 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransRef: Multi-Scale Reference Embedding Transformer for Reference-Guided Image Inpainting
Jun 21, 2023



Image inpainting for completing complicated semantic environments and diverse hole patterns of corrupted images is challenging even for state-of-the-art learning-based inpainting methods trained on large-scale data. A reference image capturing the same scene of a corrupted image offers informative guidance for completing the corrupted image as it shares similar texture and structure priors to that of the holes of the corrupted image. In this work, we propose a transformer-based encoder-decoder network, named TransRef, for reference-guided image inpainting. Specifically, the guidance is conducted progressively through a reference embedding procedure, in which the referencing features are subsequently aligned and fused with the features of the corrupted image. For precise utilization of the reference features for guidance, a reference-patch alignment (Ref-PA) module is proposed to align the patch features of the reference and corrupted images and harmonize their style differences, while a reference-patch transformer (Ref-PT) module is proposed to refine the embedded reference feature. Moreover, to facilitate the research of reference-guided image restoration tasks, we construct a publicly accessible benchmark dataset containing 50K pairs of input and reference images. Both quantitative and qualitative evaluations demonstrate the efficacy of the reference information and the proposed method over the state-of-the-art methods in completing complex holes. Code and dataset can be accessed at https://github.com/Cameltr/TransRef.
Making the Invisible Visible: Toward High-Quality Terahertz Tomographic Imaging via Physics-Guided Restoration
Apr 28, 2023Terahertz (THz) tomographic imaging has recently attracted significant attention thanks to its non-invasive, non-destructive, non-ionizing, material-classification, and ultra-fast nature for object exploration and inspection. However, its strong water absorption nature and low noise tolerance lead to undesired blurs and distortions of reconstructed THz images. The diffraction-limited THz signals highly constrain the performances of existing restoration methods. To address the problem, we propose a novel multi-view Subspace-Attention-guided Restoration Network (SARNet) that fuses multi-view and multi-spectral features of THz images for effective image restoration and 3D tomographic reconstruction. To this end, SARNet uses multi-scale branches to extract intra-view spatio-spectral amplitude and phase features and fuse them via shared subspace projection and self-attention guidance. We then perform inter-view fusion to further improve the restoration of individual views by leveraging the redundancies between neighboring views. Here, we experimentally construct a THz time-domain spectroscopy (THz-TDS) system covering a broad frequency range from 0.1 THz to 4 THz for building up a temporal/spectral/spatial/ material THz database of hidden 3D objects. Complementary to a quantitative evaluation, we demonstrate the effectiveness of our SARNet model on 3D THz tomographic reconstruction applications.
Efficient Image Super-Resolution with Feature Interaction Weighted Hybrid Network
Dec 29, 2022Recently, great progress has been made in single-image super-resolution (SISR) based on deep learning technology. However, the existing methods usually require a large computational cost. Meanwhile, the activation function will cause some features of the intermediate layer to be lost. Therefore, it is a challenge to make the model lightweight while reducing the impact of intermediate feature loss on the reconstruction quality. In this paper, we propose a Feature Interaction Weighted Hybrid Network (FIWHN) to alleviate the above problem. Specifically, FIWHN consists of a series of novel Wide-residual Distillation Interaction Blocks (WDIB) as the backbone, where every third WDIBs form a Feature shuffle Weighted Group (FSWG) by mutual information mixing and fusion. In addition, to mitigate the adverse effects of intermediate feature loss on the reconstruction results, we introduced a well-designed Wide Convolutional Residual Weighting (WCRW) and Wide Identical Residual Weighting (WIRW) units in WDIB, and effectively cross-fused features of different finenesses through a Wide-residual Distillation Connection (WRDC) framework and a Self-Calibrating Fusion (SCF) unit. Finally, to complement the global features lacking in the CNN model, we introduced the Transformer into our model and explored a new way of combining the CNN and Transformer. Extensive quantitative and qualitative experiments on low-level and high-level tasks show that our proposed FIWHN can achieve a good balance between performance and efficiency, and is more conducive to downstream tasks to solve problems in low-pixel scenarios.
Meta Transferring for Deblurring
Oct 14, 2022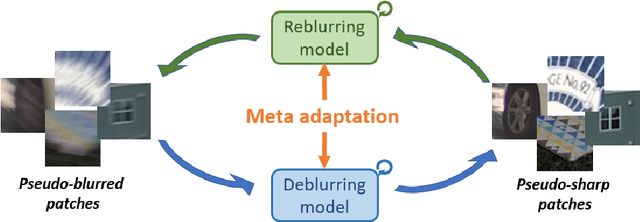
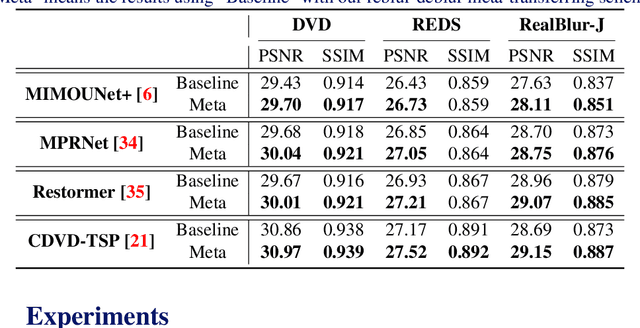
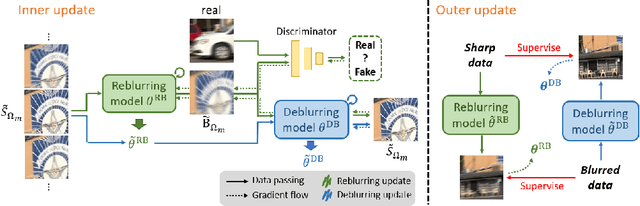
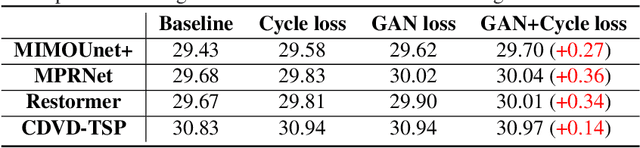
Most previous deblurring methods were built with a generic model trained on blurred images and their sharp counterparts. However, these approaches might have sub-optimal deblurring results due to the domain gap between the training and test sets. This paper proposes a reblur-deblur meta-transferring scheme to realize test-time adaptation without using ground truth for dynamic scene deblurring. Since the ground truth is usually unavailable at inference time in a real-world scenario, we leverage the blurred input video to find and use relatively sharp patches as the pseudo ground truth. Furthermore, we propose a reblurring model to extract the homogenous blur from the blurred input and transfer it to the pseudo-sharps to obtain the corresponding pseudo-blurred patches for meta-learning and test-time adaptation with only a few gradient updates. Extensive experimental results show that our reblur-deblur meta-learning scheme can improve state-of-the-art deblurring models on the DVD, REDS, and RealBlur benchmark datasets.
A heterogeneous group CNN for image super-resolution
Sep 26, 2022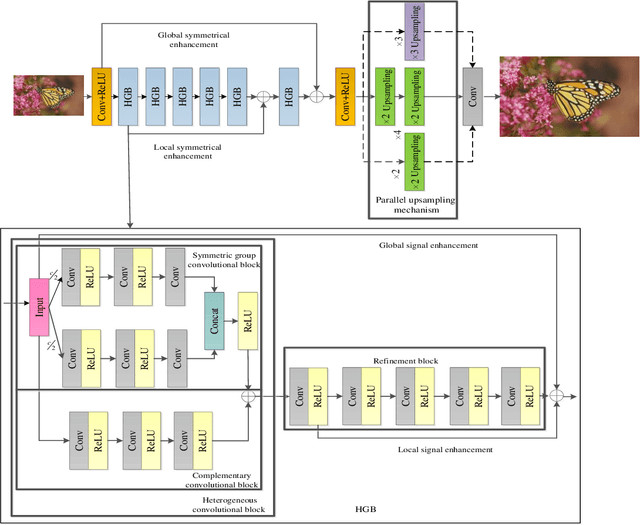
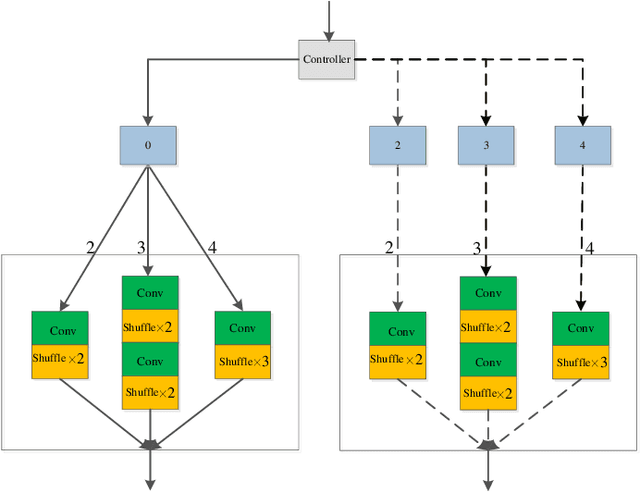


Convolutional neural networks (CNNs) have obtained remarkable performance via deep architectures. However, these CNNs often achieve poor robustness for image super-resolution (SR) under complex scenes. In this paper, we present a heterogeneous group SR CNN (HGSRCNN) via leveraging structure information of different types to obtain a high-quality image. Specifically, each heterogeneous group block (HGB) of HGSRCNN uses a heterogeneous architecture containing a symmetric group convolutional block and a complementary convolutional block in a parallel way to enhance internal and external relations of different channels for facilitating richer low-frequency structure information of different types. To prevent appearance of obtained redundant features, a refinement block with signal enhancements in a serial way is designed to filter useless information. To prevent loss of original information, a multi-level enhancement mechanism guides a CNN to achieve a symmetric architecture for promoting expressive ability of HGSRCNN. Besides, a parallel up-sampling mechanism is developed to train a blind SR model. Extensive experiments illustrate that the proposed HGSRCNN has obtained excellent SR performance in terms of both quantitative and qualitative analysis. Codes can be accessed at https://github.com/hellloxiaotian/HGSRCNN.
Magic ELF: Image Deraining Meets Association Learning and Transformer
Jul 21, 2022
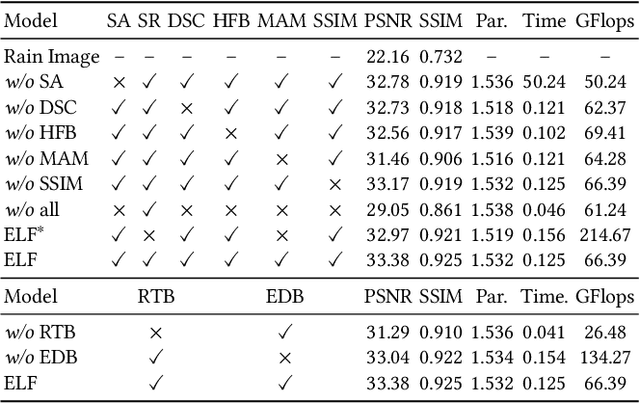
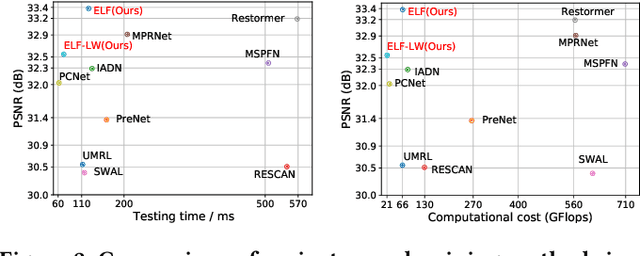
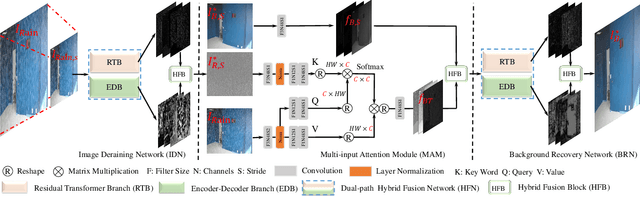
Convolutional neural network (CNN) and Transformer have achieved great success in multimedia applications. However, little effort has been made to effectively and efficiently harmonize these two architectures to satisfy image deraining. This paper aims to unify these two architectures to take advantage of their learning merits for image deraining. In particular, the local connectivity and translation equivariance of CNN and the global aggregation ability of self-attention (SA) in Transformer are fully exploited for specific local context and global structure representations. Based on the observation that rain distribution reveals the degradation location and degree, we introduce degradation prior to help background recovery and accordingly present the association refinement deraining scheme. A novel multi-input attention module (MAM) is proposed to associate rain perturbation removal and background recovery. Moreover, we equip our model with effective depth-wise separable convolutions to learn the specific feature representations and trade off computational complexity. Extensive experiments show that our proposed method (dubbed as ELF) outperforms the state-of-the-art approach (MPRNet) by 0.25 dB on average, but only accounts for 11.7\% and 42.1\% of its computational cost and parameters. The source code is available at https://github.com/kuijiang94/Magic-ELF.
Unsupervised Foggy Scene Understanding via Self Spatial-Temporal Label Diffusion
Jun 10, 2022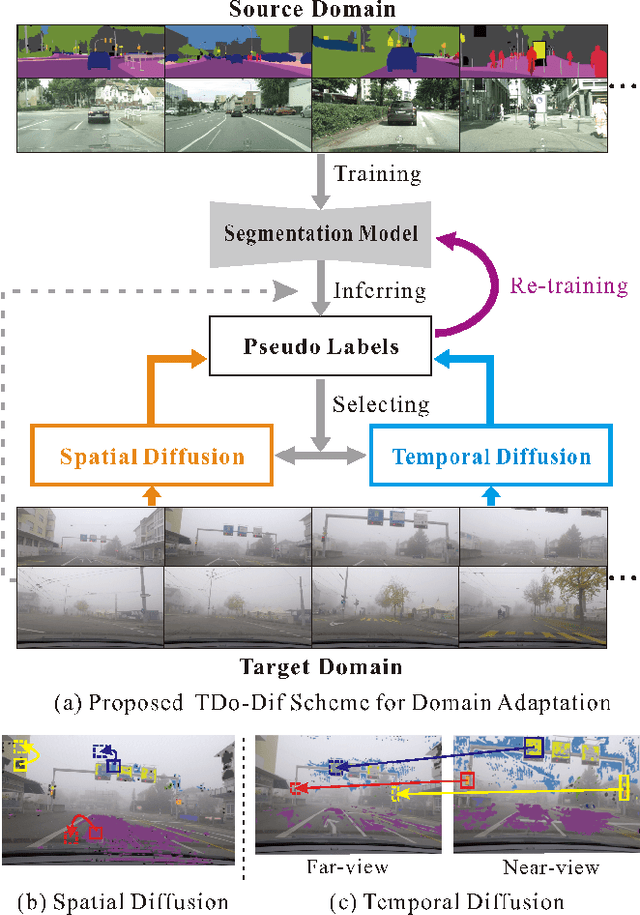
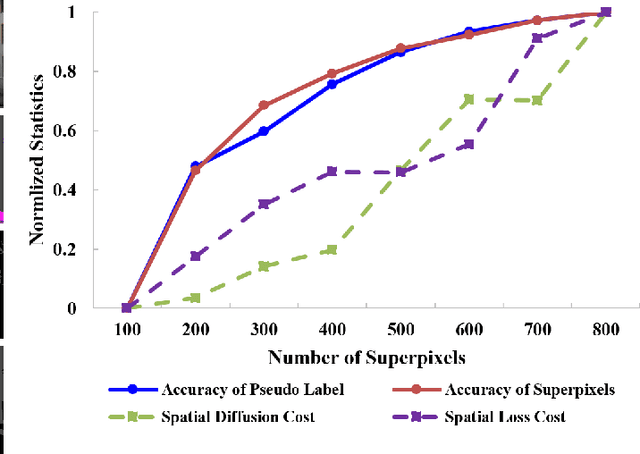
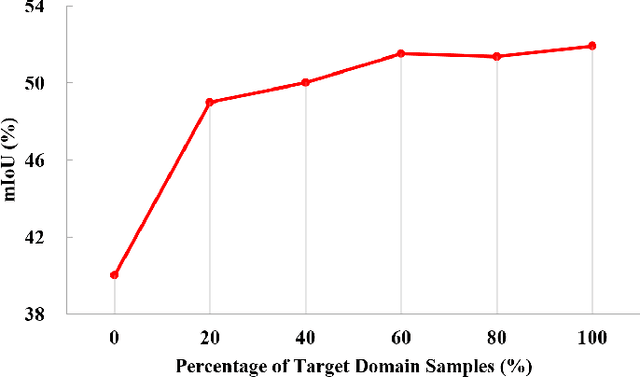
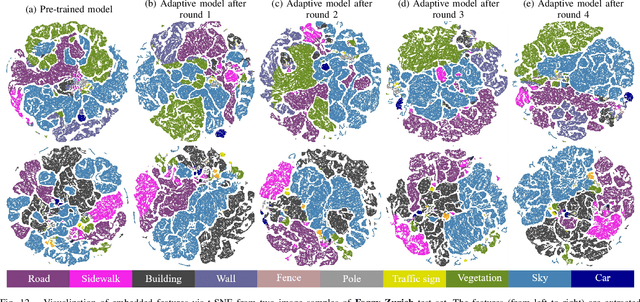
Understanding foggy image sequence in the driving scenes is critical for autonomous driving, but it remains a challenging task due to the difficulty in collecting and annotating real-world images of adverse weather. Recently, the self-training strategy has been considered a powerful solution for unsupervised domain adaptation, which iteratively adapts the model from the source domain to the target domain by generating target pseudo labels and re-training the model. However, the selection of confident pseudo labels inevitably suffers from the conflict between sparsity and accuracy, both of which will lead to suboptimal models. To tackle this problem, we exploit the characteristics of the foggy image sequence of driving scenes to densify the confident pseudo labels. Specifically, based on the two discoveries of local spatial similarity and adjacent temporal correspondence of the sequential image data, we propose a novel Target-Domain driven pseudo label Diffusion (TDo-Dif) scheme. It employs superpixels and optical flows to identify the spatial similarity and temporal correspondence, respectively and then diffuses the confident but sparse pseudo labels within a superpixel or a temporal corresponding pair linked by the flow. Moreover, to ensure the feature similarity of the diffused pixels, we introduce local spatial similarity loss and temporal contrastive loss in the model re-training stage. Experimental results show that our TDo-Dif scheme helps the adaptive model achieve 51.92% and 53.84% mean intersection-over-union (mIoU) on two publicly available natural foggy datasets (Foggy Zurich and Foggy Driving), which exceeds the state-of-the-art unsupervised domain adaptive semantic segmentation methods. Models and data can be found at https://github.com/velor2012/TDo-Dif.
Image Super-resolution with An Enhanced Group Convolutional Neural Network
May 29, 2022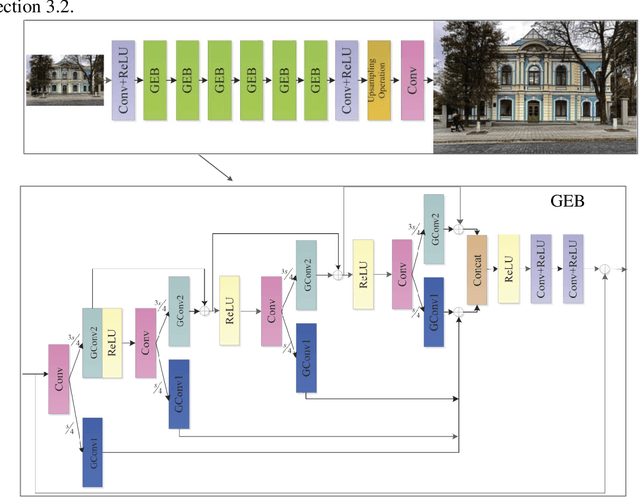

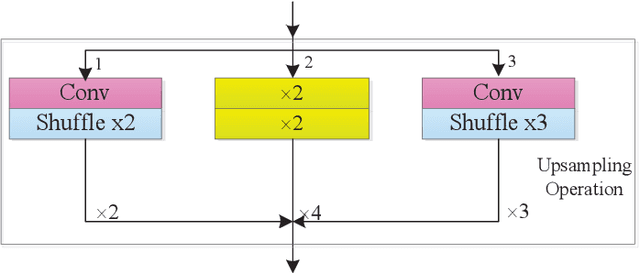
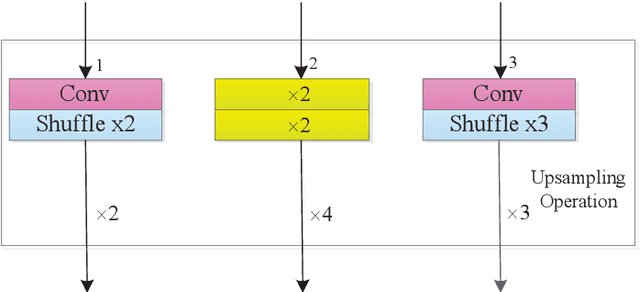
CNNs with strong learning abilities are widely chosen to resolve super-resolution problem. However, CNNs depend on deeper network architectures to improve performance of image super-resolution, which may increase computational cost in general. In this paper, we present an enhanced super-resolution group CNN (ESRGCNN) with a shallow architecture by fully fusing deep and wide channel features to extract more accurate low-frequency information in terms of correlations of different channels in single image super-resolution (SISR). Also, a signal enhancement operation in the ESRGCNN is useful to inherit more long-distance contextual information for resolving long-term dependency. An adaptive up-sampling operation is gathered into a CNN to obtain an image super-resolution model with low-resolution images of different sizes. Extensive experiments report that our ESRGCNN surpasses the state-of-the-arts in terms of SISR performance, complexity, execution speed, image quality evaluation and visual effect in SISR. Code is found at https://github.com/hellloxiaotian/ESRGCNN.
Physics-guided Terahertz Computational Imaging
Apr 30, 2022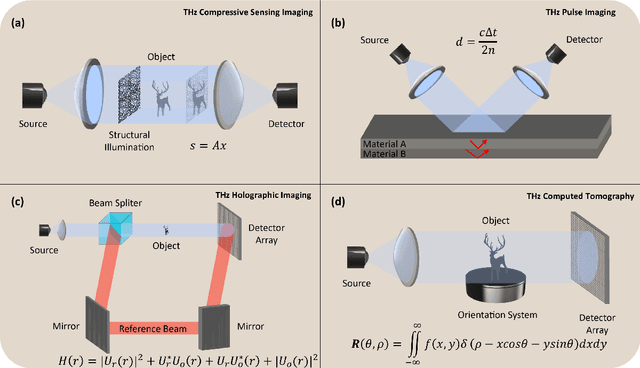
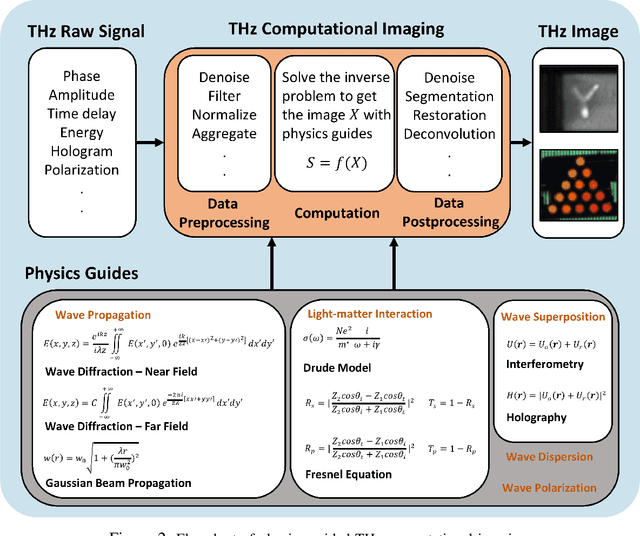
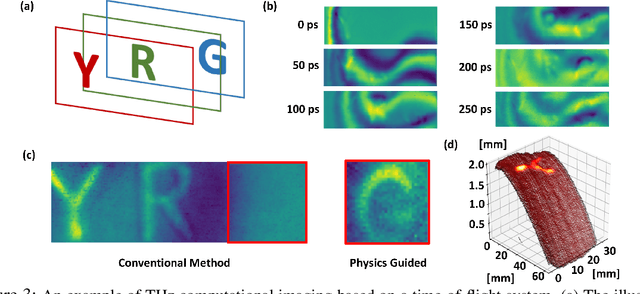
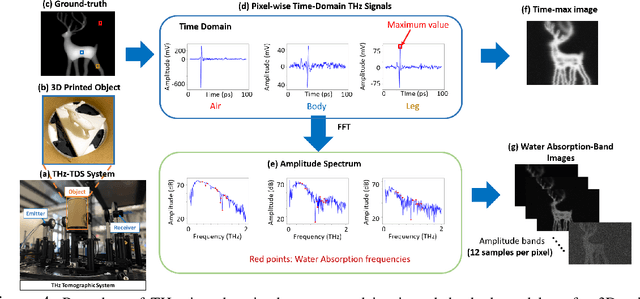
Visualizing information inside objects is an ever-lasting need to bridge the world from physics, chemistry, biology to computation. Among all tomographic techniques, terahertz (THz) computational imaging has demonstrated its unique sensing features to digitalize multi-dimensional object information in a non-destructive, non-ionizing, and non-invasive way. Applying modern signal processing and physics-guided modalities, THz computational imaging systems are now launched in various application fields in industrial inspection, security screening, chemical inspection and non-destructive evaluation. In this article, we overview recent advances in THz computational imaging modalities in the aspects of system configuration, wave propagation and interaction models, physics-guided algorithm for digitalizing interior information of imaged objects. Several image restoration and reconstruction issues based on multi-dimensional THz signals are further discussed, which provides a crosslink between material digitalization, functional property extraction, and multi-dimensional imager utilization from a signal processing perspective.
Stripformer: Strip Transformer for Fast Image Deblurring
Apr 10, 2022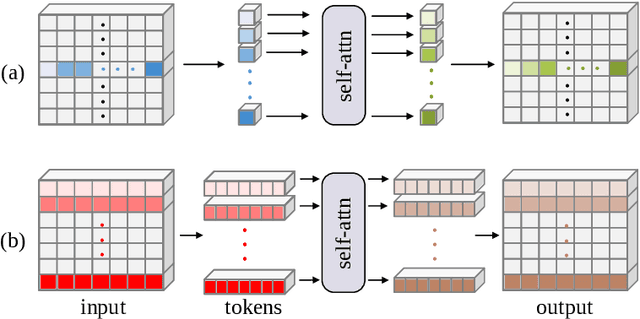
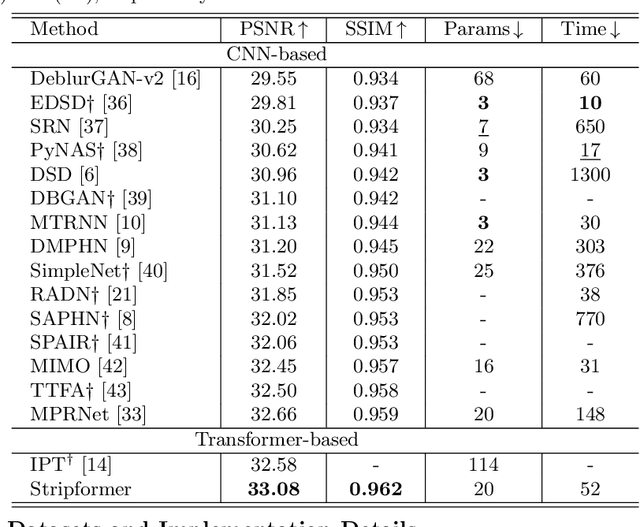
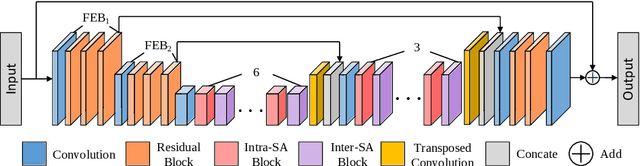
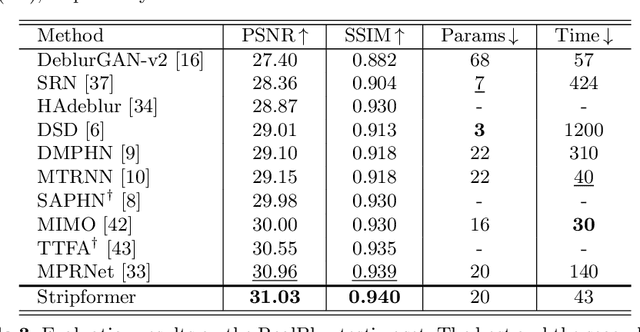
Images taken in dynamic scenes may contain unwanted motion blur, which significantly degrades visual quality. Such blur causes short- and long-range region-specific smoothing artifacts that are often directional and non-uniform, which is difficult to be removed. Inspired by the current success of transformers on computer vision and image processing tasks, we develop, Stripformer, a transformer-based architecture that constructs intra- and inter-strip tokens to reweight image features in the horizontal and vertical directions to catch blurred patterns with different orientations. It stacks interlaced intra-strip and inter-strip attention layers to reveal blur magnitudes. In addition to detecting region-specific blurred patterns of various orientations and magnitudes, Stripformer is also a token-efficient and parameter-efficient transformer model, demanding much less memory usage and computation cost than the vanilla transformer but works better without relying on tremendous training data. Experimental results show that Stripformer performs favorably against state-of-the-art models in dynamic scene deblurring.