 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation
Apr 12, 2021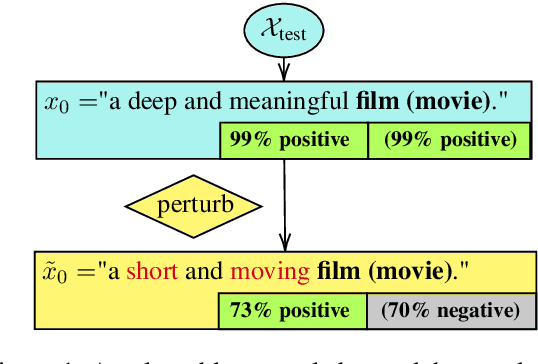

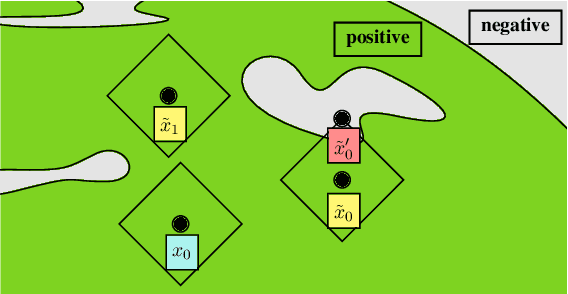
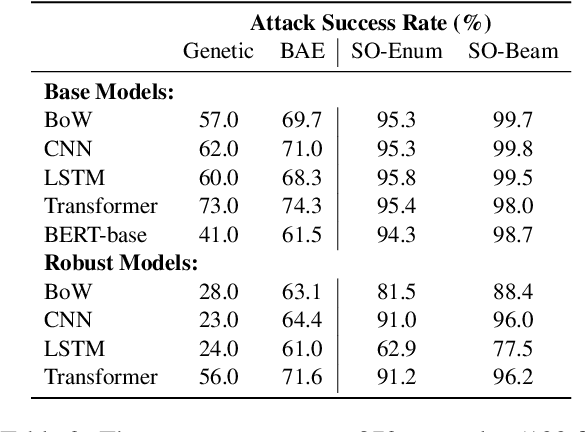
Robustness and counterfactual bias are usually evaluated on a test dataset. However, are these evaluations robust? If the test dataset is perturbed slightly, will the evaluation results keep the same? In this paper, we propose a "double perturbation" framework to uncover model weaknesses beyond the test dataset. The framework first perturbs the test dataset to construct abundant natural sentences similar to the test data, and then diagnoses the prediction change regarding a single-word substitution. We apply this framework to study two perturbation-based approaches that are used to analyze models' robustness and counterfactual bias in English. (1) For robustness, we focus on synonym substitutions and identify vulnerable examples where prediction can be altered. Our proposed attack attains high success rates (96.0%-99.8%) in finding vulnerable examples on both original and robustly trained CNNs and Transformers. (2) For counterfactual bias, we focus on substituting demographic tokens (e.g., gender, race) and measure the shift of the expected prediction among constructed sentences. Our method is able to reveal the hidden model biases not directly shown in the test dataset. Our code is available at https://github.com/chong-z/nlp-second-order-attack.
Fast Certified Robust Training via Better Initialization and Shorter Warmup
Apr 01, 2021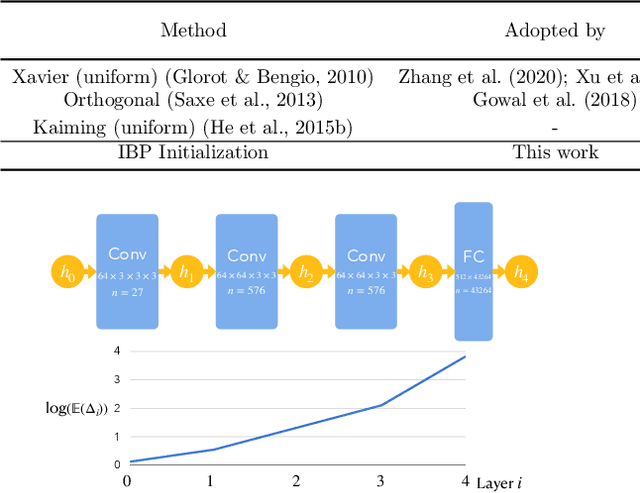
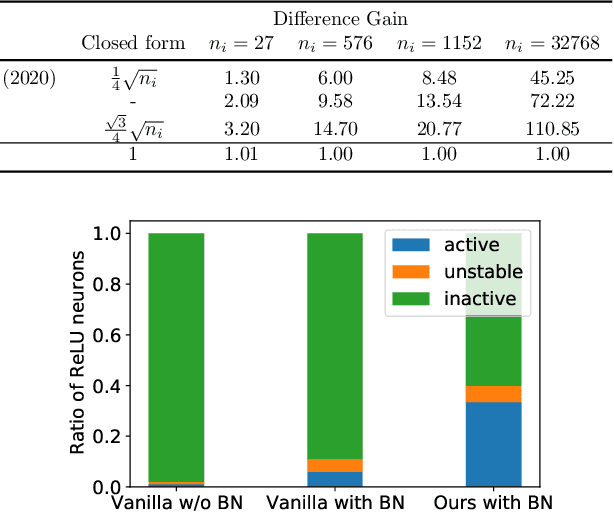
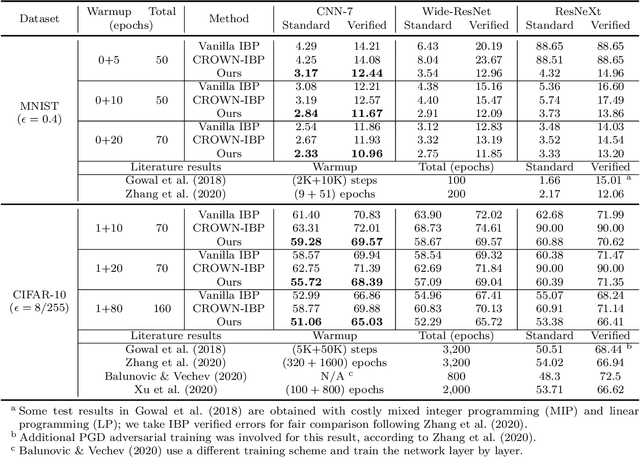
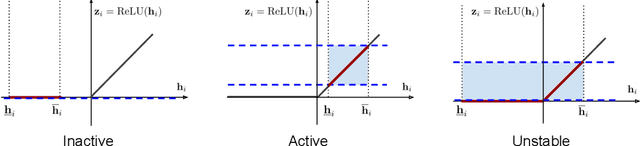
Recently, bound propagation based certified adversarial defense have been proposed for training neural networks with certifiable robustness guarantees. Despite state-of-the-art (SOTA) methods including interval bound propagation (IBP) and CROWN-IBP have per-batch training complexity similar to standard neural network training, to reach SOTA performance they usually need a long warmup schedule with hundreds or thousands epochs and are thus still quite costly for training. In this paper, we discover that the weight initialization adopted by prior works, such as Xavier or orthogonal initialization, which was originally designed for standard network training, results in very loose certified bounds at initialization thus a longer warmup schedule must be used. We also find that IBP based training leads to a significant imbalance in ReLU activation states, which can hamper model performance. Based on our findings, we derive a new IBP initialization as well as principled regularizers during the warmup stage to stabilize certified bounds during initialization and warmup stage, which can significantly reduce the warmup schedule and improve the balance of ReLU activation states. Additionally, we find that batch normalization (BN) is a crucial architectural element to build best-performing networks for certified training, because it helps stabilize bound variance and balance ReLU activation states. With our proposed initialization, regularizers and architectural changes combined, we are able to obtain 65.03% verified error on CIFAR-10 ($\epsilon=\frac{8}{255}$) and 82.13% verified error on TinyImageNet ($\epsilon=\frac{1}{255}$) using very short training schedules (160 and 80 total epochs, respectively), outperforming literature SOTA trained with a few hundreds or thousands epochs.
On the Adversarial Robustness of Visual Transformers
Mar 29, 2021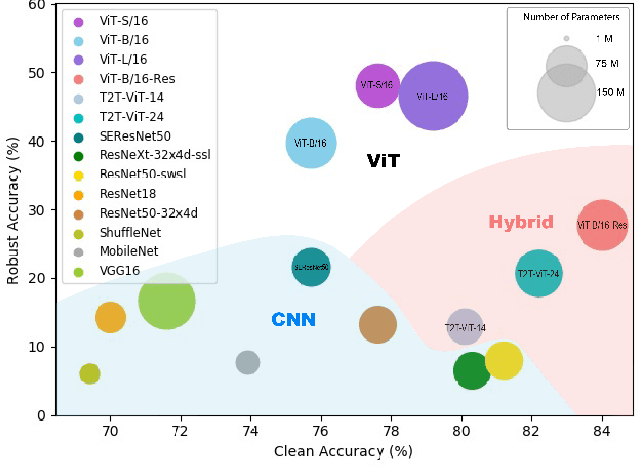
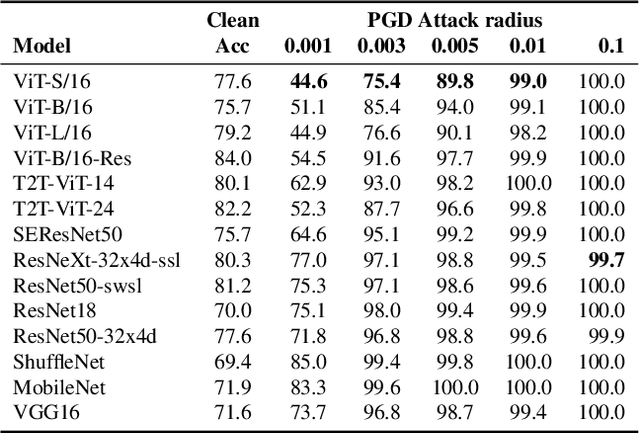
Following the success in advancing natural language processing and understanding, transformers are expected to bring revolutionary changes to computer vision. This work provides the first and comprehensive study on the robustness of vision transformers (ViTs) against adversarial perturbations. Tested on various white-box and transfer attack settings, we find that ViTs possess better adversarial robustness when compared with convolutional neural networks (CNNs). We summarize the following main observations contributing to the improved robustness of ViTs: 1) Features learned by ViTs contain less low-level information and are more generalizable, which contributes to superior robustness against adversarial perturbations. 2) Introducing convolutional or tokens-to-token blocks for learning low-level features in ViTs can improve classification accuracy but at the cost of adversarial robustness. 3) Increasing the proportion of transformers in the model structure (when the model consists of both transformer and CNN blocks) leads to better robustness. But for a pure transformer model, simply increasing the size or adding layers cannot guarantee a similar effect. 4) Pre-training on larger datasets does not significantly improve adversarial robustness though it is critical for training ViTs. 5) Adversarial training is also applicable to ViT for training robust models. Furthermore, feature visualization and frequency analysis are conducted for explanation. The results show that ViTs are less sensitive to high-frequency perturbations than CNNs and there is a high correlation between how well the model learns low-level features and its robustness against different frequency-based perturbations.
Robust and Accurate Object Detection via Adversarial Learning
Mar 26, 2021
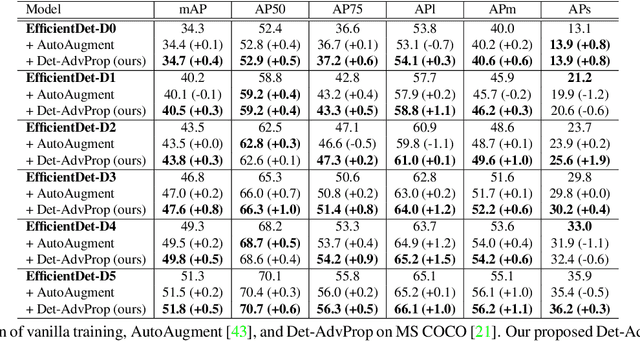
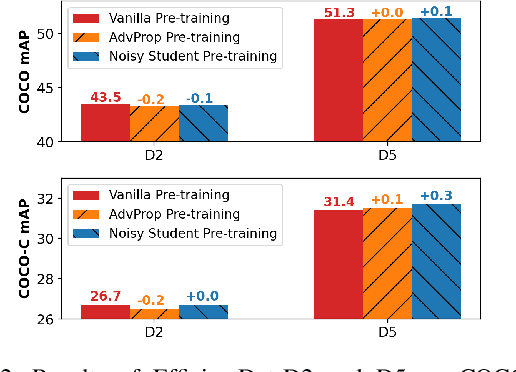
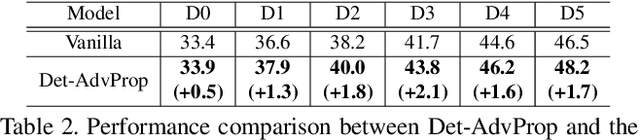
Data augmentation has become a de facto component for training high-performance deep image classifiers, but its potential is under-explored for object detection. Noting that most state-of-the-art object detectors benefit from fine-tuning a pre-trained classifier, we first study how the classifiers' gains from various data augmentations transfer to object detection. The results are discouraging; the gains diminish after fine-tuning in terms of either accuracy or robustness. This work instead augments the fine-tuning stage for object detectors by exploring adversarial examples, which can be viewed as a model-dependent data augmentation. Our method dynamically selects the stronger adversarial images sourced from a detector's classification and localization branches and evolves with the detector to ensure the augmentation policy stays current and relevant. This model-dependent augmentation generalizes to different object detectors better than AutoAugment, a model-agnostic augmentation policy searched based on one particular detector. Our approach boosts the performance of state-of-the-art EfficientDets by +1.1 mAP on the COCO object detection benchmark. It also improves the detectors' robustness against natural distortions by +3.8 mAP and against domain shift by +1.3 mAP. Models are available at https://github.com/google/automl/tree/master/efficientdet/Det-AdvProp.md
Beta-CROWN: Efficient Bound Propagation with Per-neuron Split Constraints for Complete and Incomplete Neural Network Verification
Mar 11, 2021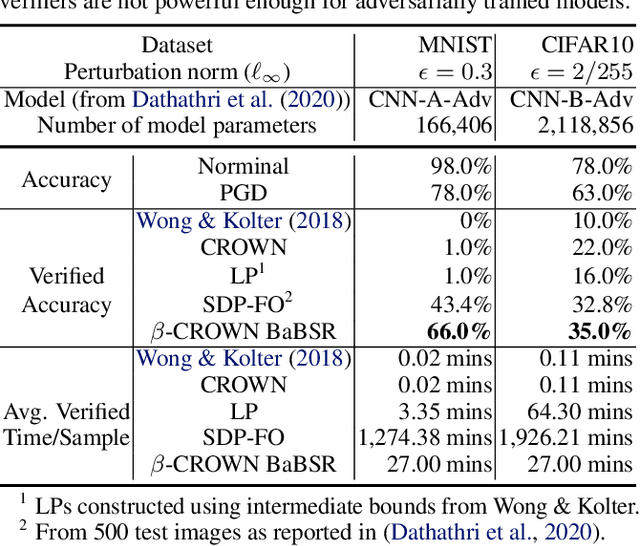
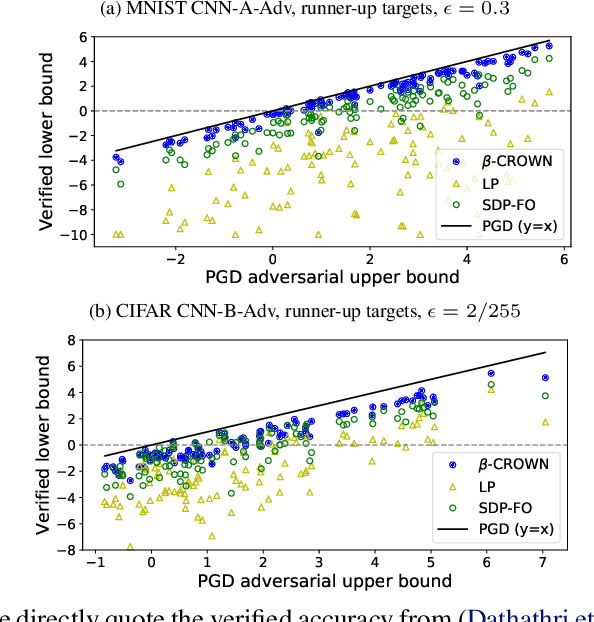
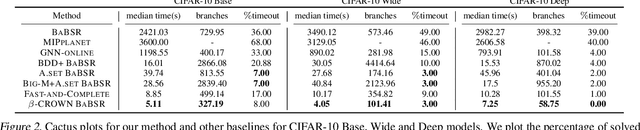
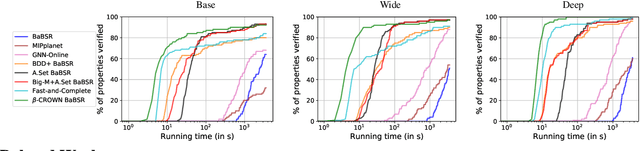
Recent works in neural network verification show that cheap incomplete verifiers such as CROWN, based upon bound propagations, can effectively be used in Branch-and-Bound (BaB) methods to accelerate complete verification, achieving significant speedups compared to expensive linear programming (LP) based techniques. However, they cannot fully handle the per-neuron split constraints introduced by BaB like LP verifiers do, leading to looser bounds and hurting their verification efficiency. In this work, we develop $\beta$-CROWN, a new bound propagation based method that can fully encode per-neuron splits via optimizable parameters $\beta$. When the optimizable parameters are jointly optimized in intermediate layers, $\beta$-CROWN has the potential of producing better bounds than typical LP verifiers with neuron split constraints, while being efficiently parallelizable on GPUs. Applied to the complete verification setting, $\beta$-CROWN is close to three orders of magnitude faster than LP-based BaB methods for robustness verification, and also over twice faster than state-of-the-art GPU-based complete verifiers with similar timeout rates. By terminating BaB early, our method can also be used for incomplete verification. Compared to the state-of-the-art semidefinite-programming (SDP) based verifier, we show a substantial leap forward by greatly reducing the gap between verified accuracy and empirical adversarial attack accuracy, from 35% (SDP) to 12% on an adversarially trained MNIST network ($\epsilon=0.3$), while being 47 times faster. Our code is available at https://github.com/KaidiXu/Beta-CROWN
Local Critic Training for Model-Parallel Learning of Deep Neural Networks
Feb 03, 2021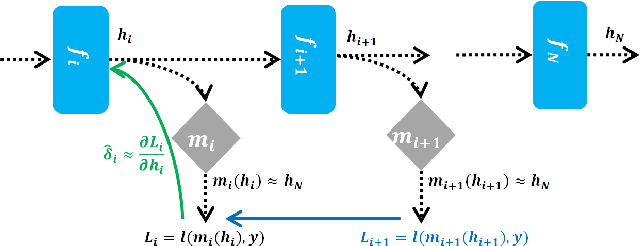
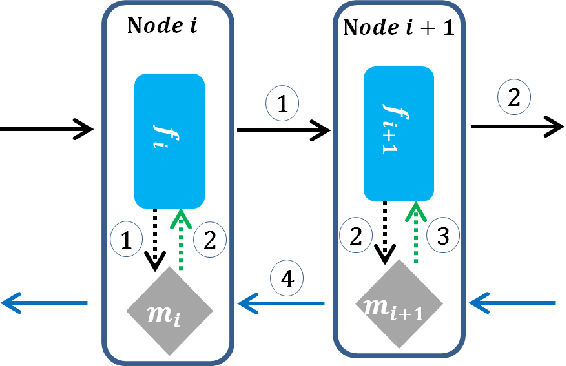
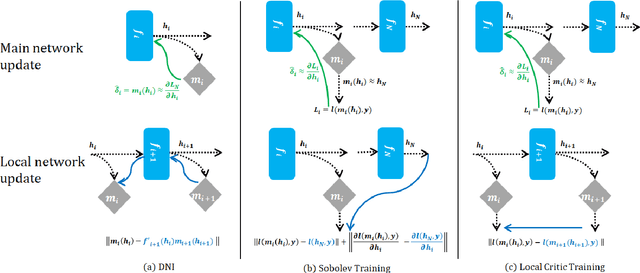
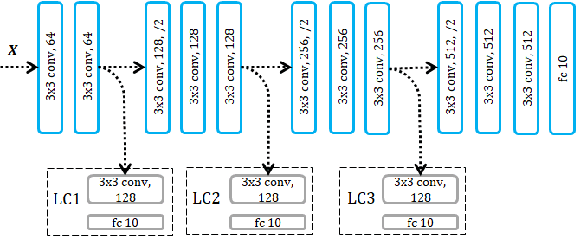
In this paper, we propose a novel model-parallel learning method, called local critic training, which trains neural networks using additional modules called local critic networks. The main network is divided into several layer groups and each layer group is updated through error gradients estimated by the corresponding local critic network. We show that the proposed approach successfully decouples the update process of the layer groups for both convolutional neural networks (CNNs) and recurrent neural networks (RNNs). In addition, we demonstrate that the proposed method is guaranteed to converge to a critical point. We also show that trained networks by the proposed method can be used for structural optimization. Experimental results show that our method achieves satisfactory performance, reduces training time greatly, and decreases memory consumption per machine. Code is available at https://github.com/hjdw2/Local-critic-training.
Robust Reinforcement Learning on State Observations with Learned Optimal Adversary
Jan 21, 2021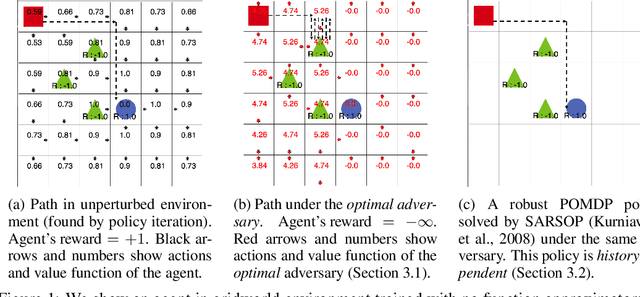
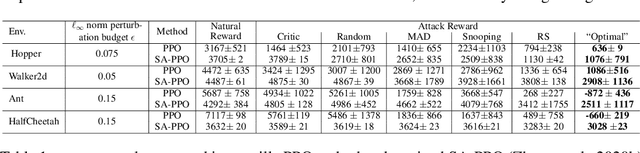
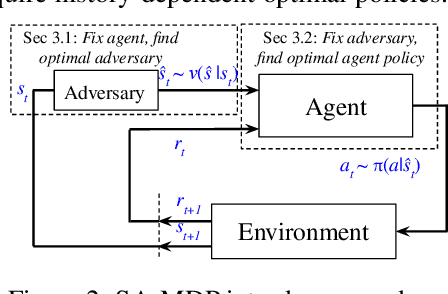
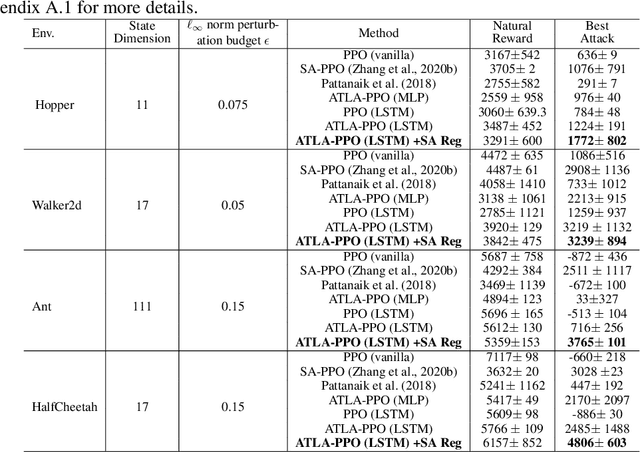
We study the robustness of reinforcement learning (RL) with adversarially perturbed state observations, which aligns with the setting of many adversarial attacks to deep reinforcement learning (DRL) and is also important for rolling out real-world RL agent under unpredictable sensing noise. With a fixed agent policy, we demonstrate that an optimal adversary to perturb state observations can be found, which is guaranteed to obtain the worst case agent reward. For DRL settings, this leads to a novel empirical adversarial attack to RL agents via a learned adversary that is much stronger than previous ones. To enhance the robustness of an agent, we propose a framework of alternating training with learned adversaries (ATLA), which trains an adversary online together with the agent using policy gradient following the optimal adversarial attack framework. Additionally, inspired by the analysis of state-adversarial Markov decision process (SA-MDP), we show that past states and actions (history) can be useful for learning a robust agent, and we empirically find a LSTM based policy can be more robust under adversaries. Empirical evaluations on a few continuous control environments show that ATLA achieves state-of-the-art performance under strong adversaries. Our code is available at https://github.com/huanzhang12/ATLA_robust_RL.
Emotional EEG Classification using Connectivity Features and Convolutional Neural Networks
Jan 18, 2021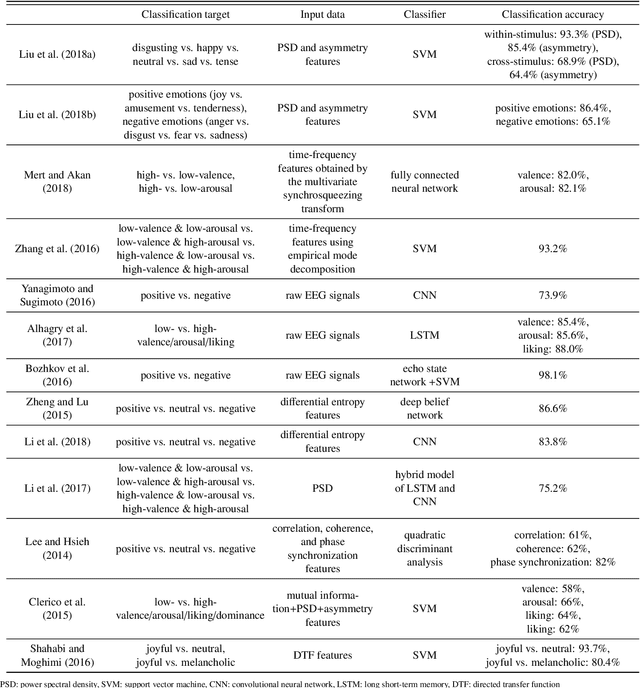
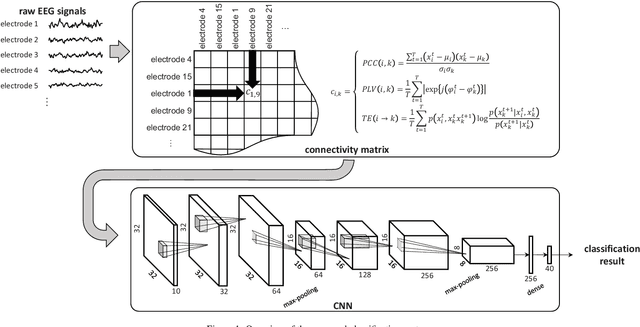
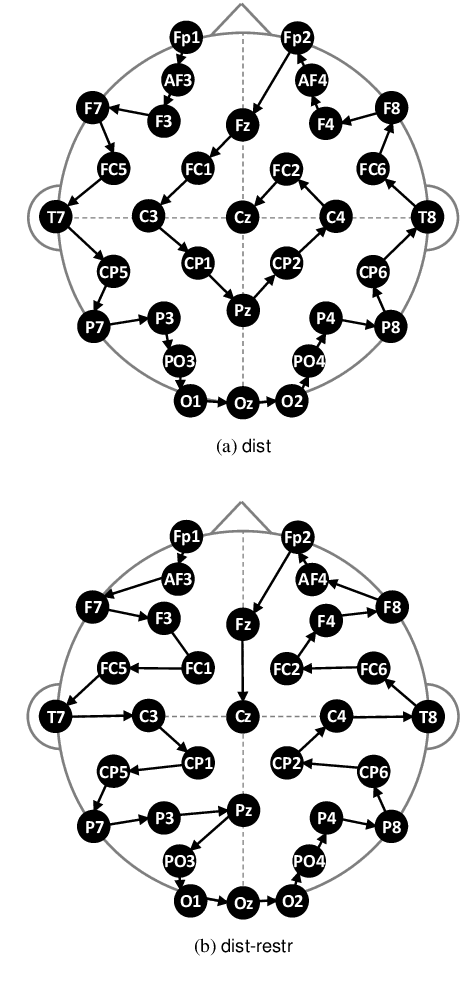
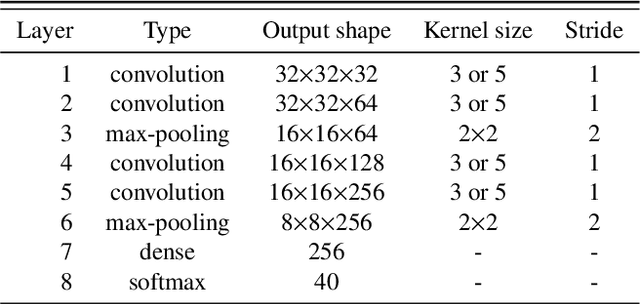
Convolutional neural networks (CNNs) are widely used to recognize the user's state through electroencephalography (EEG) signals. In the previous studies, the EEG signals are usually fed into the CNNs in the form of high-dimensional raw data. However, this approach makes it difficult to exploit the brain connectivity information that can be effective in describing the functional brain network and estimating the perceptual state of the user. We introduce a new classification system that utilizes brain connectivity with a CNN and validate its effectiveness via the emotional video classification by using three different types of connectivity measures. Furthermore, two data-driven methods to construct the connectivity matrix are proposed to maximize classification performance. Further analysis reveals that the level of concentration of the brain connectivity related to the emotional property of the target video is correlated with classification performance.
Robust Text CAPTCHAs Using Adversarial Examples
Jan 07, 2021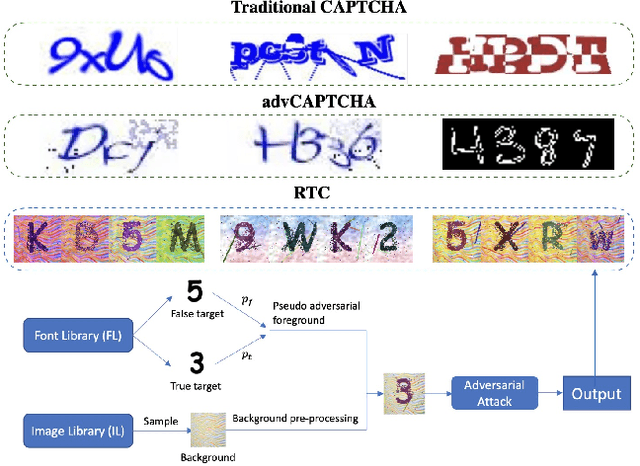
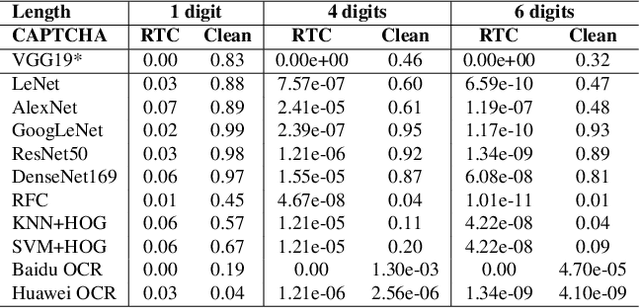

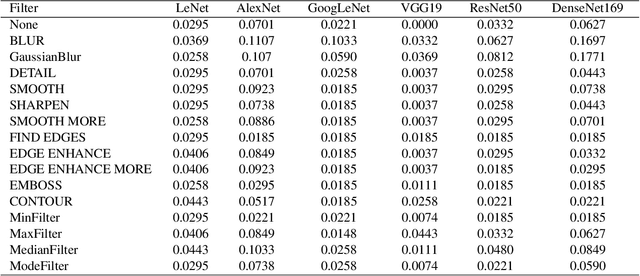
CAPTCHA (Completely Automated Public Truing test to tell Computers and Humans Apart) is a widely used technology to distinguish real users and automated users such as bots. However, the advance of AI technologies weakens many CAPTCHA tests and can induce security concerns. In this paper, we propose a user-friendly text-based CAPTCHA generation method named Robust Text CAPTCHA (RTC). At the first stage, the foregrounds and backgrounds are constructed with randomly sampled font and background images, which are then synthesized into identifiable pseudo adversarial CAPTCHAs. At the second stage, we design and apply a highly transferable adversarial attack for text CAPTCHAs to better obstruct CAPTCHA solvers. Our experiments cover comprehensive models including shallow models such as KNN, SVM and random forest, various deep neural networks and OCR models. Experiments show that our CAPTCHAs have a failure rate lower than one millionth in general and high usability. They are also robust against various defensive techniques that attackers may employ, including adversarial training, data pre-processing and manual tagging.
Self-Progressing Robust Training
Dec 22, 2020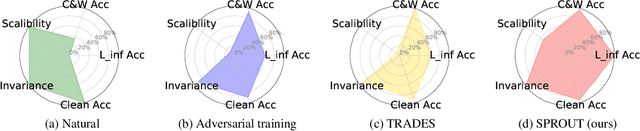


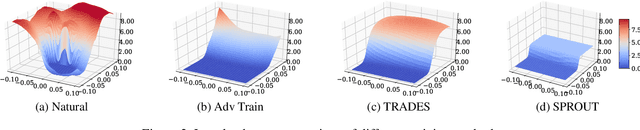
Enhancing model robustness under new and even adversarial environments is a crucial milestone toward building trustworthy machine learning systems. Current robust training methods such as adversarial training explicitly uses an "attack" (e.g., $\ell_{\infty}$-norm bounded perturbation) to generate adversarial examples during model training for improving adversarial robustness. In this paper, we take a different perspective and propose a new framework called SPROUT, self-progressing robust training. During model training, SPROUT progressively adjusts training label distribution via our proposed parametrized label smoothing technique, making training free of attack generation and more scalable. We also motivate SPROUT using a general formulation based on vicinity risk minimization, which includes many robust training methods as special cases. Compared with state-of-the-art adversarial training methods (PGD-l_inf and TRADES) under l_inf-norm bounded attacks and various invariance tests, SPROUT consistently attains superior performance and is more scalable to large neural networks. Our results shed new light on scalable, effective and attack-independent robust training methods.