 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDispersion Loss Counteracts Embedding Condensation and Improves Generalization in Small Language Models
Jan 30, 2026Large language models (LLMs) achieve remarkable performance through ever-increasing parameter counts, but scaling incurs steep computational costs. To better understand LLM scaling, we study representational differences between LLMs and their smaller counterparts, with the goal of replicating the representational qualities of larger models in the smaller models. We observe a geometric phenomenon which we term $\textbf{embedding condensation}$, where token embeddings collapse into a narrow cone-like subspace in some language models. Through systematic analyses across multiple Transformer families, we show that small models such as $\texttt{GPT2}$ and $\texttt{Qwen3-0.6B}$ exhibit severe condensation, whereas the larger models such as $\texttt{GPT2-xl}$ and $\texttt{Qwen3-32B}$ are more resistant to this phenomenon. Additional observations show that embedding condensation is not reliably mitigated by knowledge distillation from larger models. To fight against it, we formulate a dispersion loss that explicitly encourages embedding dispersion during training. Experiments demonstrate that it mitigates condensation, recovers dispersion patterns seen in larger models, and yields performance gains across 10 benchmarks. We believe this work offers a principled path toward improving smaller Transformers without additional parameters.
Geometry-Aware Generative Autoencoders for Warped Riemannian Metric Learning and Generative Modeling on Data Manifolds
Oct 16, 2024



Rapid growth of high-dimensional datasets in fields such as single-cell RNA sequencing and spatial genomics has led to unprecedented opportunities for scientific discovery, but it also presents unique computational and statistical challenges. Traditional methods struggle with geometry-aware data generation, interpolation along meaningful trajectories, and transporting populations via feasible paths. To address these issues, we introduce Geometry-Aware Generative Autoencoder (GAGA), a novel framework that combines extensible manifold learning with generative modeling. GAGA constructs a neural network embedding space that respects the intrinsic geometries discovered by manifold learning and learns a novel warped Riemannian metric on the data space. This warped metric is derived from both the points on the data manifold and negative samples off the manifold, allowing it to characterize a meaningful geometry across the entire latent space. Using this metric, GAGA can uniformly sample points on the manifold, generate points along geodesics, and interpolate between populations across the learned manifold. GAGA shows competitive performance in simulated and real world datasets, including a 30% improvement over the state-of-the-art methods in single-cell population-level trajectory inference.
DiffKillR: Killing and Recreating Diffeomorphisms for Cell Annotation in Dense Microscopy Images
Oct 04, 2024



The proliferation of digital microscopy images, driven by advances in automated whole slide scanning, presents significant opportunities for biomedical research and clinical diagnostics. However, accurately annotating densely packed information in these images remains a major challenge. To address this, we introduce DiffKillR, a novel framework that reframes cell annotation as the combination of archetype matching and image registration tasks. DiffKillR employs two complementary neural networks: one that learns a diffeomorphism-invariant feature space for robust cell matching and another that computes the precise warping field between cells for annotation mapping. Using a small set of annotated archetypes, DiffKillR efficiently propagates annotations across large microscopy images, reducing the need for extensive manual labeling. More importantly, it is suitable for any type of pixel-level annotation. We will discuss the theoretical properties of DiffKillR and validate it on three microscopy tasks, demonstrating its advantages over existing supervised, semi-supervised, and unsupervised methods.
Assessing Neural Network Representations During Training Using Noise-Resilient Diffusion Spectral Entropy
Dec 04, 2023



Entropy and mutual information in neural networks provide rich information on the learning process, but they have proven difficult to compute reliably in high dimensions. Indeed, in noisy and high-dimensional data, traditional estimates in ambient dimensions approach a fixed entropy and are prohibitively hard to compute. To address these issues, we leverage data geometry to access the underlying manifold and reliably compute these information-theoretic measures. Specifically, we define diffusion spectral entropy (DSE) in neural representations of a dataset as well as diffusion spectral mutual information (DSMI) between different variables representing data. First, we show that they form noise-resistant measures of intrinsic dimensionality and relationship strength in high-dimensional simulated data that outperform classic Shannon entropy, nonparametric estimation, and mutual information neural estimation (MINE). We then study the evolution of representations in classification networks with supervised learning, self-supervision, or overfitting. We observe that (1) DSE of neural representations increases during training; (2) DSMI with the class label increases during generalizable learning but stays stagnant during overfitting; (3) DSMI with the input signal shows differing trends: on MNIST it increases, while on CIFAR-10 and STL-10 it decreases. Finally, we show that DSE can be used to guide better network initialization and that DSMI can be used to predict downstream classification accuracy across 962 models on ImageNet. The official implementation is available at https://github.com/ChenLiu-1996/DiffusionSpectralEntropy.
Sentence Embeddings using Supervised Contrastive Learning
Jun 09, 2021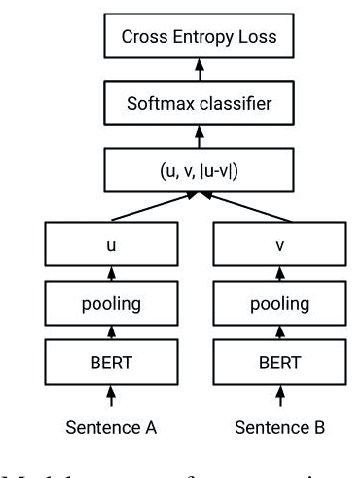

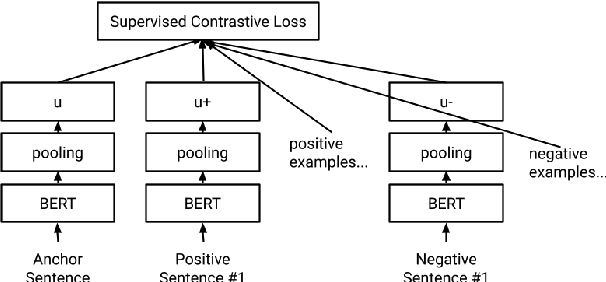
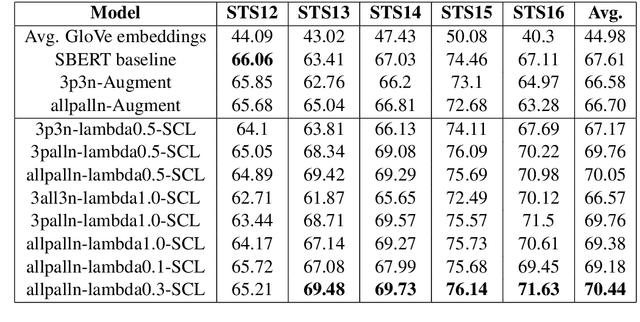
Sentence embeddings encode sentences in fixed dense vectors and have played an important role in various NLP tasks and systems. Methods for building sentence embeddings include unsupervised learning such as Quick-Thoughts and supervised learning such as InferSent. With the success of pretrained NLP models, recent research shows that fine-tuning pretrained BERT on SNLI and Multi-NLI data creates state-of-the-art sentence embeddings, outperforming previous sentence embeddings methods on various evaluation benchmarks. In this paper, we propose a new method to build sentence embeddings by doing supervised contrastive learning. Specifically our method fine-tunes pretrained BERT on SNLI data, incorporating both supervised crossentropy loss and supervised contrastive loss. Compared with baseline where fine-tuning is only done with supervised cross-entropy loss similar to current state-of-the-art method SBERT, our supervised contrastive method improves 2.8% in average on Semantic Textual Similarity (STS) benchmarks and 1.05% in average on various sentence transfer tasks.