 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandit Learning in Matching Markets with Interviews
Feb 12, 2026Two-sided matching markets rely on preferences from both sides, yet it is often impractical to evaluate preferences. Participants, therefore, conduct a limited number of interviews, which provide early, noisy impressions and shape final decisions. We study bandit learning in matching markets with interviews, modeling interviews as \textit{low-cost hints} that reveal partial preference information to both sides. Our framework departs from existing work by allowing firm-side uncertainty: firms, like agents, may be unsure of their own preferences and can make early hiring mistakes by hiring less preferred agents. To handle this, we extend the firm's action space to allow \emph{strategic deferral} (choosing not to hire in a round), enabling recovery from suboptimal hires and supporting decentralized learning without coordination. We design novel algorithms for (i) a centralized setting with an omniscient interview allocator and (ii) decentralized settings with two types of firm-side feedback. Across all settings, our algorithms achieve time-independent regret, a substantial improvement over the $O(\log T)$ regret bounds known for learning stable matchings without interviews. Also, under mild structured markets, decentralized performance matches the centralized counterpart up to polynomial factors in the number of agents and firms.
Offline Clustering of Preference Learning with Active-data Augmentation
Oct 30, 2025



Preference learning from pairwise feedback is a widely adopted framework in applications such as reinforcement learning with human feedback and recommendations. In many practical settings, however, user interactions are limited or costly, making offline preference learning necessary. Moreover, real-world preference learning often involves users with different preferences. For example, annotators from different backgrounds may rank the same responses differently. This setting presents two central challenges: (1) identifying similarity across users to effectively aggregate data, especially under scenarios where offline data is imbalanced across dimensions, and (2) handling the imbalanced offline data where some preference dimensions are underrepresented. To address these challenges, we study the Offline Clustering of Preference Learning problem, where the learner has access to fixed datasets from multiple users with potentially different preferences and aims to maximize utility for a test user. To tackle the first challenge, we first propose Off-C$^2$PL for the pure offline setting, where the learner relies solely on offline data. Our theoretical analysis provides a suboptimality bound that explicitly captures the tradeoff between sample noise and bias. To address the second challenge of inbalanced data, we extend our framework to the setting with active-data augmentation where the learner is allowed to select a limited number of additional active-data for the test user based on the cluster structure learned by Off-C$^2$PL. In this setting, our second algorithm, A$^2$-Off-C$^2$PL, actively selects samples that target the least-informative dimensions of the test user's preference. We prove that these actively collected samples contribute more effectively than offline ones. Finally, we validate our theoretical results through simulations on synthetic and real-world datasets.
Learning Best Paths in Quantum Networks
Jun 14, 2025


Quantum networks (QNs) transmit delicate quantum information across noisy quantum channels. Crucial applications, like quantum key distribution (QKD) and distributed quantum computation (DQC), rely on efficient quantum information transmission. Learning the best path between a pair of end nodes in a QN is key to enhancing such applications. This paper addresses learning the best path in a QN in the online learning setting. We explore two types of feedback: "link-level" and "path-level". Link-level feedback pertains to QNs with advanced quantum switches that enable link-level benchmarking. Path-level feedback, on the other hand, is associated with basic quantum switches that permit only path-level benchmarking. We introduce two online learning algorithms, BeQuP-Link and BeQuP-Path, to identify the best path using link-level and path-level feedback, respectively. To learn the best path, BeQuP-Link benchmarks the critical links dynamically, while BeQuP-Path relies on a subroutine, transferring path-level observations to estimate link-level parameters in a batch manner. We analyze the quantum resource complexity of these algorithms and demonstrate that both can efficiently and, with high probability, determine the best path. Finally, we perform NetSquid-based simulations and validate that both algorithms accurately and efficiently identify the best path.
Practical Adversarial Attacks on Stochastic Bandits via Fake Data Injection
May 28, 2025Adversarial attacks on stochastic bandits have traditionally relied on some unrealistic assumptions, such as per-round reward manipulation and unbounded perturbations, limiting their relevance to real-world systems. We propose a more practical threat model, Fake Data Injection, which reflects realistic adversarial constraints: the attacker can inject only a limited number of bounded fake feedback samples into the learner's history, simulating legitimate interactions. We design efficient attack strategies under this model, explicitly addressing both magnitude constraints (on reward values) and temporal constraints (on when and how often data can be injected). Our theoretical analysis shows that these attacks can mislead both Upper Confidence Bound (UCB) and Thompson Sampling algorithms into selecting a target arm in nearly all rounds while incurring only sublinear attack cost. Experiments on synthetic and real-world datasets validate the effectiveness of our strategies, revealing significant vulnerabilities in widely used stochastic bandit algorithms under practical adversarial scenarios.
Offline Clustering of Linear Bandits: Unlocking the Power of Clusters in Data-Limited Environments
May 25, 2025Contextual linear multi-armed bandits are a learning framework for making a sequence of decisions, e.g., advertising recommendations for a sequence of arriving users. Recent works have shown that clustering these users based on the similarity of their learned preferences can significantly accelerate the learning. However, prior work has primarily focused on the online setting, which requires continually collecting user data, ignoring the offline data widely available in many applications. To tackle these limitations, we study the offline clustering of bandits (Off-ClusBand) problem, which studies how to use the offline dataset to learn cluster properties and improve decision-making across multiple users. The key challenge in Off-ClusBand arises from data insufficiency for users: unlike the online case, in the offline case, we have a fixed, limited dataset to work from and thus must determine whether we have enough data to confidently cluster users together. To address this challenge, we propose two algorithms: Off-C$^2$LUB, which we analytically show performs well for arbitrary amounts of user data, and Off-CLUB, which is prone to bias when data is limited but, given sufficient data, matches a theoretical lower bound that we derive for the offline clustered MAB problem. We experimentally validate these results on both real and synthetic datasets.
Fusing Reward and Dueling Feedback in Stochastic Bandits
Apr 22, 2025This paper investigates the fusion of absolute (reward) and relative (dueling) feedback in stochastic bandits, where both feedback types are gathered in each decision round. We derive a regret lower bound, demonstrating that an efficient algorithm may incur only the smaller among the reward and dueling-based regret for each individual arm. We propose two fusion approaches: (1) a simple elimination fusion algorithm that leverages both feedback types to explore all arms and unifies collected information by sharing a common candidate arm set, and (2) a decomposition fusion algorithm that selects the more effective feedback to explore the corresponding arms and randomly assigns one feedback type for exploration and the other for exploitation in each round. The elimination fusion experiences a suboptimal multiplicative term of the number of arms in regret due to the intrinsic suboptimality of dueling elimination. In contrast, the decomposition fusion achieves regret matching the lower bound up to a constant under a common assumption. Extensive experiments confirm the efficacy of our algorithms and theoretical results.
Heterogeneous Multi-Agent Bandits with Parsimonious Hints
Feb 22, 2025



We study a hinted heterogeneous multi-agent multi-armed bandits problem (HMA2B), where agents can query low-cost observations (hints) in addition to pulling arms. In this framework, each of the $M$ agents has a unique reward distribution over $K$ arms, and in $T$ rounds, they can observe the reward of the arm they pull only if no other agent pulls that arm. The goal is to maximize the total utility by querying the minimal necessary hints without pulling arms, achieving time-independent regret. We study HMA2B in both centralized and decentralized setups. Our main centralized algorithm, GP-HCLA, which is an extension of HCLA, uses a central decision-maker for arm-pulling and hint queries, achieving $O(M^4K)$ regret with $O(MK\log T)$ adaptive hints. In decentralized setups, we propose two algorithms, HD-ETC and EBHD-ETC, that allow agents to choose actions independently through collision-based communication and query hints uniformly until stopping, yielding $O(M^3K^2)$ regret with $O(M^3K\log T)$ hints, where the former requires knowledge of the minimum gap and the latter does not. Finally, we establish lower bounds to prove the optimality of our results and verify them through numerical simulations.
Heterogeneous Multi-agent Multi-armed Bandits on Stochastic Block Models
Feb 11, 2025
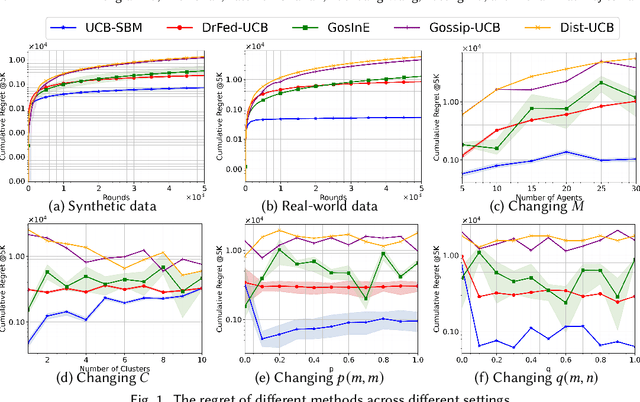
We study a novel heterogeneous multi-agent multi-armed bandit problem with a cluster structure induced by stochastic block models, influencing not only graph topology, but also reward heterogeneity. Specifically, agents are distributed on random graphs based on stochastic block models - a generalized Erdos-Renyi model with heterogeneous edge probabilities: agents are grouped into clusters (known or unknown); edge probabilities for agents within the same cluster differ from those across clusters. In addition, the cluster structure in stochastic block model also determines our heterogeneous rewards. Rewards distributions of the same arm vary across agents in different clusters but remain consistent within a cluster, unifying homogeneous and heterogeneous settings and varying degree of heterogeneity, and rewards are independent samples from these distributions. The objective is to minimize system-wide regret across all agents. To address this, we propose a novel algorithm applicable to both known and unknown cluster settings. The algorithm combines an averaging-based consensus approach with a newly introduced information aggregation and weighting technique, resulting in a UCB-type strategy. It accounts for graph randomness, leverages both intra-cluster (homogeneous) and inter-cluster (heterogeneous) information from rewards and graphs, and incorporates cluster detection for unknown cluster settings. We derive optimal instance-dependent regret upper bounds of order $\log{T}$ under sub-Gaussian rewards. Importantly, our regret bounds capture the degree of heterogeneity in the system (an additional layer of complexity), exhibit smaller constants, scale better for large systems, and impose significantly relaxed assumptions on edge probabilities. In contrast, prior works have not accounted for this refined problem complexity, rely on more stringent assumptions, and exhibit limited scalability.
Multi-Agent Conversational Online Learning for Adaptive LLM Response Identification
Jan 03, 2025



The remarkable generative capability of large language models (LLMs) has sparked a growing interest in automatically generating responses for different applications. Given the dynamic nature of user preferences and the uncertainty of LLM response performance, it is crucial to design efficient online learning algorithms to identify optimal LLM responses (i.e., high-quality responses that also meet user preferences). Most existing online algorithms adopt a centralized approach and fail to leverage explicit user preferences for more efficient and personalized LLM response identification. In contrast, this paper introduces \textit{MACO} (\underline{M}ulti-\underline{A}gent \underline{C}onversational \underline{O}nline Learning for Adaptive LLM Response Identification): 1) The online LLM response identification process is accelerated by multiple local agents (such as smartphones), while enhancing data privacy; 2) A novel conversational mechanism is proposed to adaptively conduct conversations for soliciting user preferences (e.g., a preference for a humorous tone over a serious one in generated responses), so to minimize uncertainty in preference estimation. Our theoretical analysis demonstrates that \cadi\ is near-optimal regarding cumulative regret. Additionally, \cadi\ offers reduced communication costs and computational complexity by eliminating the traditional, computing-intensive ``G-optimal design" found in previous works. Extensive experiments with the open LLM \textit{Llama}, coupled with two different embedding models from Google and OpenAI for text vector representation, demonstrate that \cadi\ significantly outperforms the current state-of-the-art in online LLM response identification.
Multi-Agent Stochastic Bandits Robust to Adversarial Corruptions
Nov 12, 2024We study the problem of multi-agent multi-armed bandits with adversarial corruption in a heterogeneous setting, where each agent accesses a subset of arms. The adversary can corrupt the reward observations for all agents. Agents share these corrupted rewards with each other, and the objective is to maximize the cumulative total reward of all agents (and not be misled by the adversary). We propose a multi-agent cooperative learning algorithm that is robust to adversarial corruptions. For this newly devised algorithm, we demonstrate that an adversary with an unknown corruption budget $C$ only incurs an additive $O((L / L_{\min}) C)$ term to the standard regret of the model in non-corruption settings, where $L$ is the total number of agents, and $L_{\min}$ is the minimum number of agents with mutual access to an arm. As a side-product, our algorithm also improves the state-of-the-art regret bounds when reducing to both the single-agent and homogeneous multi-agent scenarios, tightening multiplicative $K$ (the number of arms) and $L$ (the number of agents) factors, respectively.