 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind Maya: Building a Multilingual Vision Language Model
May 15, 2025
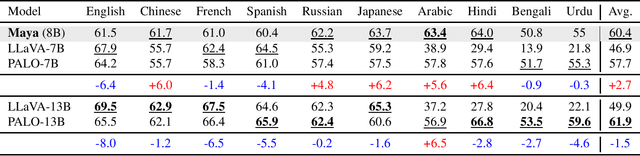

In recent times, we have seen a rapid development of large Vision-Language Models (VLMs). They have shown impressive results on academic benchmarks, primarily in widely spoken languages but lack performance on low-resource languages and varied cultural contexts. To address these limitations, we introduce Maya, an open-source Multilingual VLM. Our contributions are: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; and 2) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.
Understanding and Mitigating Toxicity in Image-Text Pretraining Datasets: A Case Study on LLaVA
May 09, 2025Pretraining datasets are foundational to the development of multimodal models, yet they often have inherent biases and toxic content from the web-scale corpora they are sourced from. In this paper, we investigate the prevalence of toxicity in LLaVA image-text pretraining dataset, examining how harmful content manifests in different modalities. We present a comprehensive analysis of common toxicity categories and propose targeted mitigation strategies, resulting in the creation of a refined toxicity-mitigated dataset. This dataset removes 7,531 of toxic image-text pairs in the LLaVA pre-training dataset. We offer guidelines for implementing robust toxicity detection pipelines. Our findings underscore the need to actively identify and filter toxic content - such as hate speech, explicit imagery, and targeted harassment - to build more responsible and equitable multimodal systems. The toxicity-mitigated dataset is open source and is available for further research.
Maya: An Instruction Finetuned Multilingual Multimodal Model
Dec 10, 2024



The rapid development of large Vision-Language Models (VLMs) has led to impressive results on academic benchmarks, primarily in widely spoken languages. However, significant gaps remain in the ability of current VLMs to handle low-resource languages and varied cultural contexts, largely due to a lack of high-quality, diverse, and safety-vetted data. Consequently, these models often struggle to understand low-resource languages and cultural nuances in a manner free from toxicity. To address these limitations, we introduce Maya, an open-source Multimodal Multilingual model. Our contributions are threefold: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; 2) a thorough analysis of toxicity within the LLaVA dataset, followed by the creation of a novel toxicity-free version across eight languages; and 3) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.
Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning
Feb 09, 2024



Datasets are foundational to many breakthroughs in modern artificial intelligence. Many recent achievements in the space of natural language processing (NLP) can be attributed to the finetuning of pre-trained models on a diverse set of tasks that enables a large language model (LLM) to respond to instructions. Instruction fine-tuning (IFT) requires specifically constructed and annotated datasets. However, existing datasets are almost all in the English language. In this work, our primary goal is to bridge the language gap by building a human-curated instruction-following dataset spanning 65 languages. We worked with fluent speakers of languages from around the world to collect natural instances of instructions and completions. Furthermore, we create the most extensive multilingual collection to date, comprising 513 million instances through templating and translating existing datasets across 114 languages. In total, we contribute four key resources: we develop and open-source the Aya Annotation Platform, the Aya Dataset, the Aya Collection, and the Aya Evaluation Suite. The Aya initiative also serves as a valuable case study in participatory research, involving collaborators from 119 countries. We see this as a valuable framework for future research collaborations that aim to bridge gaps in resources.