 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Inversion Transcript: Leveraging Robust Generative Priors to Reconstruct Training Data from Gradient Leakage
May 26, 2025We propose Gradient Inversion Transcript (GIT), a novel generative approach for reconstructing training data from leaked gradients. GIT employs a generative attack model, whose architecture is tailored to align with the structure of the leaked model based on theoretical analysis. Once trained offline, GIT can be deployed efficiently and only relies on the leaked gradients to reconstruct the input data, rendering it applicable under various distributed learning environments. When used as a prior for other iterative optimization-based methods, GIT not only accelerates convergence but also enhances the overall reconstruction quality. GIT consistently outperforms existing methods across multiple datasets and demonstrates strong robustness under challenging conditions, including inaccurate gradients, data distribution shifts and discrepancies in model parameters.
Creativity or Brute Force? Using Brainteasers as a Window into the Problem-Solving Abilities of Large Language Models
May 16, 2025



Accuracy remains a standard metric for evaluating AI systems, but it offers limited insight into how models arrive at their solutions. In this work, we introduce a benchmark based on brainteasers written in long narrative form to probe more deeply into the types of reasoning strategies that models use. Brainteasers are well-suited for this goal because they can be solved with multiple approaches, such as a few-step solution that uses a creative insight or a longer solution that uses more brute force. We investigate large language models (LLMs) across multiple layers of reasoning, focusing not only on correctness but also on the quality and creativity of their solutions. We investigate many aspects of the reasoning process: (1) semantic parsing of the brainteasers into precise mathematical competition style formats; (2) generating solutions from these mathematical forms; (3) self-correcting solutions based on gold solutions; (4) producing step-by-step sketches of solutions; and (5) making use of hints. We find that LLMs are in many cases able to find creative, insightful solutions to brainteasers, suggesting that they capture some of the capacities needed to solve novel problems in creative ways. Nonetheless, there also remain situations where they rely on brute force despite the availability of more efficient, creative solutions, highlighting a potential direction for improvement in the reasoning abilities of LLMs.
Behind Maya: Building a Multilingual Vision Language Model
May 15, 2025
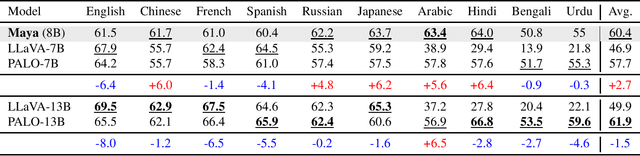
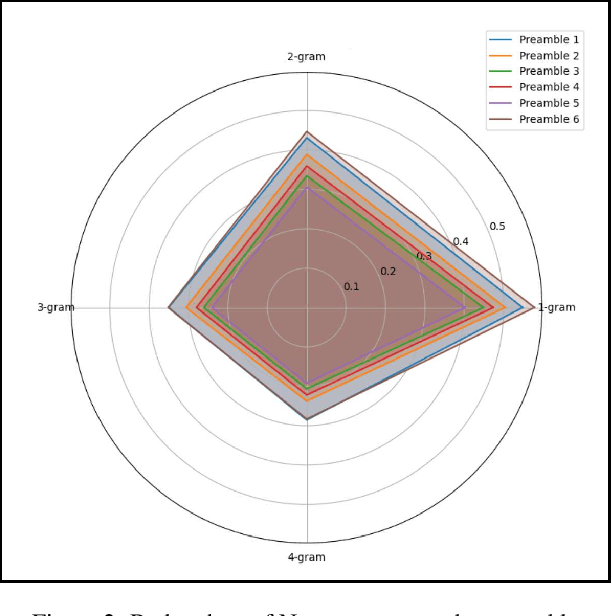

In recent times, we have seen a rapid development of large Vision-Language Models (VLMs). They have shown impressive results on academic benchmarks, primarily in widely spoken languages but lack performance on low-resource languages and varied cultural contexts. To address these limitations, we introduce Maya, an open-source Multilingual VLM. Our contributions are: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; and 2) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.
DualOptim: Enhancing Efficacy and Stability in Machine Unlearning with Dual Optimizers
Apr 22, 2025Existing machine unlearning (MU) approaches exhibit significant sensitivity to hyperparameters, requiring meticulous tuning that limits practical deployment. In this work, we first empirically demonstrate the instability and suboptimal performance of existing popular MU methods when deployed in different scenarios. To address this issue, we propose Dual Optimizer (DualOptim), which incorporates adaptive learning rate and decoupled momentum factors. Empirical and theoretical evidence demonstrates that DualOptim contributes to effective and stable unlearning. Through extensive experiments, we show that DualOptim can significantly boost MU efficacy and stability across diverse tasks, including image classification, image generation, and large language models, making it a versatile approach to empower existing MU algorithms.
Efficient Deployment of Spiking Neural Networks on SpiNNaker2 for DVS Gesture Recognition Using Neuromorphic Intermediate Representation
Apr 09, 2025Spiking Neural Networks (SNNs) are highly energy-efficient during inference, making them particularly suitable for deployment on neuromorphic hardware. Their ability to process event-driven inputs, such as data from dynamic vision sensors (DVS), further enhances their applicability to edge computing tasks. However, the resource constraints of edge hardware necessitate techniques like weight quantization, which reduce the memory footprint of SNNs while preserving accuracy. Despite its importance, existing quantization methods typically focus on synaptic weights quantization without taking account of other critical parameters, such as scaling neuron firing thresholds. To address this limitation, we present the first benchmark for the DVS gesture recognition task using SNNs optimized for the many-core neuromorphic chip SpiNNaker2. Our study evaluates two quantization pipelines for fixed-point computations. The first approach employs post training quantization (PTQ) with percentile-based threshold scaling, while the second uses quantization aware training (QAT) with adaptive threshold scaling. Both methods achieve accurate 8-bit on-chip inference, closely approximating 32-bit floating-point performance. Additionally, our baseline SNNs perform competitively against previously reported results without specialized techniques. These models are deployed on SpiNNaker2 using the neuromorphic intermediate representation (NIR). Ultimately, we achieve 94.13% classification accuracy on-chip, demonstrating the SpiNNaker2's potential for efficient, low-energy neuromorphic computing.
* 8 pages, 3 figures, 8 tables, Conference-2025 Neuro Inspired Computational Elements (NICE)
GarmageNet: A Dataset and Scalable Representation for Generic Garment Modeling
Apr 02, 2025



High-fidelity garment modeling remains challenging due to the lack of large-scale, high-quality datasets and efficient representations capable of handling non-watertight, multi-layer geometries. In this work, we introduce Garmage, a neural-network-and-CG-friendly garment representation that seamlessly encodes the accurate geometry and sewing pattern of complex multi-layered garments as a structured set of per-panel geometry images. As a dual-2D-3D representation, Garmage achieves an unprecedented integration of 2D image-based algorithms with 3D modeling workflows, enabling high fidelity, non-watertight, multi-layered garment geometries with direct compatibility for industrial-grade simulations.Built upon this representation, we present GarmageNet, a novel generation framework capable of producing detailed multi-layered garments with body-conforming initial geometries and intricate sewing patterns, based on user prompts or existing in-the-wild sewing patterns. Furthermore, we introduce a robust stitching algorithm that recovers per-vertex stitches, ensuring seamless integration into flexible simulation pipelines for downstream editing of sewing patterns, material properties, and dynamic simulations. Finally, we release an industrial-standard, large-scale, high-fidelity garment dataset featuring detailed annotations, vertex-wise correspondences, and a robust pipeline for converting unstructured production sewing patterns into GarmageNet standard structural assets, paving the way for large-scale, industrial-grade garment generation systems.
VenusFactory: A Unified Platform for Protein Engineering Data Retrieval and Language Model Fine-Tuning
Mar 19, 2025Natural language processing (NLP) has significantly influenced scientific domains beyond human language, including protein engineering, where pre-trained protein language models (PLMs) have demonstrated remarkable success. However, interdisciplinary adoption remains limited due to challenges in data collection, task benchmarking, and application. This work presents VenusFactory, a versatile engine that integrates biological data retrieval, standardized task benchmarking, and modular fine-tuning of PLMs. VenusFactory supports both computer science and biology communities with choices of both a command-line execution and a Gradio-based no-code interface, integrating $40+$ protein-related datasets and $40+$ popular PLMs. All implementations are open-sourced on https://github.com/tyang816/VenusFactory.
Dynamic Derivation and Elimination: Audio Visual Segmentation with Enhanced Audio Semantics
Mar 17, 2025Sound-guided object segmentation has drawn considerable attention for its potential to enhance multimodal perception. Previous methods primarily focus on developing advanced architectures to facilitate effective audio-visual interactions, without fully addressing the inherent challenges posed by audio natures, \emph{\ie}, (1) feature confusion due to the overlapping nature of audio signals, and (2) audio-visual matching difficulty from the varied sounds produced by the same object. To address these challenges, we propose Dynamic Derivation and Elimination (DDESeg): a novel audio-visual segmentation framework. Specifically, to mitigate feature confusion, DDESeg reconstructs the semantic content of the mixed audio signal by enriching the distinct semantic information of each individual source, deriving representations that preserve the unique characteristics of each sound. To reduce the matching difficulty, we introduce a discriminative feature learning module, which enhances the semantic distinctiveness of generated audio representations. Considering that not all derived audio representations directly correspond to visual features (e.g., off-screen sounds), we propose a dynamic elimination module to filter out non-matching elements. This module facilitates targeted interaction between sounding regions and relevant audio semantics. By scoring the interacted features, we identify and filter out irrelevant audio information, ensuring accurate audio-visual alignment. Comprehensive experiments demonstrate that our framework achieves superior performance in AVS datasets.
Robust Audio-Visual Segmentation via Audio-Guided Visual Convergent Alignment
Mar 17, 2025Accurately localizing audible objects based on audio-visual cues is the core objective of audio-visual segmentation. Most previous methods emphasize spatial or temporal multi-modal modeling, yet overlook challenges from ambiguous audio-visual correspondences such as nearby visually similar but acoustically different objects and frequent shifts in objects' sounding status. Consequently, they may struggle to reliably correlate audio and visual cues, leading to over- or under-segmentation. To address these limitations, we propose a novel framework with two primary components: an audio-guided modality alignment (AMA) module and an uncertainty estimation (UE) module. Instead of indiscriminately correlating audio-visual cues through a global attention mechanism, AMA performs audio-visual interactions within multiple groups and consolidates group features into compact representations based on their responsiveness to audio cues, effectively directing the model's attention to audio-relevant areas. Leveraging contrastive learning, AMA further distinguishes sounding regions from silent areas by treating features with strong audio responses as positive samples and weaker responses as negatives. Additionally, UE integrates spatial and temporal information to identify high-uncertainty regions caused by frequent changes in sound state, reducing prediction errors by lowering confidence in these areas. Experimental results demonstrate that our approach achieves superior accuracy compared to existing state-of-the-art methods, particularly in challenging scenarios where traditional approaches struggle to maintain reliable segmentation.
7ABAW-Compound Expression Recognition via Curriculum Learning
Mar 11, 2025With the advent of deep learning, expression recognition has made significant advancements. However, due to the limited availability of annotated compound expression datasets and the subtle variations of compound expressions, Compound Emotion Recognition (CE) still holds considerable potential for exploration. To advance this task, the 7th Affective Behavior Analysis in-the-wild (ABAW) competition introduces the Compound Expression Challenge based on C-EXPR-DB, a limited dataset without labels. In this paper, we present a curriculum learning-based framework that initially trains the model on single-expression tasks and subsequently incorporates multi-expression data. This design ensures that our model first masters the fundamental features of basic expressions before being exposed to the complexities of compound emotions. Specifically, our designs can be summarized as follows: 1) Single-Expression Pre-training: The model is first trained on datasets containing single expressions to learn the foundational facial features associated with basic emotions. 2) Dynamic Compound Expression Generation: Given the scarcity of annotated compound expression datasets, we employ CutMix and Mixup techniques on the original single-expression images to create hybrid images exhibiting characteristics of multiple basic emotions. 3) Incremental Multi-Expression Integration: After performing well on single-expression tasks, the model is progressively exposed to multi-expression data, allowing the model to adapt to the complexity and variability of compound expressions. The official results indicate that our method achieves the \textbf{best} performance in this competition track with an F-score of 0.6063. Our code is released at https://github.com/YenanLiu/ABAW7th.