 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Prediction via Shrinkage
Feb 05, 2026We study differentially private prediction introduced by Dwork and Feldman (COLT 2018): an algorithm receives one labeled sample set $S$ and then answers a stream of unlabeled queries while the output transcript remains $(\varepsilon,δ)$-differentially private with respect to $S$. Standard composition yields a $\sqrt{T}$ dependence for $T$ queries. We show that this dependence can be reduced to polylogarithmic in $T$ in streaming settings. For an oblivious online adversary and any concept class $\mathcal{C}$, we give a private predictor that answers $T$ queries with $|S|= \tilde{O}(VC(\mathcal{C})^{3.5}\log^{3.5}T)$ labeled examples. For an adaptive online adversary and halfspaces over $\mathbb{R}^d$, we obtain $|S|=\tilde{O}\left(d^{5.5}\log T\right)$.
Learning Adaptive Cross-Embodiment Visuomotor Policy with Contrastive Prompt Orchestration
Feb 01, 2026Learning adaptive visuomotor policies for embodied agents remains a formidable challenge, particularly when facing cross-embodiment variations such as diverse sensor configurations and dynamic properties. Conventional learning approaches often struggle to separate task-relevant features from domain-specific variations (e.g., lighting, field-of-view, and rotation), leading to poor sample efficiency and catastrophic failure in unseen environments. To bridge this gap, we propose ContrAstive Prompt Orchestration (CAPO), a novel approach for learning visuomotor policies that integrates contrastive prompt learning and adaptive prompt orchestration. For prompt learning, we devise a hybrid contrastive learning strategy that integrates visual, temporal action, and text objectives to establish a pool of learnable prompts, where each prompt induces a visual representation encapsulating fine-grained domain factors. Based on these learned prompts, we introduce an adaptive prompt orchestration mechanism that dynamically aggregates these prompts conditioned on current observations. This enables the agent to adaptively construct optimal state representations by identifying dominant domain factors instantaneously. Consequently, the policy optimization is effectively shielded from irrelevant interference, preventing the common issue of overfitting to source domains. Extensive experiments demonstrate that CAPO significantly outperforms state-of-the-art baselines in sample efficiency and asymptotic performance. Crucially, it exhibits superior zero-shot adaptation across unseen target domains characterized by drastic environmental (e.g., illumination) and physical shifts (e.g., field-of-view and rotation), validating its effectiveness as a viable solution for cross-embodiment visuomotor policy adaptation.
Step-Audio-EditX Technical Report
Nov 05, 2025


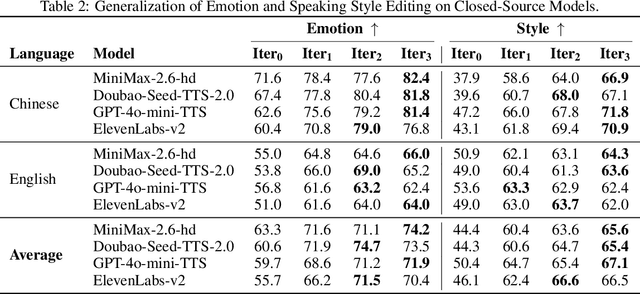
We present Step-Audio-EditX, the first open-source LLM-based audio model excelling at expressive and iterative audio editing encompassing emotion, speaking style, and paralinguistics alongside robust zero-shot text-to-speech (TTS) capabilities.Our core innovation lies in leveraging only large-margin synthetic data, which circumvents the need for embedding-based priors or auxiliary modules. This large-margin learning approach enables both iterative control and high expressivity across voices, and represents a fundamental pivot from the conventional focus on representation-level disentanglement. Evaluation results demonstrate that Step-Audio-EditX surpasses both MiniMax-2.6-hd and Doubao-Seed-TTS-2.0 in emotion editing and other fine-grained control tasks.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025



Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
An \tilde{O}ptimal Differentially Private Learner for Concept Classes with VC Dimension 1
May 10, 2025We present the first nearly optimal differentially private PAC learner for any concept class with VC dimension 1 and Littlestone dimension $d$. Our algorithm achieves the sample complexity of $\tilde{O}_{\varepsilon,\delta,\alpha,\delta}(\log^* d)$, nearly matching the lower bound of $\Omega(\log^* d)$ proved by Alon et al. [STOC19]. Prior to our work, the best known upper bound is $\tilde{O}(VC\cdot d^5)$ for general VC classes, as shown by Ghazi et al. [STOC21].
Role and Use of Race in AI/ML Models Related to Health
Apr 01, 2025The role and use of race within health-related artificial intelligence and machine learning (AI/ML) models has sparked increasing attention and controversy. Despite the complexity and breadth of related issues, a robust and holistic framework to guide stakeholders in their examination and resolution remains lacking. This perspective provides a broad-based, systematic, and cross-cutting landscape analysis of race-related challenges, structured around the AI/ML lifecycle and framed through "points to consider" to support inquiry and decision-making.
A Consensus Privacy Metrics Framework for Synthetic Data
Mar 06, 2025Synthetic data generation is one approach for sharing individual-level data. However, to meet legislative requirements, it is necessary to demonstrate that the individuals' privacy is adequately protected. There is no consolidated standard for measuring privacy in synthetic data. Through an expert panel and consensus process, we developed a framework for evaluating privacy in synthetic data. Our findings indicate that current similarity metrics fail to measure identity disclosure, and their use is discouraged. For differentially private synthetic data, a privacy budget other than close to zero was not considered interpretable. There was consensus on the importance of membership and attribute disclosure, both of which involve inferring personal information about an individual without necessarily revealing their identity. The resultant framework provides precise recommendations for metrics that address these types of disclosures effectively. Our findings further present specific opportunities for future research that can help with widespread adoption of synthetic data.
Towards Statistical Factuality Guarantee for Large Vision-Language Models
Feb 27, 2025Advancements in Large Vision-Language Models (LVLMs) have demonstrated promising performance in a variety of vision-language tasks involving image-conditioned free-form text generation. However, growing concerns about hallucinations in LVLMs, where the generated text is inconsistent with the visual context, are becoming a major impediment to deploying these models in applications that demand guaranteed reliability. In this paper, we introduce a framework to address this challenge, ConfLVLM, which is grounded on conformal prediction to achieve finite-sample distribution-free statistical guarantees on the factuality of LVLM output. This framework treats an LVLM as a hypothesis generator, where each generated text detail (or claim) is considered an individual hypothesis. It then applies a statistical hypothesis testing procedure to verify each claim using efficient heuristic uncertainty measures to filter out unreliable claims before returning any responses to users. We conduct extensive experiments covering three representative application domains, including general scene understanding, medical radiology report generation, and document understanding. Remarkably, ConfLVLM reduces the error rate of claims generated by LLaVa-1.5 for scene descriptions from 87.8\% to 10.0\% by filtering out erroneous claims with a 95.3\% true positive rate. Our results further demonstrate that ConfLVLM is highly flexible, and can be applied to any black-box LVLMs paired with any uncertainty measure for any image-conditioned free-form text generation task while providing a rigorous guarantee on controlling the risk of hallucination.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.