 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlueGen: Plug and Play Multi-modal Encoders for X-to-image Generation
Mar 17, 2023Text-to-image (T2I) models based on diffusion processes have achieved remarkable success in controllable image generation using user-provided captions. However, the tight coupling between the current text encoder and image decoder in T2I models makes it challenging to replace or upgrade. Such changes often require massive fine-tuning or even training from scratch with the prohibitive expense. To address this problem, we propose GlueGen, which applies a newly proposed GlueNet model to align features from single-modal or multi-modal encoders with the latent space of an existing T2I model. The approach introduces a new training objective that leverages parallel corpora to align the representation spaces of different encoders. Empirical results show that GlueNet can be trained efficiently and enables various capabilities beyond previous state-of-the-art models: 1) multilingual language models such as XLM-Roberta can be aligned with existing T2I models, allowing for the generation of high-quality images from captions beyond English; 2) GlueNet can align multi-modal encoders such as AudioCLIP with the Stable Diffusion model, enabling sound-to-image generation; 3) it can also upgrade the current text encoder of the latent diffusion model for challenging case generation. By the alignment of various feature representations, the GlueNet allows for flexible and efficient integration of new functionality into existing T2I models and sheds light on X-to-image (X2I) generation.
ULIP: Learning Unified Representation of Language, Image and Point Cloud for 3D Understanding
Dec 10, 2022



The understanding capabilities of current state-of-the-art 3D models are limited by datasets with a small number of annotated data and a pre-defined set of categories. In its 2D counterpart, recent advances have shown that similar problems can be significantly alleviated by employing knowledge from other modalities, such as language. Inspired by this, leveraging multimodal information for 3D modality could be promising to improve 3D understanding under the restricted data regime, but this line of research is not well studied. Therefore, we introduce ULIP to learn a unified representation of image, text, and 3D point cloud by pre-training with object triplets from the three modalities. To overcome the shortage of training triplets, ULIP leverages a pre-trained vision-language model that has already learned a common visual and textual space by training with massive image-text pairs. Then, ULIP learns a 3D representation space aligned with the common image-text space, using a small number of automatically synthesized triplets. ULIP is agnostic to 3D backbone networks and can easily be integrated into any 3D architecture. Experiments show that ULIP effectively improves the performance of multiple recent 3D backbones by simply pre-training them on ShapeNet55 using our framework, achieving state-of-the-art performance in both standard 3D classification and zero-shot 3D classification on ModelNet40 and ScanObjectNN. ULIP also improves the performance of PointMLP by around 3% in 3D classification on ScanObjectNN, and outperforms PointCLIP by 28.8% on top-1 accuracy for zero-shot 3D classification on ModelNet40. Our code and pre-trained models will be released.
Model ensemble instead of prompt fusion: a sample-specific knowledge transfer method for few-shot prompt tuning
Oct 23, 2022Prompt tuning approaches, which learn task-specific soft prompts for a downstream task conditioning on frozen pre-trained models, have attracted growing interest due to its parameter efficiency. With large language models and sufficient training data, prompt tuning performs comparably to full-model tuning. However, with limited training samples in few-shot settings, prompt tuning fails to match the performance of full-model fine-tuning. In this work, we focus on improving the few-shot performance of prompt tuning by transferring knowledge from soft prompts of source tasks. Recognizing the good generalization capabilities of ensemble methods in low-data regime, we first experiment and show that a simple ensemble of model predictions based on different source prompts, outperforms existing multi-prompt knowledge transfer approaches such as source prompt fusion in the few-shot setting. Motivated by this observation, we further investigate model ensembles and propose Sample-specific Ensemble of Source Models (SESoM). SESoM learns to adjust the contribution of each source model for each target sample separately when ensembling source model outputs. Through this way, SESoM inherits the superior generalization of model ensemble approaches and simultaneously captures the sample-specific competence of each source prompt. We conduct experiments across a diverse set of eight NLP tasks using models of different scales (T5-{base, large, XL}) and find that SESoM consistently outperforms the existing models of the same as well as larger parametric scale by a large margin.
Value Retrieval with Arbitrary Queries for Form-like Documents
Dec 15, 2021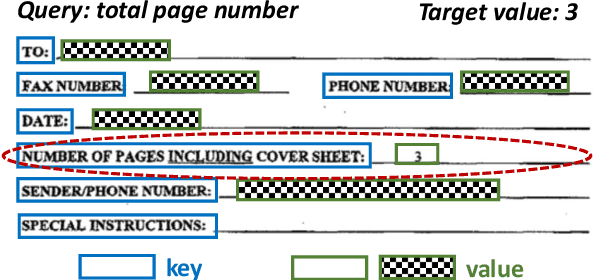

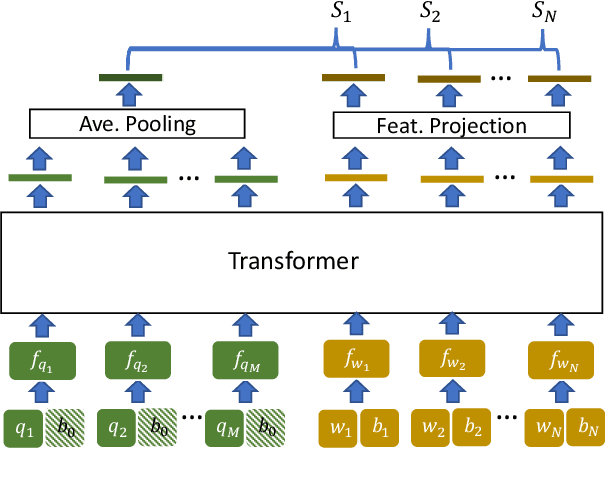
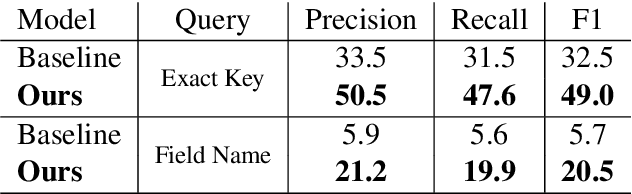
We propose value retrieval with arbitrary queries for form-like documents to reduce human effort of processing forms. Unlike previous methods that only address a fixed set of field items, our method predicts target value for an arbitrary query based on the understanding of layout and semantics of a form. To further boost model performance, we propose a simple document language modeling (simpleDLM) strategy to improve document understanding on large-scale model pre-training. Experimental results show that our method outperforms our baselines significantly and the simpleDLM further improves our performance on value retrieval by around 17\% F1 score compared with the state-of-the-art pre-training method. Code will be made publicly available.
Towards Open Vocabulary Object Detection without Human-provided Bounding Boxes
Nov 18, 2021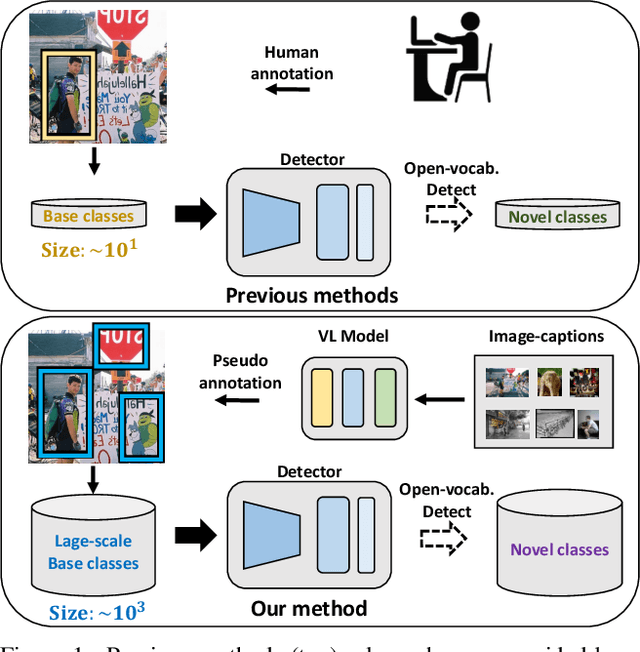
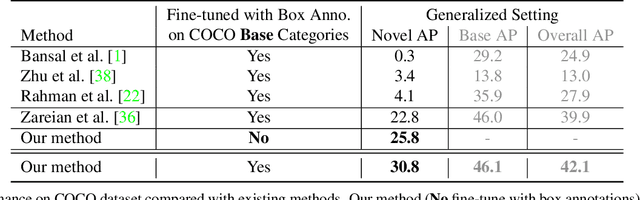
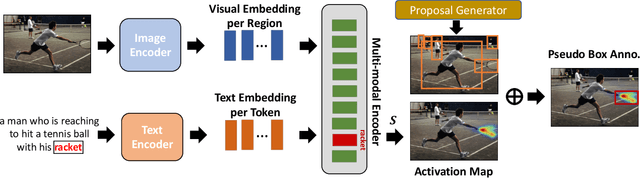
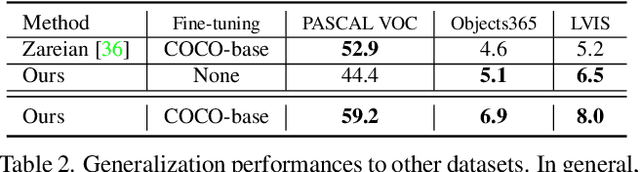
Despite great progress in object detection, most existing methods are limited to a small set of object categories, due to the tremendous human effort needed for instance-level bounding-box annotation. To alleviate the problem, recent open vocabulary and zero-shot detection methods attempt to detect object categories not seen during training. However, these approaches still rely on manually provided bounding-box annotations on a set of base classes. We propose an open vocabulary detection framework that can be trained without manually provided bounding-box annotations. Our method achieves this by leveraging the localization ability of pre-trained vision-language models and generating pseudo bounding-box labels that can be used directly for training object detectors. Experimental results on COCO, PASCAL VOC, Objects365 and LVIS demonstrate the effectiveness of our method. Specifically, our method outperforms the state-of-the-arts (SOTA) that are trained using human annotated bounding-boxes by 3% AP on COCO novel categories even though our training source is not equipped with manual bounding-box labels. When utilizing the manual bounding-box labels as our baselines do, our method surpasses the SOTA largely by 8% AP.
Improving Gender Fairness of Pre-Trained Language Models without Catastrophic Forgetting
Oct 11, 2021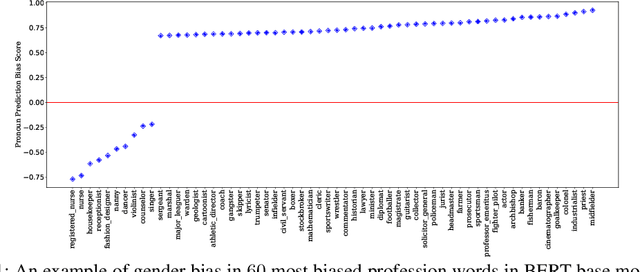

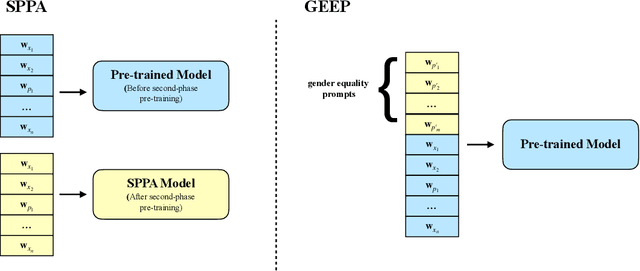
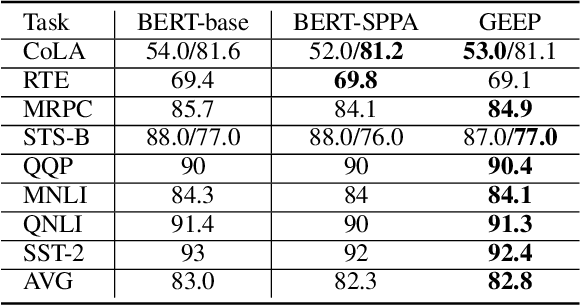
Although pre-trained language models, such as BERT, achieve state-of-art performance in many language understanding tasks, they have been demonstrated to inherit strong gender bias from its training data. Existing studies addressing the gender bias issue of pre-trained models, usually recollect and build gender-neutral data on their own and conduct a second phase pre-training on the released pre-trained model with such data. However, given the limited size of the gender-neutral data and its potential distributional mismatch with the original pre-training data, catastrophic forgetting would occur during the second-phase pre-training. Forgetting on the original training data may damage the model's downstream performance to a large margin. In this work, we first empirically show that even if the gender-neutral data for second-phase pre-training comes from the original training data, catastrophic forgetting still occurs if the size of gender-neutral data is smaller than that of original training data. Then, we propose a new method, GEnder Equality Prompt (GEEP), to improve gender fairness of pre-trained models without forgetting. GEEP learns gender-related prompts to reduce gender bias, conditioned on frozen language models. Since all pre-trained parameters are frozen, forgetting on information from the original training data can be alleviated to the most extent. Then GEEP trains new embeddings of profession names as gender equality prompts conditioned on the frozen model. Empirical results show that GEEP not only achieves state-of-the-art performances on gender debiasing in various applications such as pronoun predicting and coreference resolution, but also achieves comparable results on general downstream tasks such as GLUE with original pre-trained models without much forgetting.
Focusing More on Conflicts with Mis-Predictions Helps Language Pre-Training
Dec 16, 2020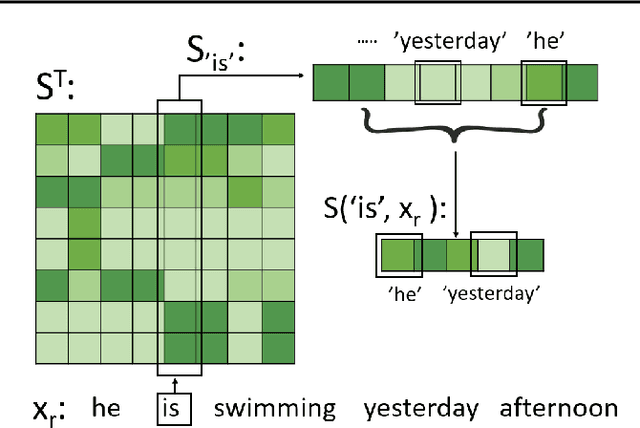
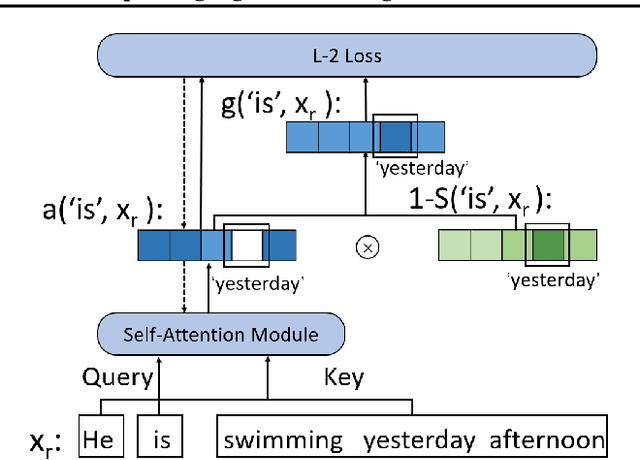
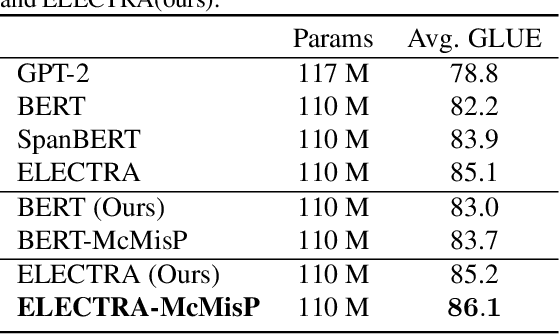
In this work, we propose to improve the effectiveness of language pre-training methods with the help of mis-predictions during pre-training. Neglecting words in the input sentence that have conflicting semantics with mis-predictions is likely to be the reason of generating mis-predictions at pre-training. Therefore, we hypothesis that mis-predictions during pre-training can act as detectors of the ill focuses of the model. If we train the model to focus more on the conflicts with the mis-predictions while focus less on the rest words in the input sentence, the mis-predictions can be more easily corrected and the entire model could be better trained. Towards this end, we introduce Focusing Less on Context of Mis-predictions(McMisP). In McMisP, we record the co-occurrence information between words to detect the conflicting words with mis-predictions in an unsupervised way. Then McMisP uses such information to guide the attention modules when a mis-prediction occurs. Specifically, several attention modules in the Transformer are optimized to focus more on words in the input sentence that have co-occurred rarely with the mis-predictions and vice versa. Results show that McMisP significantly expedites BERT and ELECTRA and improves their performances on downstream tasks.
Taking Notes on the Fly Helps BERT Pre-training
Aug 04, 2020
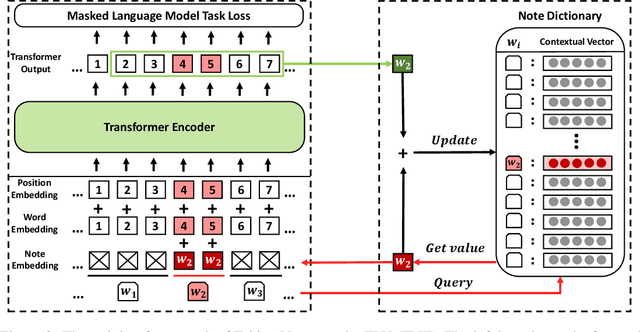

How to make unsupervised language pre-training more efficient and less resource-intensive is an important research direction in NLP. In this paper, we focus on improving the efficiency of language pre-training methods through providing better data utilization. It is well-known that in language data corpus, words follow a heavy-tail distribution. A large proportion of words appear only very few times and the embeddings of rare words are usually poorly optimized. We argue that such embeddings carry inadequate semantic signals. They could make the data utilization inefficient and slow down the pre-training of the entire model. To solve this problem, we propose Taking Notes on the Fly (TNF). TNF takes notes for rare words on the fly during pre-training to help the model understand them when they occur next time. Specifically, TNF maintains a note dictionary and saves a rare word's context information in it as notes when the rare word occurs in a sentence. When the same rare word occurs again in training, TNF employs the note information saved beforehand to enhance the semantics of the current sentence. By doing so, TNF provides a better data utilization since cross-sentence information is employed to cover the inadequate semantics caused by rare words in the sentences. Experimental results show that TNF significantly expedite the BERT pre-training and improve the model's performance on downstream tasks. TNF's training time is $60\%$ less than BERT when reaching the same performance. When trained with same number of iterations, TNF significantly outperforms BERT on most of downstream tasks and the average GLUE score.
On Layer Normalization in the Transformer Architecture
Feb 12, 2020

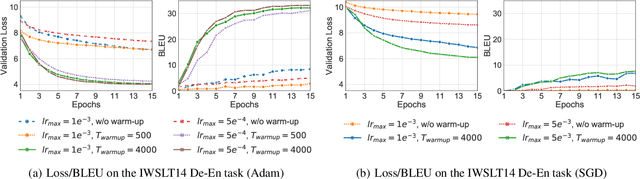

The Transformer is widely used in natural language processing tasks. To train a Transformer however, one usually needs a carefully designed learning rate warm-up stage, which is shown to be crucial to the final performance but will slow down the optimization and bring more hyper-parameter tunings. In this paper, we first study theoretically why the learning rate warm-up stage is essential and show that the location of layer normalization matters. Specifically, we prove with mean field theory that at initialization, for the original-designed Post-LN Transformer, which places the layer normalization between the residual blocks, the expected gradients of the parameters near the output layer are large. Therefore, using a large learning rate on those gradients makes the training unstable. The warm-up stage is practically helpful for avoiding this problem. On the other hand, our theory also shows that if the layer normalization is put inside the residual blocks (recently proposed as Pre-LN Transformer), the gradients are well-behaved at initialization. This motivates us to remove the warm-up stage for the training of Pre-LN Transformers. We show in our experiments that Pre-LN Transformers without the warm-up stage can reach comparable results with baselines while requiring significantly less training time and hyper-parameter tuning on a wide range of applications.
Distance-Based Learning from Errors for Confidence Calibration
Dec 03, 2019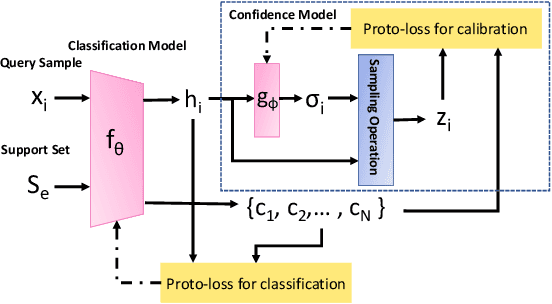
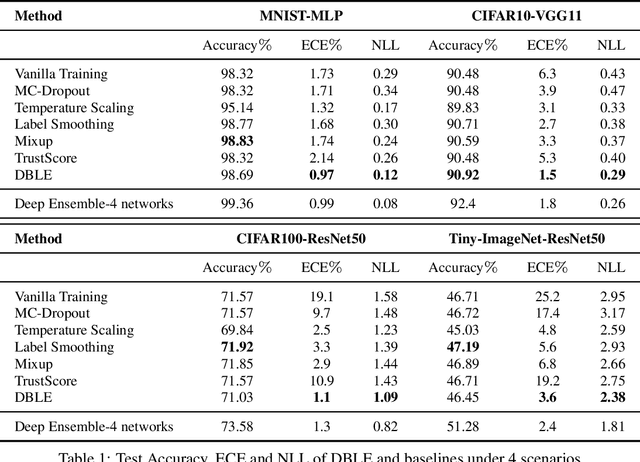
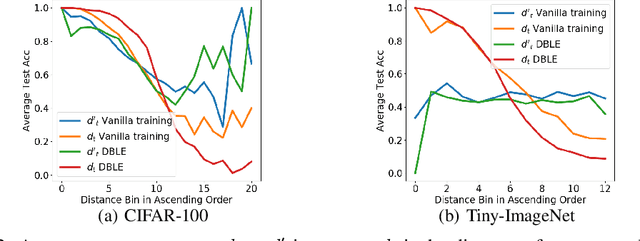

Deep neural networks (DNNs) are poorly-calibrated when trained in conventional ways. To improve confidence calibration of DNNs, we propose a novel training method, distance-based learning from errors (DBLE). DBLE bases its confidence estimation on distances in the representation space. We first adapt prototypical learning for training of a classification model for DBLE. It yields a representation space where the distance from a test sample to its ground-truth class center can calibrate the model performance. At inference, however, these distances are not available due to the lack of ground-truth labels. To circumvent this by approximately inferring the distance for every test sample, we propose to train a confidence model jointly with the classification model by merely learning from mis-classified training samples, which we show to be highly beneficial for effective learning. On multiple datasets and DNN architectures, we demonstrate that DBLE outperforms alternative single-modal confidence calibration approaches. DBLE also achieves comparable performance with computationally-expensive ensemble approaches with lower computational cost and lower number of parameters.