 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind Maya: Building a Multilingual Vision Language Model
May 15, 2025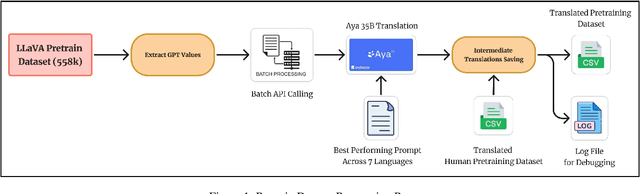
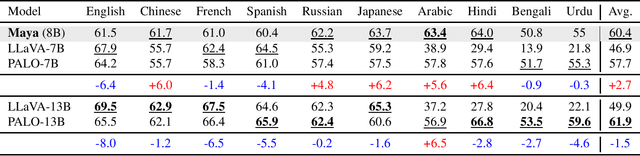

In recent times, we have seen a rapid development of large Vision-Language Models (VLMs). They have shown impressive results on academic benchmarks, primarily in widely spoken languages but lack performance on low-resource languages and varied cultural contexts. To address these limitations, we introduce Maya, an open-source Multilingual VLM. Our contributions are: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; and 2) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.
Understanding and Mitigating Toxicity in Image-Text Pretraining Datasets: A Case Study on LLaVA
May 09, 2025Pretraining datasets are foundational to the development of multimodal models, yet they often have inherent biases and toxic content from the web-scale corpora they are sourced from. In this paper, we investigate the prevalence of toxicity in LLaVA image-text pretraining dataset, examining how harmful content manifests in different modalities. We present a comprehensive analysis of common toxicity categories and propose targeted mitigation strategies, resulting in the creation of a refined toxicity-mitigated dataset. This dataset removes 7,531 of toxic image-text pairs in the LLaVA pre-training dataset. We offer guidelines for implementing robust toxicity detection pipelines. Our findings underscore the need to actively identify and filter toxic content - such as hate speech, explicit imagery, and targeted harassment - to build more responsible and equitable multimodal systems. The toxicity-mitigated dataset is open source and is available for further research.
Maya: An Instruction Finetuned Multilingual Multimodal Model
Dec 10, 2024



The rapid development of large Vision-Language Models (VLMs) has led to impressive results on academic benchmarks, primarily in widely spoken languages. However, significant gaps remain in the ability of current VLMs to handle low-resource languages and varied cultural contexts, largely due to a lack of high-quality, diverse, and safety-vetted data. Consequently, these models often struggle to understand low-resource languages and cultural nuances in a manner free from toxicity. To address these limitations, we introduce Maya, an open-source Multimodal Multilingual model. Our contributions are threefold: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; 2) a thorough analysis of toxicity within the LLaVA dataset, followed by the creation of a novel toxicity-free version across eight languages; and 3) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.
Distributed Swarm Intelligence
Jan 30, 2023This paper presents the development of a distributed application that facilitates the understanding and application of swarm intelligence in solving optimization problems. The platform comprises a search space of customizable random particles, allowing users to tailor the solution to their specific needs. By leveraging the power of Ray distributed computing, the application can support multiple users simultaneously, offering a flexible and scalable solution. The primary objective of this project is to provide a user-friendly platform that enhances the understanding and practical use of swarm intelligence in problem-solving.
People counting system for retail analytics using edge AI
May 25, 2022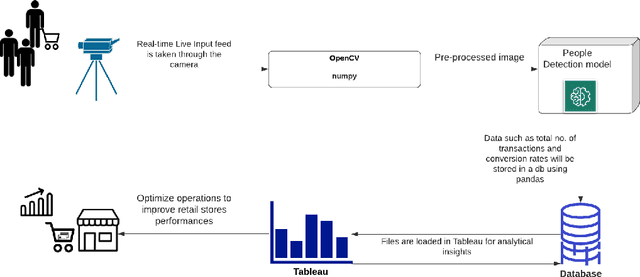

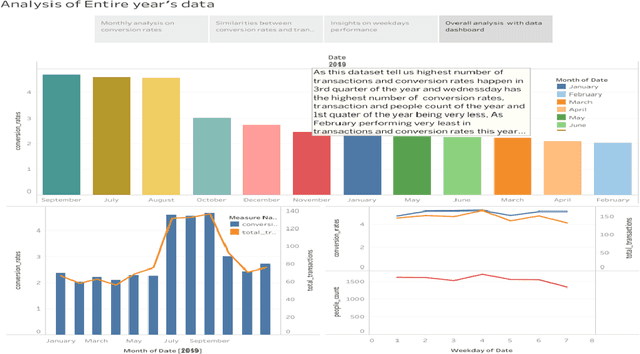
Developments in IoT applications are playing an important role in our day-to-day life, starting from business predictions to self driving cars. One of the area, most influenced by the field of AI and IoT is retail analytics. In Retail Analytics, Conversion Rates - a metric which is most often used by retail stores to measure how many people have visited the store and how many purchases has happened. This retail conversion rate assess the marketing operations, increasing stock, store outlet and running promotions ..etc. Our project intends to build a cost-effective people counting system with AI at Edge, where it calculates Conversion rates using total number of people counted by the system and number of transactions for the day, which helps in providing analytical insights for retail store optimization with a very minimum hardware requirements.