains understudied. In this work, we present ODYSSEY, a unified mobile manipulation framework for agile quadruped robots equipped with manipulators, which seamlessly integrates high-level task planning with low-level whole-body control. To address the challenge of egocentric perception in language-conditioned tasks, we introduce a hierarchical planner powered by a vision-language model, enabling long-horizon instruction decomposition and precise action execution. At the control level, our novel whole-body policy achieves robust coordination across challenging terrains. We further present the first benchmark for long-horizon mobile manipulation, evaluating diverse indoor and outdoor scenarios. Through successful sim-to-real transfer, we demonstrate the system's generalization and robustness in real-world deployments, underscoring the practicality of legged manipulators in unstructured environments. Our work advances the feasibility of generalized robotic assistants capable of complex, dynamic tasks. Our project page: https://kaijwang.github.io/odyssey.github.io/
Generative Video Matting
Aug 11, 2025Video matting has traditionally been limited by the lack of high-quality ground-truth data. Most existing video matting datasets provide only human-annotated imperfect alpha and foreground annotations, which must be composited to background images or videos during the training stage. Thus, the generalization capability of previous methods in real-world scenarios is typically poor. In this work, we propose to solve the problem from two perspectives. First, we emphasize the importance of large-scale pre-training by pursuing diverse synthetic and pseudo-labeled segmentation datasets. We also develop a scalable synthetic data generation pipeline that can render diverse human bodies and fine-grained hairs, yielding around 200 video clips with a 3-second duration for fine-tuning. Second, we introduce a novel video matting approach that can effectively leverage the rich priors from pre-trained video diffusion models. This architecture offers two key advantages. First, strong priors play a critical role in bridging the domain gap between synthetic and real-world scenes. Second, unlike most existing methods that process video matting frame-by-frame and use an independent decoder to aggregate temporal information, our model is inherently designed for video, ensuring strong temporal consistency. We provide a comprehensive quantitative evaluation across three benchmark datasets, demonstrating our approach's superior performance, and present comprehensive qualitative results in diverse real-world scenes, illustrating the strong generalization capability of our method. The code is available at https://github.com/aim-uofa/GVM.
$π^3$: Scalable Permutation-Equivariant Visual Geometry Learning
Jul 17, 2025We introduce $\pi^3$, a feed-forward neural network that offers a novel approach to visual geometry reconstruction, breaking the reliance on a conventional fixed reference view. Previous methods often anchor their reconstructions to a designated viewpoint, an inductive bias that can lead to instability and failures if the reference is suboptimal. In contrast, $\pi^3$ employs a fully permutation-equivariant architecture to predict affine-invariant camera poses and scale-invariant local point maps without any reference frames. This design makes our model inherently robust to input ordering and highly scalable. These advantages enable our simple and bias-free approach to achieve state-of-the-art performance on a wide range of tasks, including camera pose estimation, monocular/video depth estimation, and dense point map reconstruction. Code and models are publicly available.