 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImputation-Free Learning from Incomplete Observations
Jul 05, 2021

Although recent works have developed methods that can generate estimations (or imputations) of the missing entries in a dataset to facilitate downstream analysis, most depend on assumptions that may not align with real-world applications and could suffer from poor performance in subsequent tasks. This is particularly true if the data have large missingness rates or a small population. More importantly, the imputation error could be propagated into the prediction step that follows, causing the gradients used to train the prediction models to be biased. Consequently, in this work, we introduce the importance guided stochastic gradient descent (IGSGD) method to train multilayer perceptrons (MLPs) and long short-term memories (LSTMs) to directly perform inference from inputs containing missing values without imputation. Specifically, we employ reinforcement learning (RL) to adjust the gradients used to train the models via back-propagation. This not only reduces bias but allows the model to exploit the underlying information behind missingness patterns. We test the proposed approach on real-world time-series (i.e., MIMIC-III), tabular data obtained from an eye clinic, and a standard dataset (i.e., MNIST), where our imputation-free predictions outperform the traditional two-step imputation-based predictions using state-of-the-art imputation methods.
Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE
Jul 02, 2021


InfoNCE-based contrastive representation learners, such as SimCLR, have been tremendously successful in recent years. However, these contrastive schemes are notoriously resource demanding, as their effectiveness breaks down with small-batch training (i.e., the log-K curse, whereas K is the batch-size). In this work, we reveal mathematically why contrastive learners fail in the small-batch-size regime, and present a novel simple, non-trivial contrastive objective named FlatNCE, which fixes this issue. Unlike InfoNCE, our FlatNCE no longer explicitly appeals to a discriminative classification goal for contrastive learning. Theoretically, we show FlatNCE is the mathematical dual formulation of InfoNCE, thus bridging the classical literature on energy modeling; and empirically, we demonstrate that, with minimal modification of code, FlatNCE enables immediate performance boost independent of the subject-matter engineering efforts. The significance of this work is furthered by the powerful generalization of contrastive learning techniques, and the introduction of new tools to monitor and diagnose contrastive training. We substantiate our claims with empirical evidence on CIFAR10, ImageNet, and other datasets, where FlatNCE consistently outperforms InfoNCE.
Tight Mutual Information Estimation With Contrastive Fenchel-Legendre Optimization
Jul 02, 2021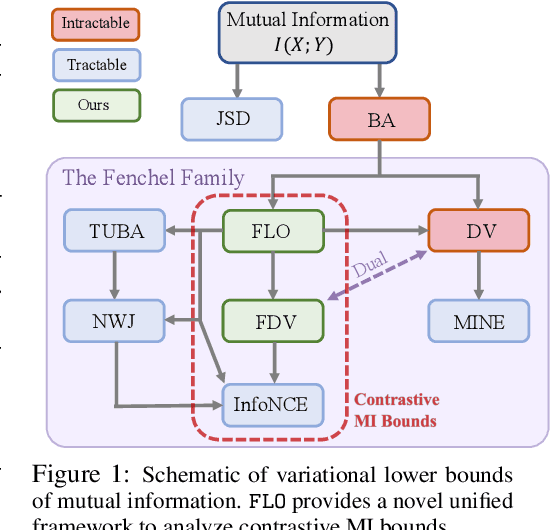
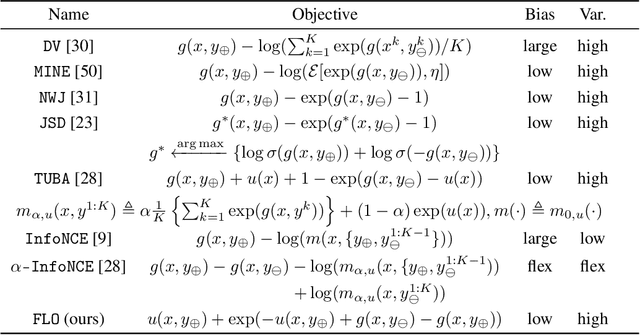
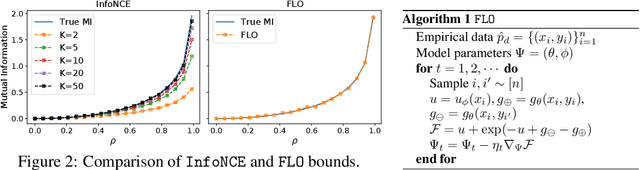

Successful applications of InfoNCE and its variants have popularized the use of contrastive variational mutual information (MI) estimators in machine learning. While featuring superior stability, these estimators crucially depend on costly large-batch training, and they sacrifice bound tightness for variance reduction. To overcome these limitations, we revisit the mathematics of popular variational MI bounds from the lens of unnormalized statistical modeling and convex optimization. Our investigation not only yields a new unified theoretical framework encompassing popular variational MI bounds but also leads to a novel, simple, and powerful contrastive MI estimator named as FLO. Theoretically, we show that the FLO estimator is tight, and it provably converges under stochastic gradient descent. Empirically, our FLO estimator overcomes the limitations of its predecessors and learns more efficiently. The utility of FLO is verified using an extensive set of benchmarks, which also reveals the trade-offs in practical MI estimation.
Proactive Pseudo-Intervention: Causally Informed Contrastive Learning For Interpretable Vision Models
Dec 06, 2020

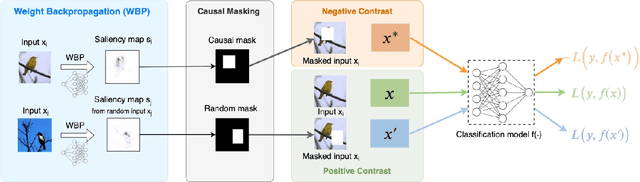
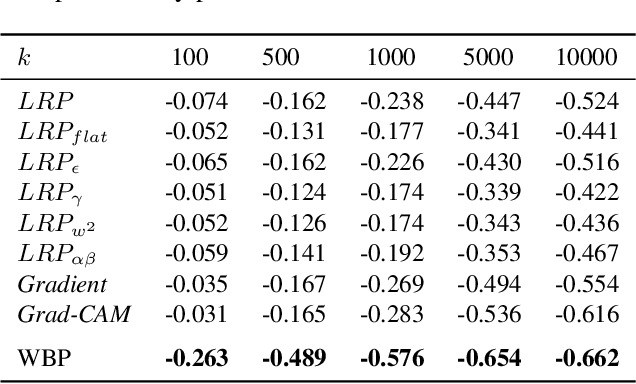
Deep neural networks have shown significant promise in comprehending complex visual signals, delivering performance on par or even superior to that of human experts. However, these models often lack a mechanism for interpreting their predictions, and in some cases, particularly when the sample size is small, existing deep learning solutions tend to capture spurious correlations that compromise model generalizability on unseen inputs. In this work, we propose a contrastive causal representation learning strategy that leverages proactive interventions to identify causally-relevant image features, called Proactive Pseudo-Intervention (PPI). This approach is complemented with a causal salience map visualization module, i.e., Weight Back Propagation (WBP), that identifies important pixels in the raw input image, which greatly facilitates the interpretability of predictions. To validate its utility, our model is benchmarked extensively on both standard natural images and challenging medical image datasets. We show this new contrastive causal representation learning model consistently improves model performance relative to competing solutions, particularly for out-of-domain predictions or when dealing with data integration from heterogeneous sources. Further, our causal saliency maps are more succinct and meaningful relative to their non-causal counterparts.
Supercharging Imbalanced Data Learning With Causal Representation Transfer
Nov 25, 2020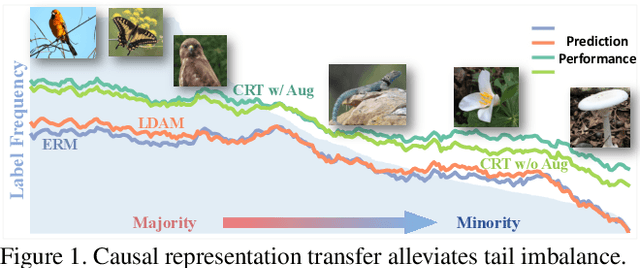
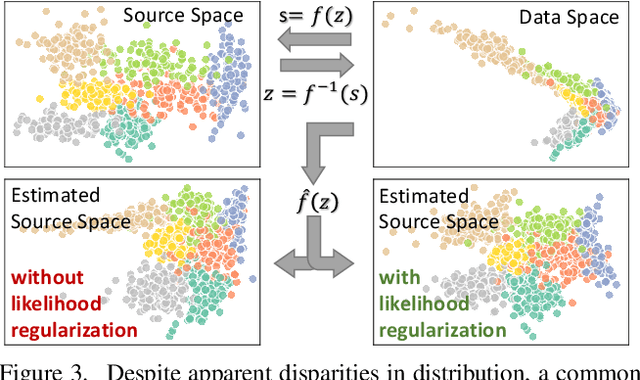
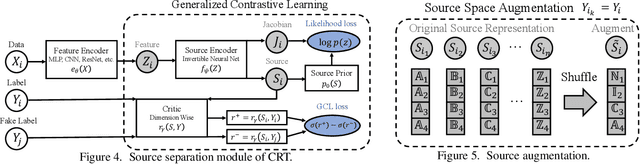
Dealing with severe class imbalance poses a major challenge for real-world applications, especially when the accurate classification and generalization of minority classes is of primary interest. In computer vision, learning from long tailed datasets is a recurring theme, especially for natural image datasets. While existing solutions mostly appeal to sampling or weighting adjustments to alleviate the pathological imbalance, or imposing inductive bias to prioritize non-spurious associations, we take novel perspectives to promote sample efficiency and model generalization based on the invariance principles of causality. Our proposal posits a meta-distributional scenario, where the data generating mechanism is invariant across the label-conditional feature distributions. Such causal assumption enables efficient knowledge transfer from the dominant classes to their under-represented counterparts, even if the respective feature distributions show apparent disparities. This allows us to leverage a causal data inflation procedure to enlarge the representation of minority classes. Our development is orthogonal to the existing extreme classification techniques thus can be seamlessly integrated. The utility of our proposal is validated with an extensive set of synthetic and real-world computer vision tasks against SOTA solutions.
Counterfactual Representation Learning with Balancing Weights
Oct 23, 2020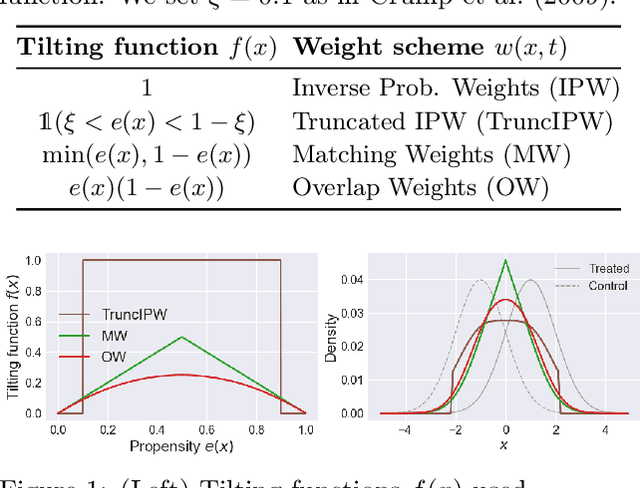
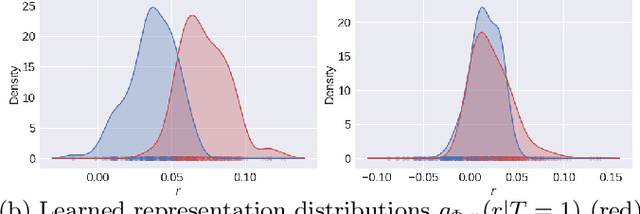
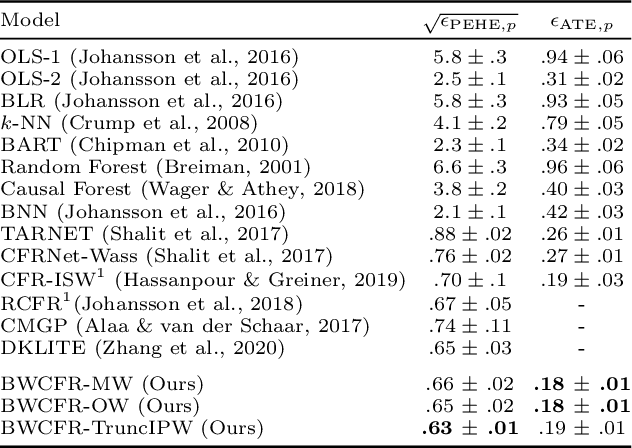
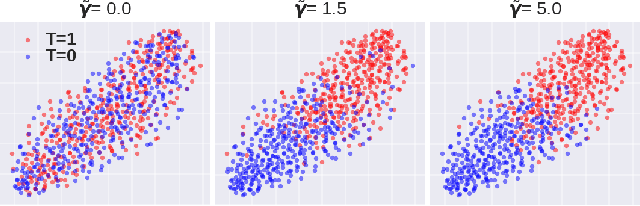
A key to causal inference with observational data is achieving balance in predictive features associated with each treatment type. Recent literature has explored representation learning to achieve this goal. In this work, we discuss the pitfalls of these strategies - such as a steep trade-off between achieving balance and predictive power - and present a remedy via the integration of balancing weights in causal learning. Specifically, we theoretically link balance to the quality of propensity estimation, emphasize the importance of identifying a proper target population, and elaborate on the complementary roles of feature balancing and weight adjustments. Using these concepts, we then develop an algorithm for flexible, scalable and accurate estimation of causal effects. Finally, we show how the learned weighted representations may serve to facilitate alternative causal learning procedures with appealing statistical features. We conduct an extensive set of experiments on both synthetic examples and standard benchmarks, and report encouraging results relative to state-of-the-art baselines.
Double Robust Representation Learning for Counterfactual Prediction
Oct 16, 2020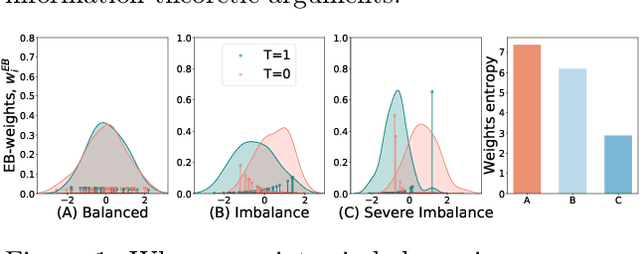
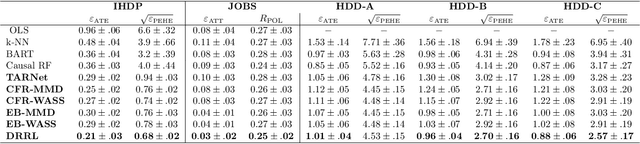
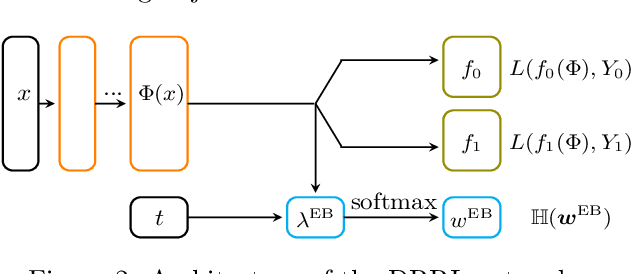

Causal inference, or counterfactual prediction, is central to decision making in healthcare, policy and social sciences. To de-bias causal estimators with high-dimensional data in observational studies, recent advances suggest the importance of combining machine learning models for both the propensity score and the outcome function. We propose a novel scalable method to learn double-robust representations for counterfactual predictions, leading to consistent causal estimation if the model for either the propensity score or the outcome, but not necessarily both, is correctly specified. Specifically, we use the entropy balancing method to learn the weights that minimize the Jensen-Shannon divergence of the representation between the treated and control groups, based on which we make robust and efficient counterfactual predictions for both individual and average treatment effects. We provide theoretical justifications for the proposed method. The algorithm shows competitive performance with the state-of-the-art on real world and synthetic data.
Improving Text Generation with Student-Forcing Optimal Transport
Oct 12, 2020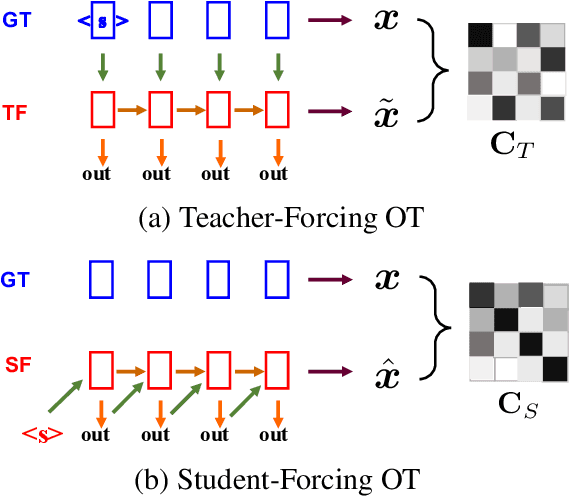
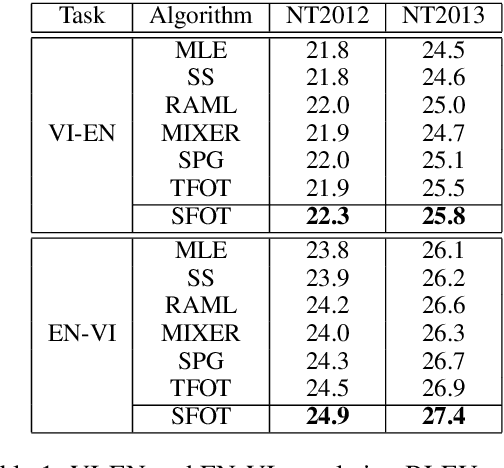
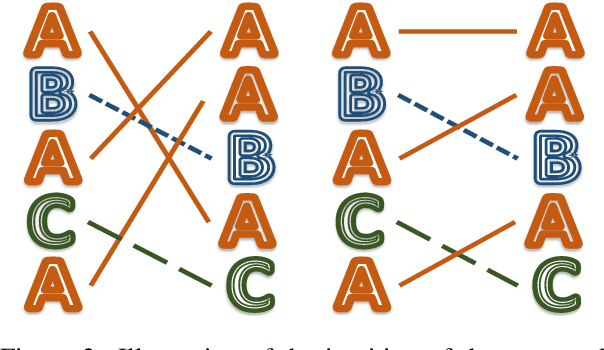
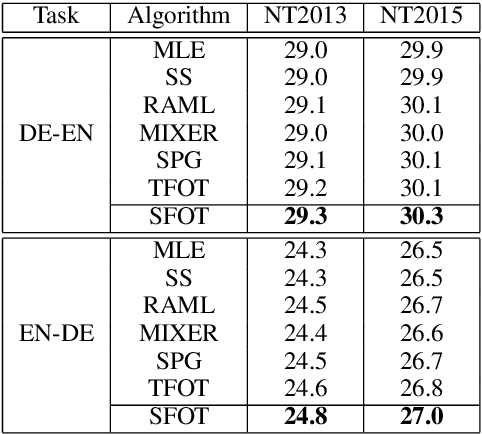
Neural language models are often trained with maximum likelihood estimation (MLE), where the next word is generated conditioned on the ground-truth word tokens. During testing, however, the model is instead conditioned on previously generated tokens, resulting in what is termed exposure bias. To reduce this gap between training and testing, we propose using optimal transport (OT) to match the sequences generated in these two modes. An extension is further proposed to improve the OT learning, based on the structural and contextual information of the text sequences. The effectiveness of the proposed method is validated on machine translation, text summarization, and text generation tasks.
Variational Disentanglement for Rare Event Modeling
Sep 21, 2020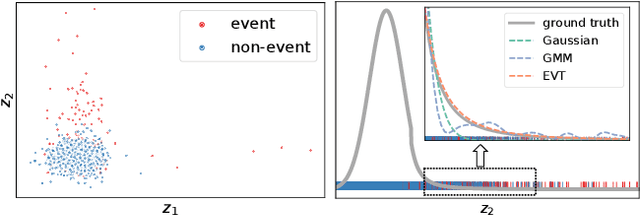


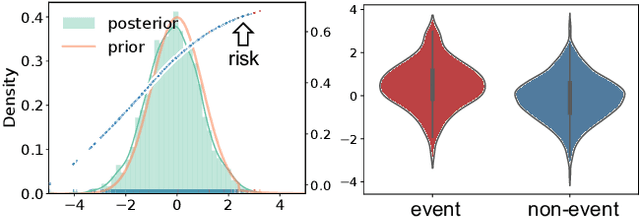
Combining the increasing availability and abundance of healthcare data and the current advances in machine learning methods have created renewed opportunities to improve clinical decision support systems. However, in healthcare risk prediction applications, the proportion of cases with the condition (label) of interest is often very low relative to the available sample size. Though very prevalent in healthcare, such imbalanced classification settings are also common and challenging in many other scenarios. So motivated, we propose a variational disentanglement approach to semi-parametrically learn from rare events in heavily imbalanced classification problems. Specifically, we leverage the imposed extreme-distribution behavior on a latent space to extract information from low-prevalence events, and develop a robust prediction arm that joins the merits of the generalized additive model and isotonic neural nets. Results on synthetic studies and diverse real-world datasets, including mortality prediction on a COVID-19 cohort, demonstrate that the proposed approach outperforms existing alternatives.
Weakly supervised cross-domain alignment with optimal transport
Aug 14, 2020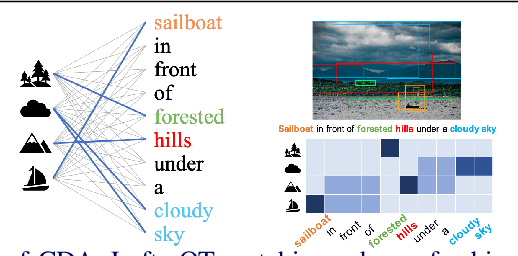
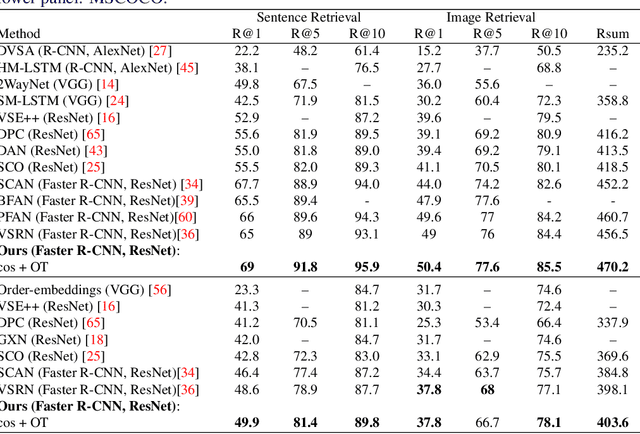
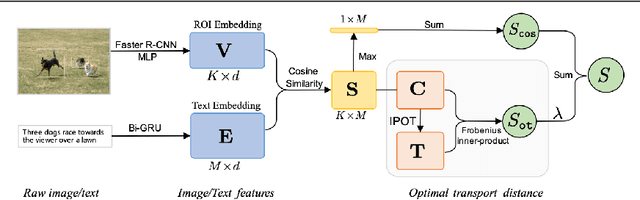
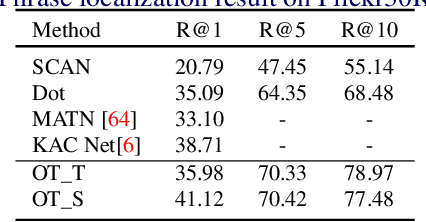
Cross-domain alignment between image objects and text sequences is key to many visual-language tasks, and it poses a fundamental challenge to both computer vision and natural language processing. This paper investigates a novel approach for the identification and optimization of fine-grained semantic similarities between image and text entities, under a weakly-supervised setup, improving performance over state-of-the-art solutions. Our method builds upon recent advances in optimal transport (OT) to resolve the cross-domain matching problem in a principled manner. Formulated as a drop-in regularizer, the proposed OT solution can be efficiently computed and used in combination with other existing approaches. We present empirical evidence to demonstrate the effectiveness of our approach, showing how it enables simpler model architectures to outperform or be comparable with more sophisticated designs on a range of vision-language tasks.