 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
Dec 18, 2025



We present WorldCanvas, a framework for promptable world events that enables rich, user-directed simulation by combining text, trajectories, and reference images. Unlike text-only approaches and existing trajectory-controlled image-to-video methods, our multimodal approach combines trajectories -- encoding motion, timing, and visibility -- with natural language for semantic intent and reference images for visual grounding of object identity, enabling the generation of coherent, controllable events that include multi-agent interactions, object entry/exit, reference-guided appearance and counterintuitive events. The resulting videos demonstrate not only temporal coherence but also emergent consistency, preserving object identity and scene despite temporary disappearance. By supporting expressive world events generation, WorldCanvas advances world models from passive predictors to interactive, user-shaped simulators. Our project page is available at: https://worldcanvas.github.io/.
Near-Zero-Overhead Freshness for Recommendation Systems via Inference-Side Model Updates
Dec 17, 2025Deep Learning Recommendation Models (DLRMs) underpin personalized services but face a critical freshness-accuracy tradeoff due to massive parameter synchronization overheads. Production DLRMs deploy decoupled training/inference clusters, where synchronizing petabyte-scale embedding tables (EMTs) causes multi-minute staleness, degrading recommendation quality and revenue. We observe that (1) inference nodes exhibit sustained CPU underutilization (peak <= 20%), and (2) EMT gradients possess intrinsic low-rank structure, enabling compact update representation. We present LiveUpdate, a system that eliminates inter-cluster synchronization by colocating Low-Rank Adaptation (LoRA) trainers within inference nodes. LiveUpdate addresses two core challenges: (1) dynamic rank adaptation via singular value monitoring to constrain memory overhead (<2% of EMTs), and (2) NUMA-aware resource scheduling with hardware-enforced QoS to eliminate update inference contention (P99 latency impact <20ms). Evaluations show LiveUpdate reduces update costs by 2x versus delta-update baselines while achieving higher accuracy within 1-hour windows. By transforming idle inference resources into freshness engines, LiveUpdate delivers online model updates while outperforming state-of-the-art delta-update methods by 0.04% to 0.24% in accuracy.
Unleashing the Power of Image-Tabular Self-Supervised Learning via Breaking Cross-Tabular Barriers
Dec 16, 2025Multi-modal learning integrating medical images and tabular data has significantly advanced clinical decision-making in recent years. Self-Supervised Learning (SSL) has emerged as a powerful paradigm for pretraining these models on large-scale unlabeled image-tabular data, aiming to learn discriminative representations. However, existing SSL methods for image-tabular representation learning are often confined to specific data cohorts, mainly due to their rigid tabular modeling mechanisms when modeling heterogeneous tabular data. This inter-tabular barrier hinders the multi-modal SSL methods from effectively learning transferrable medical knowledge shared across diverse cohorts. In this paper, we propose a novel SSL framework, namely CITab, designed to learn powerful multi-modal feature representations in a cross-tabular manner. We design the tabular modeling mechanism from a semantic-awareness perspective by integrating column headers as semantic cues, which facilitates transferrable knowledge learning and the scalability in utilizing multiple data sources for pretraining. Additionally, we propose a prototype-guided mixture-of-linear layer (P-MoLin) module for tabular feature specialization, empowering the model to effectively handle the heterogeneity of tabular data and explore the underlying medical concepts. We conduct comprehensive evaluations on Alzheimer's disease diagnosis task across three publicly available data cohorts containing 4,461 subjects. Experimental results demonstrate that CITab outperforms state-of-the-art approaches, paving the way for effective and scalable cross-tabular multi-modal learning.
ViSA: 3D-Aware Video Shading for Real-Time Upper-Body Avatar Creation
Dec 09, 2025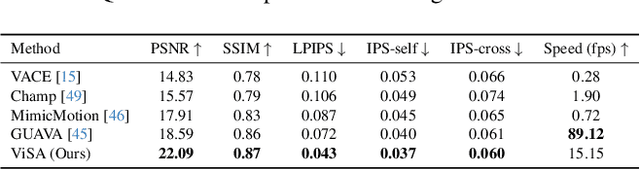
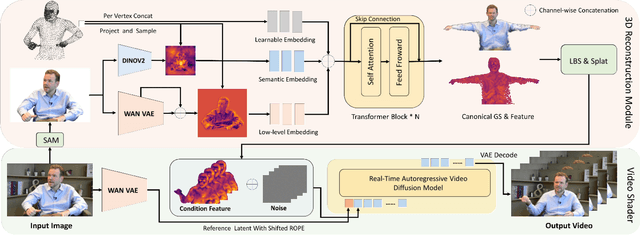
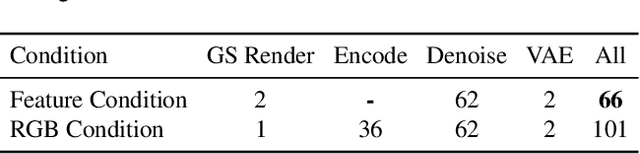
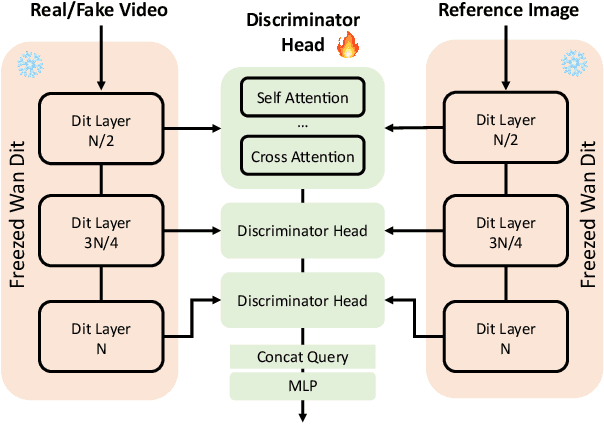
Generating high-fidelity upper-body 3D avatars from one-shot input image remains a significant challenge. Current 3D avatar generation methods, which rely on large reconstruction models, are fast and capable of producing stable body structures, but they often suffer from artifacts such as blurry textures and stiff, unnatural motion. In contrast, generative video models show promising performance by synthesizing photorealistic and dynamic results, but they frequently struggle with unstable behavior, including body structural errors and identity drift. To address these limitations, we propose a novel approach that combines the strengths of both paradigms. Our framework employs a 3D reconstruction model to provide robust structural and appearance priors, which in turn guides a real-time autoregressive video diffusion model for rendering. This process enables the model to synthesize high-frequency, photorealistic details and fluid dynamics in real time, effectively reducing texture blur and motion stiffness while preventing the structural inconsistencies common in video generation methods. By uniting the geometric stability of 3D reconstruction with the generative capabilities of video models, our method produces high-fidelity digital avatars with realistic appearance and dynamic, temporally coherent motion. Experiments demonstrate that our approach significantly reduces artifacts and achieves substantial improvements in visual quality over leading methods, providing a robust and efficient solution for real-time applications such as gaming and virtual reality. Project page: https://lhyfst.github.io/visa
Robust Decentralized Multi-armed Bandits: From Corruption-Resilience to Byzantine-Resilience
Nov 13, 2025Decentralized cooperative multi-agent multi-armed bandits (DeCMA2B) considers how multiple agents collaborate in a decentralized multi-armed bandit setting. Though this problem has been extensively studied in previous work, most existing methods remain susceptible to various adversarial attacks. In this paper, we first study DeCMA2B with adversarial corruption, where an adversary can corrupt reward observations of all agents with a limited corruption budget. We propose a robust algorithm, called DeMABAR, which ensures that each agent's individual regret suffers only an additive term proportional to the corruption budget. Then we consider a more realistic scenario where the adversary can only attack a small number of agents. Our theoretical analysis shows that the DeMABAR algorithm can also almost completely eliminate the influence of adversarial attacks and is inherently robust in the Byzantine setting, where an unknown fraction of the agents can be Byzantine, i.e., may arbitrarily select arms and communicate wrong information. We also conduct numerical experiments to illustrate the robustness and effectiveness of the proposed method.
AgentEvolver: Towards Efficient Self-Evolving Agent System
Nov 13, 2025Autonomous agents powered by large language models (LLMs) have the potential to significantly enhance human productivity by reasoning, using tools, and executing complex tasks in diverse environments. However, current approaches to developing such agents remain costly and inefficient, as they typically require manually constructed task datasets and reinforcement learning (RL) pipelines with extensive random exploration. These limitations lead to prohibitively high data-construction costs, low exploration efficiency, and poor sample utilization. To address these challenges, we present AgentEvolver, a self-evolving agent system that leverages the semantic understanding and reasoning capabilities of LLMs to drive autonomous agent learning. AgentEvolver introduces three synergistic mechanisms: (i) self-questioning, which enables curiosity-driven task generation in novel environments, reducing dependence on handcrafted datasets; (ii) self-navigating, which improves exploration efficiency through experience reuse and hybrid policy guidance; and (iii) self-attributing, which enhances sample efficiency by assigning differentiated rewards to trajectory states and actions based on their contribution. By integrating these mechanisms into a unified framework, AgentEvolver enables scalable, cost-effective, and continual improvement of agent capabilities. Preliminary experiments indicate that AgentEvolver achieves more efficient exploration, better sample utilization, and faster adaptation compared to traditional RL-based baselines.
HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives
Oct 23, 2025State-of-the-art text-to-video models excel at generating isolated clips but fall short of creating the coherent, multi-shot narratives, which are the essence of storytelling. We bridge this "narrative gap" with HoloCine, a model that generates entire scenes holistically to ensure global consistency from the first shot to the last. Our architecture achieves precise directorial control through a Window Cross-Attention mechanism that localizes text prompts to specific shots, while a Sparse Inter-Shot Self-Attention pattern (dense within shots but sparse between them) ensures the efficiency required for minute-scale generation. Beyond setting a new state-of-the-art in narrative coherence, HoloCine develops remarkable emergent abilities: a persistent memory for characters and scenes, and an intuitive grasp of cinematic techniques. Our work marks a pivotal shift from clip synthesis towards automated filmmaking, making end-to-end cinematic creation a tangible future. Our code is available at: https://holo-cine.github.io/.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
UniSearch: Rethinking Search System with a Unified Generative Architecture
Sep 10, 2025



Modern search systems play a crucial role in facilitating information acquisition. Traditional search engines typically rely on a cascaded architecture, where results are retrieved through recall, pre-ranking, and ranking stages. The complexity of designing and maintaining multiple modules makes it difficult to achieve holistic performance gains. Recent advances in generative recommendation have motivated the exploration of unified generative search as an alternative. However, existing approaches are not genuinely end-to-end: they typically train an item encoder to tokenize candidates first and then optimize a generator separately, leading to objective inconsistency and limited generalization. To address these limitations, we propose UniSearch, a unified generative search framework for Kuaishou Search. UniSearch replaces the cascaded pipeline with an end-to-end architecture that integrates a Search Generator and a Video Encoder. The Generator produces semantic identifiers of relevant items given a user query, while the Video Encoder learns latent item embeddings and provides their tokenized representations. A unified training framework jointly optimizes both components, enabling mutual enhancement and improving representation quality and generation accuracy. Furthermore, we introduce Search Preference Optimization (SPO), which leverages a reward model and real user feedback to better align generation with user preferences. Extensive experiments on industrial-scale datasets, together with online A/B testing in both short-video and live search scenarios, demonstrate the strong effectiveness and deployment potential of UniSearch. Notably, its deployment in live search yields the largest single-experiment improvement in recent years of our product's history, highlighting its practical value for real-world applications.
Decentralized Stochastic Nonconvex Optimization under the Relaxed Smoothness
Sep 10, 2025This paper studies decentralized optimization problem $f(\mathbf{x})=\frac{1}{m}\sum_{i=1}^m f_i(\mathbf{x})$, where each local function has the form of $f_i(\mathbf{x}) = {\mathbb E}\left[F(\mathbf{x};{\xi}_i)\right]$ which is $(L_0,L_1)$-smooth but possibly nonconvex and the random variable ${\xi}_i$ follows distribution ${\mathcal D}_i$. We propose a novel algorithm called decentralized normalized stochastic gradient descent (DNSGD), which can achieve the $\epsilon$-stationary point on each local agent. We present a new framework for analyzing decentralized first-order methods in the relaxed smooth setting, based on the Lyapunov function related to the product of the gradient norm and the consensus error. The analysis shows upper bounds on sample complexity of ${\mathcal O}(m^{-1}(L_f\sigma^2\Delta_f\epsilon^{-4} + \sigma^2\epsilon^{-2} + L_f^{-2}L_1^3\sigma^2\Delta_f\epsilon^{-1} + L_f^{-2}L_1^2\sigma^2))$ per agent and communication complexity of $\tilde{\mathcal O}((L_f\epsilon^{-2} + L_1\epsilon^{-1})\gamma^{-1/2}\Delta_f)$, where $L_f=L_0 +L_1\zeta$, $\sigma^2$ is the variance of the stochastic gradient, $\Delta_f$ is the initial optimal function value gap, $\gamma$ is the spectral gap of the network, and $\zeta$ is the degree of the gradient dissimilarity. In the special case of $L_1=0$, the above results (nearly) match the lower bounds on decentralized nonconvex optimization in the standard smooth setting. We also conduct numerical experiments to show the empirical superiority of our method.